本文最初发表在 Towards Data Science 博客,经原作者 Moez Ali 授权,InfoQ 中文站翻译并分享。
PyCaret 是一个用 Python 编写的开源、低代码的机器学习库,可以将机器学习工作流实现自动化。它是一个端到端的机器学习和模型管理工具,可以加快机器学习实验周期,并提高工作效率。目前,PyCaret 2.0 已经发布。
与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,仅用很少的单词就可以替换数百行代码。这使得实验的速度和效率呈指数级增长。
为什么要用 PyCaret?
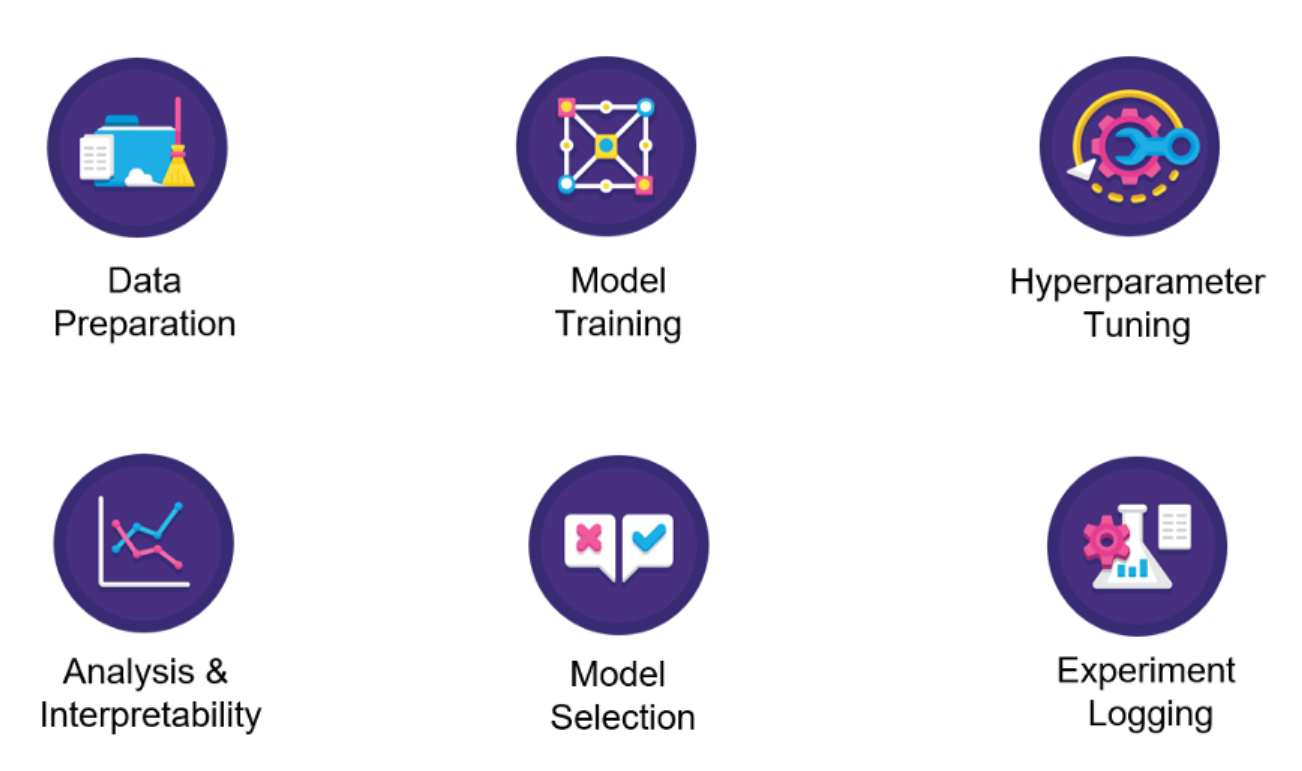
PyCaret 2.0 的主要功能包括:数据准备、模型训练、超参数调整、分析 &可解释性、模型选择、实验日志等。
安装 PyCaret 2.0
安装 PyCaret 非常简单,只需几分钟即可。我们强烈建议使用虚拟环境,以避免与其他库的潜在冲突。请参阅下面的示例代码来创建一个 conda 环境并在该 conda 环境中安装 PyCaret:
# create a conda environmentconda create --name yourenvname python=3.6# activate environmentconda activate yourenvname# install pycaretpip install pycaret==2.0# create notebook kernel linked with the conda environment python -m ipykernel install --user --name yourenvname --display-name "display-name"
复制代码
如果你使用的是 Azure Notebook 或 Google Colab,请运行以下代码来安装 PyCaret:
!pip install pycaret==2.0
复制代码
使用 pip 安装 PyCaret 时,所有硬依赖项都会自动安装。
依赖项的完整列表地址:
https://github.com/pycaret/pycaret/blob/master/requirements.txt
PyCaret 2.0 入门
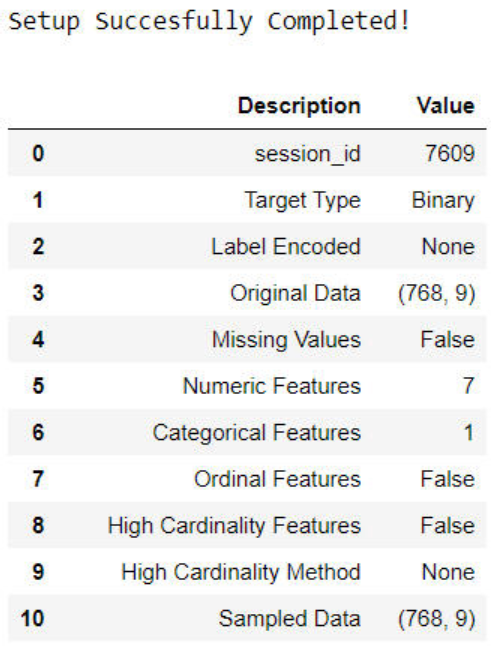
在 PyCaret 中,任何机器学习实验的第一步都是通过导入相关模块来建立环境,并通过传递数据框和目标变量的名称来初始化设置(setup)函数。请见以下示例代码:
# Import modulefrom pycaret.classification import *
# Initialize setup (when using Notebook environment)clf1 = setup(data, target = 'target-variable')
# Initialize setup (outside of Notebook environment)clf1 = setup(data, target = 'target-variable', html = False)
# Initialize setup (When using remote execution such as Kaggle / GitHub actions / CI-CD pipelines)clf1 = setup(data, target = 'target-variable', html = False, silent = True)
复制代码
样例输出:
所有预处理转换都在 setup 函数中应用。PyCaret 提供了 20 多种不同的预处理转换,这些转换可以在 setup 函数中定义。要了解 PyCaret 的预处理功能的更多信息,请单击此处。
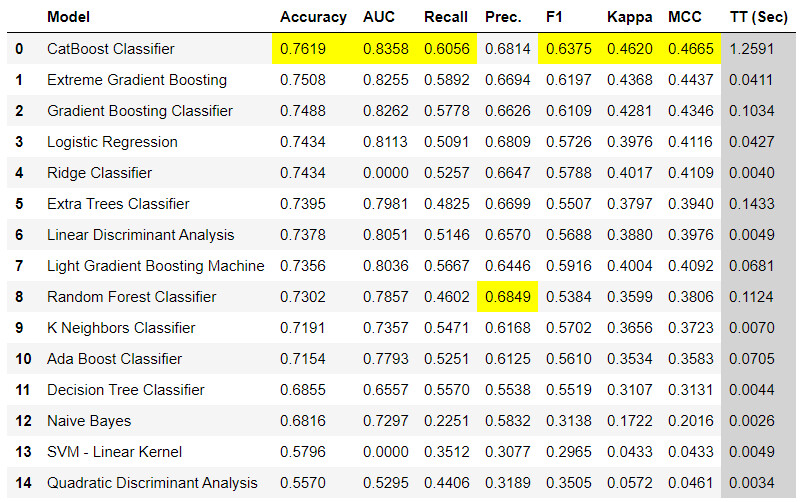
模型比较
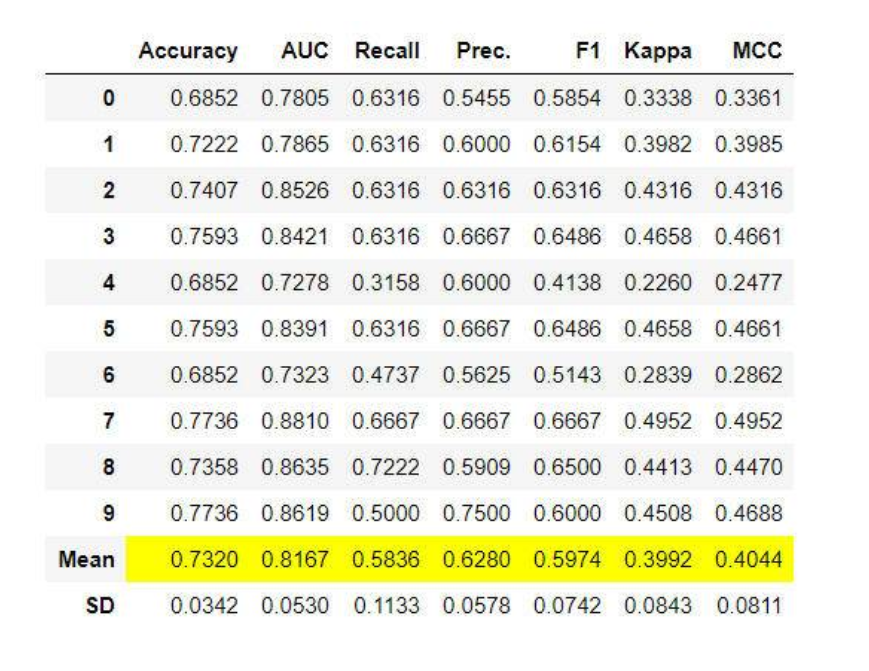
这是我们在任何监督式学习任务中推荐的第一步。这个函数使用默认的超参数来训练模型库中的所有模型,并使用交叉验证来评估性能指标。它返回经过训练的模型对象类。所使用的评估指标为:
以下是使用 compare_models 函数的几种方法:
# import classification modulefrom pycaret.classification import *
# init setupclf1 = setup(data, target = 'name-of-target')
# return best modelbest = compare_models()
# return best model based on Recallbest = compare_models(sort = 'Recall') #default is 'Accuracy'
# compare specific modelsbest_specific = compare_models(whitelist = ['dt','rf','xgboost'])
# blacklist certain modelsbest_specific = compare_models(blacklist = ['catboost','svm'])
# return top 3 models based on Accuracytop3 = compare_models(n_select = 3)
复制代码
样例输出:
模型创建
模型创建(create_model)函数使用默认超参数训练模型,并使用交叉验证评估性能指标。这个函数是 PyCaret 中几乎所有其他函数的基础。它返回经过训练的模型对象类。以下是使用这个函数的几种方法:
# import classification modulefrom pycaret.classification import *
# init setupclf1 = setup(data, target = 'name-of-target')
# train logistic regression modellr = create_model('lr') #lr is the id of the model
# check the model library to see all modelsmodels()
# train rf model using 5 fold CVrf = create_model('rf', fold = 5)
# train svm model without CVsvm = create_model('svm', cross_validation = False)
# train xgboost model with max_depth = 10xgboost = create_model('xgboost', max_depth = 10)
# train xgboost model on gpuxgboost_gpu = create_model('xgboost', tree_method = 'gpu_hist', gpu_id = 0) #0 is gpu-id
# train multiple lightgbm models with n learning_ratelgbms = [create_model('lightgbm', learning_rate = i) for i in np.arange(0.1,1,0.1)]
# train custom modelfrom gplearn.genetic import SymbolicClassifiersymclf = SymbolicClassifier(generation = 50)sc = create_model(symclf)
复制代码
样例输出:
模型调优
模型调优(tune_model)函数调优作为评估其传递的模型的超参数。它使用随机网格搜索和预定义的可调优网格是完全可定制的。以下是使用这个函数的几种方法:
# import classification modulefrom pycaret.classification import *
# init setupclf1 = setup(data, target = 'name-of-target')
# train a decision tree modeldt = create_model('dt')
# tune hyperparameters of decision treetuned_dt = tune_model(dt)
# tune hyperparameters with increased n_itertuned_dt = tune_model(dt, n_iter = 50)
# tune hyperparameters to optimize AUCtuned_dt = tune_model(dt, optimize = 'AUC') #default is 'Accuracy'
# tune hyperparameters with custom_gridparams = {"max_depth": np.random.randint(1, (len(data.columns)*.85),20), "max_features": np.random.randint(1, len(data.columns),20), "min_samples_leaf": [2,3,4,5,6], "criterion": ["gini", "entropy"] }
tuned_dt_custom = tune_model(dt, custom_grid = params)
# tune multiple models dynamicallytop3 = compare_models(n_select = 3)tuned_top3 = [tune_model(i) for i in top3]
复制代码
模型集成
对于集成基础学习者来说,几乎没有可用的函数。ensemble_model、blend_models 和 stack_models 是其中的三个。以下是使用这些函数的几种方法:
# import classification modulefrom pycaret.classification import *
# init setupclf1 = setup(data, target = 'name-of-target')
# train a decision tree modeldt = create_model('dt')
# train a bagging classifier on dtbagged_dt = ensemble_model(dt, method = 'Bagging')
# train a adaboost classifier on dt with 100 estimatorsboosted_dt = ensemble_model(dt, method = 'Boosting', n_estimators = 100)
# train a votingclassifier on all models in libraryblender = blend_models()
# train a voting classifier on specific modelsdt = create_model('dt')rf = create_model('rf')adaboost = create_model('ada')blender_specific = blend_models(estimator_list = [dt,rf,adaboost], method = 'soft')
# train a voting classifier dynamicallyblender_top5 = blend_models(compare_models(n_select = 5))
# train a stacking classifierstacker = stack_models(estimator_list = [dt,rf], meta_model = adaboost)
# stack multiple models dynamicallytop7 = compare_models(n_select = 7)stacker = stack_models(estimator_list = top7[1:], meta_model = top7[0])
复制代码
要了解 PyCaret 中模型集成的更多信息,请单击此处。
模型预测
顾名思义,这个 predict_model 函数用于推理/预测。以下是使用这个函数的方法:
# train a catboost modelcatboost = create_model('catboost')
# predict on holdout set (when no data is passed)pred_holdout = predict_model(catboost)
# predict on new datasetnew_data = pd.read_csv('new-data.csv')pred_new = predict_model(catboost, data = new_data)
复制代码
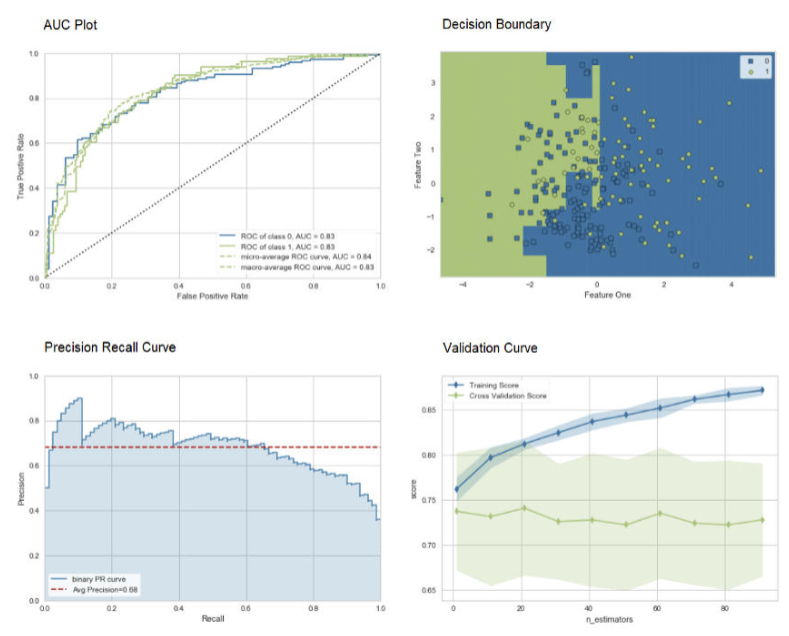
模型绘制
利用模型绘制(plot_model)函数对训练好的机器学习模型进行性能评估。下面是一个示例代码:
# import classification modulefrom pycaret.classification import *
# init setupclf1 = setup(data, target = 'name-of-target')
# train adaboost modeladaboost = create_model('ada')
# AUC plotplot_model(adaboost, plot = 'auc')
# Decision Boundaryplot_model(adaboost, plot = 'boundary')
# Precision Recall Curveplot_model(adaboost, plot = 'pr')
# Validation Curveplot_model(adaboost, plot = 'vc')
复制代码
plot_model 函数的样例输出
要了解 PyCaret 中不同可视化的更多信息,请单击此处。
或者,你可以使用 evaluate_model 函数通过 Notebook 中的用户界面查看绘图。
PyCaret 中的 evaluate_model 函数
有用的函数
PyCaret 2.0 包含了一些新的实用函数,这些函数字使用 PyCaret 管理机器学习实验时非常方便。其中一些如下示例代码所示:
# select and finalize the best model in the active runbest_model = automl() #returns the best model based on CV score
# select and finalize the best model based on 'F1' on hold_out setbest_model_holdout = automl(optimize = 'F1', use_holdout = True)
# save modelsave_model(model, 'c:/path-to-directory/model-name')
# load modelmodel = load_model('c:/path-to-directory/model-name')
# retrieve score grid as pandas dfdt = create_model('dt')dt_results = pull() #this will store dt score grid as pandas df
# get global environment variableX_train = get_config('X_train') #returns X_train dataset after preprocessingseed = get_config('seed') returns seed from global environment
# set global environment variableset_seed(seed, 999) #seed set to 999 in global environment of active run
# get experiment logs as csv filelogs = get_logs() #for active run by default
# get system logs for auditsystem_logs = get_system_logs() #read logs.log file from active directory
复制代码
要查看 PyCaret 2.0 中实现的所有新函数,请参阅发行说明。
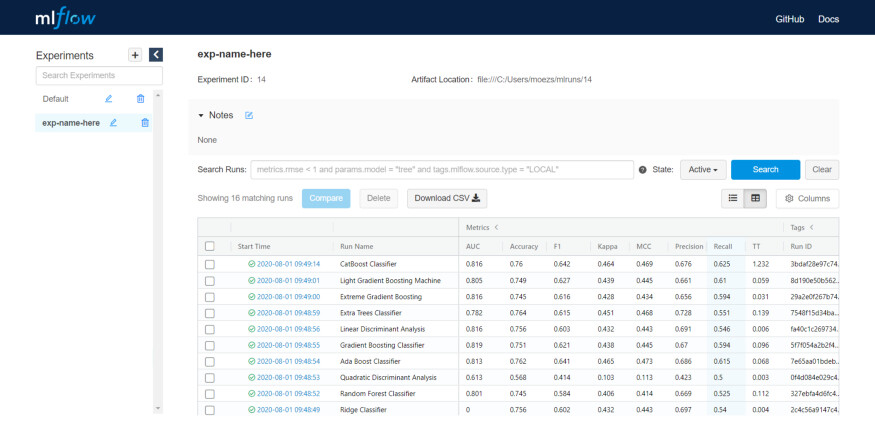
实验日志
PyCaret 2.0 嵌入了 MLflow 跟踪组件,作为运行机器学习代码时的后端 API 和 UI,用于记录参数、代码版本、指标和输出文件,并用于以后可视化结果。下面是如何在 PyCaret 中记录实验的方法。
# import classification modulefrom pycaret.classification import *
# init setupclf1 = setup(data, target = 'name-of-target', log_experiment = True, experiment_name = 'exp-name-here')
# compare modelsbest = compare_models()
# start mlflow server on localhost:5000 (when using notebook)!mlflow ui
复制代码
输出(在 localhost:5000):
将它们放在一起——创建你自己的 AutoML 软件
使用所有的函数,让我们创建一个简单的命令行软件,它可以使用默认参数来训练多个模型,调优最佳候选模型的超参数,尝试不同的集成技术,并返回/保存最佳模型。以下是命令行脚本:
# import librariesimport pandas as pdimport sys
# define command line parametersdata = sys.argv[1]target = sys.argv[2]
# load data (replace this part with your own script)from pycaret.datasets import get_datainput_data = get_data(data)
# init setupfrom pycaret.classification import *clf1 = setup(data = input_data, target = target, log_experiment = True)
# compare baseline models and select top5top5 = compare_models(n_select = 5)
# tune top5 modelstuned_top5 = [tune_model(i) for i in top5]
# ensemble top5 tuned modelsbagged_tuned_top5 = [ensemble_model(i, method = 'Bagging') for i in tuned_top5]
# blend top5 modelsblender = blend_models(estimator_list = top5)
# stack top5 modelsstacker = stack_models(estimator_list = top5[1:], meta_model = top5[0])
# select best model based on recallbest_model = automl(optimize = 'Recall')
# save modelsave_model(best_model, 'c:/path-to-directory/final-model')
复制代码
这个脚本将动态选择并保存最佳模型。只需几行代码,就可以开发出自己的 AutoML 软件,这个软件带有一个完善的日志记录系统,甚至还有一个漂亮的排行榜的 UI。使用 Python 中的轻量级工作流自动化库可以实现的功能是没有限制的。
作者简介:
Moez Ali,数据科学家,PyCaret 的创始人和作者。
原文链接:
https://towardsdatascience.com/announcing-pycaret-2-0-39c11014540e


















评论