

前言
目前携程酒店绝大部分排序业务中所涉及的问题,基本可以通过应用排序学习完成。而其中模型训练步骤中所需的训练数据集,一般是通过线下收集数据来完成的。
然而在实际当中,往往存在业务新增或者业务变更,这就使得使用历史数据训练的模型,并不能很好地用于变更后的应用场景。形成该问题的主要原因,是过去所收集的数据与实际排序场景并不一致。
为了应对类似问题,我们尝试在城市欢迎度排序场景中引入了强化学习。通过实验发现,增加强化学习后,能够在一定程度上提高排序的质量。
一、实际面临的问题
在目前大部分的实践中,我们解决排序问题所诉诸的办法,基本都可以归为传统意义上的“排序学习”(learning to rank, L2R)。排序学习基本的建模过程,是通过收集数据,构建特征,选择模型,训练模型等步骤实现。
其中第一步收集数据,往往是以离线的方式完成。常见方法是通过埋点服务器收集用户行为数据,再进行模型训练数据的构建。
在收集数据的时候,一般存在一个假设要求:即我们所收集到的数据是和总体数据分布保持一致的,模型只要在这个基础上进行训练,所得到的结果在实际线上业务使用时是可靠的。我们暂且称其为“分布一致假设”。
当业务体量足够大、收集数据足够多时,一般会认为这一假设是成立的。然而在实际当中,要满足分布一致假设会面临一系列的挑战。这其中包含且不限于各种埋点服务准确性难以保证,数据处理中无法完全避免的数据损失,以及收集数据时间空间上的限制等问题。
此外,当排序应用的目标是预测现有数据集中不存在的情况时,传统的排序学习将变得无能为力。举一个商品排序的例子。在排序 list 结果展现中,我们设置业务限制:top10 的 item 只能是 1000 元以上的商品。假设现在的排序目标为点击率(CTR),从现有数据进行模型训练后,模型很难准确地告诉我们一件 10 元商品出现在 top10 时它的 CTR 是多少,因为它根本没有在这个位置出现过。
这种“预测不曾在历史中出现的事件”的需求在实际当中并不少见:在多指标融合的排序指标中(例如排序指标是要在 CTR 和转化率 CVR 之间做加权),如何设置不同子指标之间的权重就是一例。
由于新的权重下得到的数据分布是不存在现有的数据集当中的,因此无法充分知晓用户在新的排序结果下的行为结果,在新权重的条件下训练一个模型满足业务目标也就无从谈起了。
更重要的是,实际上我们很难充分收集数据:试想,对于同一个用户,难道我们要将 100 种不同的权重参数所得到的排序结果,都一一展现给同一个用户,然后收集其给出的行为结果么?答案当然是否定的。
携程酒店排序业务中,同样也存在这样的问题。具体来说有两点最为明显:
1)对于内外网比价结果为优势或者劣势的酒店,我们是否应该调整该酒店的排序位置、以及应该如何调整。这个问题的答案并不是直观的,因为对不同用户来说,可能会存在不同的偏好,以及对于不同酒店来说,这一个问题的结果也可能是不同的。
2)对于历史上由于业务设置的原因排名靠后的酒店,在个性化排序或者广告业务中若将其位置提前,如何准确预测用户对这些酒店的行为。
这两个业务需求,都可以归结为前面提到的无法预先收集同分布数据集的问题,传统的 L2R 并不能很好地进行支持解决。
二、可能的解决方案
我们再仔细考虑下“将 100 个不同排序结果丢给同一个用户”这种做法的弊端。毫无疑问,这种暴力的做法虽然似乎能够充分收集数据,但事实上是有着极高的成本:极为伤害用户体验。
然而,为了能够让模型有机会预测那些未知的情况,又必然是需要一定的“随机探索”,只有这样我们才能知道实际中用户的反馈。因此,随机探索所带来的短期损失是无法完全避免的,但最终的目标是在于探索所带来的收益能够弥补并超过其带来的损失。
而“强化学习”的目标,恰好和我们的需求不谋而合。
三、谈谈 RL 的背景,它解决的问题
为了方便后的表述,先简单介绍下强化学习(reinforcement learning, RL)的背景,对其概念熟悉的同学可以略过这一部分。
“强化”的概念起源于行为心理学派。行为心理学派主要的概念是说,人的复杂高级行为,例如恐惧,是可以用过“强化”进行塑造的。同巴普洛夫的条件反射不同,心理学派认为生物的行为不需要通过直接的刺激所引起,行为更多地是因为行为本身所带来的结果,生物体自发地执行该行为。
举个例子来说,迷信行为的出现,主要的原因是人们认为迷信行为会为自己带来好运,而不是真的会直接让我们的彩票中奖。
机器学习(machinelearning,ML)领域的 RL,就好比是利用这种行为生成理论,训练一个机器人(agent),让它能出现我们所期望的行为,以实现我们的目标。
简单来说,RL 组成要素包括执行动作(action)的 agent,agent 所在环境(environment),以及环境给与 agent 的反馈(reward)。Agent 根据对环境的观察(observation)通过给出 action 到 environment,得到 environment 对该 action 的 reward,由此 agent 判断自己 action 是否有利并由此进行迭代修正,再发出新的 action。
那么它和传统 ML 方法有什么差别呢?在我的理解来看,RL 之所以能够处理一些传统 ML 无法做到的事情,主要是在于其具有探索(exploration)能力,以及其长期累计收益最大化(maximize long term cumulative reward)的学习目标。
我们耳熟能详的 RL 应用例子 Alpha Go 为例,之所以它能够击败人类职业棋手,依靠的就是 RL 可以通过探索获得更好的长期收益,而不是完全地从人类历史棋谱中进行监督学习,从而实现对人类的超越。
对于我们前面提到的 L2R 无法处理的问题,也同样可以诉诸 RL 途径。例如前面提到电商排序问题,通过 RL 的 exploration 机制,让排序在后面的商品有机会以一定的概率在靠前位置曝光,并且在长期收益最大化的目标保证下,能够让我们随机探索的收益大于其带来的代价。
四、RL 和业务结合应用的思考过程,详述实践内容和碰到的问题,分步骤的实践方案
再回到前面提及的酒店排序中遇到的两个问题。我们认为 RL 是解决这两个问题的不二途径。成功实施 RL 的关键点在于如何设计 RL 中各要素以满足业务的需求。为此我们预先设计了几套循序渐进的方案。
第一个方案,我们就姑且称其为“方案 A”吧。方案 A 我们主要将其作为一个小规模探索,摸清流程和潜在的问题。在这个方案里,我们将不会花过多的时间在特征构建等问题上,主要是将 RL 的流程实现,并观察其带来的结果。
具体来说,我们计划在主排序的线性模型基础之上,对线性模型的若干维度进行权重调整,以实现对排序结果的调整。而 RL 的目标,就是学习这些对权重做出调整的“超参”,从而能够依照不同的输入数据,得到更优的排序序列。在粒度控制上,我们以城市为单位进行 action 输出,这样做的主要考量是数据部分的工程复杂性。
算法选择上,我们选择使用 DQN。DQN 作为 value base 的 RL 算法,无法给出连续区间的控制输出,这就意味着我们给出的权重调整需要预先定义一些固定的区间,但其易用性是我们在方案 A 中选择它的理由之一。
在工程实现上,RL 最大的挑战在于 action 发出与 reward 回收的环节对实时性的要求较高。在方案 A 我们打算利用现有 Kafka 环境,通过消息同步的方式连接前后端,进行 action 与 reward 数据匹配。这样的额外工程量最小。
但问题也很明显:Kafka 当时是对全业务埋点进行统一定时处理,势必存在更新缓慢延迟过大的问题,且发出 action 后与实际权重更新发送到前端存在不可控的时间差,由此带来的缺陷便是 RL 模型 update 频率被明显拖慢,agent 可能需要上线很久才能达到可用的状态。
在第二步,我们称为“方案 B”,将主要改造 action 与 reward 数据的发送回收环节。方案 A 中的 Kafka 环境实时性不高,在方案 B 中,我们将采用 storm 实现流式处理,从而实现较为实时的 action 发送。在获取 reward 数据时,我们也能够更便捷地匹配到其对应的 action。
这样一来便能够显著提升 agent 学习频次。此外,由于避免了复杂前后端消息同步,算法的调整粒度也能够从城市粒度进一步提升为酒店粒度至用户粒度,从而提升 RL 的潜在效能。
在方案 B 中,我们也将对数据维度做进一步的丰富化。我们当前正在进行对酒店以及用户的 embedding 表征学习,在现有模型的线下测试中取得了一定效果。这些 embedding 维度也将在第二步方案中融合成为 RL 模型的输入维度。
第三步方案 C,我们则会将精力集中在算法的调优上。在解决了数据同步以及粒度问题后,我们打算在方案 C 中尝试不同的 RL 模型,目标是保证效果的前提下,能够用更少的参数量、更少的算法训练时间,以优化整个 RL 部分。
首先考虑可以改进替换的算法为 DDPG。DDPG 为基于 value 的 actor-critic RL 算法。首先来说,由于开销限制,即使使用了流式处理,模型在线更新频次也不能做得非常高,那么同样具有 experience replay 机制的 DDPG 能够更好地实现较高的数据训练效率。此外,DDPG 的 actor 部分可以实现连续值输出,从而能够让控制更为平滑。
方案 A 的 DQN 模型,其输出值是离散的,因而需要人为将参数调整范围进行分段,分段的多少以及每一段区间设置需要人为指定。DDPG 还有其改进算法 TD3,能够进一步稳定 Q 网络输出,缓解 TD error 的大幅度波动。
另一方面,我们可以使用 policy gradient 的算法,例如 A2C,TRPO 等,与前面 value base 的算法进行对比选优。在有一些工作中,提到相比 DDPG,TRPO 等能够减低由于 Q-value 估计的波动带来的不稳定性。但在我们看来,这些 policy base 方法由于其 action 输出存在随机性,对训练数据量的要求可能会更高。
最后,我们也将会考虑尝试基于高斯过程(Gaussian process, GP)的汤普森采样(Thompsonsampling)的算法方案。领英在它的首页混排排序问题中,就应用了这样的构架。
前面提到的一系列 RL 算法都是需要构建深度神经网络(DNN),需要依赖 TensorFlow 或者 PyTorch 来实现。而基于 GP 的方案基本只涉及相对简单的数值计算。当然,作为非参数模型,需要额外空间来存放样本数据。
总结一下我们的 RL 实施规划,主要包含了前期的流程探索,打通流式数据处理并丰富数据维度,以及后期的各种算法尝试及调优这样三个阶段。
五、最后的实践说明,初步探索
现在我们已经完成了方案 A 的实施,通过结果初步说明了 RL 起到了一定的作用。接下来将详细介绍下我们的做法,以及过程中遇到的问题。
整体上 RL 模型将会依据输入数据,调整现有模型的某些重要的权重值。RL 模型的输入值包括了全网比价结果,以及城市粒度的默认排序相关统计维度。
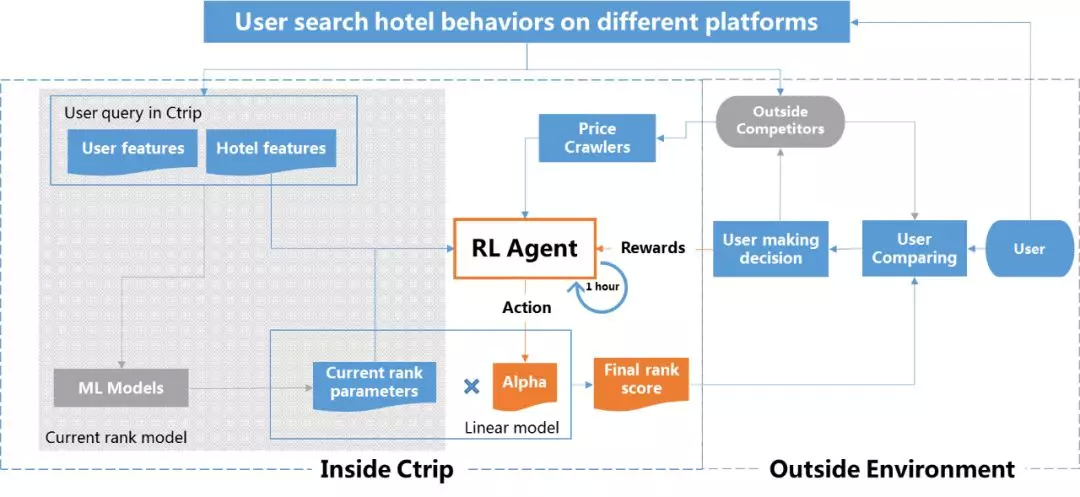
首先,我们定义 agent 的 action 用于调整现有线性排序模型的参数 WBase_model。
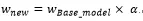
其中,alpha 即为 agent 输出值。
接下来,我们构造 reward 函数为:
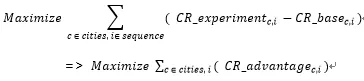
即我们的优化目标为增加了 RL 模型的流量分桶,能够比原模型流量分桶的转化率(CR)更高,也就是最大化 CR 优势。
模型选择及参数设置。在方案 A 中,我们没有对算法选择和参数设置上做太多的调整。值得说明的一点是,我们将 DQN 中 Bellman Equation 更新部分的衰减参数γ设置为 0,意味这我们的优化的目标是一步达成更优的 CR,而不考虑多步马尔科夫决策过程(MDP)。
显然这是一个简化操作,但我们认为在城市粒度上,追求多步 MDP 意义不大,设置γ=0 能够简化模型。当粒度细化到单独一个用户时,考虑 MDP 将更为有价值。
模型调整的粒度。我们前面讲到,方案 A 是按照城市粒度进行参数调整的。当 agent 对某个城市给出一个 action 后,经过一个时间片回收 reward 结果,作为模型的训练依据。考虑城市粒度,主要是为了平衡数据量和同步难度:如果将整个默认排序进行调整,RL 作用的价值有限;而若以更细粒度进行,数据实时同步又会比较困难。
更新时间片长度的设置。模型所需的 reward 反馈依赖于由 Kafka 给出的埋点记录数据,而当时是全业务埋点统一定时处理的,造成 reward 收集存在很大的时间间隔。此外,在模型给出 action 到最终在前端权重更新也存在较大延迟。
为了应对这个问题,我们增加了前端的消息同步,以确保 action 与回收的 reward 能够一一对应。但这并不能改善模型更新频次少、更新延迟的问题。我们原计划是每一个小时进行数据更新,但在极端情况下,模型更新间隔被拉长到了 3 个小时,对模型的效果形成了较大的影响。
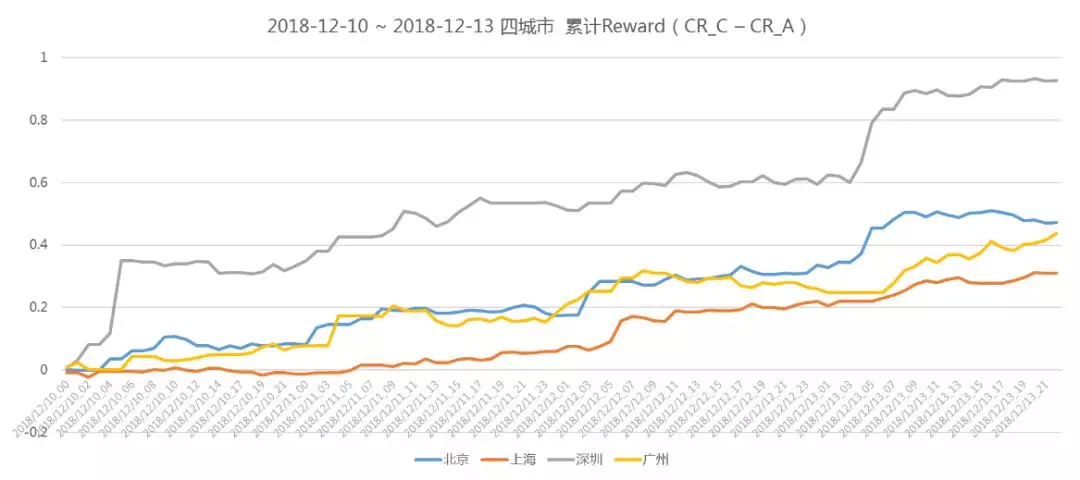
最后,我们来看下线上实验的效果。我们选择了北上广深四个城市观察,发现这四个城市的累积 reward 虽有上下波动,但总趋势为正向增长。但同时也应注意,累积 reward 值绝对数值较小,对其评估还需要更多的实验。
六、总结
我们从传统 L2R 应对探索问题能力不足谈起,介绍了 RL 的背景以及其对这类平衡探索与收益问题的适应性。在此基础上,我们结合排序业务出发,制定了循序渐进的若干 RL 应用方案,以期能够利用 RL 的优点,满足排序业务的需求。
此外,对初步探索中我们的实践与碰到的问题做了详细的讨论,并在最后通过对线上结果实验的分析,说明了 RL 能够起到一定的作用,但还需要更进一步的应用和实验,以加强 RL 能够带来正向作用的结论。
接下来我们将首先对数据处理构架方面进行改进,利用流式处理构架,并尝试探索更为适合算法的以进一步释放 RL 的效能,从而实现更优的排序结果,进一步降低用户费力度、提升用户使用体验。
作者简介
宣云儿,携程酒店排序算法工程师,主要负责酒店排序相关的算法逻辑方案设计实施。目前主要的兴趣在于排序学习、强化学习等领域的理论与应用。
本文转载自公众号携程技术中心(ID:ctriptech)。
原文链接:
https://mp.weixin.qq.com/s/_QkxCrQlyRM10eZK8aNCKA
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论