
业务背景
虽然目前基于 Transformers 架构的自然语言处理模型在各类工业场景落地过程中都表现出了优异的成绩,但其背后所需要的标注数据依然是日常工作中的重点,也是费时费力的瓶颈所在。怎样在我们数据标注过程中降低成本,便成了我们必须面对的问题。主动学习(Active Learning, AL) 便是我们尝试提高标注效率,降低整体标注和训练成本的重要技术手段。
主动学习,一种机器学习方法,是通过一定抽样策略找出对现有模型最有价值的样本数据,经人工标注后加入训练集,再次训练模型并继续以上步骤迭代的流程。简而言之,通过某种挑选方式,减少整体所需的标注数据量,尽快地接近业务需求的标准。
解决方案
常见考量维度:不确定性和多样性
考虑到我们的业务场景,我们这里主要介绍 pool-based 的主动学习方法。在该场景中,我们在一个现有的数据池中通过挑选策略挑选新一批的无标签样本,交给标注人员(oracle)进行标注。

From (Active Learning Literature Survey[5])
主动学习的核心便是挑选策略(查询策略),在 pool-based 下常见的两个策略是不确定性采样和多样性采样。
不确定性采样--What Model knows it doesn't know:

From (Active Learning Literature Survey[5])
一般地,把模型输出概率作为不确定性的衡量依据。有以下三种常见方式:least confident、smallest-margin、entropy。
多样性采样 --What model doesn't know that it doesn't know or the "unknown unknows":

From Human-in-the-Loop Machine Learning[4]
如上图所示,如果使用随机抽样,数据点大概率是从中间最大的聚类簇中获取,通过先聚类,后在聚类簇中抽样,能更大可能性地保证采样数据点的多样性。
通常是抽取尽量与整体分布相似的子集,比如采用聚类簇的方式挑选最具代表性的数据子集。
既要又要,可否?
不确定性和多样性,代表了一个机器学习模型当前的两个重要盲区。而经典的主动学习数据抽取策略,如前文所述的方法,往往只能顾及到一端。那么,这个问题是鱼和熊掌不可兼得的吗?其实并不然。近年来,研究者提出了一些创新性的融合技术方案。一个主流的思路是先把不确定性衡量表达为某种可计算表示(representation),然后基于这种表示进行聚类计算,最后通过纳入更丰富的簇中心点来达到多样性。
其中聚类计算可以采用很多经典的方法,比如 k-means 等。而不确定性的可计算表示(uncertainty representation)是最为关键的。非常有启发性的两个不确定性表示技术是 BADGE 和 ALPS。
ALPS [8]:利用了掩码语言模型的损失函数,MLM loss 的直接输出当作不确定性的表达
其中 BADGE 很巧妙地把梯度作为了不确定性的表示,由此启发了很多后续的工作。而 ALPS 把预训练模型常用的掩码语言模型损失作为不确定性表达,能较好地解决冷启动的问题。
他山之石可以攻玉:通过虚拟对抗扰动来表示不确定性
作业帮的很多业务场景,也需要同时考虑不确定性和多样性,因此我们在实践中也延续了这一思路。
BADGE 和 ALPS 是两个很好的不确定性表示的方案,但不一定符合实践中的一些需求。比如,在很多我们面对的实际场景中,需要模型的鲁棒性比较强,也就是对噪音样本有较好的处理能力。因此,我们需要设计另外的不确定性表示方法。
我们看到,在很多图像处理场景中,会采用虚拟对抗扰动(Virtual Adversarial Perturbation)[6]来增加模型的鲁棒性和泛化能力。于是,我们将其借鉴过来,提出了一个基于虚拟对抗扰动的不确定性表示。具体地,通过针对 BERT 的隐层表达创建其一一对应的虚拟对抗扰动(VAP)来作为样本数据的不确定性表示。相应地,提出了一个新的主动学习方案 VAPAL(Virtual Adversarial Perturbation based Active Learning)。在 VAPAL 中,我们依然是遵循了不确定性学习+聚类的主体思路。
VAPAL 算法流程 [9]:

实验验证
我们在英文数据 PUBMED 和 SST-2 验证了该方案的有效性。

From [9]
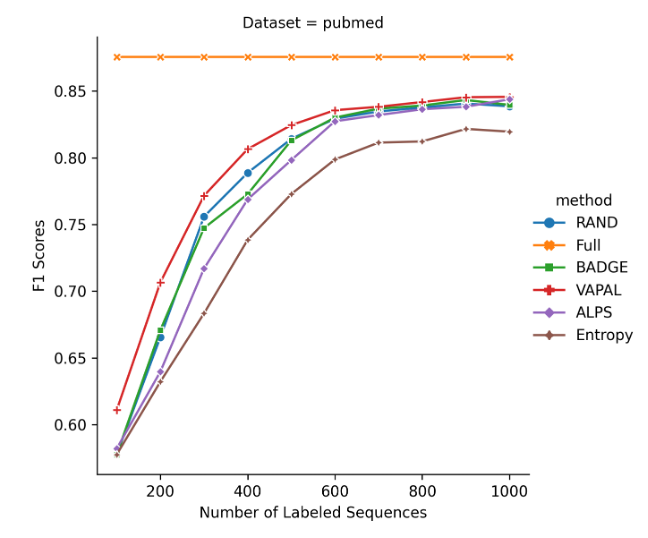
From [9]
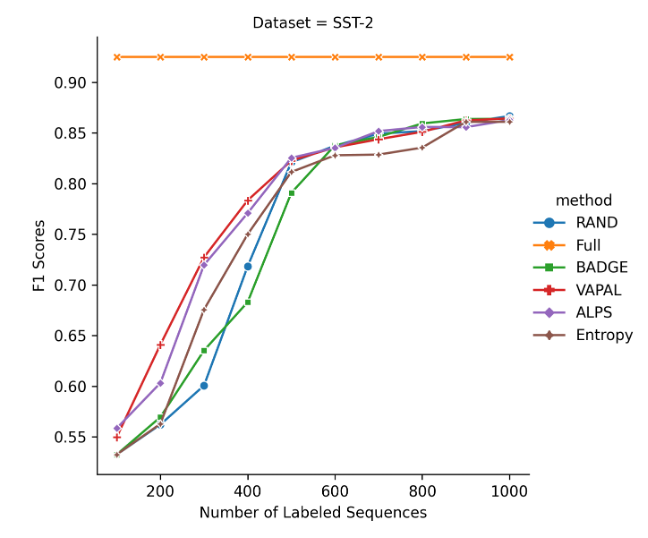
From [9]
实验表明:
在公开数据集上,和现在的主流的 BADGE 以及 ALPS 算法相比,VAPAL 取得了可比性能,是一个强有竞争力的主动学习策略候选。
同时实验数据表明,初始阶段 VAPAL 表现更优,意味着在极端标注资源受限的情况下,VAPAL 更胜任。
VAPAL 相关算法已经集成在作业帮内部自研的人机协同标注平台中。
下图是一个实际标注项目的汇总信息。

从图中可以看出,整个人机协同的标注迭代流程中,通过主动学习抽取的样本,经人工标注后,补充到训练数据后,训出的新模型能更快地符合标注复核人员的要求,从而完成对很多类别的自动扩标,极大地提升标注效率(本例中是 10+倍的效率提升)。
下图是展示了一个同类型同规模任务,分别采用纯人工标注和人机协同主动学习快速标注的项目效果对比。

从图中可以看出:
标注量方面,协同方案提升约 9 倍
产出专题方面,协同方案有助于标注更加精细: 7 个专题到 58 个专题
时间方面:协同方案提效 6 倍以上
机器标注准确率方面:采用抽样人工再确认,准确率为 93.8%
总结
我们从业务需求出发,通过引入主动学习提高了业务的数据标注效率。引入虚拟对抗扰动(VAP),提出了一个和当前最优技术方案可比甚至在初期表现更优秀的新改进方案 VAPAL。在实际使用中,我们发现了现有抽选策略(除了随机之外)都对随机种子有着相对的敏感性,后期我们将在这个方向上更进一步的优化。关于 VAPAL 的详细介绍,可以参见文献[9]。
参考文献:
1.Scheffer, T., Decomain, C., & Wrobel, S. (2001). Active hidden markov models for information extraction. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2189, 309–318. https://doi.org/10.1007/3-540-44816-0_31
2.Ido, D., & Sean P, E. (1995). Committee-Based Sampling For Training Probabilistic Classi ers. MACHINE LEARNING-INTERNATIONAL WORKSHOP THEN CONFERENCE, 150–157. https://doi.org/10.5555/3091622.3091641
3.Culotta, A., & McCallum, A. (2005). Reducing labeling effort for structured prediction tasks. Proceedings of the National Conference on Artificial Intelligence, 2, 746–751.
4.Sampling, C. U., Sampling, D., Regression, L., & Trees, D. (n.d.). Monarch - Human-in-the-Loop Machine Learning_ Active learning and annotation for human-centered AI-Manning.
5.Settles, B. (2009). Active Learning Literature Survey, (January).
6.Miyato, T., Maeda, S. I., Koyama, M., & Ishii, S. (2019). Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(8), 1979–1993. https://doi.org/10.1109/TPAMI.2018.2858821
7.Ash, J. T., Zhang, C., Krishnamurthy, A., Langford, J., & Agarwal, A. (2019). Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds. Retrieved from http://arxiv.org/abs/1906.03671
8.Yuan, M., Lin, H.-T., & Boyd-Graber, J. (2020). Cold-start Active Learning through Self-supervised Language Modeling, 7935–7948. https://doi.org/10.18653/v1/2020.emnlp-main.637
9.Zhang, H., Zhang, Z., Jiang, H., & Song, Y. (2022). Uncertainty Sentence Sampling by Virtual Adversarial Perturbation. Retrieved from http://arxiv.org/abs/2210.14576




