

Rancher 是一个流行的开源企业级 Kubernetes 管理平台,许多组织使用它来管理混合部署的 Kubernetes 集群。Rancher 支持 Amazon Elastic Container Service for Kubernetes (Amazon EKS) ,借助此功能,Rancher 用户可以直接通过 Rancher 平台来对 AWS EKS 进行直接纳管。
Amazon EKS 与 Rancher 结合后,使用方便,可兼具您在 Rancher 中养成的使用习惯与期望从 AWS 获得的功能、可靠性和性能。Amazon 的托管 Kubernetes 解决方案 EKS,可以让您 在云中快速创建可扩展的 Kubernetes 实例,而 Rancher 拥有简洁易用的 UI 和针对 Kubernetes 的更多拓展功能,强强组合将带来企业 Kubernetes 使用的操作体验和性能的极大提升。
不论你是 EKS 和 Rancher 的新手用户,还是对 EKS 或 Rancher 都有所了解、着重关注如何使用开源软件管理 EKS,本文都值得一读。
本文将演示如何使用 Rancher 设置 EKS 集群,部署可公开访问的应用程序来测试集群,以及部署示例项目以使用其他开源软件(例如 Grafana 和 InfluxDB)来跟踪实时地理空间数据。
前期准备
若您将跟随本文进行同步操作,前期您需要拥有:
主机 VM、笔记本电脑或服务器,具有公共 Internet IP 地址,且未屏蔽端口 22、80 和 443。
Docker,已安装在主机 VM、笔记本电脑或服务器上。
一个 AWS 账户,具有访问 Amazon EKS 的足够权限,可参阅此处的详细说明:
https://docs.aws.amazon.com/eks/latest/userguide/EKS_IAM_user_policies.html
满足上述先决条件后,我们可以着手开始第一步:安装 Rancher。
启动 Rancher Docker 容器
在 VM 主机上,发出以下命令,以启动 Rancher 容器(Rancher 版本应等于或高于 2.0):
以上命令应创建一个 Rancher 容器版本 2.16 或更高版本
(https://hub.docker.com/r/rancher/rancher)。
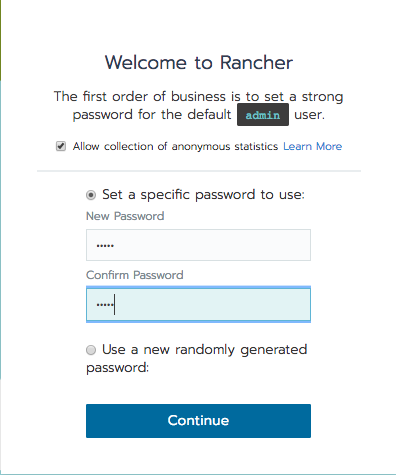
现在将浏览器指向主机的公共 IP;您应该看到一个 Rancher 欢迎页面。请注意,由于 https 采用自签名证书,您可能会收到 cert-authority-invalid 警告。此时请忽略该警告并继续。如果您想完全消除此警告,可以在继续操作之前,按照下述链接说明获得一个有效证书:
https://aws.amazon.com/premiumsupport/knowledge-center/acm-certificate-error-https/
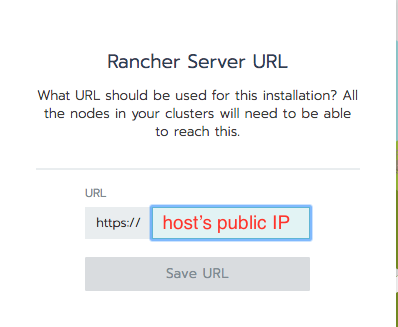
在以下窗口中,键入主机的公共 IP,以便 EKS 可以通知 Rancher 安装进度:
创建 EKS 集群
您首先需要为您的帐户创建密钥凭证。通过转到 IAM > 用户 >(您的用户名)> 安全凭证来执行此操作。
然后单击创建访问密钥;应出现一个像这样的弹出窗口:
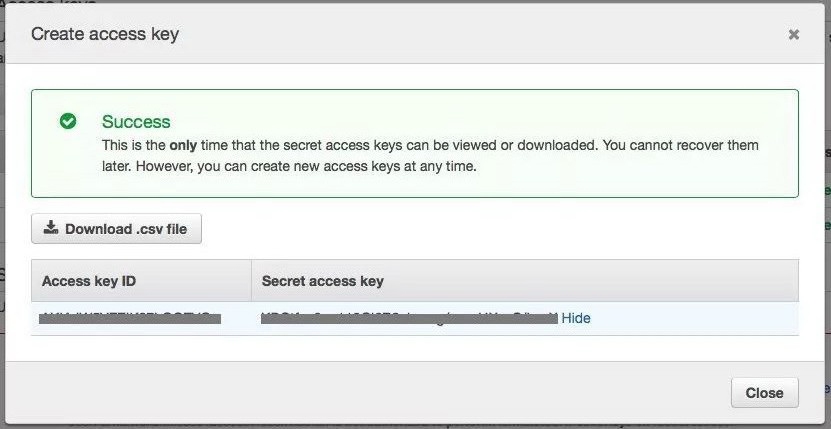
记录访问密钥 ID 和秘密访问密钥;这些是您在 Rancher 中创建 EKS 集群时所需要的。
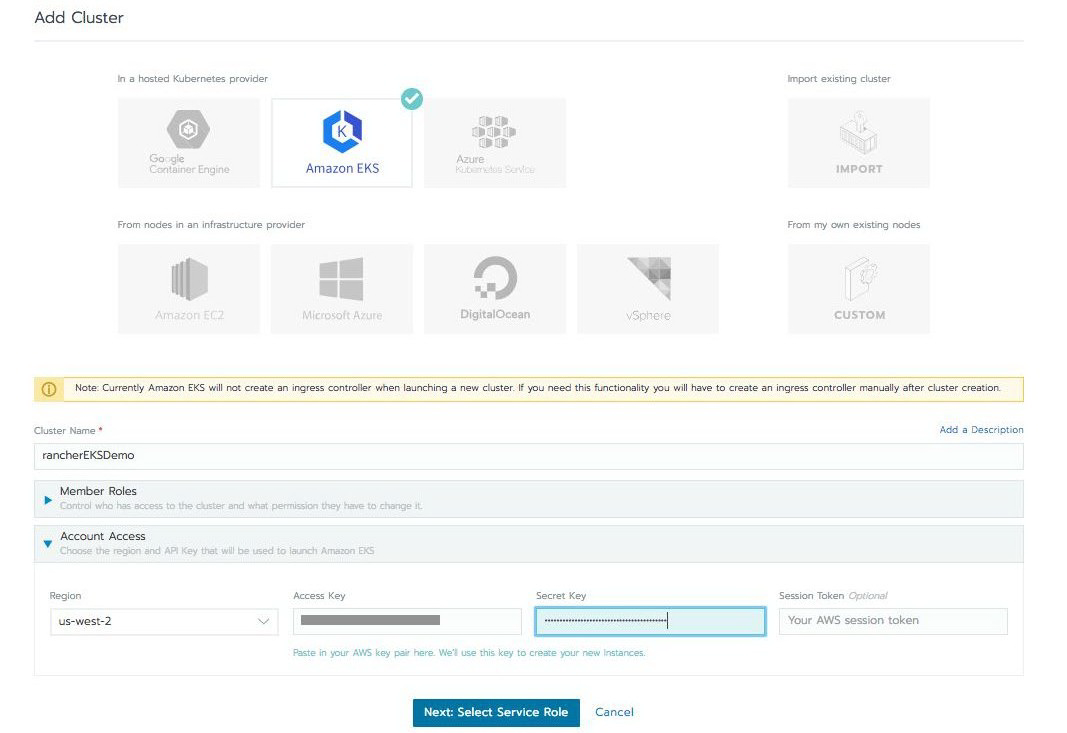
接下来,进入 Rancher 实例,单击添加集群按钮,然后选择 Amazon EKS 选项。现在给集群命名,例如“rancherEKSDemo”,然后输入您在上一步中记录的访问密钥 ID 和秘密访问密钥。
在“区域”下拉菜单中,只有两个区域可供选择:us-east-1 和 us-west-2。(注意,EKS 本身在全球许多地区都可用,请参阅此链接了解详细信息:https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/)选择要部署 EKS 集群的区域,将所有项目设置为默认值,然后单击下一步:选择服务角色。Rancher 将验证您提交的密钥 ID 和密钥是否已获得授权。
在下一个屏幕上,检查 Rancher 生成的“标准”服务角色,然后单击下一步:选择 VPC 和子网。 系统将提示您为工作节点、VPC 和子网选择 IP。只需选择默认值,然后单击下一步:选择实例选项。出于演示目的,选择默认实例类型“m4.large”,并将最小和最大 ASG(自动缩放组)值保留为默认值。验证完成后,单击创建按钮。
创建 EKS 集群需要 10 到 15 分钟;在此期间,您将在控制台上看到集群状态为“预置”。
Rancher 使用 AWS 后端上的 Cloudformation 模板启动安装。您可以通过转到 Cloudformation 控制台来监控这些详细事件,如下面的屏幕截图所示:
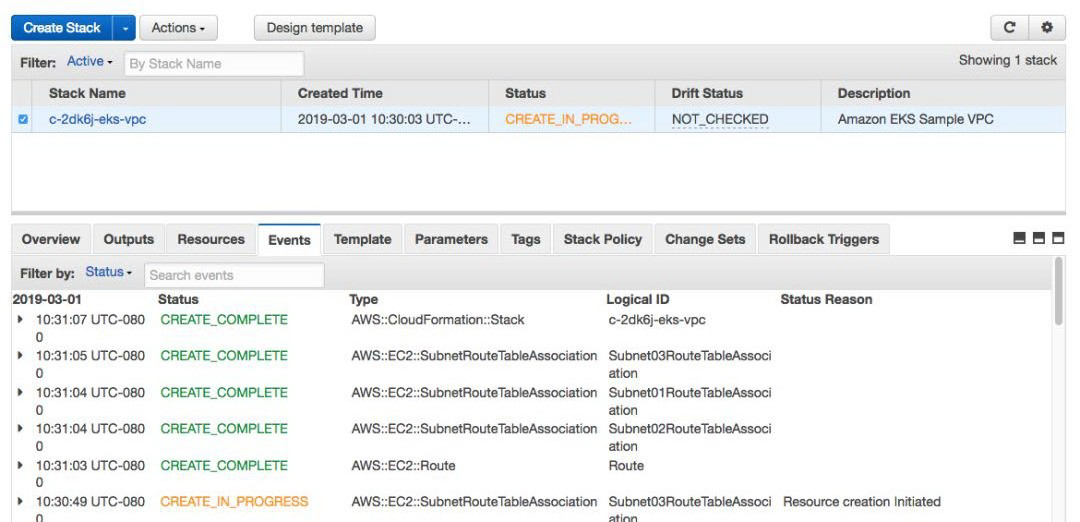
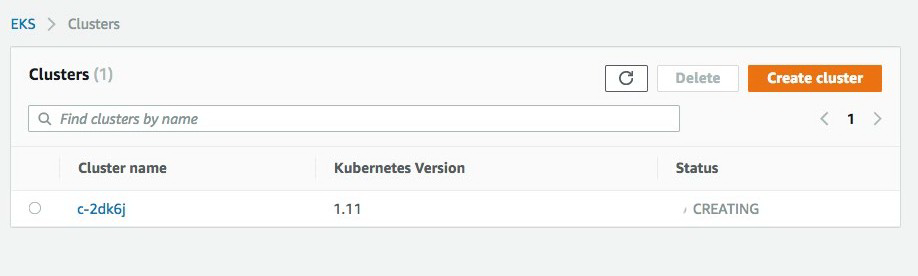
您还可以访问 EKS 控制台,并验证是否正在创建集群,如下列屏幕截图所示:
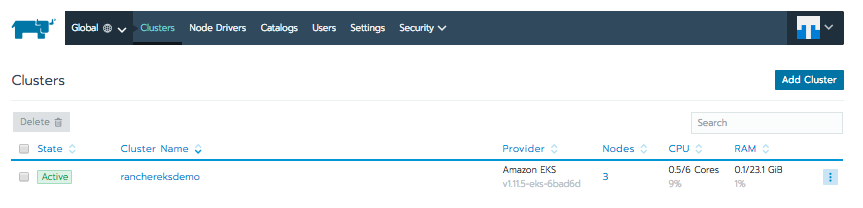
集群完成预置后,您应看到 Rancher 控制台中的状态变为“活动”:
通过部署 nginx Pod 来测试您的 EKS 集群
现在,您可以在集群上部署 Pod/容器了。若要开始体验,请尝试部署 nginx pod。单击位于左上角的下拉菜单,然后选择“默认”项目。
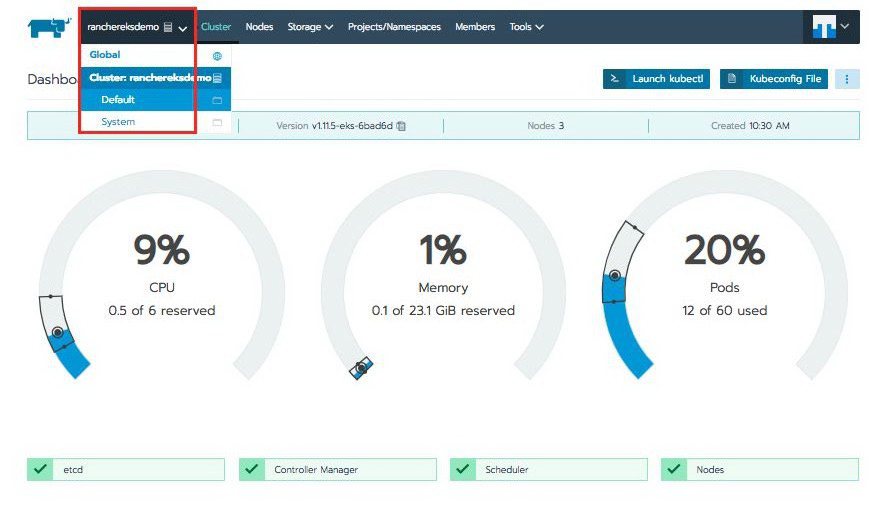
接下来,您将看到工作负载屏幕,单击位于屏幕右上角的部署按钮:
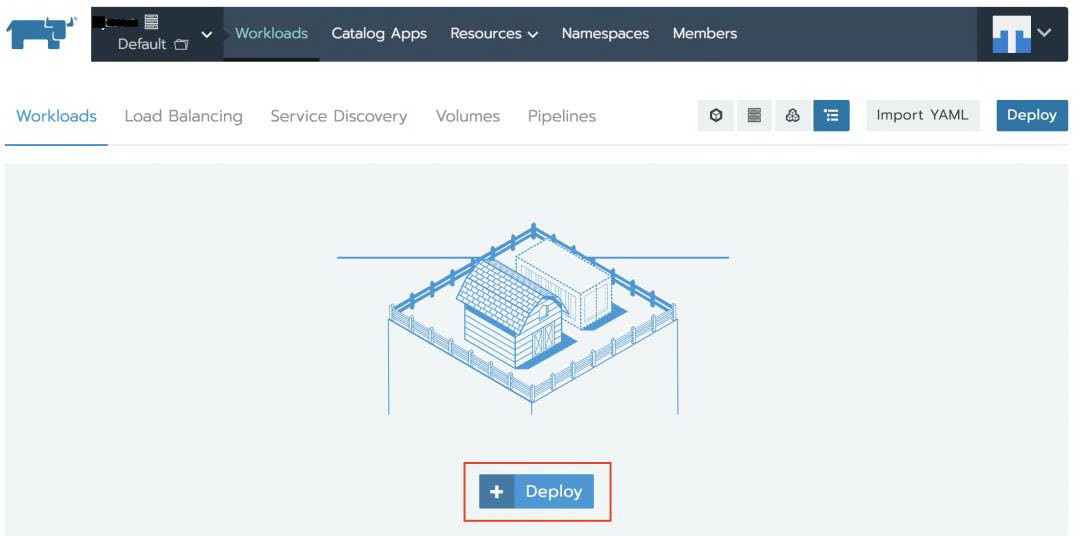
现在给您的工作负载命名并指定“nginx”Docker 映像。单击添加端口,发布容器端口“80”并指定侦听端口“80”,然后指定一个第 4 层负载均衡器。这将允许您通过公共互联网访问您的 nginx 实例。
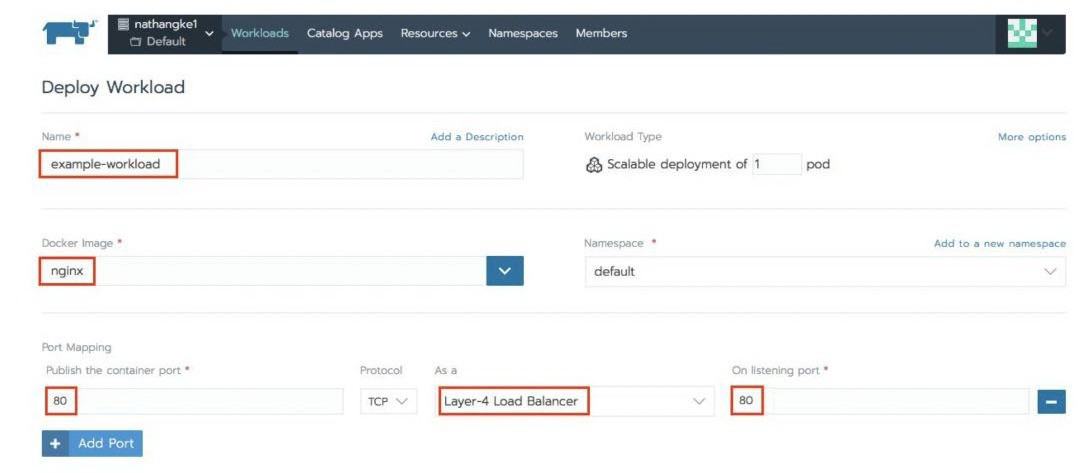
单击启动,等待工作负载和负载均衡器完成预置,方法是检查工作负载和负载均衡选项卡的状态,直至其显示“活动”。
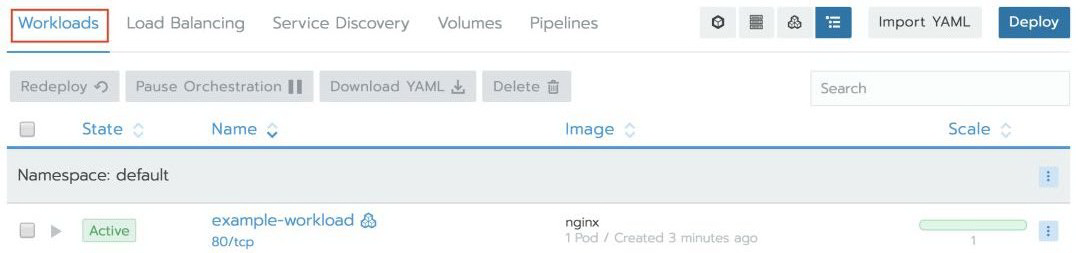
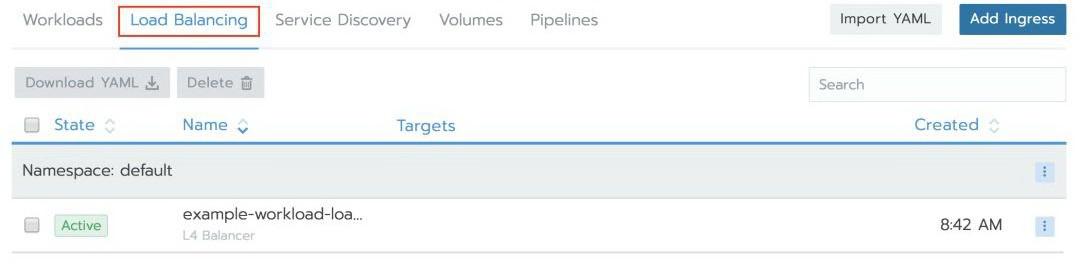
负载均衡器完成预置后,工作负载下方将显示一个可单击的链接。请注意,AWS 将为此 EKS 集群创建 DNS 条目,可能需要几分钟才能完成发布。如果在单击链接后出现 404 错误,请再等几分钟以更新 Elastic Load Balancer DNS 记录,然后重试。
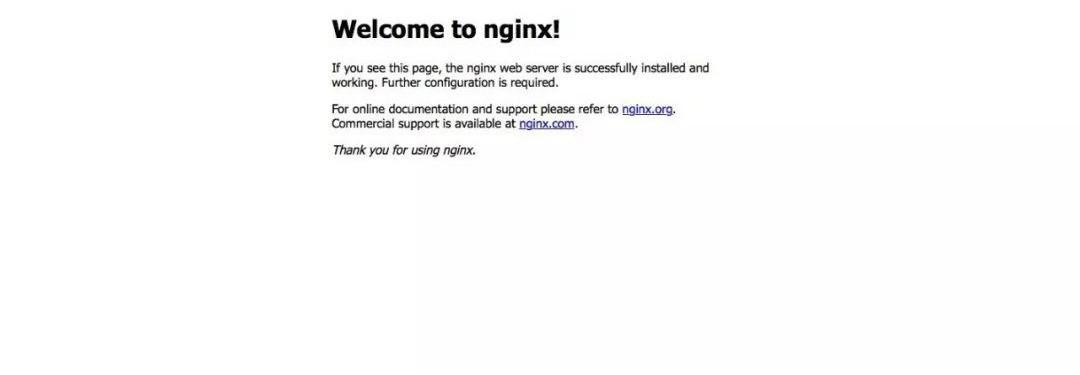
单击链接“80/tcp”应转到默认的 nginx 页面:
扩展您的 nginx 部署
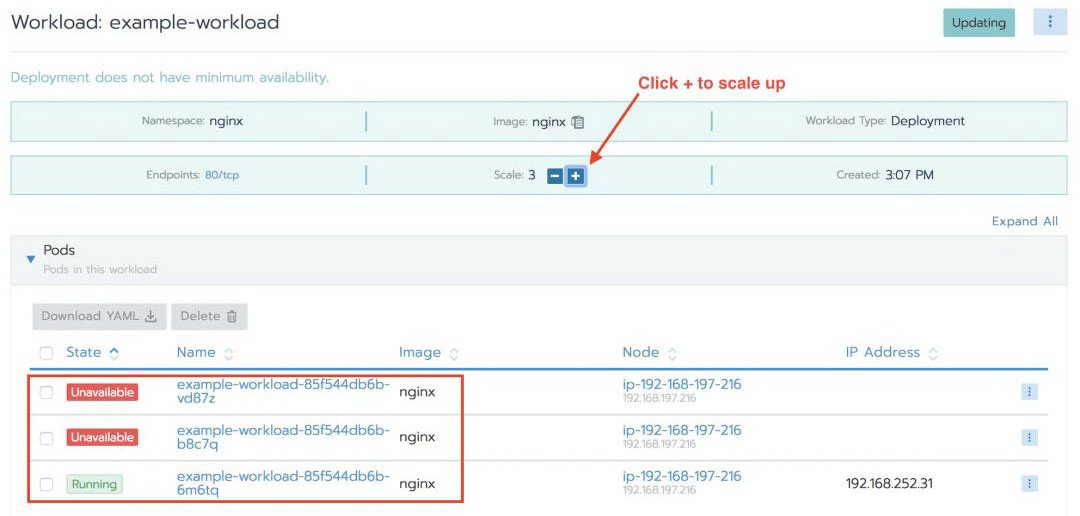
您可以非常轻松地扩展容器数量以适应工作负载高峰。只需在默认项目中选择工作负载,然后单击 +/- 标记,即可扩展和缩减部署以动态调整工作负载:
部署示例项目
下面,让我们通过部署 Rancher 项目来实时跟踪纽约市 Citi Bike 的乘客量,让这个演示更有趣。您将预置三个 Pod:
数据提取 Pod:此 Pod 包含一个脚本,用于定期查询 Citi Bike 发布的 json 格式的实时数据,并通过 API 将其保存到 InfluxDB 数据库。
使用 InfluxDB 的时间序列数据库 Pod:此 Pod 已安装 InfluxDB,用于处理来自 Citi Bike 站点的实时数据。InfluxDB 是一个流行的开源数据库,针对查询和搜索时间序列进行了优化。此外,此 Pod 还具有一个本地安装点,其中 AWS EBS gp2 存储类用于提供存档历史数据所需的持久卷。
Grafana pod:此 Pod 使用 Grafana 显示收集的数据。
下一步是为项目创建 Kubernetes 命名空间。从位于左上角的下拉菜单中选择默认命名空间,然后单击命名空间。单击添加命名空间并键入“ns-citibike”,然后单击创建。
通过选择左上角的下拉菜单返回集群控制台,屏幕截图如下。然后选择启动 kubectl。
在 shell 窗口中,键入“kubectl get nodes -o wide”以查看工作节点状态;它们应全部“准备就绪”。

现在发出以下命令来启动项目:
随意下载脚本以查看所涉及的步骤。我已在脚本中添加了注释供您查看。
等待几分钟,让脚本完成执行。
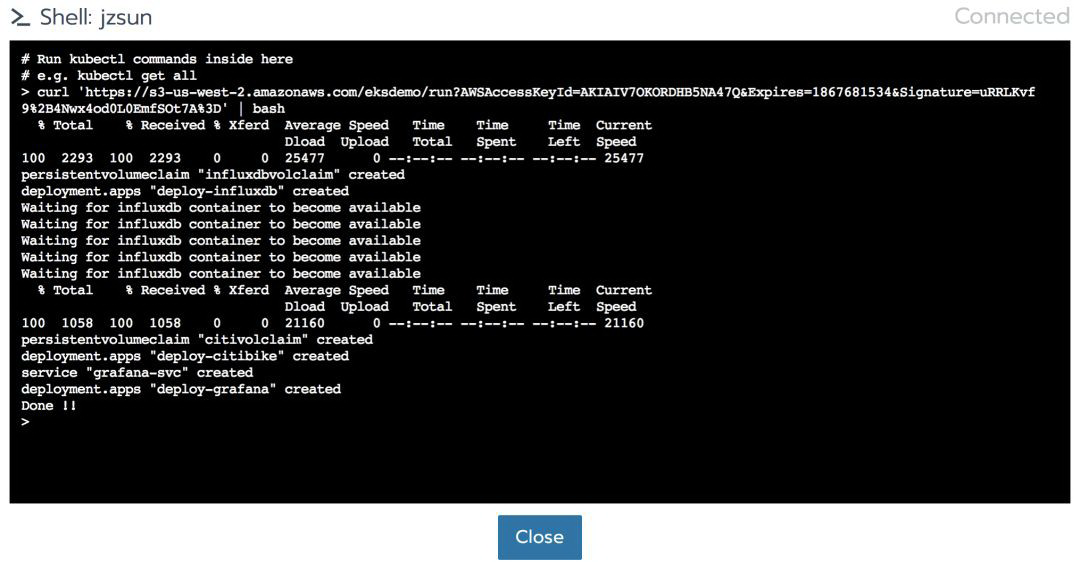
在默认项目中,您应该看到已预置了三个 Pod。再等待几分钟,以便更新负载均衡器的 DNS 记录,然后再单击 80/tcp 转到 Grafana:
在 Grafana 登录页面上,输入“admin”作为用户名并输入“admin”作为密码,然后登录。
现在,您可以配置控制面板以显示数据。
配置数据源
选择左窗格中的齿轮图标,单击数据源, 然后单击 + 添加位于窗口右侧的数据源:
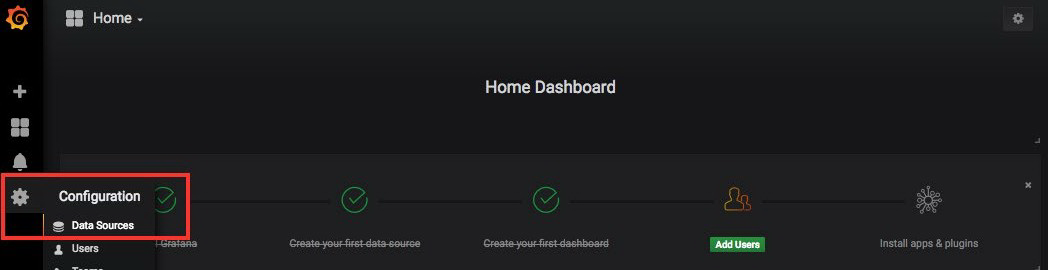
填写数据源的名称(例如 citibike),选择 InfluxDB 作为类型,填写“coordinates”作为数据库名称:
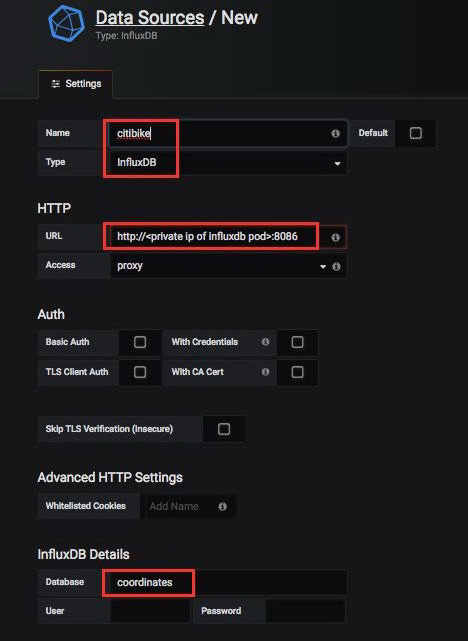
然后,在 URL 字段中,找到 InfluxDB pod 的私有 IP 地址,并填写 http://<ip of influxdb pod>:8086。
您可以通过转到 Rancher 中的默认命名空间页面找到 Influxdb 的私有 IP 地址,然后单击 deploy-Influxdb pod:
单击保存并测试以添加数据源。
导入控制面板模板
下载此控制面板模板并将其保存到桌面:
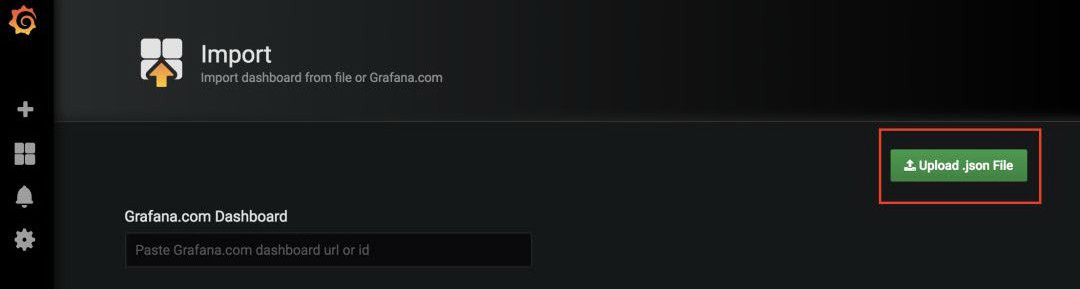
在 Grafana 中,单击左窗格中的 + ,然后选择导入。 单击位于窗口右侧的上传 json 文件,然后选择刚下载到桌面的模板:
现在,您可以开始跟踪整个纽约市每个 Citi Bike 站点的实时状态。您可以选择自行车站点 ID 并查看其历史需求趋势,如折线图所示。您还可以指定一个时间窗口来跟踪某一站点的长期需求趋势。所有站点目前的自行车容量也显示在彩色编码的地图上;绿色表示有超过 30 辆自行车可用,而红色表示自行车数量不足:
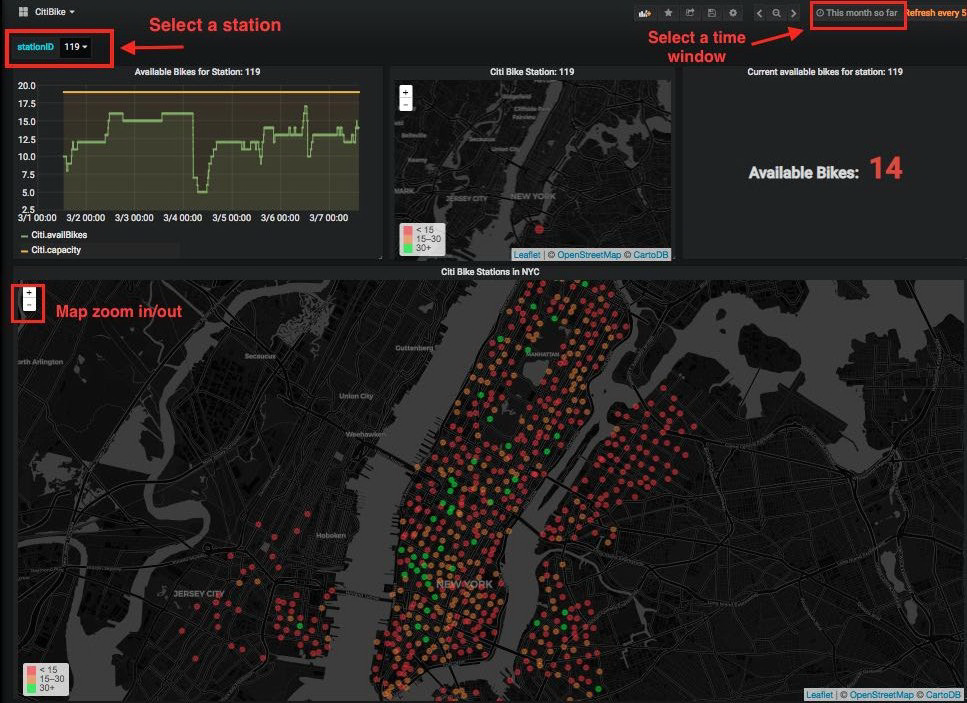
城市规划者可以利用这些信息来增加/缩小自行车站点的容量,以便更好地服务哪些依靠自行车满足日常交通需求的纽约居民。
与 AWS EBS 集成
以满足更大的存储容量需求
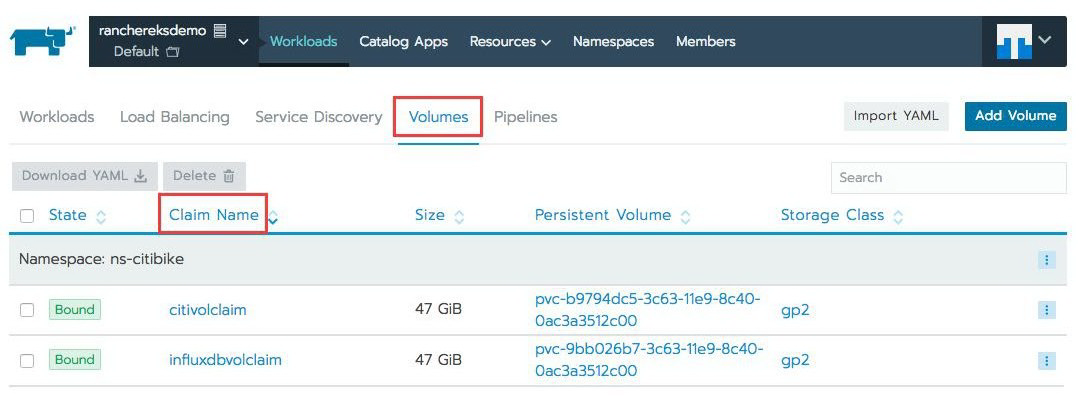
在启动上面的项目命令时,您同时还使用 EBS for InfluxDB 和提取 Pod 中的 gp2 存储类型创建了两个持久卷(每个 50 GB),因为容器的本地存储空间不足以容纳持续流入的数据。若要查看这些持久卷及其持久卷声明,请前往默认命名空间并选择顶部的卷选项卡。
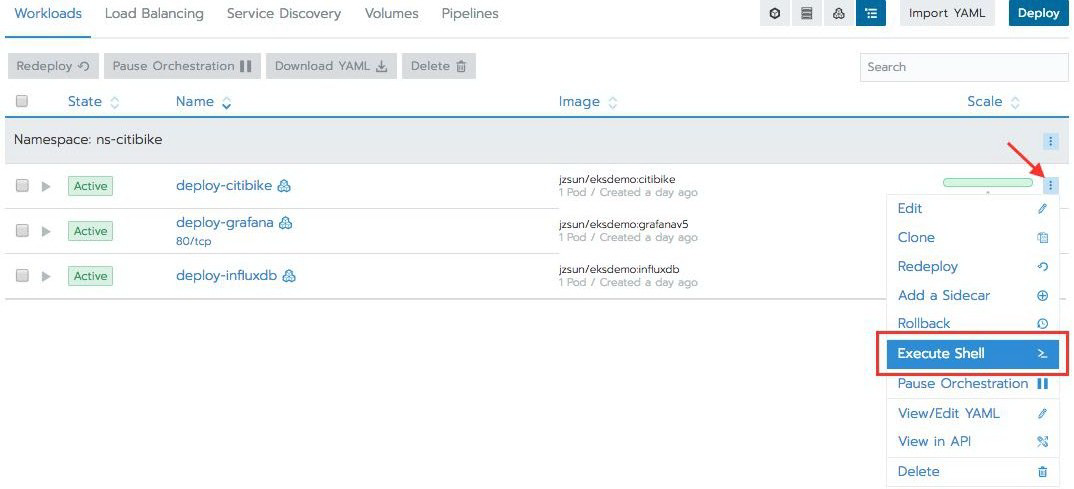
现在,通过单击工作负载选项卡,查看提取 Pod,然后单击位于窗口最右侧的“deploy-citibike”容器的下拉菜单,并选择执行 Shell。
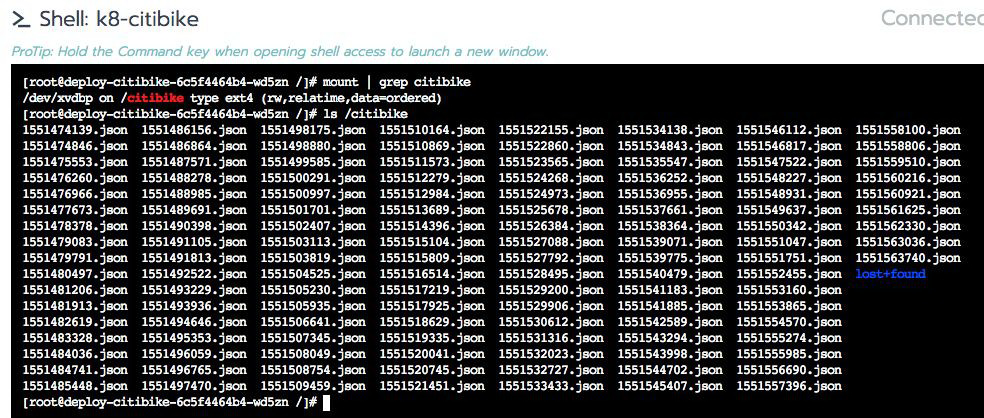
现在您处于容器的 shell 提示下。输入“mount / grep citibike”,您会看到一个卷设备 /dev/xvdxx 安装在带有 ext4 文件系统的 /citibike 上。
制作一个 “ls /citibike” – 您将看到所有原始 json 文件均存档在那里。
结语
在这篇文章中,我们演示了如何使用 Rancher 来创建和管理 EKS 集群,作为实操示例,我们还成功部署了一个示例项目,使用流行的开源工具(容器化的 Grafana 和 InfluxDB),成功跟踪了纽约市 Citi Bike 的实时地理空间数据。
原文链接:
作者简介
James Sun
AWS 解决方案架构师。James 拥有超过 15 年的信息技术行业从业经验。加入 AWS 前,他曾在 MapR、惠普、NetApp、雅虎和 EMC 等公司担任多个高级技术职位。他拥有斯坦福大学博士学位。
本文原发于亚马逊 AWS 官方博客。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论