

并行编程的演化
一个自然而然的问题是:为什么要用并行编程?在 20 世纪 70 年代、80 年代甚至 90 年代的一部分时间里,我们对单线程编程(或者称为串行编程)非常满意。你可以编写一个程序来完成一项任务。执行结束后,它会给你一个结果。任务完成,每个人都会很开心!虽然任务已经完成,但是如果你正在做一个每秒需要数百万甚至数十亿次计算的粒子模拟,或者正在对具有成千上万像素的图像进行处理,你会希望程序运行得更快一些,这意味着你需要更快的 CPU。
在 2004 年以前,CPU 制造商 IBM、英特尔和 AMD 都可以为你提供越来越快的处理器,处理器时钟频率从 16 MHz、20 MHz、66 MHz、100 MHz,逐渐提高到 200 MHz、333 MHz、466 MHz⋯⋯看起来它们可以不断地提高 CPU 的速度,也就是可以不断地提高 CPU 的性能。但到 2004 年时,由于技术限制,CPU 速度的提高不能持续下去的趋势已经很明显了。这就需要其他技术来继续提供更高的性能。CPU 制造商的解决方案是将两个 CPU 放在一个 CPU 内,即使这两个 CPU 的工作速度都低于单个 CPU。例如,与工作在 300 MHz 速度上的单核 CPU 相比,以 200 MHz 速度工作的两个 CPU(制造商称它们为核心)加在一起每秒可以执行更多的计算(也就是说,直观上看 2×200 > 300)。
听上去像梦一样的“单 CPU 多核心”的故事变成了现实,这意味着程序员现在必须学习并行编程方法来利用这两个核心。如果一个 CPU 可以同时执行两个程序,那么程序员必须编写这两个程序。但是,这可以转化为两倍的程序运行速度吗?如果不能,那我们的 2×200 > 300 的想法是有问题的。如果一个核心没有足够的工作会怎么样?也就是说,只有一个核心是真正忙碌的,而另一个核心却什么都不做?这样的话,还不如用一个 300 MHz 的单核。引入多核后,许多类似的问题就非常突出了,只有通过编程才能高效地利用这些核心。
核心越多,并行性越高
程序员不能简单地忽略 CPU 制造商每年推出的更多数量的核心。2015 年,英特尔在市场上推出 8 核台式机处理器 i7-5960X[11]和 10 核工作站处理器,如 Xeon E7-8870 [14]。很明显,这种多核狂热在可预见的未来会持续下去。并行编程从 2000 年年初的一种奇异的编程模型转变为 2015 年唯一被接受的编程模型。这种现象并不局限于台式电脑。在移动处理器方面,iPhone 和 Android 手机都有 2 个或 4 个核。预计未来几年,移动领域的核心数量将不断增加。
那么,什么是线程?要回答这个问题,让我们来看看 8 核 INTEL CPU i7-5960X [11]。 INTEL 的文档说这是一个 8C/16T CPU。换句话说,它有 8 个核心,但可以执行 16 个线程。你也许听到过并行编程被错误地称为多核编程。正确的术语应该是多线程编程。这是因为当 CPU 制造商开始设计多核架构时,他们很快意识到通过共享一些核心资源(如高速缓存)来实现在一个核心中同时执行两项任务并不困难。
类比 1.1:核心与线程
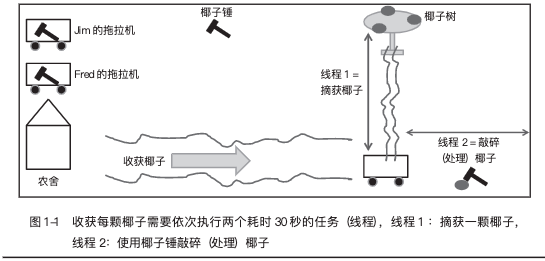
图 1-1 显示了两个兄弟 Fred 和 Jim,他们是拥有两台拖拉机的农民。每天,他们开车从农舍到椰子树所在的地方,收获椰子并把它们带回农舍。他们用拖拉机内的锤子来收获(处理)椰子。整个收获过程由两个独立但有序的任务组成,每个任务需要 30 秒:任务 1 是从拖拉机走向椰子树,每次带回 1 颗椰子。任务 2 是用锤子敲碎(处理)它们,并将它们存放在拖拉机内。Fred 每分钟可以处理 1 颗椰子,而 Jim 每分钟也可以处理 1 颗椰子。综合起来,他们俩每分钟可以处理 2 颗椰子。
一天,Fred 的拖拉机发生了故障。他把拖拉机留在修理厂,并把椰子锤忘在了拖拉机内。回到农舍的时候已经太迟了,但他们仍然有工作要做。只使用 Jim 的拖拉机和里面的 1 把椰子锤,他们还能每分钟处理 2 颗椰子吗?
核心与线程
让我们来看看图 1-1 中描述的类比 1.1。如果收获 1 颗椰子需要完成两个连续的任务(我们将它们称为线程):线程 1 从树上摘取 1 颗椰子并花费 30 秒将它带回拖拉机,线程 2 花费 30 秒用拖拉机内的锤子敲碎(处理)该椰子,这样可以在 60 秒内收获 1 颗椰子(每分钟 1 颗椰子)。如果 Jim 和 Fred 各自都有自己的拖拉机,他们可以简单地收获两倍多的椰子(每分钟 2 颗椰子),因为在收获每颗椰子时,他们可以共享从拖拉机到椰子树的道路,并且他们各自拥有自己的锤子。
在这个类比中,一台拖拉机就是一个核心,收获一颗椰子就是针对一个数据单元的程序执行。椰子是数据单元,每个人(Jim、Fred)是一个执行线程,需要使用椰子锤。椰子锤是执行单元,就像核心中的 ALU 一样。该程序由两个互相依赖的线程组成:在线程 1 执行结束之前,你无法执行线程 2。收获的椰子数量意味着程序性能。性能越高,Jim 和 Fred 销售椰子挣的钱就越多。可以将椰子树看作内存,你可以从中获得一个数据单元(椰子),这样在线程 1 中摘取一颗椰子的过程就类似于从内存中读取数据单元。
并行化更多的是线程还是核心
现在,让我们看看如果 Fred 的拖拉机发生故障后会发生什么。过去他们每分钟都能收获两颗椰子,但现在他们只有一台拖拉机和一把椰子锤。他们把拖拉机开到椰子树附近,并停在那儿。他们必须依次地执行线程 1(Th1)和线程 2(Th2)来收获 1 颗椰子。他们都离开拖拉机,并在 30 秒内走到椰子树那儿,从而完成了 Th1。他们带回挑好的椰子,现在,他们必须敲碎椰子。但因为只有 1 把椰子锤,他们不能同时执行 Th2。Fred 不得不等 Jim 先敲碎他的椰子,并且在 Jim 敲碎后,他才开始敲。这需要另外的 30+30 秒,最终他们在 90 秒内收获 2 颗椰子。虽然效率不如每分钟 2 颗椰子,但他们的性能仍然从每分钟 1 颗提升至每分钟 1.5 颗椰子。
收获一些椰子后,Jim 问了自己一个问题:“为什么我要等 Fred 敲碎椰子?当他敲椰子时,我可以立即走向椰子树,并摘获下 1 颗椰子,因为 Th1 和 Th2 需要的时间完全相同,我们肯定不会遇到需要等待椰子锤空闲的状态。在 Fred 摘取 1 颗椰子回来的时候,我会敲碎我的椰子,这样我们俩都可以是 100%的忙碌。”这个天才的想法让他们重新回到每分钟 2 颗椰子的速度,甚至不需要额外的拖拉机。重要的是,Jim 重新设计了程序,也就是线程执行的顺序,让所有的线程永远都不会陷入等待核心内部共享资源(比如拖拉机内的椰子锤)的状态。正如我们将很快看到的,核心内部的共享资源包括 ALU、FPU、高速缓存等,现在,不要担心这些。
我在这个类比中描述了两个配置场景,一个是 2 个核心(2C),每个核心可以执行一个单线程(1T);另一个是能够执行 2 个线程(2T)的单个核心(1C)。在 CPU 领域将两种配置称为 2C/2T 与 lC/2T。换句话说,有两种方法可以让一个程序同时执行 2 个线程:2C/2T(2 个核心,每个核心都可以执行 1 个线程—就像 Jim 和 Fred 的两台单独的拖拉机一样)或者 lC/2T(单个核心,能够执行 2 个线程—就像 Jim 和 Fred 共享的单台拖拉机一样)。尽管从程序员的角度来看,它们都意味着具有执行 2 个线程的能力,但从硬件的角度来看,它们是非常不同的,这要求程序员充分意识到需要共享资源的线程的含义。否则,线程数量的性能优势可能会消失。再次提醒一下:全能的 INTEL i7-5960X [11] CPU 是 8C/l6T,它有 8 个核心,每个核心能够执行 2 个线程。
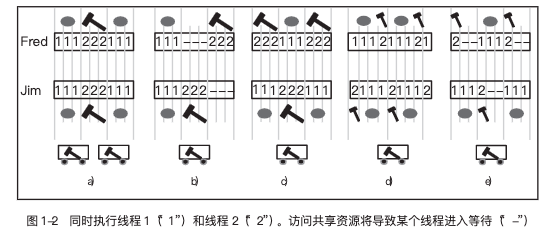
图 1-2 显示了三种情况:a)是具有 2 个独立核心的 2C/2T 情况;b)是具有糟糕编程的 1C/2T 情况,每分钟只能收获 1.5 颗椰子;c)是对椰子锤的需求永远不会同时发生的顺序正确版本,每分钟可以收获 2 颗椰子。
核心资源共享的影响
Jim 为自己的发现感到自豪,他们的速度提高到每分钟 2 颗椰子,Jim 希望继续创造一些方法来用一台拖拉机完成更多的工作。一天,他对 Fred 说:“我买了一把新的自动椰子锤,它在 10 秒内就能敲碎 1 颗椰子。”他们对这一发现非常满意,立即出发并将拖拉机停在椰子树旁。这次他们知道在开始收获前必须先做好计划⋯⋯
Fred 问道:“如果我们的 Th1 需要 30 秒,而 Th2 需要 10 秒,并且我们唯一需要共享资源的任务是 Th2(椰子锤),我们应该如何收获椰子?”答案对他们来说很清楚:唯一重要的是线程的执行顺序(即程序的设计),应确保他们永远不会遇到两人同时执行 Th2 并需要唯一的椰子锤(即共享核心资源)的情况。换句话说,它们的程序由两个互相依赖的线程组成:Th1 需要 30 秒,并且不需要共享(内存)资源,因为两个人可以同时步行到椰子树。Th2 需要 10 秒并且不能同时执行,因为他们需要共享(核心)资源:椰子锤。由于每颗椰子需要 30+10=40 秒的总执行时间,他们能够期望的最好结果是 40 秒收获 2 颗椰子,如
图 1-2 d 所示。如果每个人都按顺序执行 Th1 和 Th2,且不等待任何共享资源,则会发生这种情况。所以,他们的平均速度将是每分钟 3 颗椰子(即每颗椰子平均 20 秒)。
内存资源共享的影响
用新的椰子锤实现了每分钟收获 3 颗椰子后,Jim 和 Fred 第二天开始工作时看到了可怕的一幕。因为昨晚的一场大雨阻塞了半边道路,从拖拉机到椰子树的道路今天只能由一个人通行。所以,他们再次制订计划⋯⋯现在,他们有 2 个线程,每个线程都需要一个不能共享的资源。Th1(30 秒—表示为 30s)只能由一人执行,而 Th2(10s)也只能由一人执行。怎么办?
考虑多种选择后,他们意识到其速度的限制因素是 Th1,他们能达到的最好目标是 30 秒收获 1 颗椰子。当可以同时执行 Th1(共享内存访问)时,每个人可以顺序地执行 10+30s,并且两个人都可以持续运行而无须访问共享资源。但是现在没有办法对这些线程进行排序。他们能够期望的最好结果是执行 10+30s 并等待 20s,因为在此期间两人都需要访问内存。他们的速度回到平均每分钟 2 颗椰子,如图 1-2 e 所示。
这场大雨使他们的速度降低到每分钟 2 颗椰子。Th2 不再重要,因为一个人可以不慌不忙地敲椰子,而另一个人正在去摘取椰子的路上。Fred 提出了这样一个想法:他们应该从农舍再拿一把(较慢)椰子锤来帮忙。然而,这对于此时的情况绝对没有帮助,因为收获速度的限制因素是 Th1。这种来自于某个资源的限制因素被称为资源竞争。这个例子展示了当访问内存是我们程序执行速度的限制因素时会发生什么。处理数据的速度有多快(即核心运行速度)已无关紧要。我们将受到数据获取速度的限制。即使 Fred 有一把可以在 1 秒钟内敲碎椰子的椰子锤,但如果存在内存访问竞争,他们仍然会被限制为每分钟 2 颗椰子。在本书中,我们将区分两种不同类型的程序:核心密集型,该类型不大依赖于内存访问速度;存储密集型,该类型对内存访问速度高度敏感,正如我刚才提到的那样。
第一个串行程序
我们已经理解了椰子世界中的并行编程,现在是时候将这些知识应用于真实计算机编程了。我会先介绍一个串行(即单线程)程序,然后将其并行化。我们的第一个串行程序 imf?lip.c 读入图 1-3(左)中的小狗图片并将其水平(中)或垂直(右)翻转。为了简化程序的解释,我们将使用 Bitmap(BMP)图像格式,并将结果也输出为 BMP 格式。这是一种非常容易理解的图像格式,可以让我们专注于程序本身。不要担心本章中的细节,它们很快就会被解释清楚,目前可以只关注高层的功能。

imflip.c 源文件可以在 Unix 提示符下编译和执行,如下所示:
在命令行中用“H”指定水平翻转图像(图 1-3 中),用“V”指定垂直翻转(图 1-3 右侧)。你将看到如下所示的输出(数字可能不同,取决于你电脑的速度):
运行该程序的 CPU 速度非常快,以致我必须将原始的 640×480 的图像 dog.bmp 扩展为 3200×2400 的 dogL.bmp,这样它的运行时间才能被测量出来;dogL.bmp 的每个维度扩大到原来的 5 倍,因此比 dog.bmp 大 25 倍。统计时间时,我们必须在图像翻转开始和结束时记录 CPU 的时钟。
理解数据传输速度
从磁盘读取图像的过程(无论是 SSD 还是硬盘驱动器)应该从执行时间中扣除,这很重要。换句话说,我们从磁盘读取图像,并确保它位于内存中(在我们的数组中),然后只统计翻转操作所需的时间。由于不同硬件部件的数据传输速度存在巨大差异,我们需要分别分析在磁盘、内存和 CPU 上花费的时间。
在本书将要编写的众多并行程序中,我们重点关注 CPU 执行时间和内存访问时间,因为我们可以控制它们。磁盘访问时间(称为 I/O 时间)通常在单线程中就达到极限,因而几乎看不到多线程编程的好处。另外,请记住,当我们开始 GPU 编程时,较慢的 I/O 速度会严重困扰我们,因为 I/O 是计算机中速度最慢的部分,并且从 CPU 到 GPU 的数据传输要通过 I/O 子系统的 PCI express 总线进行,因此我们将面临如何将数据更快地提供给 GPU 的挑战。没有人说 GPU 编程很容易!为了让你了解不同硬件部件的传输速度,我在下面列举了一些:
典型的网卡(NIC)具有 1 Gbps 的传输速度(千兆比特每秒或一亿比特每秒)。这些卡俗称“千兆网卡”或“Gig 网卡”。请注意,1 Gbps 只是“原始数据”的数量,其中包括大量的校验码和其他同步信号。传输的实际数据量少于此数量的一半。我的目的是给读者一个大致的概念,这个细节对我们来说并不重要。
即使连接到具有 6 Gbps 峰值传输速度的 SATA3 接口,典型的硬盘驱动器(HDD)也几乎无法达到 1 Gbps〜2 Gbps 的传输速度。HDD 的机械读写性质根本不能实现快速的数据访问。传输速度甚至不是硬盘的最大问题,最大问题是定位时间。HDD 的机械磁头需要一段时间在旋转的金属柱面上定位需要的数据,这迫使它在磁头到达数据所在位置前必须等待。如果数据以不规则的方式分布(即碎片式的存放),则可能需要毫秒(ms)级的时间。因此,HDD 的传输速度可能远远低于它所连接的 SATA3 总线的峰值速度。
连接到 USB 2.0 端口的闪存磁盘的峰值传输速度为 480 Mbps(兆比特每秒或百万比特每秒)。但是,USB 3.0 标准具有更快的 5 Gbps 传输速度。更新的 USB 3.1 可以达到 10 Gbps 左右的传输速率。由于闪存磁盘使用闪存构建,它不需要查找时间,只需提供地址即可直接访问数据。
典型的固态硬盘(SSD)可以连接在 SATA3 接口上,达到接近 4 Gbps〜5 Gbps 的读取速度。因此,实际上 SSD 是唯一可以达到 SATA3 接口峰值速度的设备,即以预期的 6 Gbps 峰值速率传输数据。
一旦数据从 I/O(SDD、HDD 或闪存磁盘)传输到 CPU 的内存中,传输速度就会大大提高。已发展到第 6 代的 Core i7 系列(i7-6xxx),更高端的 Xeon CPU 使用 DDR2、DDR3 和 DDR4 内存技术,内存到 CPU 的传输速度为 20 GBps〜60 GBps(千兆字节每秒)。注意这个速度是千兆字节。一个字节有 8 个比特,为与其他较慢的设备进行比较,转换为存储访问速度时为 160 Gbps〜480 Gbps(千兆比特每秒)。
正如我们将在第二部分及以后所看到的,GPU 内部存储器子系统的传输速度可以达到 100 GBps〜1000 GBps。例如,新的 Pascal 系列 GPU 就具有接近后者的内部存储传输速率。转换后为 8000 Gbps,比 CPU 内部存储器快一个数量级,比闪存磁盘快 3 个数量级,比 HDD 快近 4 个数量级。
imflip.c 中的 main( )函数
代码 1.1 中所示的程序会读取一些命令行参数,并按照命令行参数垂直或水平地翻转输入图像。命令行参数由 C 放入 argv 数组中。
clock( )函数以毫秒为单位统计时间。重复执行奇数次(例如 129 次)操作可以提高时间统计的准确性,操作重复次数在"#define REPS 129"行中指定。该数字可以根据你的系统更改。
ReadBMP( )函数从磁盘读取源图像,WriteBMP( )将处理后的(即翻转的)图像写回磁盘。从磁盘读取图像和将图像写入磁盘的时间定义为 I/O 时间,我们从处理时间中去除它们。这就是为什么我在实际的图像翻转代码之间添加"start = clock( )"和"stop = c1ock( )"行,这些代码对已在内存中的图像进行翻转操作,因此有意地排除了 I/O 时间。
在输出所用时间之前,imf?lip.c 程序会使用一些 free( )函数释放所有由 ReadBMP( )分配的内存以避免内存泄漏。
代码 1.1:imflip.c 的 main( ){⋯}
imflip.c 中的 main( )函数读取 3 个命令行参数,用以确定输入和输出的 BMP 图像文件名以及翻转方向(水平或垂直)。该操作会重复执行多次(REPS)以提高计时的准确性。


垂直翻转行:FlipImageV( )
代码 1.2 中的 FlipImageV( )遍历每一列,并交换该列中互为垂直镜像的两个像素的值。有关 Bitmap(BMP)图像的函数存放在另一个名为 ImageStuff.c 的文件中,ImageStuff.h 是对应的头文件,我们将在下一章详细解释它们。图像的每个像素都以“struct Pixel”类型存储,包含 unsigned char 类型的该像素的 R、G 和 B 颜色分量。由于 unsigned char 占用 1 个字节,所以每个像素需要 3 个字节来存储。
ReadBMP( )函数将图像的宽度和高度分别放在两个变量 ip.Hpixels 和 ip.Vpixels 中。存储一行图像需要的字节数在 ip.Hbytes 中。FlipImageV( )函数包含两层循环:外层循环遍历图像的 ip.Hbytes,也就是每一列,内层循环一次交换一组对应的垂直翻转像素。
代码 1.2:imflip.c ⋯FlipImageV( ){⋯}
对图像的行做垂直翻转,每个像素都会被读取并替换为镜像行中的相应像素。


水平翻转列:FlipImageH( )
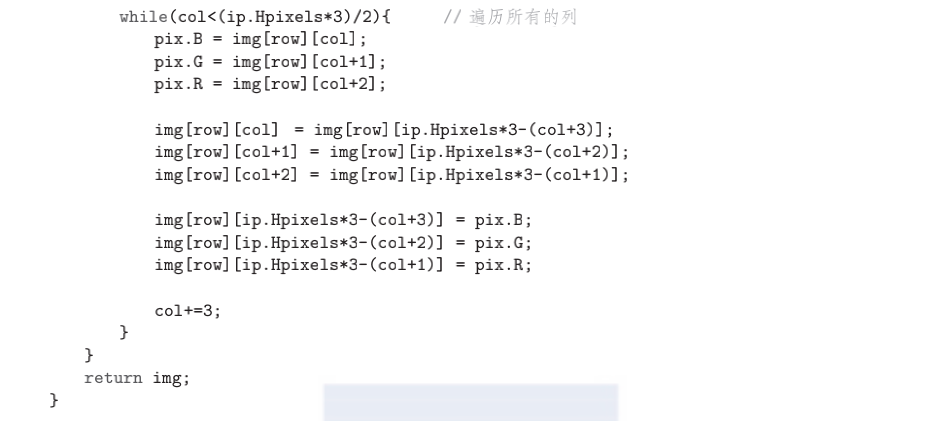
imf?lip.c 的 FlipImageH( )实现图像的水平翻转,如代码 1.3 所示。除了内层循环相反,该函数与垂直翻转的操作完全相同。每次交换使用“struct Pixel”类型的临时像素变量 pix。
由于每行像素以 3 个字节存储,即 RGB、RGB、RGB⋯⋯因此访问连续的像素需要一次读取 3 个字节。这些细节将在下一节介绍。现在我们需要知道的是,以下几行代码:
只是读取位于垂直的第 row 行和水平的第 col 列处的一个像素。像素的蓝色分量在地址 img[row][col]处,绿色分量在地址 img[row][col+1]处,红色分量在 img[row][col+2]处。在下一章中我们将看到,指向图像起始地址的指针 img 由 ReadBMP( )为其分配空间,然后由 main( )传递给 FlipImageH( )函数。
代码 1.3:imflip.c FlipImageH( ){⋯}
进行水平翻转时,每个像素都将被读取并替换为镜像列中相应的像素。

本文内容来自作者图书作品《基于 CUDA 的 GPU 并行程序开发指南》,点击购买。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论