

什么是自注意力机制?
2017 年,谷歌发表了一篇名字叫做《Attention Is All You Need》的论文,该论文提出了基于注意力机制的来处理序列模型的问题,可以改变 RNN 模型训练慢的弊端,并且在 11 个 NLP 任务中取得了最优结果。那么,我们要认识 Transformer 模型,首先应该了解什么是注意力机制。
通俗的来讲,当我们在看一样东西的时候,我们的注意力一定是在当前正在看的这个东西的某一个地方,换句话说,当我们的目光转移到别处时,我们的注意力也在随之转移。将这个东西换成我们当前存在的一个场景中,那么在这个场景中每一处位置上的注意力分布是不均匀的。因此,注意力机制就是在模型中模拟人的这种注意力,去学习不同空间或者是局部重要性,然后将这些重要性结合起来。
自注意力机制也叫做内注意力,是将一个序列中的不同位置联系起来,计算序列的表示的机制。假设我们要将一个英文句子翻译为中文:Tom can’t play with Jerry because he has to move。那么在这句话中,“he”指的是 Tom 还是 Jerry 呢?我们人类可以很快的回答这个问题,但是机器不能,这个时候就需要用到自注意力机制。当我们构建的模型处理“he”这个单词的时候,自注意力机制会允许“he”与“Tom”建立联系,帮助模型对这个单词更好的进行编码。
当我们了解了自注意力机制以后,我们就来拆解分析它的计算方式。在论文中,作者将自注意力机制解释为“按比例缩放的点积注意力”,可以看出,整个注意力机制的计算过程是通过“点积(乘积)”的方式完成的。
自注意力的计算步骤:
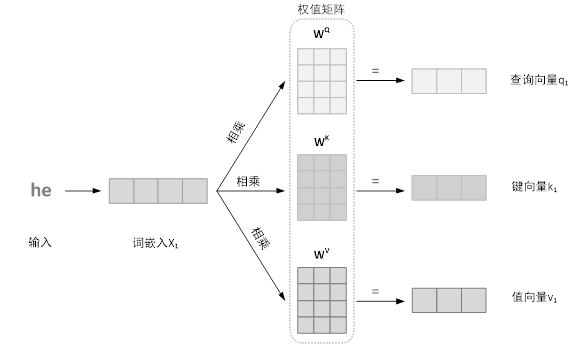
(1)将每个单词词向量生成三个向量,分别为:查询向量,键向量和值向量,这三个向量是通过词嵌入与三个权值矩阵相乘得到的。具体计算过程如下图所示:
(2)计算得分。得到每个单词的查询向量、键向量以及值向量以后,需要拿每个单词对当前处理的单词进行打分,即计算两个单词之间的相关性。该步骤通过当前单词的查询向量与其他单词的键向量相点积完成。
(3)将上一步得到的分数除以键向量维数的平方根(论文中使用了 8),使得梯度更稳定,然后通过 softmax 函数传递结果,即将所有单词的分数归一化。
(4)将上一步得到的结果分别乘以值向量,通过这一步来弱化不相关的单词。
(5)将上一步骤的计算结果进行求和,得到自注意力层在当前位置(即当前关注的单词)的输出。
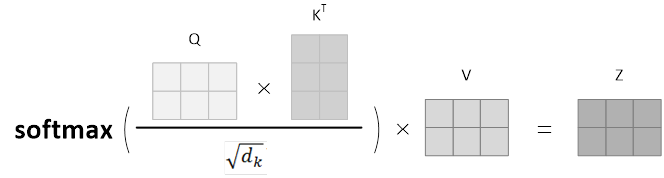
将上述步骤通过矩阵计算,计算公式如下图所示,Q 矩阵中的每一行代表一个句子中每一个单词的查询矩阵,以此类推,Z 矩阵就是自注意力层的输出形式。
初识 Transformer 模型
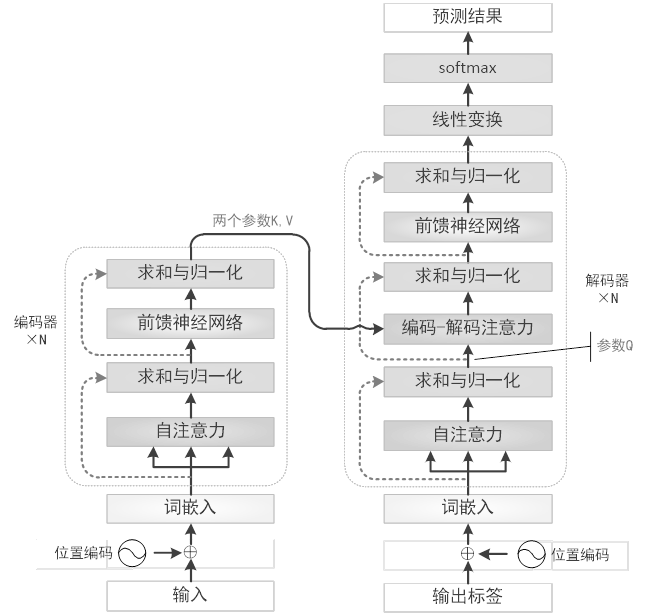
我们在上一节中已经了解了什么是自注意力机制,Transformer 是第一个完全依赖自注意力机制计算输入和输出表示的转换模型,因此我们在这一节来深入了解一下 Transformer 模型。如果将 Transformer 模型看做一个黑盒,那么机器翻译任务就可以解释为输入一种语言,经过 Transformer 模型输出为另一种语言。将这个黑盒拆开来看,里面包括了编码组件和解码组件,以及这两个组件之间的交互。编码组件由一堆编码器构成,解码组件由相同数量的解码器组成。
所有的编码器的结构都是一样的,可以分为自注意力层和前馈神经网络层。输入单词 x 经过自注意力层输出 z,然后将 z 作为前馈神经网络的输入,以此类推。解码器与编码器结构类似,但是在自注意力层和前馈神经网络层之间多了编码-解码注意力层,在这一层中,查询向量来自于前一个解码器层的输出,键向量和值向量来自于编码器的输出,这使得解码器中的每个位置都可以参与输入序列中的所有位置。
另外在 Transformer 结构中,还有几个细节需要注意:
(1)残差连接。在编码器和解码器的每一个子层之间,都存在一个残差连接,并且跟随一个“归一化”层。
(2)位置编码。在 NLP 问题中,每一句话的单词输入顺序很重要,因此,Transformer 在词嵌入中添加了一个位置向量,通过使用不同频率的正弦余弦函数来获得单词的绝对或者相对位置信息。
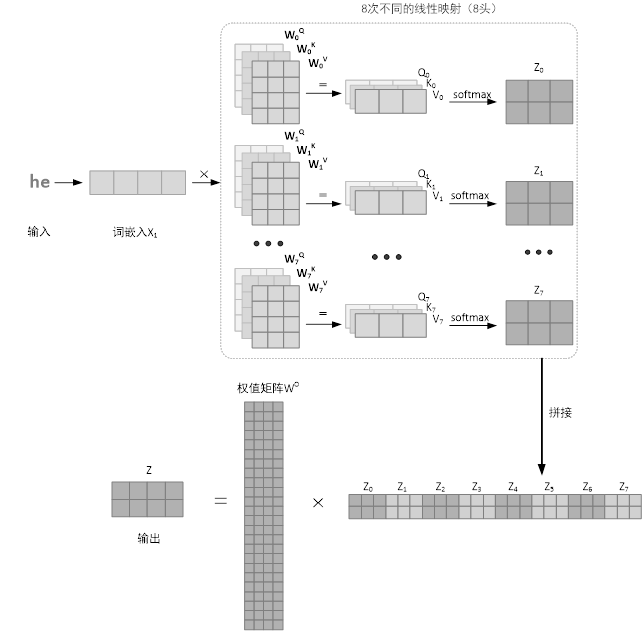
在 Transformer 模型中,作者引入了“多头”注意力。在上一节中,我们已经了解了单层注意力机制,但是论文作者发现对查询向量、键向量以及值向量进行 h 次不同的线性映射效果特别好,因此提出了“多头”注意力机制。多头注意力机制就是将学习到的线性映射分别映射到 d_k、d_k 和 d_v 维,对每个映射之后得到的查询向量、键向量以及值向量进行自注意力函数的并行操作,得到了 d_v 维的输出。输出的矩阵与附加权重 W^O 相乘,得到压缩后的矩阵,该矩阵中融合了所有注意力头信息。用图来表示计算过程,如图所示。
多头注意力机制主要提高了两个方面的性能:首先它扩展了模型对于不同位置的专注能力,比如我们在本节一开始提出的问题,“he”指的是 Tom 还是 Jerry。第二个方面是它给出了注意力层的多个“表示子空间”,即每个单词可以映射要不同的表示子空间中。
如下图所示,为 Transformer 的整体框架图。
进化的 Transformer 结构
2019 年,谷歌提出了一种新的思想:利用神经架构搜索的方法找到最好的 Transformer 架构。因此,提出了基于进化算法的 Transformer 架构搜索算法。首先根据前馈序列模型的最新进展构建一个大的搜索空间,然后使用进化算法进行架构的搜索,用 Transformer 模型来初始化种群。下面,我们将分搜索空间和搜索算法两个方面介绍该框架。
1. 搜索空间
在该问题中,搜索空间是由两个可堆叠的单元组成的(如图 12-15 所示),一个是编码器,一个是解码器,编码器包含六个块,解码器包含八个块。每个块包含两个分支,每个分支都接受前面的隐藏层作为输入,然后对其应用归一化、卷积层(具有指定的相对输出维度)和激活函数。然后,这两个分支通过组合函数连接起来。任何未使用的隐藏状态都会通过加法自动添加到最后的块输出中。以这种方式定义的编码器和解码器单元均重复其相应的单元数次,并连接到网络的输入和输出嵌入部分,生成最终的模型。
我们的搜索空间包含五个分支级搜索字段(input, normalization, layer, output dimension and activation)、一个块级搜索字段(combiner function)和一个单元级搜索字段(number of cells)。
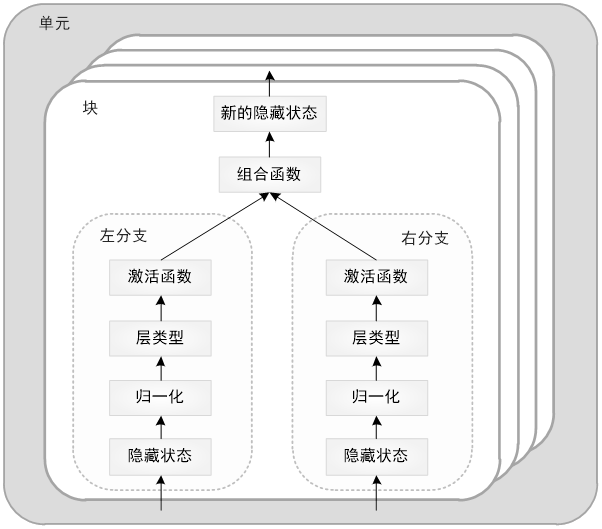
下面我们分别介绍这些基因(参数)。
Input
指定单元中的隐藏状态将作为输入提供给分支。对于每个第 i 个块,其分支的输入选项为[0,i),其中第 j 个隐藏状态对应于第 j 个块输出,第 0 个隐藏状态为单元格输入。
Normalization
归一化层,在应用层转换之前应用于每个输入。提供两个选项[LAYER normalization, NONE]。一般选择前一个字段。
Layer
规范化后应用的神经网络层。
它提供的选项包括:
标准卷积 w×1,w∈{1,3}
深度可分离卷积 w×1,w∈{3,5,7,9,11}
轻量卷积 w×1 r ,w∈{3,5,7,15},r∈{1,4,16}.r 是缩减因子,相当于 d⁄H。
h 头注意力层:h∈{4,8,6}
门控线性单元
参与编码器(解码器专用)
恒等式:不对输入进行转换
死分支:没有输出
对于解码器卷积层,输入偏移 w-1⁄2,以便当前位置无法“看到”后面的预测。
Relative Output Dimension
相对输出维度,它描述了相应图层的输出维度。该参数解释了可变的输出深度,可选字段包括 10 个相对输出大小:[1,10]
Activations
激活函数,即在神经网络层之后对每个分支应用非线性激活函数。激活函数包括{SWISH, RELU, LEAKY RELU, NONE}。
Combiner Functions
块级搜索字段组合函数描述了如何将左层和右层分支组合在一起。它的选项包括{ADDITION,CONCATENATION,MULTIPLICATION}。对于 MULTIPLICATION 和 ADDITION,如果右和左分支输出具有不同的嵌入深度,那么填充两者中的较小者以使维度匹配。对于 ADDITION,填充为 0,对于 MULTIPLICATION,填充是 1。
Number of Cells
单元级搜索字段是单元数,它描述了单元重复的次数。它的选项是[1,6]。
因此,在搜索空间中,子模型的基因编码表示为:[left input, left normalization, left layer, left relative output dimension, left activation, right input, right normalization, right layer, right relative output dimension, right activation, combiner function]×14 + [number of cells]×2。
2. 搜索策略
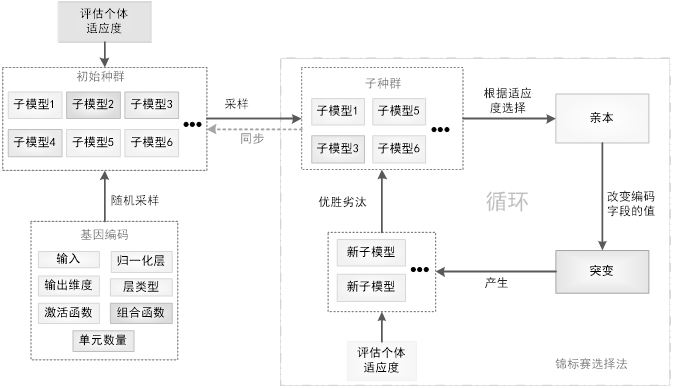
在该框架中,使用锦标赛选择进化搜索策略,首先定义描述神经网络架构的基因编码;然后,从基因编码空间中随机采样来创建个体从而创建一个初始种群。基于这些个体在目标任务上描述的神经网络的训练为它们分配适应度(fitness),再在任务的验证集上评估它们的表现。然后,研究者对种群进行重复采样,以产生子种群,从中选择适应度最高的个体作为亲本(parent)。被选中的亲本使自身基因编码发生突变(编码字段随机改变为不同的值)以产生子模型。然后,通过在目标任务上的训练和评估,像对待初始种群一样为这些子模型分配适应度。当适应度评估结束时,再次对种群进行抽样,子种群中适应度最低的个体被移除,也就是从种群中移除。然后,新评估的子模型被添加到种群中,取代被移除的个体。这一过程会重复进行,直到种群中出现具备高度适应度的个体。
具体搜索过程如下图所示:
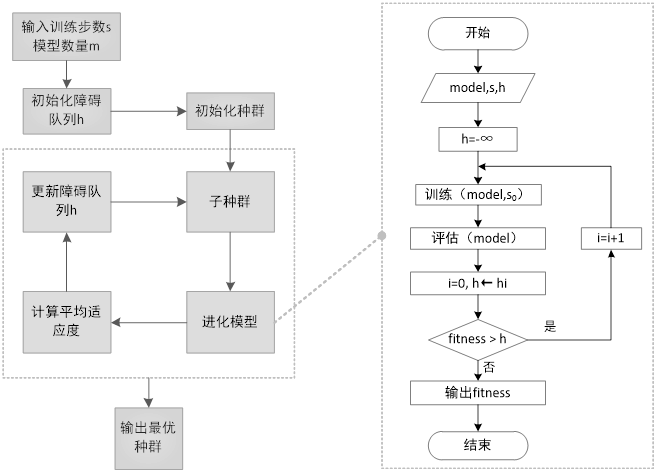
由于进化算法的搜索需要很大的时间代价,为了加快搜索过程,论文作者在锦标赛选择法的基础上提出了一种渐进动态障碍(PDH)优化策略,根据资源的适用性将资源动态分配给更有前景的架构。该算法首先训练子模型固定数量的 s0 步,并在验证集上进行评估以生成适应度,作为基线适应度,与障碍(h)进行比较,以确定是否应该继续训练。每个 h_i 表示子模型在∑_(j=0)^i▒s_j 训练步骤后必须具备的适应度,才能继续训练。每次通过一个障碍 h_i,模型都会训练额外的 s_(i+1)步。如果模型的适应度低于与它所训练的步数相对应的障碍,则训练立即结束,并返回当前的适应度。具体流程如下图所示:

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论