
NVIDIA 近日推出 OmniVinci,这是一款专为多模态理解与推理而设计的大语言模型,能够处理文本、视觉、音频,甚至机器人数据等多种输入形式。该项目由 NVIDIA Research 团队主导,探索如何让模型以更接近人类的方式理解文字、图像和声音等多种信息。
OmniVinci 将架构创新与大规模合成数据流水线相结合。据研究论文介绍,该系统包含三项核心组件:OmniAlignNet,用于将视觉和音频嵌入对齐至共享的潜在空间;Temporal Embedding Grouping(时间嵌入分组),用于捕捉视频和音频信号间的动态变化关系;以及 Constrained Rotary Time Embedding(受限旋转时间嵌入),用于编码绝对时间信息,从而在多模态输入间实现同步。
研究团队还构建了一个新的数据合成引擎,生成了超过 2400 万条单模态和多模态对话,用以训练模型如何整合并跨模态进行推理。尽管训练仅使用了 0.2 万亿个 token(仅为 Qwen2.5-Omni 的六分之一),但据报道,OmniVinci 在多项关键基准测试中表现更佳:
在跨模态理解任务 DailyOmni 上提升 19.05
在音频任务 MMAR 上提升 1.7
在视觉任务 Video-MME 上提升 3.9
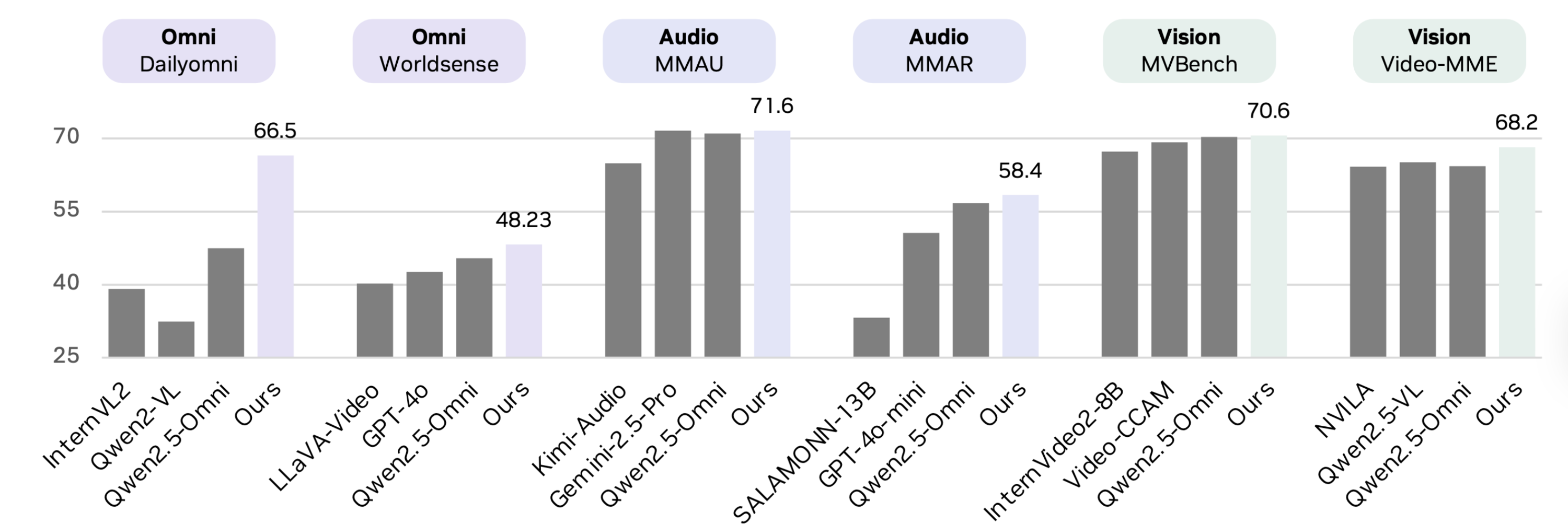
基准结果来源: https://huggingface.co/nvidia/omnivinci
NVIDIA 研究人员表示,这些结果表明“多模态之间是相互强化的”,当模型能够同时处理视觉与听觉输入时,其感知与推理能力都会显著提升。早期实验也已延伸至机器人、医学影像和智能工厂自动化等应用领域,多模态上下文的引入有望提升决策精度并降低响应延迟。
然而,这一发布也引发了部分争议。尽管论文中称 OmniVinci 为开源模型,但它实际采用了 NVIDIA 的 OneWay Noncommercial License 许可证,限制了商业用途。这一做法在研究者与开发者社区中引起了讨论。
数据研究员 Julià Agramunt 在 LinkedIn 上写道:
没错,NVIDIA 花了钱,也确实把模型造出来了。但把一个“只限研究用”的模型放出来,却把商业权利牢牢攥在自己手里,这哪叫开源?简直是“地主收租”:社区干活,他们坐享其成。这不是共享创新,而是披着慷慨外衣的利益收割。
在 Reddit 上,一位用户也抱怨了访问受限的问题:
有人拿到访问权限了吗?我只是想看看他们的基准测试结果,但被卡在他们那套“用户审核”流程里,太离谱了。
对于获得访问权限的研究人员,NVIDIA 提供了通过 Hugging Face 部署的设置脚本与示例,展示如何直接在视频、音频或图像数据上使用 Transformers 进行推理。该代码库基于 NVILA(NVIDIA 的多模态基础架构)构建,并全面支持 GPU 加速,以实现实时应用。
原文链接:




