
近日,微软和加州大学默塞德分校联合推出了一种新颖的异构深度学习训练技术 ZeRO-Offload,这是基于 Zero Redundancy Optimizer (ZeRO 是微软在 2020 年 2 月提出的一种万亿级模型参数训练方法) 构建的。该技术可在单个 GPU 上训练数十亿个参数模型。
图片来源:https://arxiv.org/pdf/2101.06840.pdf
技术发展至今,我们正在迈入一个高度依赖深度学习(DL)模型的技术时代。随着这些模型规模的成倍增加,训练这些模型的成本也变得非常昂贵。 由于训练这些大规模模型需要最先进的系统技术,这就使得这类大规模模型的训练受到了一定的限制。仅有为数不多的 AI 研究人员和机构拥有资源来训练这些包含十亿多个参数的、规模庞大的深度学习模型。例如,要训练 100 亿个参数模型,就需要一个 DGX-2 等效节点,该节点需要具有 19 张 NVIDIA V100 卡,成本超过 10 万美元,这超出了许多数据科学家甚至许多学术机构的承受范围。
为了增加训练大规模模型的可能性,加利福尼亚大学、默塞德大学和微软的一组研究人员联合开发了 ZeRO-Offload。这项新的异构深度学习技术可帮助数据科学家在单个 GPU 上训练数十亿个参数模型,而无需进行模型重构。它是一款具有高计算效率和近似线性扩展性的 GPU-CPU 混合深度学习训练技术。
在训练大规模模型时面临的挑战包括模型状态,即参数、梯度、优化器状态,以及缺乏有关利用 CPU 计算的研究。许多研究人员已经尝试使用异构深度学习训练来解决这些问题,以减少 GPU 内存需求,但这些办法都是针对基于小型 CNN 模型的内存激活问题。
传统的数据并行性通常是用于将深度学习训练扩展到多个 GPU 的社区标准。尽管如此,它仍然需要数据和计算再现,这就导致了传统数据并行不适用于深度学习模型的异构训练。另一方面,ZeRO-Offload 可以同时利用 CPU 和 GPU 内存,从而高效地进行训练。ZeRO-Offload 还可以在 CPU 内存上维护优化器状态的单个副本,而与数据并行度无关,这可以实现多达 128 个 GPU 的可伸缩性。
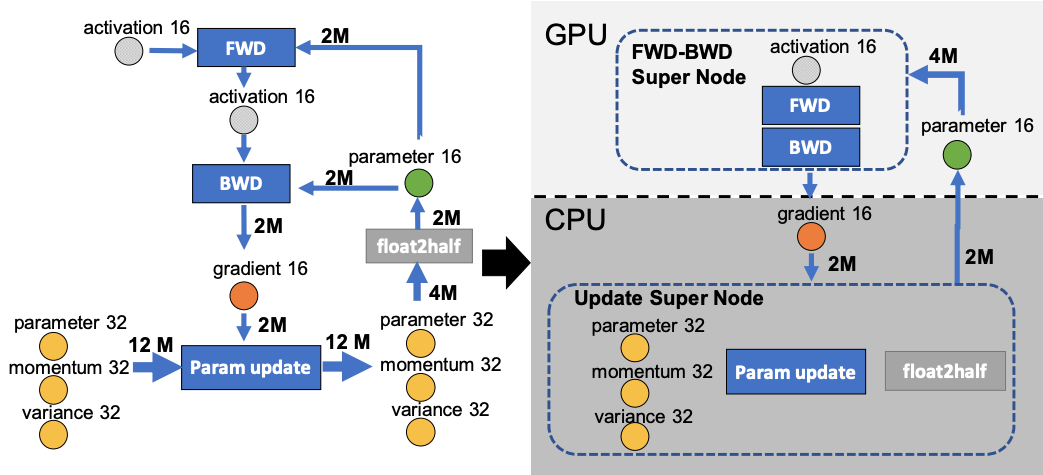
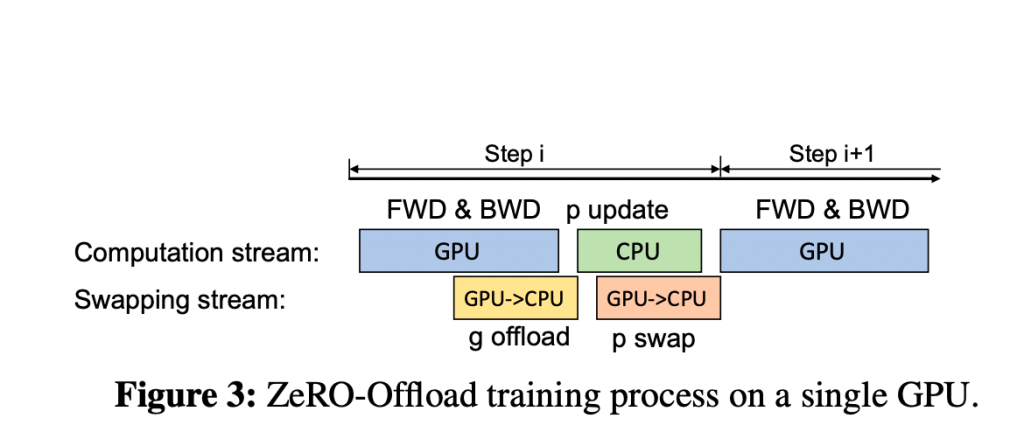
ZeRO-offload 是基于三个原则设计的:效率、可伸缩性和可用性。研究人员已经确定了 CPU 和 GPU 设备之间独特的数据分区和最佳计算策略。该方法涉及到的流程包括将梯度、优化器状态和优化器计算分散到 CPU,保留参数以及在 GPU 上保持向前和向后计算。研究人员观察到,在计算条件有限的情况下,可训练的模型大小增加了十倍,从而使单个 NVIDIA V100GPU 能够以 40 TFLOPS 的速度训练 130 亿个参数。
图片来源:https://arxiv.org/pdf/2101.06840.pdf
ZeRO-Offload 作为开源 PyTorch 库 DeepSpeed 一部分,可在 Github 上获取。只需更改几行代码,即可轻松将其添加到现有的训练管道中。ZeRO-Offload 提高了计算和存储效率,并且易于使用。这些功能甚至能让使用单个 GPU 的研究人员和数据科学家也可以进行大规模的模型训练。
论文地址:https://arxiv.org/pdf/2101.06840.pdf
DeepSpeed 项目地址:https://github.com/microsoft/DeepSpeed




