
直播是社交娱乐 app 的综合性变现工具,如何培养用户的心智,高效的建立用户和主播的多种连接 ( 点击、观看、关注、常看、常打赏 ) 是直播生态的重要问题之一。为了解决这个问题,各大平台所使用的方法之一是通过个性化推荐系统来促进用户和主播的实时社交。本文主要分享腾讯音乐旗下全民 K 歌的推荐系统技术及应用。将围绕下面四点展开:
业务背景
推荐系统架构及挑战
召回模型算法设计
精排模型算法设计
业务背景
直播推荐和其他推荐的比较
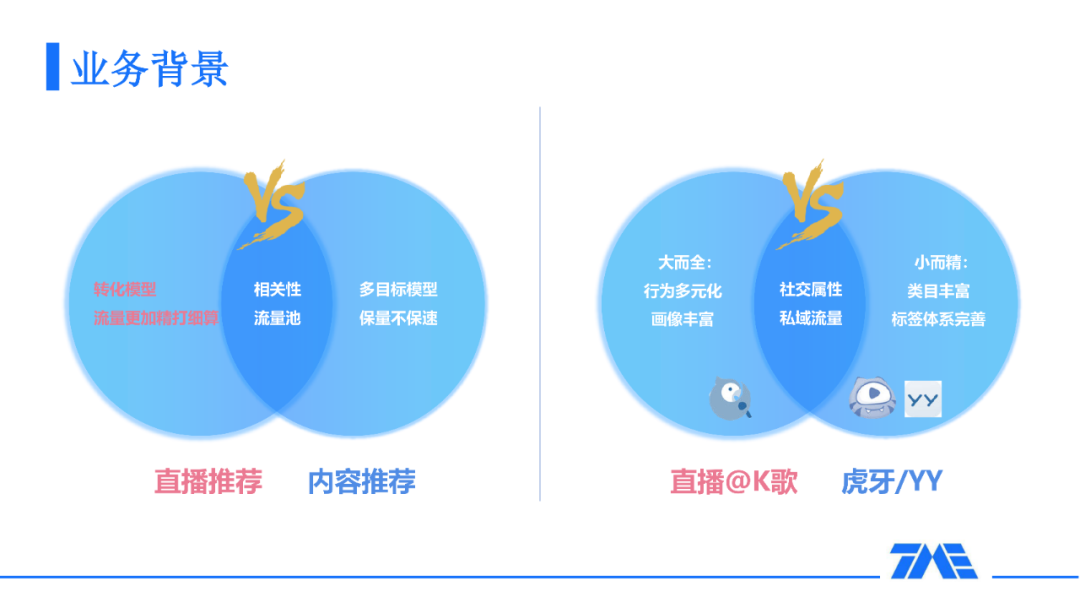
直播推荐和内容推荐的对比:它们的相同点是都有一个严格的计划经济,在一个流量池体系下寻找用户和主播/用户和 item 的相关性;不同点在于直播推荐寻找的是最优的转化率模型,而内容推荐更多的是寻找多目标的融合。直播推荐不仅是有量的要求,而且需要让用户平滑地进入直播间来防止直播间过载(主播接待能力同步)。K 歌的直播推荐对比虎牙/YY:场景更大而全,用户的量级更大,用户行为和画像更丰富。而虎牙/YY 它们的类目是更丰富的。
推荐系统架构
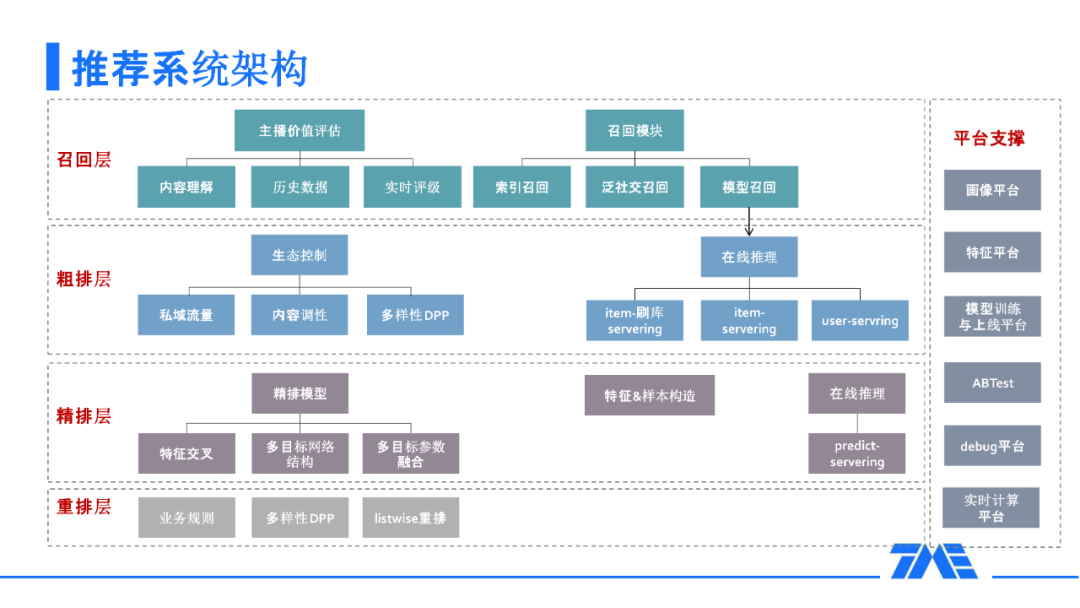
在召回这一层面,有索引召回,比如用户喜欢的伴奏来召回直播间。泛社交召回,还有通过好友和用户感兴趣的人所在的直播间来召回。另外,我们对主播有非常严格的价值评估体系,包括实时直播推流去进行视频理解和音频理解,对主播的历史和实时数据的理解等等。
在粗排层,除了需要去考虑一些模型化的问题外,还要考虑一些常看常打赏/关系链这些私域流量,以及用户去消费直播间内容所能感受到的多样性。
对于精排层,主要考虑两个方面:第一个方面是怎么去做更好地交叉;另一个方面是多目标,考虑怎么去设计更好的多目标网络结构和更好的多目标的参数融合。
在重排层,除了对业务的研究之外,还加入了基于行列式的方法这样一些模型来进行多样性重排。
在除了召回、粗排、精排、重排之外,推荐团队依托多个平台支撑,包括:画像、特征、训练、AB test、debug 和实时计算平台。
召回模型算法设计
1. 召回模型迭代
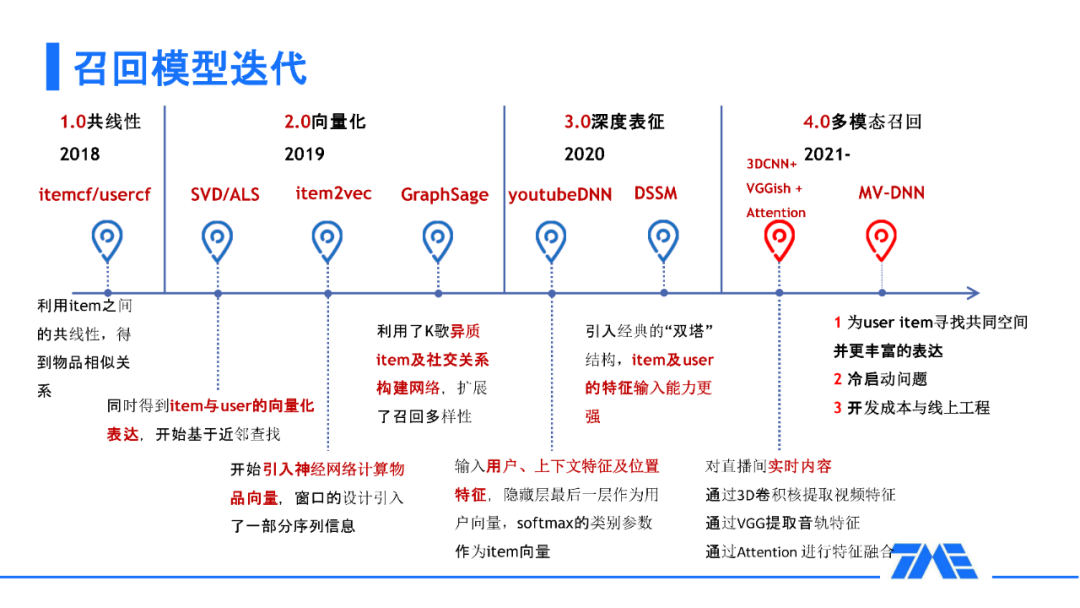
从 2018 年开始做直播推荐,跟随着深度模型的进展,我们的模型迭代了四个阶段,直到工业界的 baseline,也就是双塔模型 ( DSSM )。总的方法论就是为用户和 item 寻找一个共同的空间,并且能够有更全更丰富的表达。此外,如果我们认为 DSSM 其实是一个 single view,还可以有更多的 view 来辅助主场景,比如我们引入直播间的伴奏信息来进行辅助训练,或者我们加入一些对直播间内容的实时理解。
2. 召回双塔模型
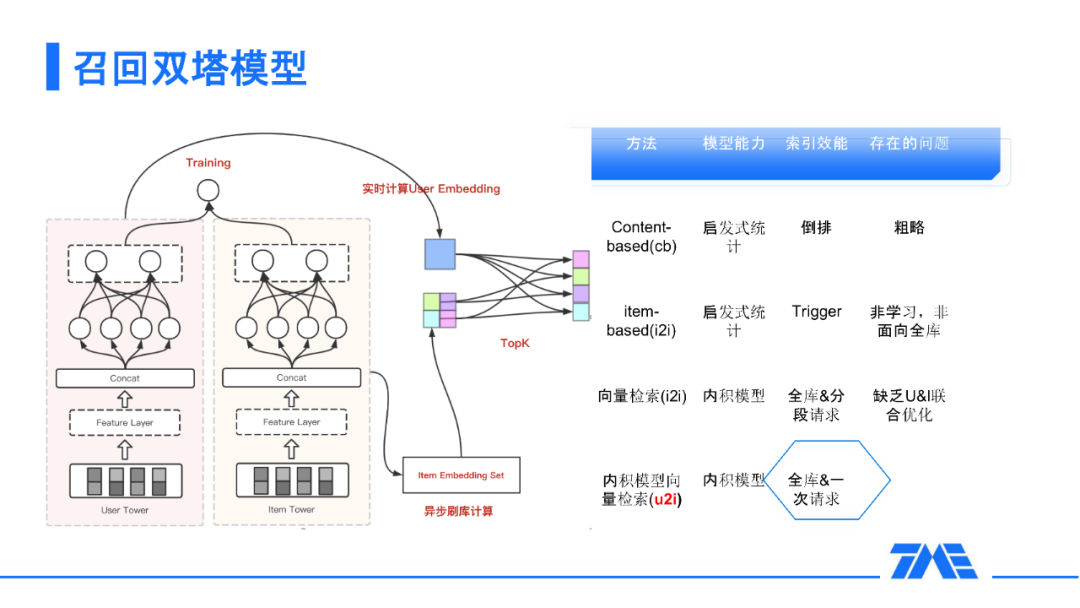
为什么 DSSM 在工业界是一个非常 baseline 的一个方法呢,以及为什么在这样的框架下能进行非常好的延展呢?第一个方面就是这个模型的表达能力,它的表达能力的上限是非常高的,比起一些传统的方法,比如 content-based 或者 i2i 这样的启发式统计模型,它在 DNN 的框架内,本身就可以享受到主流推荐领域的各种优化。在线上的工程来看,我们只用通过一次请求和快速索引来完成最快速的召回工作。
3. 召回多模态模型实践
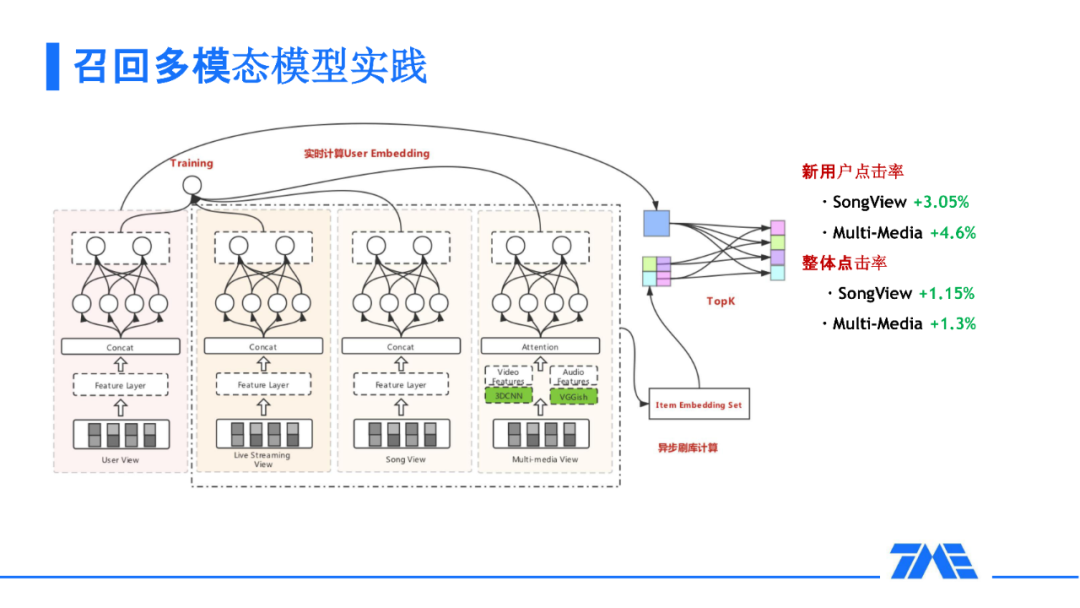
基于这样的召回模型,我们做了怎样的优化呢?我们增加了一个 SongView 和多媒体的 View。我们的思考点是 K 歌大部分的主播其实是属于唱歌类型的主播,大部分的直播间可能都带着 SongID 这样一个特征信息,这样的信息是不是能辅助我们对用户进行推荐呢?尤其是 K 歌直播的许多新用户其实很早以前就是 K 歌的老用户,他/她对这个 Song 其实已经有了很多的丰富行为,加了这个信息来作为一个辅助 View 是不是能够对新用户提升一些效率呢?而且除此之外,我们的兄弟部门 QQ 音乐,能对这些 Song 有一个比较好的训练好的 embedding 来为我们提供支持,加上我们的多媒体库也有很多根据伴奏的一些信息,考虑到以上诸多的优点,我们就尝试了这样一个 Multi-view 的 DNN,这样的效果在新用户以及整体的点击率上都能够取得一些成绩。
进一步思考,直播的本质是我们能够通过理解它的内容来给用户一个更好的推荐,尤其是对一些刚来 K 歌的用户的第一印象而言,比如对于一个男生来,他会看到这个女生很漂亮,这样一种情况,那么多媒体会给我们一些比较大的帮助。所以我们增加了多媒体这个辅助 view 能对我们的新用户和点击率有一定的帮助。
精排模型算法设计
1. 精排模型多维度迭代
接下来,就是精排模型。我们的精排模型主要在三个维度进行了优化:第一个维度是特征交互的部分,在这部分我们的主要侧重点是如何进行显式的特征交叉,包括了两部分的优化,一部分是 FM 这样的低阶特征交叉,一部分是像 Cross 和 Autoint 这样的高阶特征去进行交叉。我们的总思想是能不能让特征的交叉更加的自由而且更加的具有物理意义,后面会详细地介绍我们是如何去优化的。
2. 特征处理、采样及加权
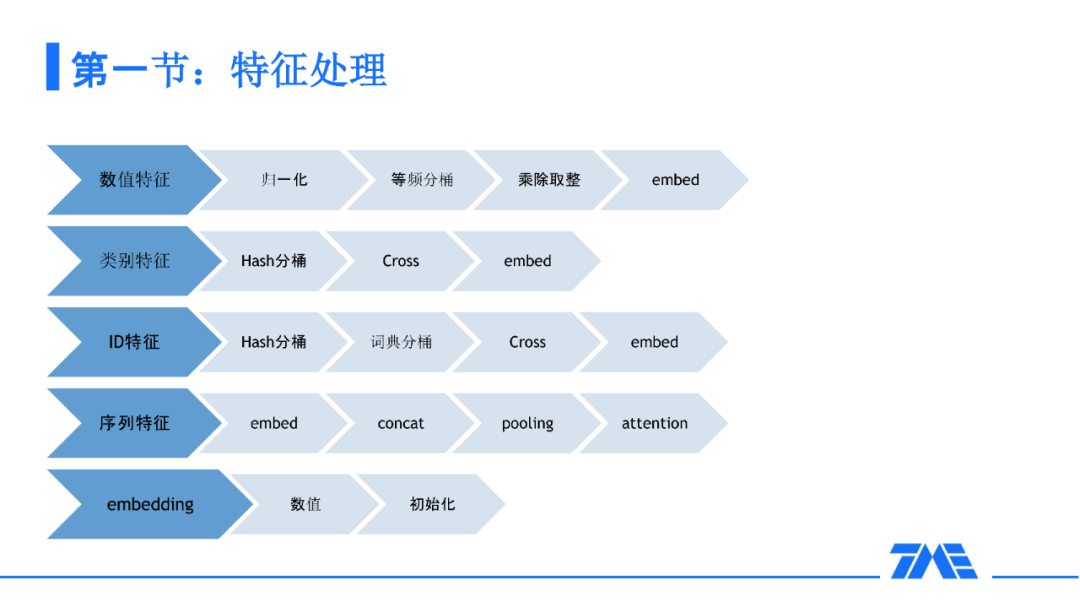
我们首先介绍一下特征的处理。特征首先包括数值特征、类别特征、ID 特征、序列特征还有 embedding。举个例子,序列特征:比如说用户去过的直播间,我们会把这些直播间 ID 转成 embedding。对这些 embedding 做后续的一些例如 pooling 或者 attention 这样的操作进而去训练我们的模型。多媒体团队为我们提供多媒体的 embedding,第一种用法就是我们把 embedding 当做一个数值来喂给我们的模型;第二个用法就是我们把 embedding 作为一个主播的表达直接加载到我们的模型中进行进一步的运算。
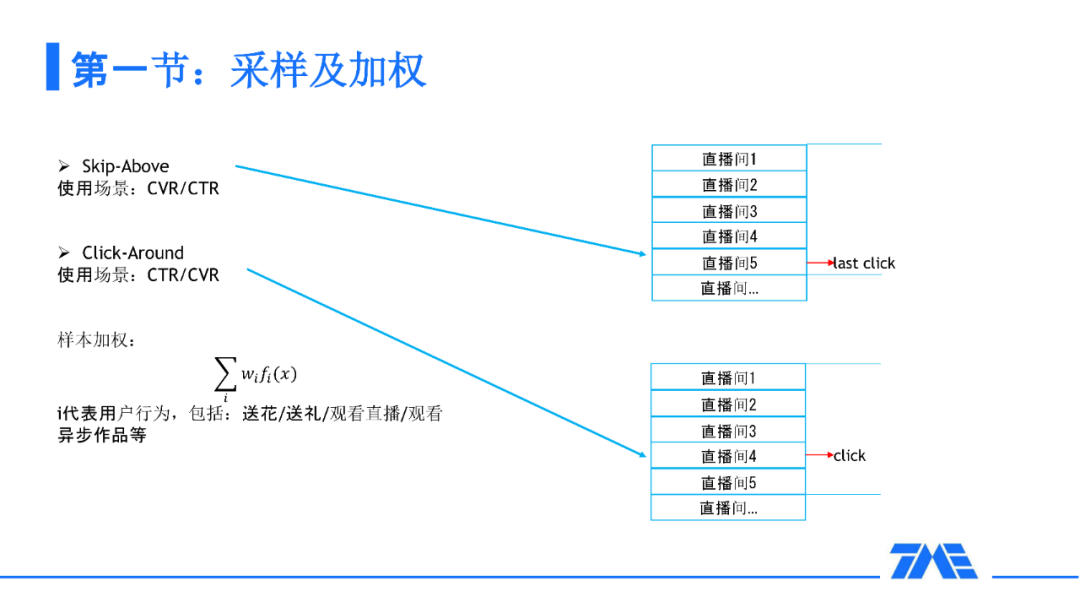
对于双排方法,由于我们是双排的直播间 click,所以我们需要有一定的采样方式,这样的采样方式一般是有两种:一种是 Skip-Above,另一种是 Click-Around。去采取一些有效的负样本来使我们的模型更加鲁棒,对于样本的加权,在我们的场景中如果有一些送花送礼或者是异步作品的话,会对这样的样本模型加权。
3. 特征交叉-KFM,DeepKFM,Cross|AutoInt
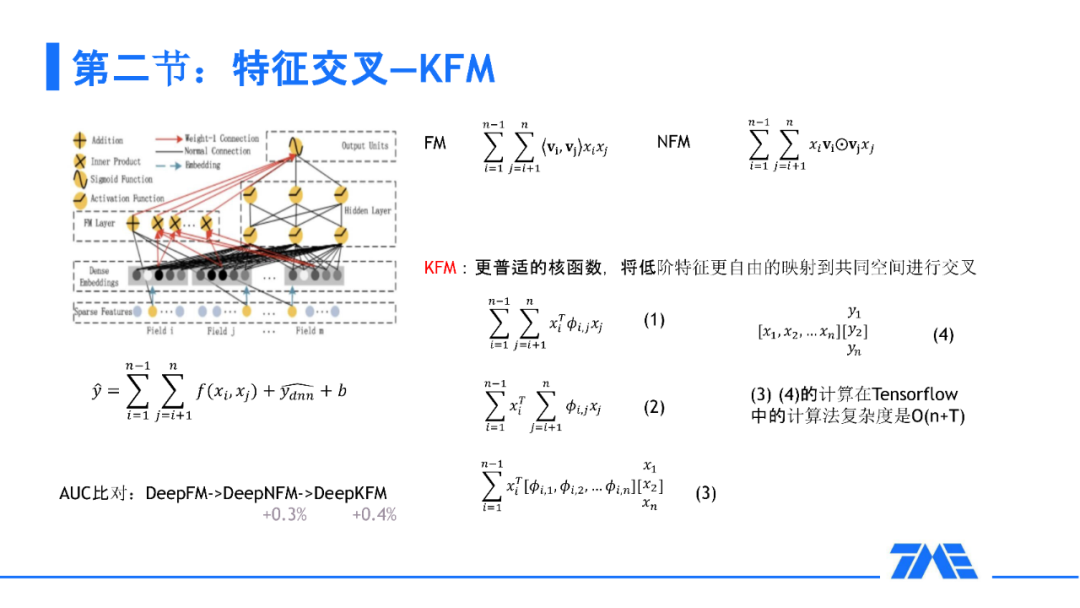
下面来讲一下我们的低阶特征交叉。从左上角的图可以看到现在的深度神经网络普遍流行的一个并行架构。对于现在的业界,DeepFM 还是一个比较普遍的 baseline。因为这样的低阶特征实际是可以通过向量的内积来表达两两特征之间的交叉。在这个基础上,何向南老师提出了 NFM,把内积换成了哈达玛积,那么我们来进一步思考:其实 FM 的本质就是两两特征之间的核函数就能够表达特征交叉。这里要思考一个问题:FM 的一个问题就是 embedding 长度需要设置成一样才能保证两两特征交叉。我们参考看点团队的方法,设置一个更加普适的核函数来把所有的低阶特征映射到一个比较通用的空间来进行交叉。这种情况相当于我们直接对 Bit 级别的特征做 FM,从而能够达到两两特征交叉的目的。在这样的情况下,KFM 比 FM 有四个千分点的提升。
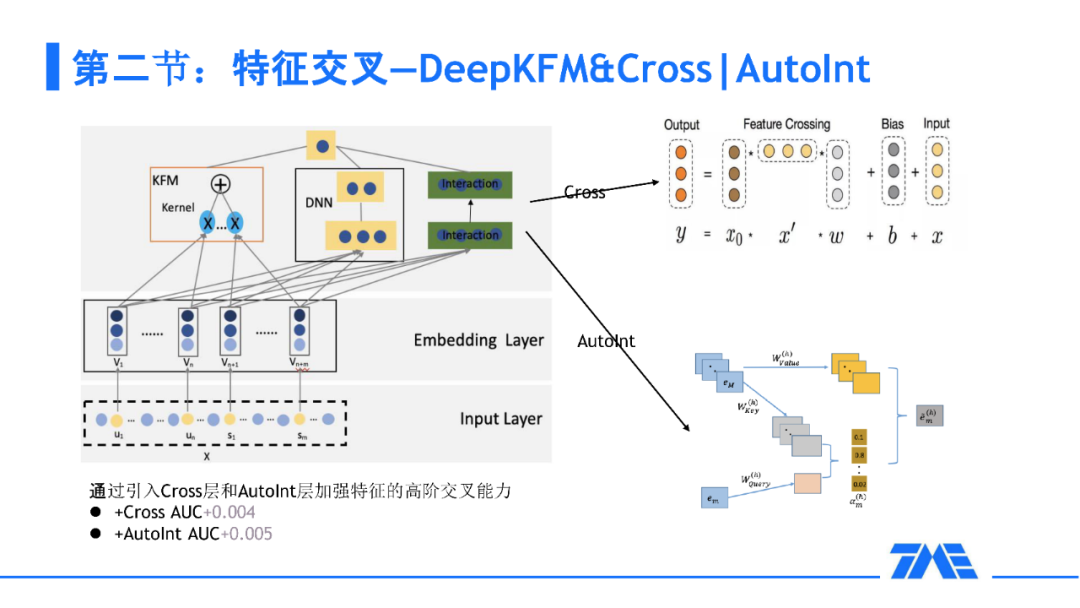
对于高阶的特征交叉,我们也是走的和业界比较通用的路线,比如 DCN-V1/V2/M。比如 AutoInt,Autoint 就是把每个特征去比作一个词来做多头的 self-attention 进行高阶特征的交叉。这样其实在我们的场景中也是能得到一些收益的,但是我们仍然想要把每个特征设置成不同的 embedding。这样的不同可以给我们带来比较大的好处,比如说年龄,性别这样的 embedding 一般都会比较小,而 user embedding 往往都比较大,这种情况下,其实更适合 Bit 级别的特征去做 self-attention 交叉方式。所以我们唯一的变化就是把交叉的粒度变成了 Bit 级别,这样的 AutoInt 也给我们的 AUC 带来 7 个千分点的提升。
4. CVR 预估--ESMM,GradNorm
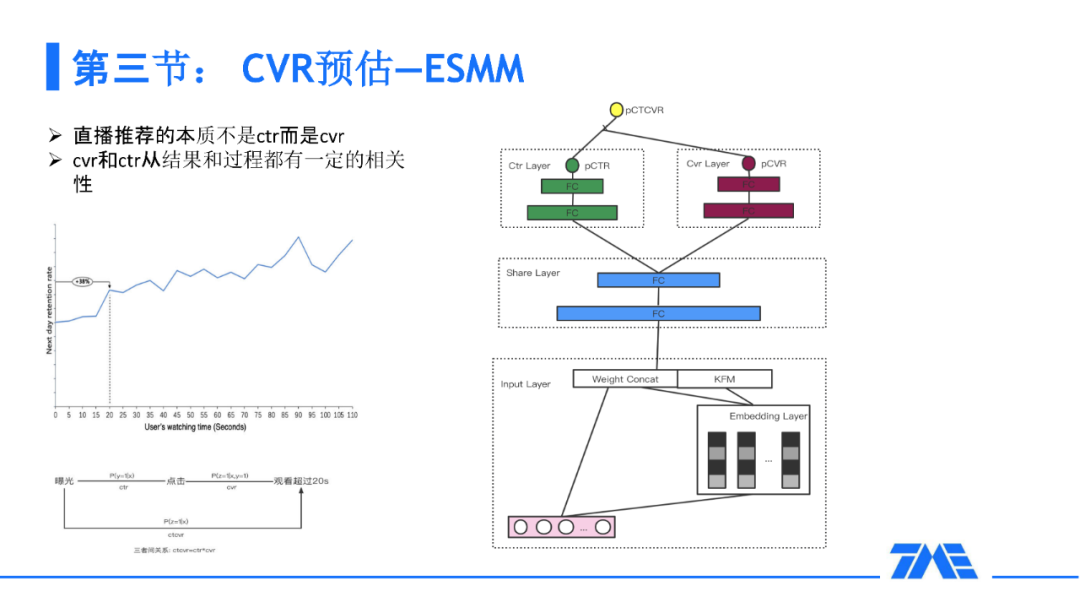
直播推荐的本质不是 CTR 而是 CVR。即我们需要让用户 get 到直播间的内容,而不是仅仅让他点进去。CTR 和 CVR 是有一定的用户路径的,也就是说我们要先去点然后才能成为 CVR。而且 CVR 对于我们最终的留存是有一定的相关性的,如果我们超过一定的时间,用户的直播的留存就会有一些比较显著的提升。在这样的思考下,我们也采用了一些业界比较通用的方案,就是 ESMM。这样的通用方案其实解决了一些比较通用的问题。第一,就是选择的偏差,从 CTR 到 CVR 是一个选择的偏差。第二个问题就是 CVR 这样的问题在我们的场景里也是比较稀疏的。
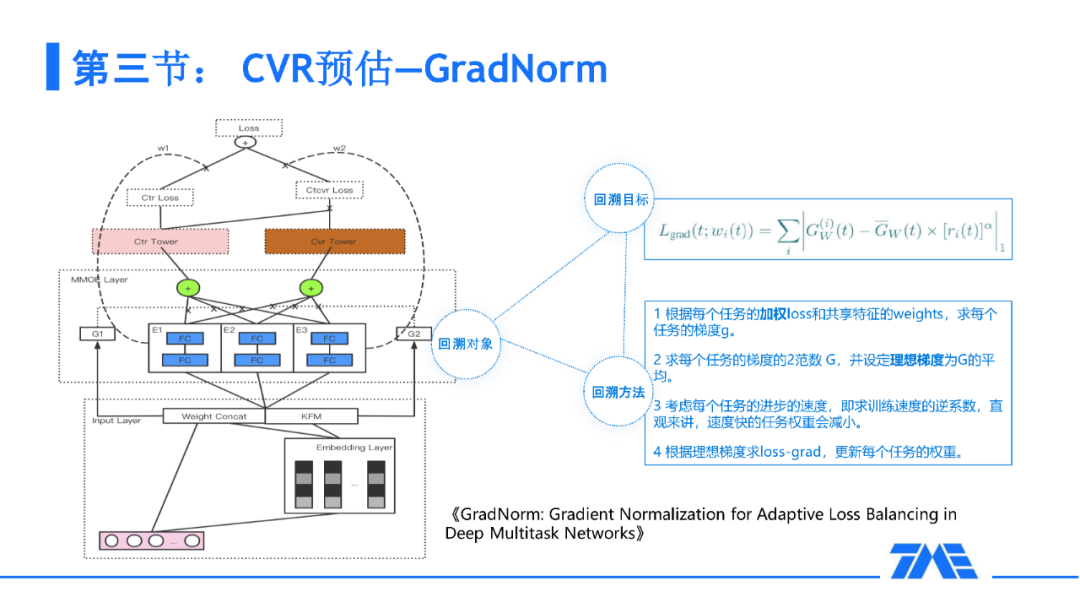
并且在以 ESMM 为 baseline 的基础上,我们还发现了一些问题:CVR 是一个很重要的任务,而这个任务在多个任务一起学习的过程中可能会没有任何收益。原因是这个任务太过难以学习,在这个前提下,我们参考了另外一个比较通用的框架:GradNorm。在学习的过程中,如果我们手动调节 CVR、CTR 的权重也是可以的。但是这样的调节不能做到端到端的动态调节。我们参考这样的一个框架:在训练完之后我们需要回溯,回溯的对象就是第一层共享的 embedding,回溯目标也就是归一化的梯度,通俗一点就是希望我们的任务能够齐头并进地去进行学习。这种情况下,可以在 tensorflow 中打印出每个任务的权重,在训练过程中,CTR、CVR 的权重会占比更加高,会给到一些倾斜,使得一些比较难的任务能得到一些补充信息来更加好的学习。
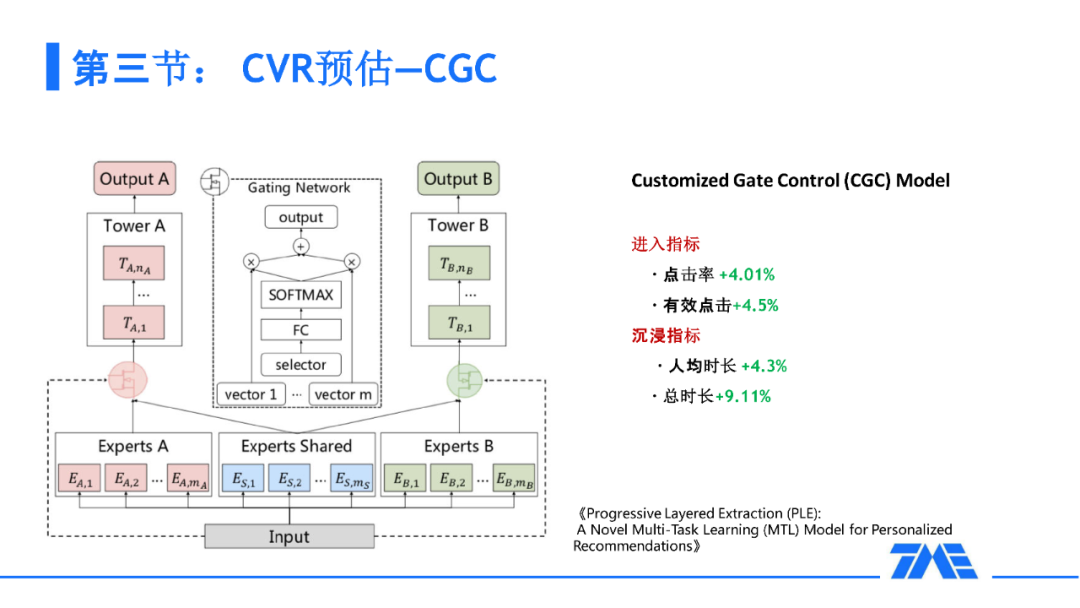
我们还思考怎样能使 GradNorm 学习的更充分一些,能更好的调节两个任务的权重,那么是不是应该有一个公共,独享的专家,唐红艳同学 2020 年的 Recsys 的 bestpaper 中提出了 CGC,它就是一个定制共享的机制,讲的是我们把 MMOE 的机制做得更精致一些。此外,有一个共享专家能把我们的 GradNorm 做的更好一些,能更充分地调节出一个梯度的归一化。我们在上了 CGC 以后,在点击率和有效点击,以及时长方面都有很大提升。
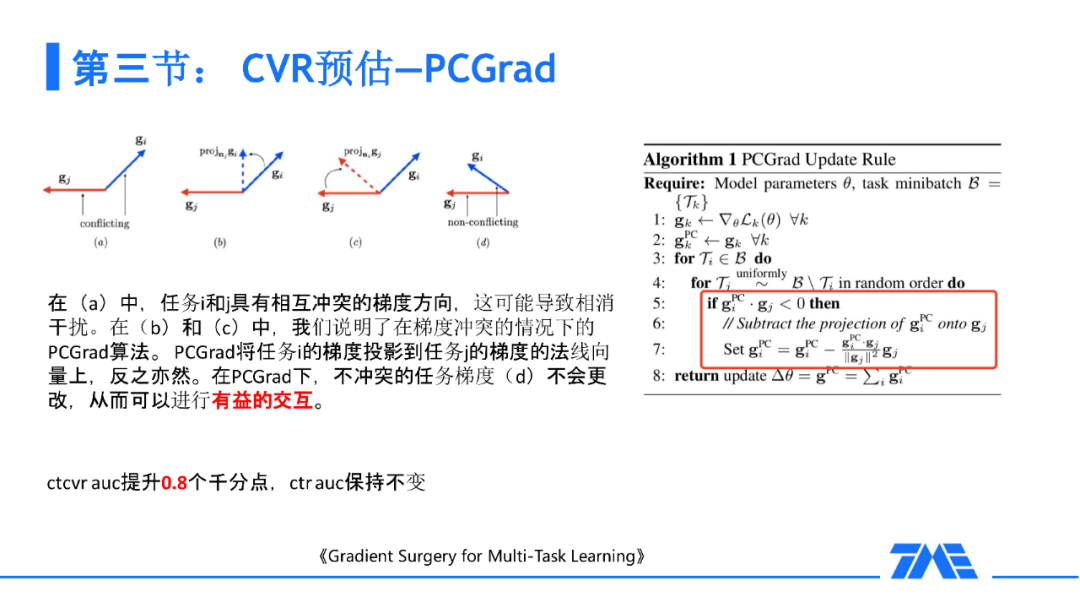
事实上,GradNorm 也有一定的缺点:GradNorm 本身其实是做一次比较粗暴的回溯,只是从最后一层回溯最开始的一层,而且它调节的是一个权重。除了调节权重,我们还能做什么?是不是能够更加精确的去控制这个权重的过程?
我个人认为:训练的精髓在于梯度,如果我们能够直接影响到每个任务的梯度,就能够对每个任务中相互的受益做出更有效的判断,使得任务之间能够做出一些更加有意义的交互。举个例子:我们看到一篇 PCGrad 这样一篇论文,当两个梯度它们比较相似时,我们会计算 cosine 的相似度,当两个任务的梯度是比较相似的情况下,我们会继续沿用每个任务的梯度;当两个任务梯度不太一样甚至冲突的情况下,我们会做一次映射让任务进行提督的相互的融合。下一步,我们会利用修正后的梯度来进行梯度下降从而使我们的模型训练的更加鲁棒。
嘉宾:timmili,腾讯音乐高级研究员
本文转载自:Datafuntalk(ID:datafuntalk)
原文链接:全民K歌直播推荐算法实践




