
新冠疫情全球肆虐,预期的通货膨胀,使得投资理财变得愈发重要。截止 2020 年 11 月份,客户在老虎证券的累计开户数已突破百万,对于券商而言,这既是机遇也是挑战。老虎证券内容团队秉持“用户至上、创造增量价值”的理念,为解决投资者面对信息过载的问题,期望为用户提供更好的交易体验。利用大数据和人工智能技术构建数据资产,旨在实现数据驱动业务与运营。
传统机器学习技术和深度学习技术在计算广告、推荐排序、图像识别、机器翻译等领域的成功应用,一方面提供了大量模型实践经验,另一方面印证了模型强大的表达能力。但其中,涉及券商领域的探索少之又少,故撰写本文作为实践记录,同时也为抛砖引玉。
了解互联网券商
境外证券经纪商包括三类:传统券商属于第一代券商,在线下提供市场营销和交易渠道;第二代券商线上线下同步营销,提供行情、基本市场分析和交易系统;第三代券商为在线券商,主要通过互联网进行营销活动,使用先进的市场分析工具和算法提供新型交易系统。老虎证券就是典型的第三代互联网券商。
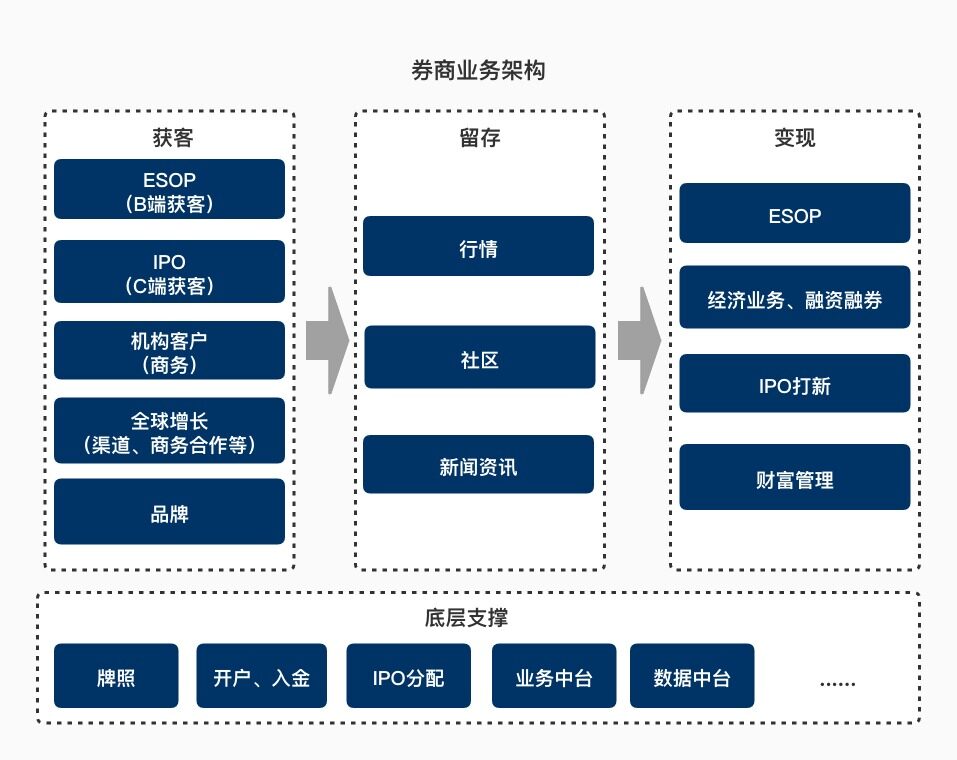
下图是一个典型的互联网券商业务架构图。相比于传统券商,互联网券商在获客方面降低了用户开户入金等操作的门槛;在留存方面,通过技术降低投资者信息过载问题,提高资讯的实时性,对长尾用户同样友好;另外在变现方面,有着更低的运营成本优势。
券商社区业务痛点及应用挑战
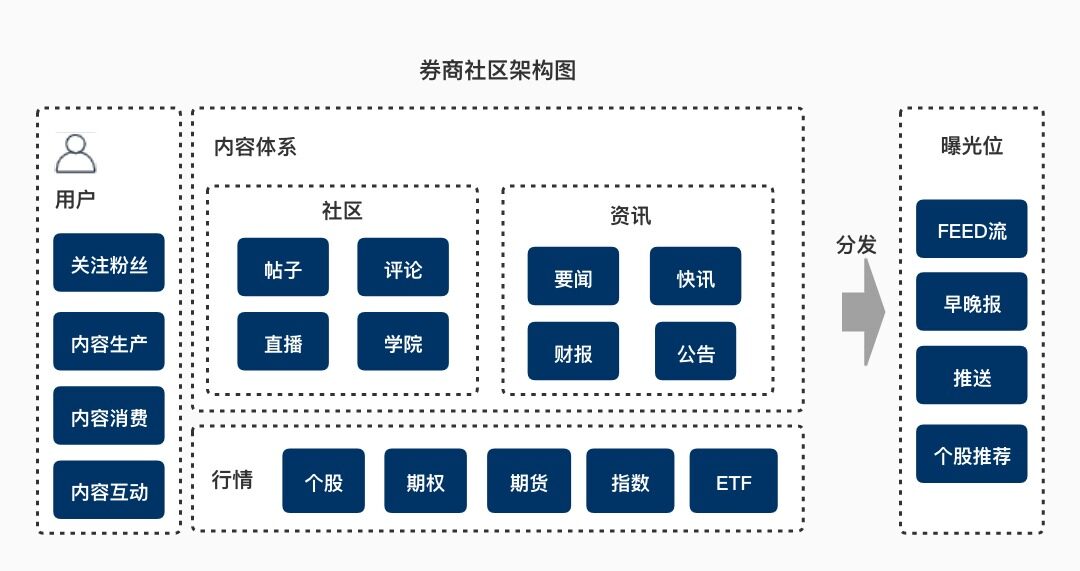
作为一个投资者,每天需要的不仅是股价、K 线、资金分析等技术上的指标,同时十分迫切需要有价值的投资信息和建议。老虎券商社区主要的任务就是解决投资者信息过载问题,将有价值的内容及时提供给有需要的投资者,使其获得价值,进而帮助老虎 App 提高用户粘性,改善用户留存问题。
下图描述了当前老虎社区的功能架构和模块组织结构。可以看到老虎社区整合用户信息、内容体系与行情数据于一体实现“千人前面”的智能分发。当然,在实践的过程中我们还是碰到了一些痛点。
首先,从内容生产者的角度,很多价值投资者乐于将自己的投资经验分享出来。社区如何给他们更合理的曝光,令其获取更多的粉丝,使其有更强的创作动力。这是个挑战;
其次,从内容消费者的角度,我们发现如何在投资者宝贵的时间里将最有价值的信息呈现给投资者是我们面临的主要课题;
最后,从内容本身的角度,内容的时效性要比其他领域更强,如何在第一时间将其推荐给需要的投资者,充分发挥内容本身的价值,将是一个非常值得研究的事情。
在尝试解决这些痛点的过程中,我们面临了诸多挑战:
要求高水平地保护券商用户的隐私数据。用户信息和交易数据需要进行严格数据脱敏(数据层面);
用户是多账户的,同时会在多个市场进行交易,市场的汇率在不断变化(数据层面);
行情波动会直接影响市场情绪,进而影响用户交易行为、浏览行为甚至内容生产,使训练模型产生偏差(bias);
用户的浏览行为受诸多因素影响,包括个人习惯、投资风格和市场行情等。必须采用合理的方法对这些数据进行数据清洗和特征工程,同时需要采用一个合理的模型结构。
券商机器学习技术应用探索
券商机器学习场景选择
在机器学习大行其道的今天,我们希望所有的场景都是智能的。但是理想是美好的,企业在应用的过程中,一定会考虑其性价比。毕竟有多少智能,就有多少人工。再智能的模型也不可避免地会涉及数据标注、数据清洗、特征工程、模型训练、超参调整、离线评估等工作。
所以我们在选择应用场景的时候,主要考虑了如下的因素:首先,场景必须是比较稳定,不会经常有大的产品改动,能够为模型提供稳定的训练数据;其次,场景要有一定 PV,有一定用户渗透率(即场景使用者比例),从而保证模型的训练数据量;最后,我们希望场景是有相当的潜在商业价值的,例如有入金转化可能或帮助用户进行融资融券等。
鉴于此,我们确定了本次主要的研究方向:
社区内容推荐(FEED 流、个股推荐、关注推荐)
用户交易行为预测(是否会入金、是否融资及其可能金额、是否会做空)
舆情监控(标的异动、内容异动)本文将以社区内容推荐场景为依托,阐述老虎证券社区应用机器学习的各项探索。
影响投资者内容消费的因素
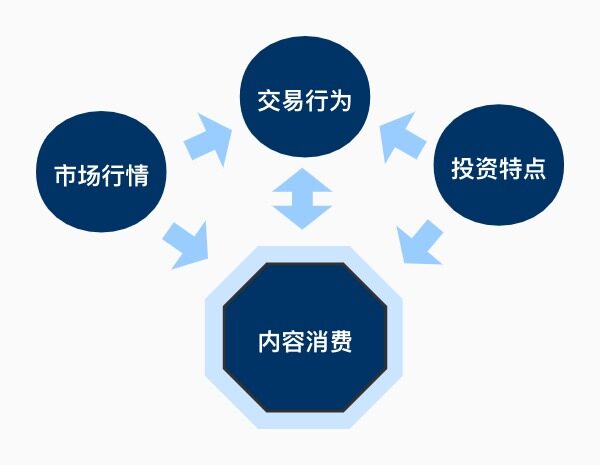
通过观察用户在平台的交易数据和内容生产消费数据,我们发现如下关系:当行情好时,用户的交易数量也会增加,在社区的内容生产数量和活跃程度也会相应增加;用户的投资特点,同样会影响其在社区的行为,比如长线投资者更热衷于分享等。我们将其抽象为如下图所示的关系:
样本采样降低行情波动的 bias
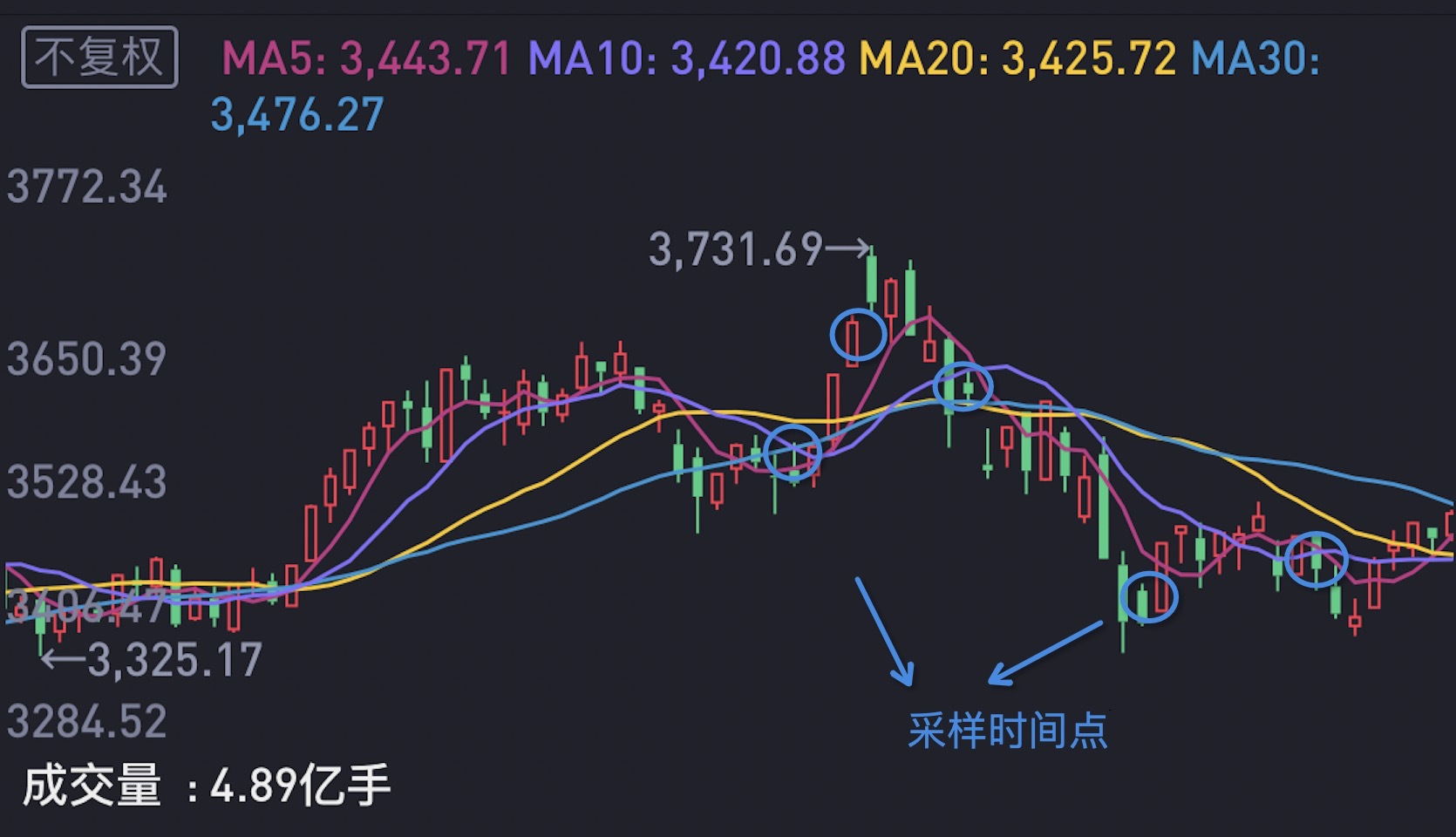
市场行情会影响用户的社区浏览行为,也就是说如果短期内行情比较好,此时收集训练数据,训练出的模型必然会存在一定的 bias。为了降低这一影响,我们在收集训练数据时,不会仅收集近期用户的浏览数据,而且会在不同的市场行情下,进行用户浏览数据采样。下图展示了我们对个股浏览数据在不同行情下的采样时间点。
漏斗模型丰富排序样本集
我们的业务场景通常优化目标是比较明确的,因而比较适合采用监督学习。这会涉及到一个很重要的话题:数据标注问题。现有的数据标注是业界的待解决的问题,采用人工标注的方式比较多,同时也催生了一个数据标注师的职业。
投入人工标注是比较花费代价的,所以也产生了一些通过用户主动行为进行自动标注的方式,比如 FEED 流常用的 skip-above。但是这样仍然存在一个问题就是,现有的推荐系统,仍然受上一个推荐系统影响,在排序阶段产生 bias。为解决这一问题,我们需要丰富训练数据。
平台页面结构形成的漏斗模型,天然地对用户进行的一次次的清洗、筛选、分类。也就是能进入某些深层页面,同时还进行了内容消费行为,将这些样本视为正例是更可信的。我们通过这部分数据来丰富排序层的样本集,从而降低上一个推荐系统的 bias。
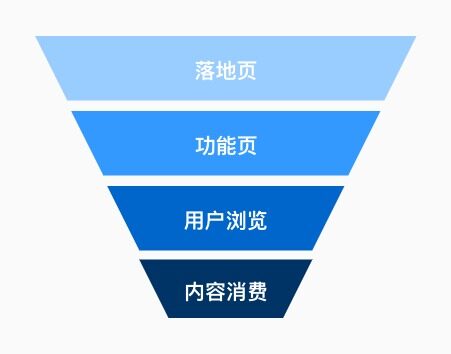
浏览时长的加权处理
在对内容排序中,以 Logistic Regression 为例,$exp(\omega^Tx+b)$预测的是几率(odds),即$N_+/N_-$,N 是帖子曝光数,$N_+$是帖子的的点击数,$T_i$是内容第 i 个人的浏览时长。我们将正样本按照浏览时长进行加权:$odds=\frac{\sum{T_i}}{N_-}=\frac{\sum{T_i}}{N}\frac{N}{N-N_+}=\frac{\sum{T_i}}{N}\frac{1}{1-p}\approx\frac{\sum{T_i}}{N}$
transform_fn = lambda x: tf.math.log(T+1)label_weight = tf.feature_column.numeric_column('label_weight', shape=(1,), default_value=1, dtype=tf.dtypes.float32, normalizer_fn=transform_fn) 在对正样本加权后,模型预测出的是帖子的平均浏览时长,其中,$p=\frac{N_+}{N}$,为点击率,通常很小。同理未来对于融资场景,我们对样本数据根据融资金额进行加权,使得模型预测出的结果,为用户可能的融资金额。
应用实践
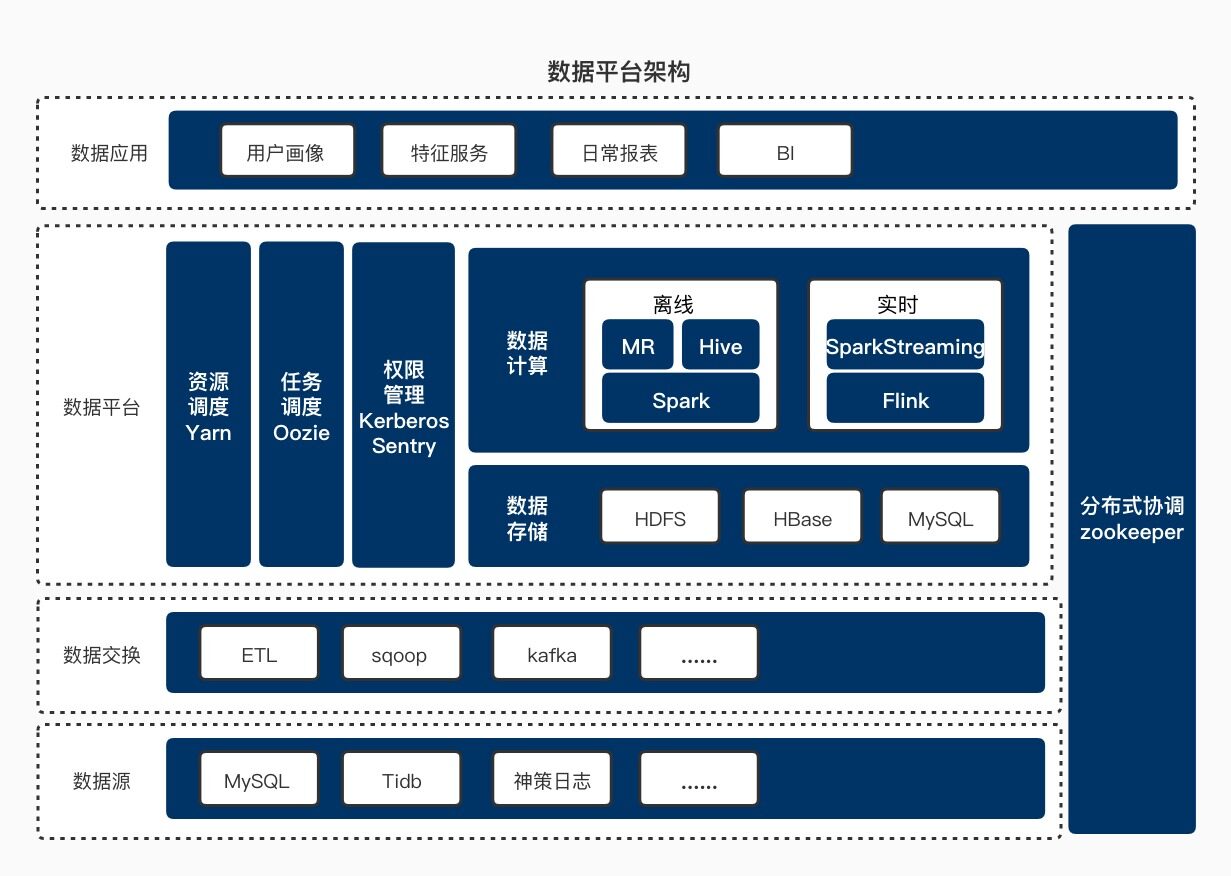
数据平台架构
在构建数据平台时,我们首先需要打通各个业务线的数据,同时需要考虑用户是多账户的,多个交易市场的,存在多种交易货币等因素。在数据层面,券商的数据安全防护是极为严格的,用户的特征数据和画像数据,凡是涉及用户个人信息和交易信息,都需要进行严格的数据脱敏处理和相应的权限管理。
用户画像的本质就是用户数据的标签化,标签可分为两大类:事实型标签和预测型标签。其整个过程包括:数据收集(埋点上报、业务库监控)、数据清洗及特征库维护、模型或规则打标签、画像服务。对于事实型标签,数据经过清洗,设定规则,抽象为用户标签;对于预测型标签,需要经过模型预测评估等过程后,为用户打标签,比如用户兴趣标的。
下图展示了老虎证券数据平台的总体架构。数据挖掘的天花板是数据本身,因而在构建数据平台时,我们尽可能着眼全公司的数据,收集全各个业务线数据,同时保证数据的时效性和准确性。
投资领域特征库构建
结合具体的应用场景,和上述的影响因素,我们抽象出 7 大类特征:用户价值、营销偏好、营销活跃、访问活跃、内容业务、账户总览、基本信息。下面,我们以基本信息、内容业务和交易业务为例,介绍特征的构建细节:
基本信息人口属性:性别、年龄、学历、职业等地域特征:身份证所在国、APP 激活所在国、手机号所在国、纳税国等资产资质:可投资额、贷款状况、可投资评估等风险特征:测评等级、投资经验、年限区间等社会学:婚姻状况、子女状况等
内容业务浏览互动:24 小时内浏览最多 top3 标的、7 天内浏览最多 top3 标的行为:启动 app 次数、自选股列表、参与活动、搜索标的等内容:相关标的、文本长度、情绪值、累计点赞数、实时互动数、运营等级等
交易业务上下文特征:市场涨跌幅、星期、天气等统计特征:24 小时订单金额、24 小时港股 OPT 订单次数、持仓等类别特征:24 小时订单标的、7 天 IPO 标的、换汇订单、加密货币订单等
其中交易业务,是最直接反应用户交易性格的特征,所以在此处的特征也是最细致的,特征会按照美股、港股、期权和期货做进一步划分。
类别特征的处理
标的是券商领域一个天然且十分重要的标签,不同的标的也往往包含着用户的交易风格。用户与用户之间的交易特点是不同的。一个用户的交易风格在短时间内是不会快速变化,所以我们将用户 ID 也作为一个特征用于记录用户的交易风格,实现个性化。内容标签承载着内容上的信息,通过其关键词、关联标的、互动数据、文本长度和运营标识等特征反映出来。
目前业界对于类别特征的技术研究十分深入,故我们在特征工程方面,采用更多的是 ID 类特征,一些连续型特征也会离散成 ID 类特征。TensorFlow 的 tf.feature_column 类封装了对于 ID 类特征的分桶、哈希、交叉等操作。ID 类特征是高维稀疏的,可方便存储、传输、提高模型计算效率。
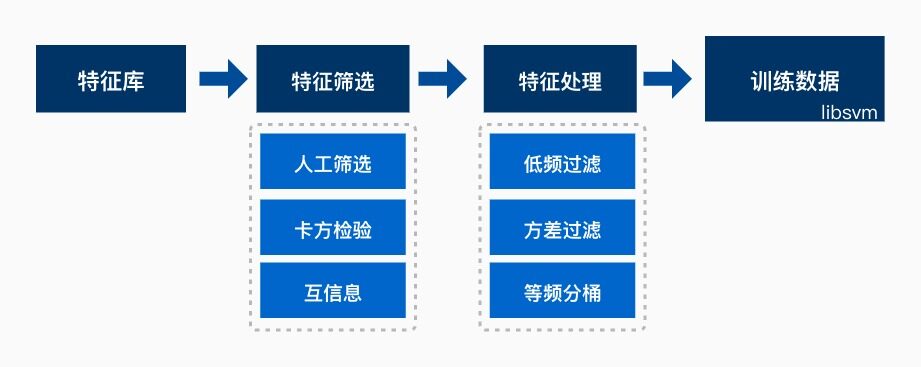
下图为我们特征处理的主要流程,为保证模型的计算速度,我们对不同应用场景下的特征进行一定程度的筛选,人工也会介入其中,结合原有规则策略、卡方检验、互信息等方式选取特征。然后进行低频过滤和方差过滤后,拼接样本标注,从而生成训练数据。
模型中数据权值共享
在模型的选择上,本次我们选择 Google 提出的 Wide&Deep 模型。该模型在整体结构上分为 Wide 和 Deep 两部分。这两部分在最外层合并后进行联合优化,Wide 侧使用 FTRL 算法,充分利用特征的稀疏性,Deep 侧使用 Adagrad 算法。该模型兼顾了模型对于数据的记忆与拓展两个方面,Wide 侧负责记忆,Deep 侧负责拓展。
如上文所述,标的在券商内容推荐中是十分重要的信息,也是天然的标签。同时我们发现,训练数据中,用户交易标的数据量是比较多的,而进行 IPO 标的数据量是十分稀疏的。如果将其作为独立的特征分开训练,会导致 IPO 标的的参数矩阵不能得到充分的训练。
如下图所示,在应用此模型时,我们对标的构建了权值共享,使一些较为稀疏的特征也能得到合理的训练。对于用户基本信息特征和用户 ID 所承载的交易风格,这部分特征,我们主要通过人工特征工程,输入到 Wide 侧。这么做有以下几点考量:
Wide 侧相比于 Deep 侧的神经网络更易于人理解;
这部分特征物理含义更为明确,方便理解某一部分用户群体的特点;
这部分特征量不是很大,不会消耗太多的人工;
利用模型 Wide 侧的记忆能力,来记忆用户的风格。
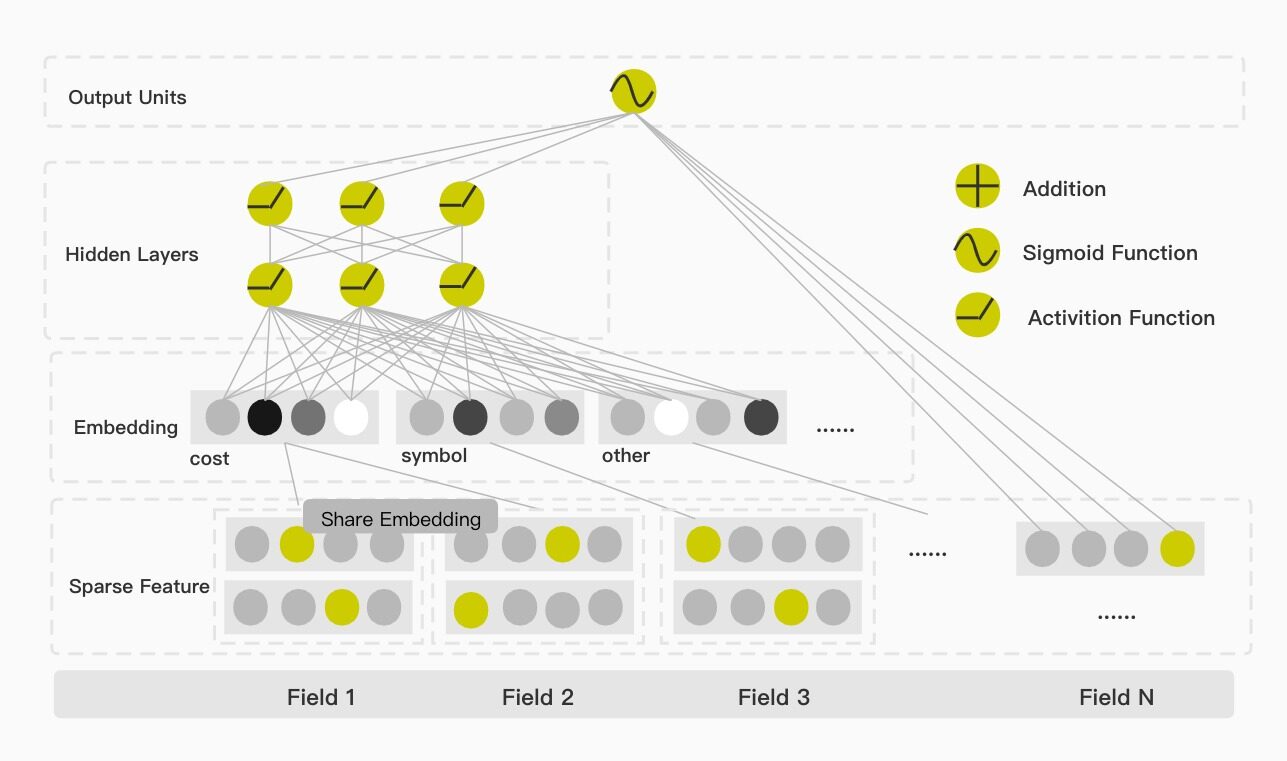
诸如美股订单次数、24 小时订单标的金额和累计 IPO 次数这样的连续型特征被执行分桶操作后,作为 ID 类特征被输入到模型中。我们将金额相关的 Field 进行再归类,作为权值共享组。同理对于标的相关的 Field 也进行权值共享,如下列代码所示:
# Bucketize column24_order_cost_buckets = tf.feature_column.bucketized_column(order_cost,boundaries=[20, 50, 100, 150, 200, 500, 1000, 1500...])# Share embedding 24_order_symbol = tf.feature_column.categorical_column_with_vocabulary_list(key='24_order_symbol', vocabulary_list=symbol_vocabulary, num_oov_buckets=2)ipo_symbol = tf.feature_column.categorical_column_with_vocabulary_list(key='ipo_symbol', vocabulary_list=symbol_vocabulary,num_oov_buckets=2)deep_columns.append(tf.feature_column.shared_embeddings([24_order_symbol, ipo_symbol],dims))$$f_1 = concat(Embedding(Field_i,Bucket(Field_n))$$
Hidden Layers 为全连接层,激活函数为 ReLu。
$$f_{j+1} = ReLu(W_j\bullet f_j+b_j)$$
对于券商领域,有许多特征是有明确的物理含义,因此一部分的人工特征工程同样是必要的。虽然 Wide 侧会增加一部分人工的特征工程量,但是其良好的可解释性,对于理解投资领域某一部分群体的行为,具有一定的指导意义。
离线评估指标及线上实测
个股推荐列表离线评估指标,在召回方式相同的情况下,经过上述的优化,排序侧的离线评估指标和线上实测指标,均具有一定程度的提升。这部分提升来源于新模型对于特征非线性的刻画。同时交易数据的权值共享、标的数据的权值共享对于券商领域的模型也是有一定提升意义的。
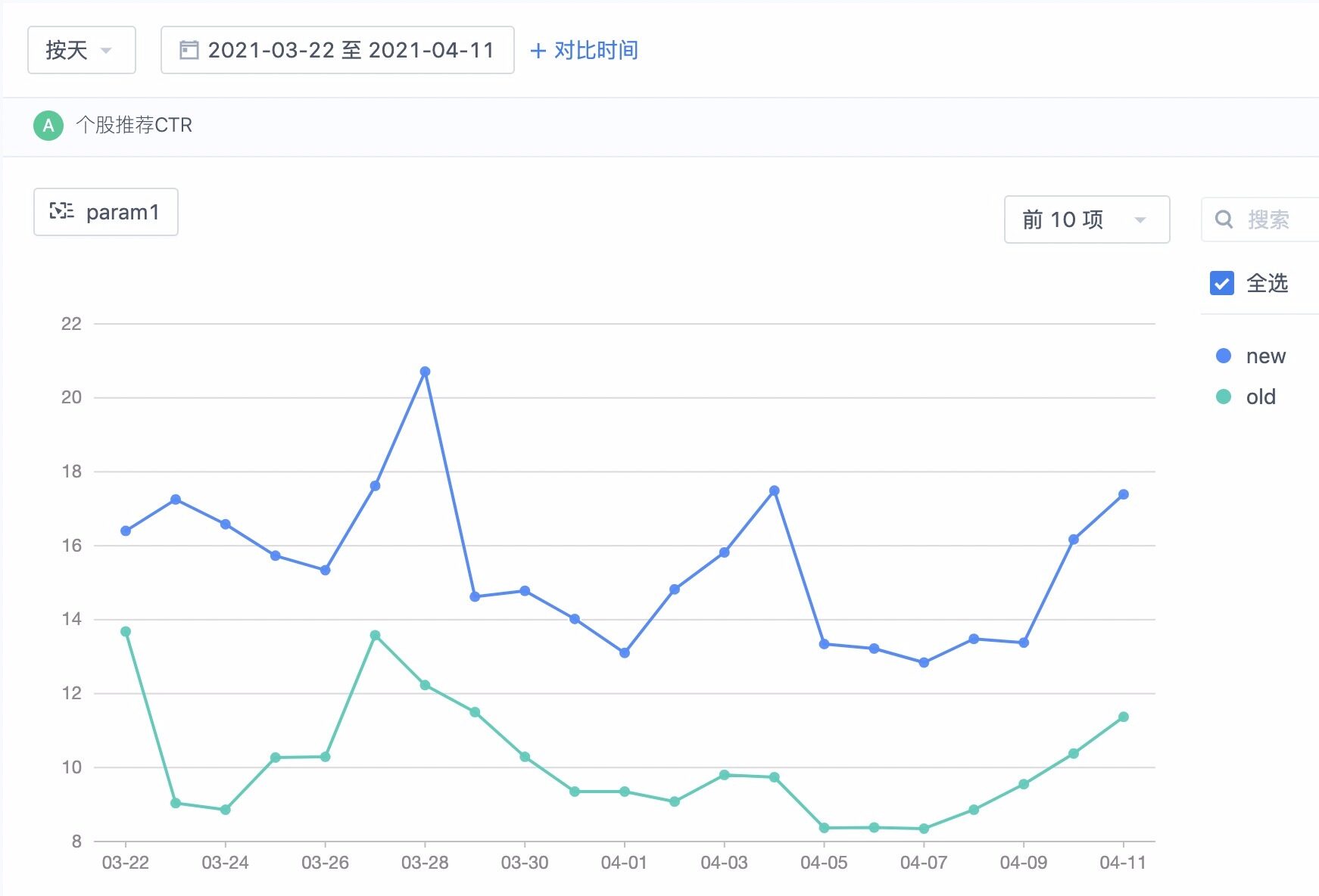
在线上实测过程中,我们保留了一小部分流量作为基线数据(baseline),主要是方便排除市场行情波动的干扰。线上真实环境测试结果表明,优化后的新模型在点击率方面平均提高 5%左右,如下图所示:
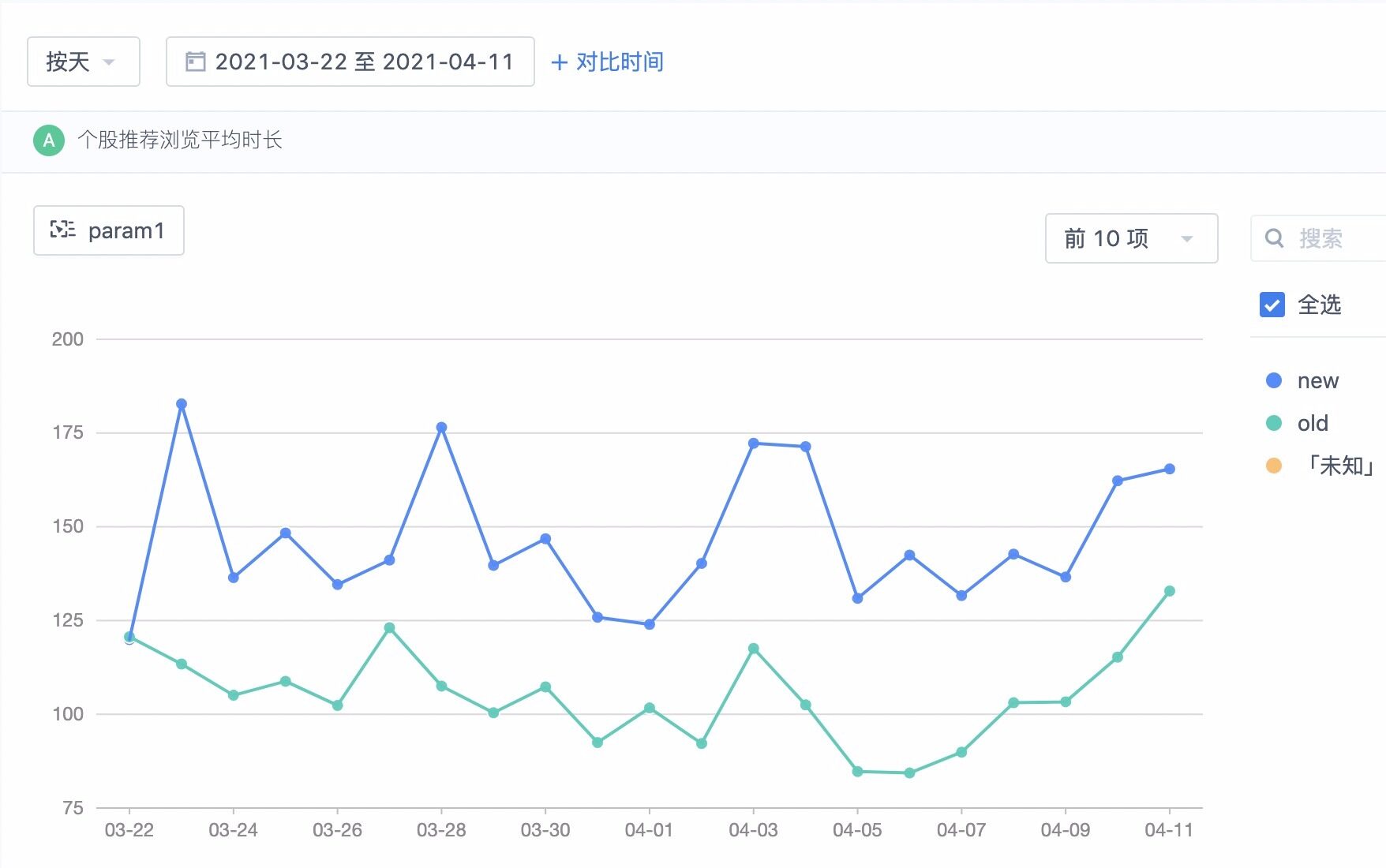
另外,使用 Wide&Deep 算法还帮助我们将用户的内容浏览时长平均提高了 50 秒,如下所示:
未来思考
总体而言,我们将 Wide&Deep 算法应用到老虎证券内容推荐的实践是有一定效果的。未来我们将在以下 5 个方面进行更加深度的思考和改进:
文本本身的挖掘还是有所欠缺,目前仅是通过一些提取标的、关键词来反应文章内容信息;
本次在券商领域的特征工程实践将为后续将机器学习应用到更多的金融相关场景提供经验;
对于模型训练过程中标的的参数矩阵,利用的尚不够充分,后续可基于这个矩阵做一些相关标的推荐等工作;
后续我们会对标的进行舆情监控,将突发事件的新闻,优质的内容推送给用户;
我们目前仍在探索预测用户未来融资金额的模型。此模型的训练数据量是比较少的,但是特征(横向)可用于探索的数据量是比较大的,也就是不能单纯靠堆积数据而获得模型感知上的智能,希望未来能在认知智能上有所突破,将金融领域内更多先验知识应用于模型中。
作者介绍
关舒元,老虎证券社区算法工程师
胡夕,老虎证券社区后端技术负责人
刘琛,老虎证券社区资深工程师




