

人工智能领域中,带标记数据的重要性不言而喻,然而现实中的开发者们却并不具备这样一个带有标记的数据集,而且未标记的数据中往往还有着异常值的存在。面对这种情况,开发者应该怎样解决这一问题呢?本文作者 Selvaratnam Lavinan 提出了一种有趣的解决方案,他利用自编码神经网络产生的数据,再交由“假正类 Reducer”训练,进而提高了数据的精确率和召回率,排除了数据集中的异常值。
问题与解决方案
在大多数你想用人工智能来解决的实际问题中,很可能你并没有一个带标记的数据集。特别是在预测异常值时,你所拥有的数据集,有可能是包含了数以百万计的历史数据,其中也包括异常值。如果你试图从这样一个未标记的数据集中检测这些异常值 / 离群点,并且担心没有标记的数据集,那么本文将为你提供一个有趣的解决方案。
一直以来,每当你遇到不均衡数据集时,训练一个模型并使其正确拟合应该是个很大的麻烦。但现在这正是我们真正需要的。你所需要的是一个由近 1% 异常值组成的不均衡数据集。
自编码神经网络
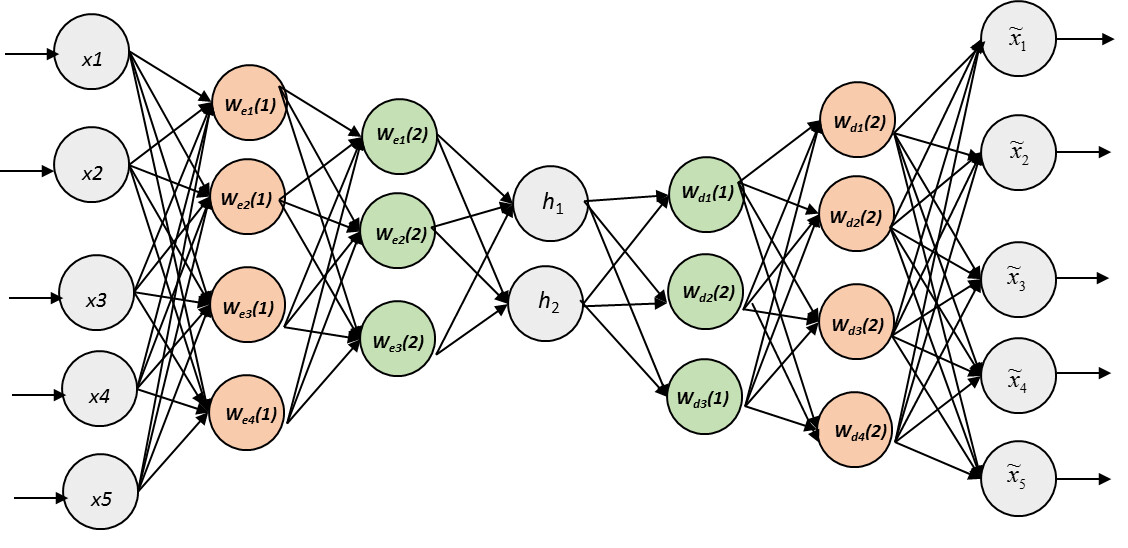
自编码器神经网络的架构(来源:Deep-autoencoders)
与给出多个输入并达到一个或多个输出的典型神经网络不同的是,自编码器神经网络在输出层和输入层具有相同数量的神经元。这基本上意味着输入和输出的数量是相同的。不仅是计数,甚至它试图预测的输出也与输入相同。自编码器神经网络的工作是将数据编码为小代码(压缩),然后解码回来,以重现输入(解压缩)。在上图中,你还可以看到,输出向量是输入向量的近似值。这一特殊属性使我们能够将其用于未标记的数据库。
自编码神经网络通常用于计算机视觉到自然语言处理的降维。要了解更多有关自编码器神经网络的知识,请参阅维基百科的“自编码器”词条。
未标记数据集是怎么回事?
由于我们试图用这个模型再现输入,因此,最适合的损失函数是均方误差(mean square error,MSE)。在训练模型时,该模型试图做的工作是将 MSE 最小化。为了将 MSE 最小化,它应该尽可能地对数据集进行拟合,也就是说,它应该尽可能地重现许多数据。在我们的案例中,由于数据集是由 99% 的正常数据和只有 1% 的异常数据组成,所以在训练时模型会忽略一小部分数据,并拟合其余 99% 的数据,因此,MSE 是非常非常小的。这是背后的核心逻辑,这使得使用它来预测异常(即使是未标记的数据集)成为可能。
如何预测异常?
在训练模型时,它将学习正常数据的特征,并将其压缩成一个小元素,然后将其解码回输入,并有一个小错误。当一个异常通过模型发送时,它将无法重现这个异常,因为它被训练为仅重现正常数据,并最终会产生较大的 MSE。我们需要做的是,计算输出与输入的 MSE,并通过检查输出来正确区分异常,根据需要设置 MSE 的阈值,这样它就有良好的预测精确率和召回率。
不止这些
在大多数情况下,通过不断调整超参数并检查输出以得到最佳阈值,很难得到完全令人满意的结果。但是,我们还有更多的选择。
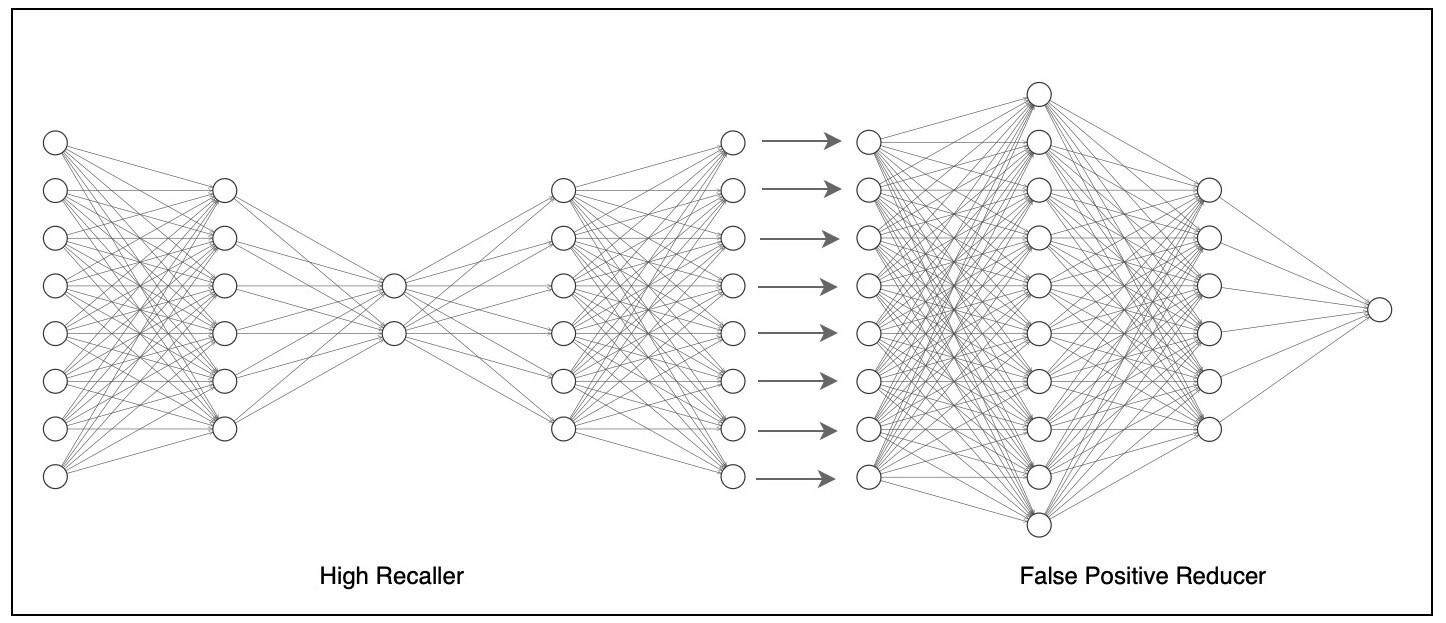
两个神经网络叠加在一起,以提高精确率和召回率。
High Recaller
即使我们用成千上万的数据来训练它,我们得到的异常值也只有几百个。因此,现在可以通过手动检查异常输出,并将其中一些标记为假正类(false positive,FP,即模型将负类别样本错误地预测为正类别)是可能的。因此,我们可以让自编码器神经网络模型作为 High Recaller。这意味着将阈值保持在较低的水平,这样,几乎所有的实际异常都能被检测到(高召回率),同时,还有其他的假正类异常(低精度)。
译注: 此处的 High Recaller 是作者生造词,是指提高召回率的模型。
现在,我们有了一个小数据集,可以手动将其标记为负类(false),并保持其余数据为正类(true)。对于这个手工标注的数据集,让我们引入一个新的人工神经网络模型。
假正类 Reducer
利用现有的数据集,我们可以选择一个神经网络,或者基于复杂性,甚至是随机森林或任何其他典型的机器学习模型,我们都可以简单地对其进行训练。
译注: 此处 Reducer 也是作者生造词,意即减少假正类的模型或方法。
实时预测
现在我们需要做的就是,将这些模型叠加起来,以便在实时预测中,那些由高召回率模型(自编码神经网络)预测为异常的那些通过假正类减少模型(人工神经网络)发送出去。这种神经网络的结合给我们提供了一个具有高召回率和高精度的深度神经网络模型。
作者介绍:
Selvaratnam Lavinan,斯里兰卡 Sysco 实验室实习软件工程师,斯里兰卡莫拉图瓦(Moratuwa)大学电子与通信工程系本科生。
原文链接:

前InfoQ编辑

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论