写在之前
当 Spotify 的用户打开客户端听歌或者搜索音乐人,用户的任何一个触发的事件都会传送回 Spotify 的服务器。事件传输系统(也即,日志收集系统)是个有趣的项目,确保全球用户使用 Spotify 客户端所产生的事件都完全、安全的发送到数据中心。在本系列文章中,将讲述 Spotify 在这方面所做过的工作,而且会详细解说 Spotify 新的事件传输系统架构,并回答“为什么 Spotify 会基于 Google 云平台管理建立自己的新系统?”。
在这个系列的文章中,第一篇讲述的是 Spotify 旧事件传输系统如何工作的以及使用经验总结;第二篇,展示了新事件传输系统的设计,以及为什么选择 Google Cloud 发布/订阅组件作为传输机制来传送事件;在本篇中,我们主要阐述如何通过 Google Dataflow 消费发布的事件,和我这种方法的性能。
Dataflow 导出事件到“小时桶”
Spotify 运行的大部分数据任务都是批量作业,它们要求事件可以可靠的导入持久化存储中。一般对于持久化存储来说,大家常用的是 Hadoop 分布式文件系统(HDFS)和 Hive。为了解决 Spotify 数据存储量和工程师的日益增长,使用 Google 云存储替代 HDFS,使用 Google 的 BigQuery 代替 Hive。
抽取、转换和加载(ETL)任务导入数据到 HDFS 和 Google 云存储中。Hive 和 BigQuery 的输出是通过批量任务从 HDFS 和 Google 云存储中的“小时桶”的数据转换而来的。所有的导出数据都经过分区(基于事件的时间戳)。这个公共接口在第一个事件传输系统中已经介绍过,它是基于 scp 命令按小时从所有的服务器中复制 syslog 文件到 HDFS。
ETL 任务必须确定所有的数据写入“小时桶”进行持久化。只有当不再有数据进入“小时桶”时,这些桶标记写入成功。后面再到达的数据是不能写入已经标记完成的“小时桶”,因为任务一般只从“小时桶”中读取一次。所有后面的数据会写入当前打开的“小时桶”。
为了写 ETL 任务,我们决定试验下 Google Dataflow。Dataflow 是一个写入数据管道以及依托 Google 云管理执行这些管道。它也支持 Google 云 发布/订阅组件、云存储和 BigQuery 开箱即用。
Google Dataflow 的写入管道更像 Apache Crunch 的写入管道,对所有的项目都得使用 FlumeJava 也不是非常吃惊。Google Dataflow 可以提供一个统一的流式处理和批量处理,但 Crunch 仅仅支持批量处理。
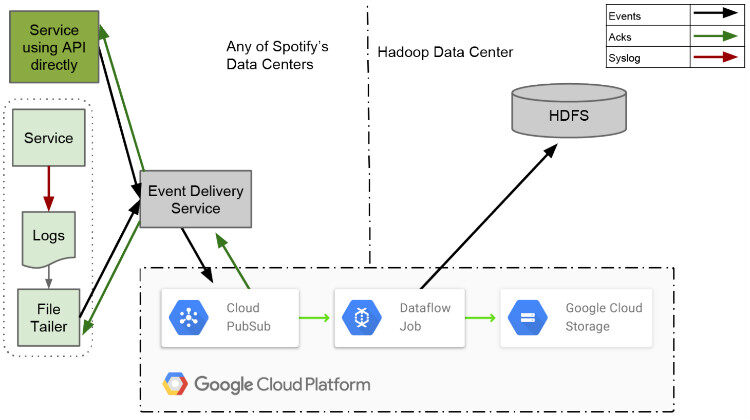
图 1 事件传输系统设计
为了达到端对端的低延迟,我们把 ETL 任务写成流失作业,这样可以持续不断增量的分离数据到“小时桶”。这比之前的系统设计在每小时结束时一次性批量导出数据的延迟性更好。
ETL 任务采用 Dataflow 的窗口概念根据事件时间来分区数据到“小时桶”。Dataflow 的窗口函数可以同时支持事件时间和处理时间,与其它流式框架相比,Dataflow 能建立基于事件时间戳的窗口函数。截至目前为止,只有 Apache Flink 同时支持处理时间和事件时间的窗口函数。
每个窗口包含一个或者多个窗格,每个窗格包含一个数据集。窗口的窗格只有在数据被 GroupByKey 后才会发送。因为 GroupByKey 通过 key 和窗口进行分组,所有在单个窗格的数据有相同的 key 并属于同一个窗口。Dataflow 提供一个水印机制来确定一个窗口的关闭,它用输入数据流的事件时间来计算终止点。
ETL 的深度探索
这部分将详细的讲述我们建立 Dataflow 的 ETL 任务遇到的挑战,如果你之前没有 Dataflow 或者类似系统的使用经验,那真的有点挑战性。
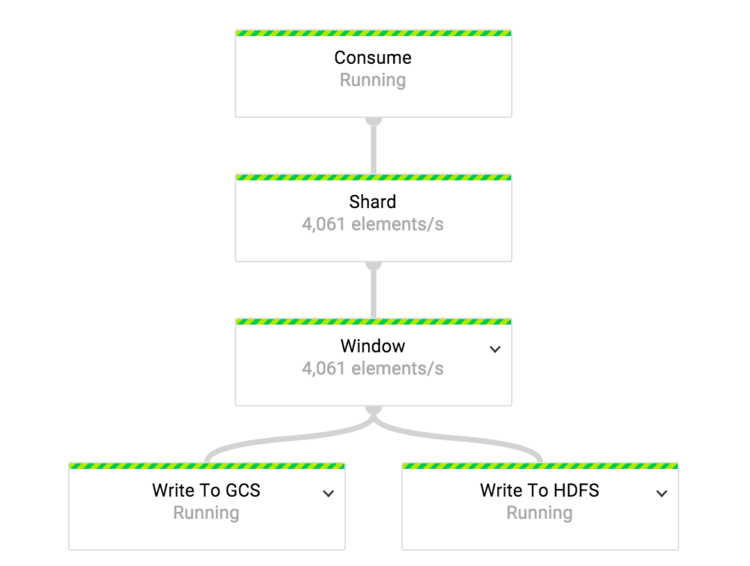
图 2 ETL 任务管道
在我们的事件传输系统中,事件类型与 Google 云发布分/订阅 topic 比例是 1:1,单个 ETL 任务消费单个类型的事件流。我们使用单独的 ETL 任务来消费所有类型的数据。
为了跨 worker 平均分布负载,在数据流到达转换前是共享的。“窗口”是一个混合的转换。这个转换操作的第一步是对输入的事件数据流按小时长度划分窗口。
@Override
public PCollection<kv><string iterable=""><gabo.eventmessage>>> apply(
final PCollection<kv><string gabo.eventmessage="">> shardedEvents) {
return shardedEvents
.apply("Assign Hourly Windows",
Window.<kv><string gabo.eventmessage="">>into(
FixedWindows.of(ONE_HOUR))
.withAllowedLateness(ONE_DAY)
.triggering(
AfterWatermark.pastEndOfWindow()
.withEarlyFirings(AfterPane.elementCountAtLeast(maxEventsInFile))
.withLateFirings(AfterFirst.of(AfterPane
.elementCountAtLeast(maxEventsInFile),AfterProcessingTime
.pastFirstElementInPane().plusDelayOf(TEN_SECONDS))))
.discardingFiredPanes())
.apply("Aggregate Events", GroupByKey.create());
}</string></kv></string></kv></gabo.eventmessage></string></kv>
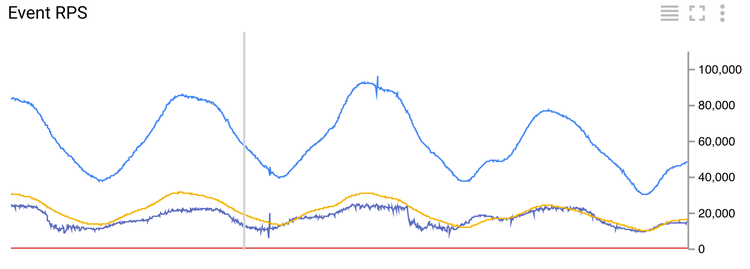
图 3 分配小时窗口的转换函数代码
在分配窗口时,会在每个窗口关闭前每 N 个元素发送一个窗格。由于这个触发使得“小时桶”可以不断的被进来的数据填满。这个触发不仅仅达到了限制低导出延迟,而且也限制了 GroupByKey 的工作区数据量。大量的数据收集在窗格中,需要放进 worker 的内存中,因为 GroupByKey 时一个内存限制的转换。
图 4 每秒到达事件数
为了监控每秒到达事件数流过 ETL 任务,所有的监控指标被送到 Google 云监控。每分钟计算五分钟时间窗口里的指标。事件时间线信息会在分配事件到窗口内后获取。如果监控转换应用到“Aggregate Events”的输出,我们可以得到完美的时间线。这种方法的缺点是指标被发出的时间不可预测性,因为窗口的触发是基于元素数目和事件的时间。
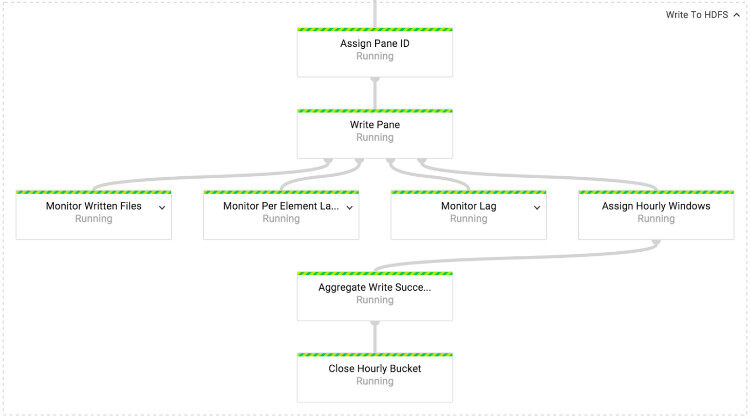
图 5 “Write to HDFS/GCS”转换
在“Write to HDFS/GCS”转换操作,我们会写入数据到 HDFS 或者 Google 云存储(GCS),HDFS 和 Google 云存储的写入数据的机制一致,仅有的不同是底层 API 使用。Dataflow 的所有 APIs 都封装在 IOChannelFactory 接口。
为了保证每个文件只写入一个窗格,即使出现失败的情况,每个发出去的窗格分配一个唯一的 ID。文件以 Avro 格式写入每个事件 schema ID。每个窗格写入桶里,并以事件时间为终止标记。后来的窗格写入当前的“小时桶”在 Spotify 数据生态系统中是不被允许的。 PaneInfo 用来探测窗格的即时性,当窗格创建时就构建 PaneInfo 对象。一个“小时桶”的完成标记只被写入一次。
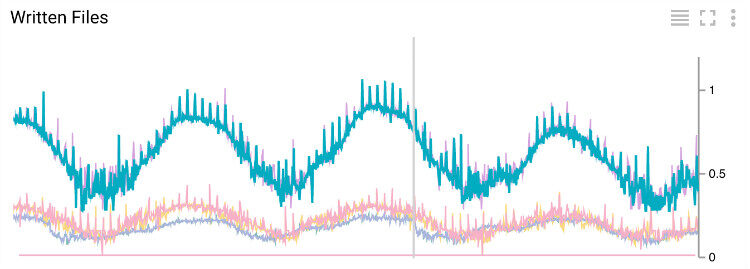
图 6 每秒文件写入数目
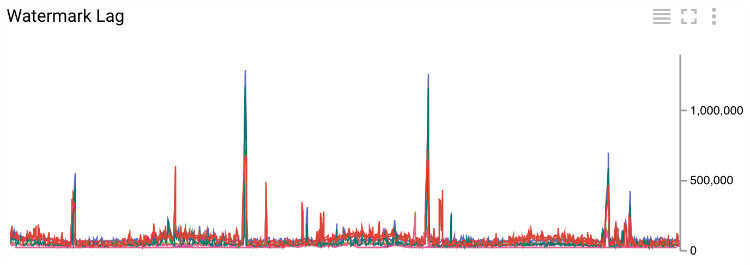
图 7 每毫秒“分水岭标记”延迟
“Write Pane”操作会发送指标来显示每秒有多少文件写入、事件的平均延迟和“分水岭标记”的延迟。“分水岭标记”的延迟是在写入文件到 HDFS/GCS 之后,它直接反应系统端对端的延迟。从图 8 可以看出,当前的“分水岭标记”的延迟大部分在 200s (~3.5 分钟)以下,偶尔会蹦到 1500s(~25 分钟)。大延迟是因为通过 VPN 连接写入 Hadoop 集群的,当前事件系统的端对端的延迟最好的情况一天是 2 小时,平均是 3 小时。
ETL 任务下一步打算
ETL 任务当前还在原型阶段,总共有 4 个 ETL 任务在运行。最小的任务每秒消费大概 30 个事件,而峰值每秒是 100k 事件。
我们还没有找到好的办法计算 ETL 任务的最优 worker 数目,worker 数目都是通过手动试错得到。当前,最小的 ETL 任务设置 2 个 worker,最大的任务设置 42 个 worker。有趣的事是 ETL 任务的性能一直被内存影响。对于一个每秒处理大概 20k 事件的管道,我们用 24 个 worker;另外一个管道处理相同速率的事件,但事件的消息大小平均是前者的四分之一,这时我们仅仅使用 4 个 worker。当 Google Dataflow 的自动扩展功能上线之后这个问题将变的很容易。
我们必须确保每个任务重启之后不会丢失数据。在测试过程中出现过这方面的问题,经过和Dataflow 工程师的协作,已经修复了问题。
最后,我们需要定一个好的CI/CD 模型来让ETL 任务更快、更安全。这个问题比较棘手:需要管理每个事件类型进入一个ETL 任务,我们总共大概有1000 个事件类型。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




