背景
当今互联网,数据呈现爆炸式增长,社交网络、移动通信、网络视频、电子商务等各种应用往往能产生亿级甚至十亿、百亿级的海量小文件。由于在元数据管理、访问性能、存储效率等方面面临巨大的挑战,海量小文件问题成为了业界公认的难题。
业界的一些知名互联网公司,也对海量小文件提出了解决方案,例如:著名的社交网站 Facebook,存储了超过 600 亿张图片,专门推出了 Haystack 系统,针对海量小图片进行定制优化的存储。
白山云存储 CWN-X 针对小文件问题,也推出独有的解决方案,我们称之为 Haystack_plus。该系统提供高性能数据读写、数据快速恢复、定期重组合并等功能。
Facebook 的 Haystack
Facebook 的 Haystack 对小文件的解决办法是合并小文件。将小文件数据依次追加到数据文件中,并且生成索引文件,通过索引来查找小文件在数据文件中的offset 和size,对文件进行读取。
Haystack 的数据文件部分

Haystack 的数据文件,将每个小文件封装成一个 needle,包含文件的 key、size、data 等数据信息。所有小文件按写入的先后顺序追加到数据文件中。
Haystack 的索引文件部分:
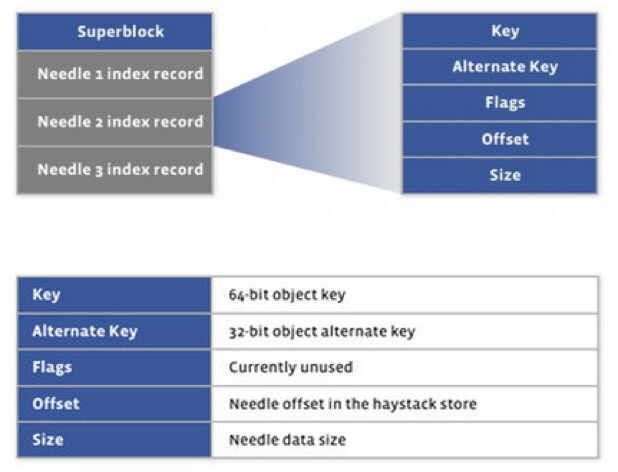
Haystack 的索引文件保存每个 needle 的 key,以及该 needle 在数据文件中的 offset、size 等信息。程序启动时会将索引加载到内存中,在内存中通过查找索引,来定位在数据文件中的偏移量和大小。
Haystack 面临的问题
Facebook 的 Haystack 特点是将文件的完整 key 都加载到内存中,进行文件定位。机器内存足够大的情况下,Facebook 完整的 8 字节 key 可以全部加载到内存中。
但是现实环境下有两个主要问题:
- 存储服务器内存不会太大,一般为 32G 至 64G;
- 小文件对应的 key 大小难控制,一般选择文件内容的 MD5 或 SHA1 作为该文件的 key。
场景举例:
- 一台存储服务器有 12 块 4T 磁盘,内存为 32GB 左右。
- 服务器上现需存储大小约为 4K 的头像、缩略图等文件,约为 10 亿个。
- 文件的 key 使用 MD5,加上 offset 和 size 字段,平均一个小文件对应的索引信息占用 28 字节。
- 在这种情况下,索引占用内存接近 30GB,磁盘仅占用 4TB。内存消耗近 100%,磁盘消耗只有 8%。
所以索引优化是一个必须要解决的问题。
Haystack_plus
Haystack_plus 的核心也由数据文件和索引文件组成。
1. Haystack_plus 的数据文件

与 Facebook 的 Haystack 类似,Haystack_plus 将多个小文件写入到一个数据文件中,每个 needle 保存 key、size、data 等信息。
2. Haystack_plus 的索引文件
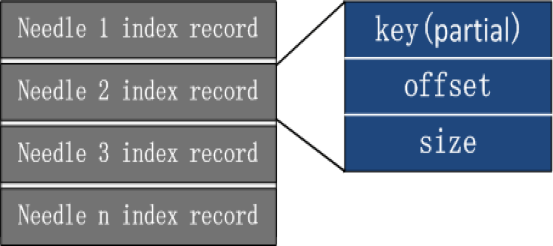
索引是我们主要优化的方向:
- 索引文件只保存 key 的前四字节,而非完整的 key;
- 索引文件中的 offset 和 size 字段,通过 512 字节对齐,节省 1 个字节;并根据整个 Haystack_plus 数据文件实际大小计算 offset 和 size 使用的字节数。
3. Haystack_plus 的不同之处
数据文件中的 needle 按照 key 的字母顺序存放。
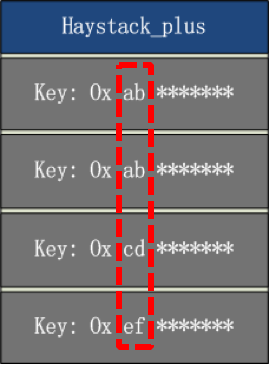
由于索引文件的 key,只保存前四字节,如果小文件 key 的前四字节相同,不顺序存放,就无法找到 key 的具体位置。可能出现如下情况:
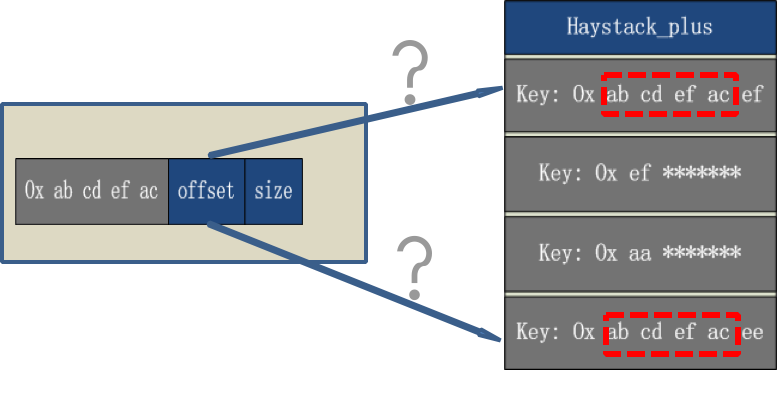
例如:用户读取的文件 key 是 0x ab cd ef ac ee,但由于索引文件中的 key 只保存前四字节,只能匹配 0x ab cd ef ac 这个前缀,此时无法定位到具体要读取的 offset。
我们可以通过 needle 顺序存放,来解决这个问题:
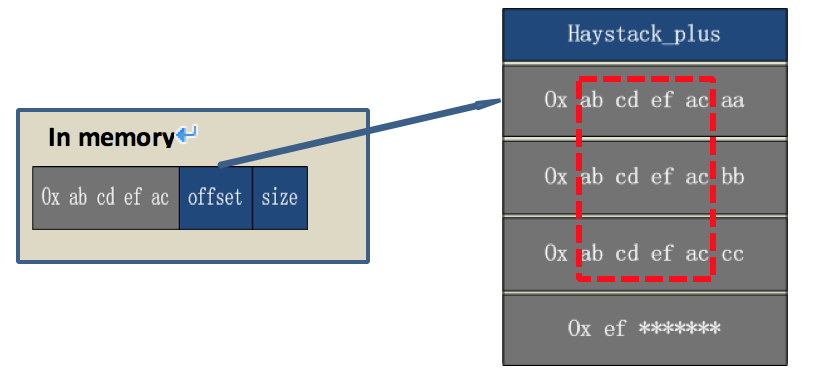
例如:用户读取文件的 key 是 0x ab cd ef ac bb,匹配到 0x ab cd ef ac 这个前缀,此时 offset 指向 0x ab cd ef ac aa 这个 needle,第一次匹配未命中。
通过存放在 needle header 中的 size,我们可以定位 0x ab cd ef ac bb 位置,匹配到正确 needle,并将数据读取给用户。
4. 索引搜索流程为
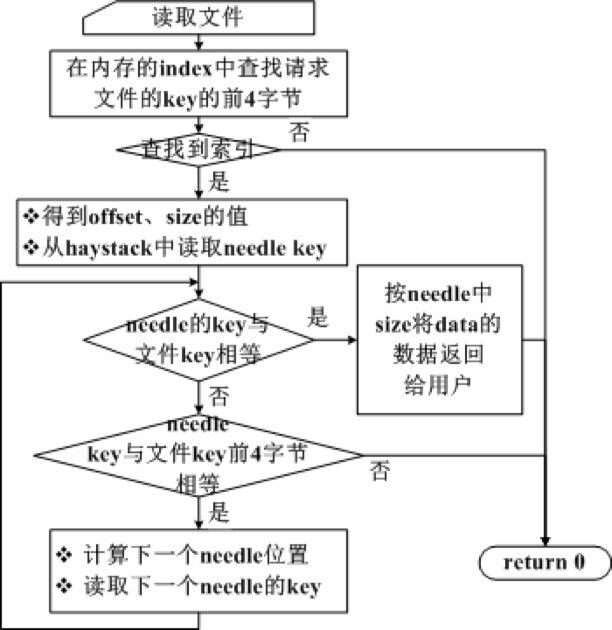
5. 请求不存在的文件
问题:我们应用折半查找算法在内存查找 key,时间复杂度为 O(log(n)),其中 n 为 needle 数目。索引前缀相同时,需要在数据文件中继续查找。此时访问的文件不存在时,容易造成多次 IO 查找。
解决方法:在内存中,将存在的文件映射到 bloom filter 中。此时只需要通过快速搜索,就可以排除不存在的文件。
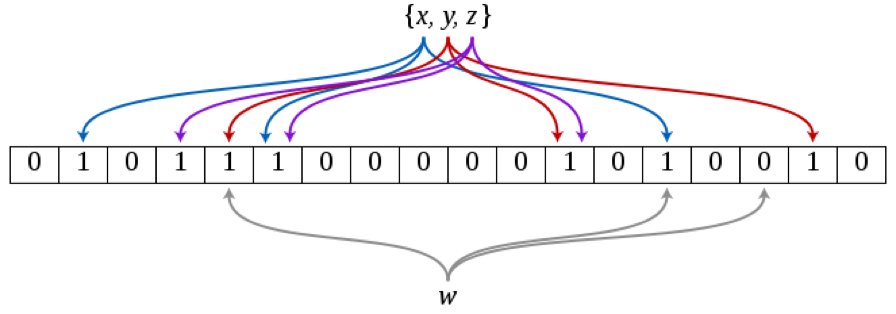
时间复杂度为 O(k),k 为一个元素需要的 bit 位数。当 k 为 9.6 时,误报率为 1%,如果 k 再增加 4.8,误报率将降低为 0.1%。
6. 前缀压缩,效果如何
Haystack_plus 与 Facebook Haystack 内存消耗的对比,场景举例,文件(如:头像、缩略图等)大小 4K,key 为 MD5:
内存消耗对比
Key
offset
size
Haystack
全量 key,16 字节
8 字节
4 字节
Haystack_plus
4 字节
4 字节
1 字节
注:Haystack 的 needle 为追加写入,因此 offset 和 size 大小固定。Haystack_plus 的 key 使用其前 4 字节,offset 根据 Haystack_plus 数据文件的地址空间计算字节数,并按 512 字节对齐;size 根据实际文件的大小计算字节数,并按 512 对齐。
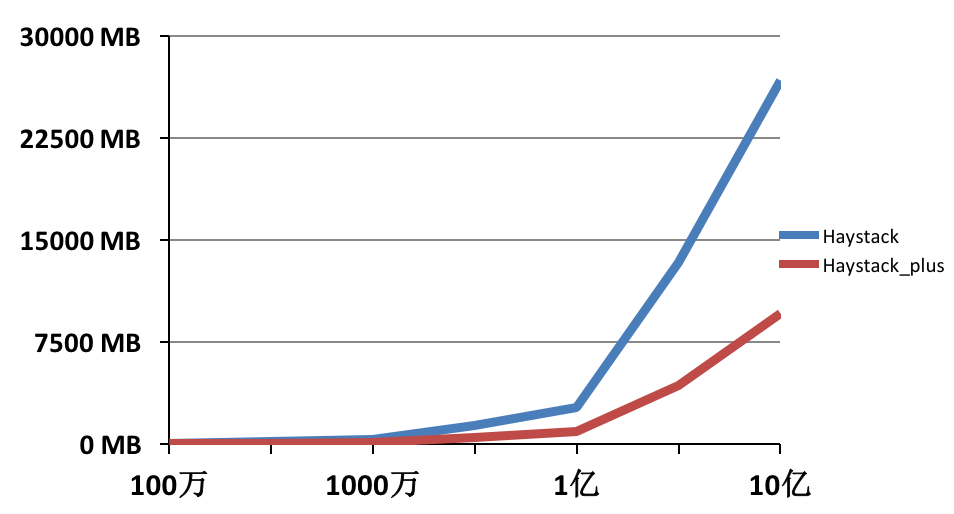
从上图可以看出在文件数量为 10 亿的情况下,使用 Facabook 的 Haystack 消耗的内存超过 26G,使用 Haystack_plus 仅消耗 9G 多内存,内存使用降低了 2/3。
7. 索引优化根本就停不下来
10 亿个 4K 小文件,消耗内存超过 9G。Key 占用 4 字节,Offset 占用 4 字节,还需要再小一些。
索引分层
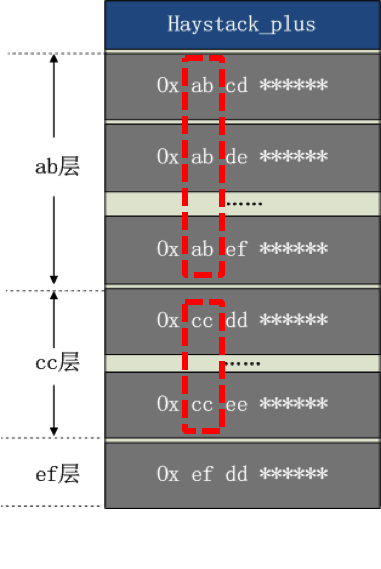
根据文件 key 的前缀,进行分层,相同的前缀为一层。
分层的好处
减少 key 的字节数
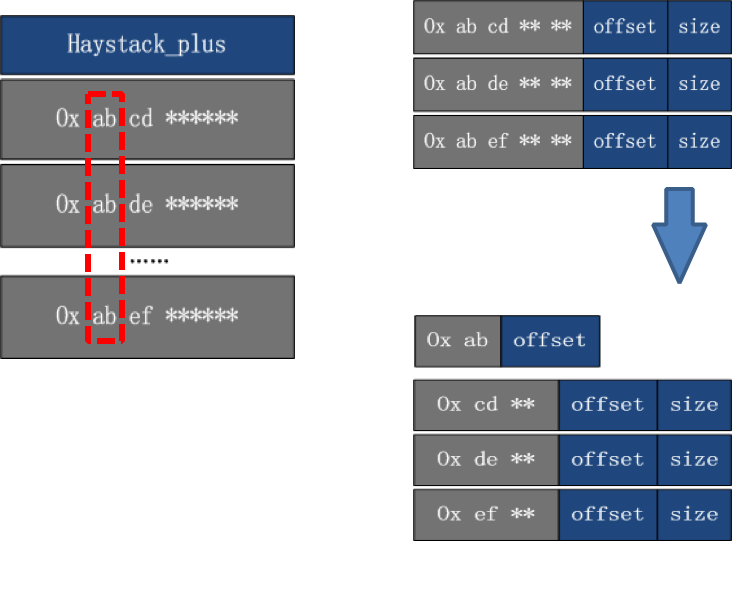
通过分层,只保存一份重复的前缀,节省 key 的字节数。
减少 offset 的字节数
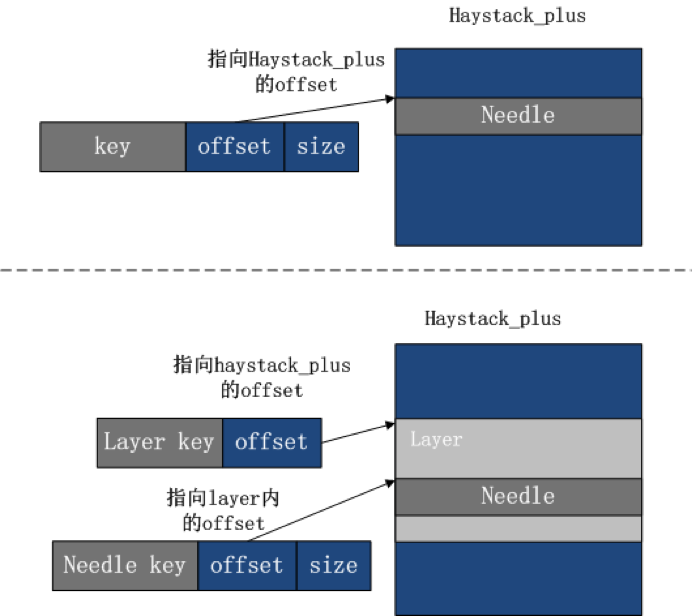
优化前的 offset,偏移范围为整个 Haystack_plus 的数据文件的地址空间。
优化后,只需在数据文件中的层内进行偏移,根据最大的层地址空间可以计算所需字节数。
分层后的效果
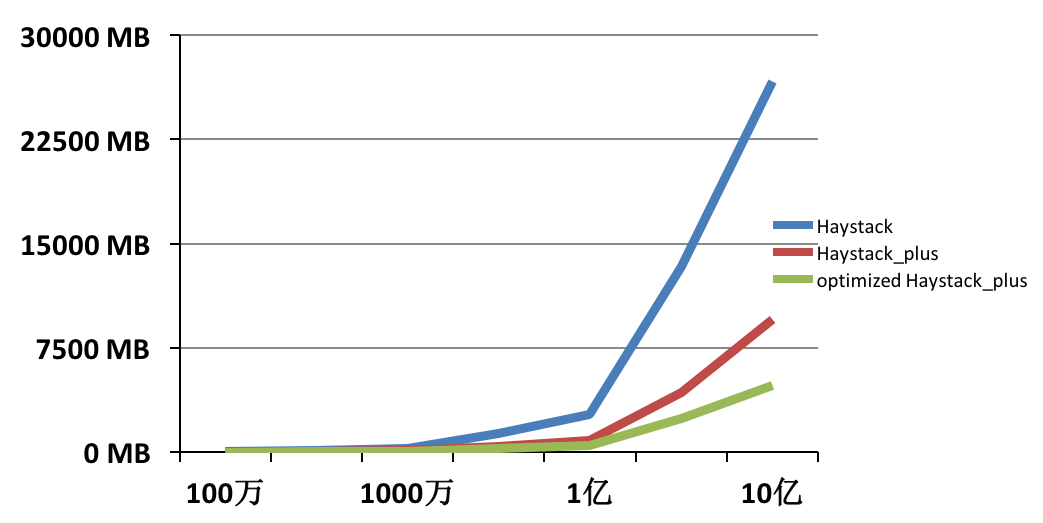
从上图可以看出,进行分层后,内存消耗从优化前的 9G 多,降低到 4G 多,节省了一半的内存消耗。
Haystack_plus 整体架构
1. Haystack_plus 组织
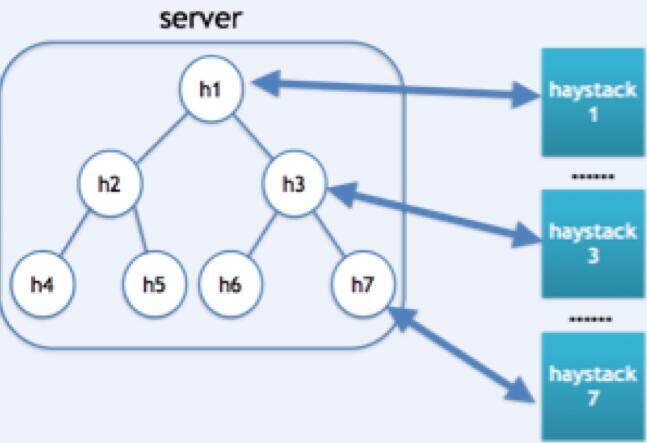
每台服务器上,我们将所有文件分成多个 group,每个 group 创建一个 Haystack_plus。系统对所有的 Haystack_plus 进行统一管理。
读、写、删除等操作,都会在系统中定位操作某个 Haystack_plus,然后通过索引定位具体的 needle,进行操作。
2. 索引组织
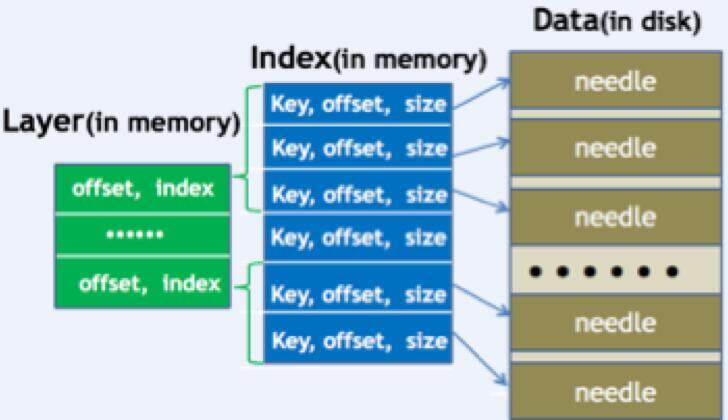
之前已经介绍过,所有 needle 顺序存放,索引做前缀压缩,并分层。
3. 文件组成
- chunk 文件:小文件的实际数据被拆分保存在固定数量的 chunk 数据文件中,默认为 12 个数据块;
- needle list 文件:保存每个 needle 的信息 (如文件名、offset 等);
- needle index 和 layer index 文件:保存 needle list 在内存中的索引信息;
- global version 文件:保存版本信息,创建新 version 时自动将新版本信息追加到该文件中;
- attribute 文件:保存系统的属性信息 (如 chunk 的 SHA1 等);
- original filenames:保存所有文件原始文件名。
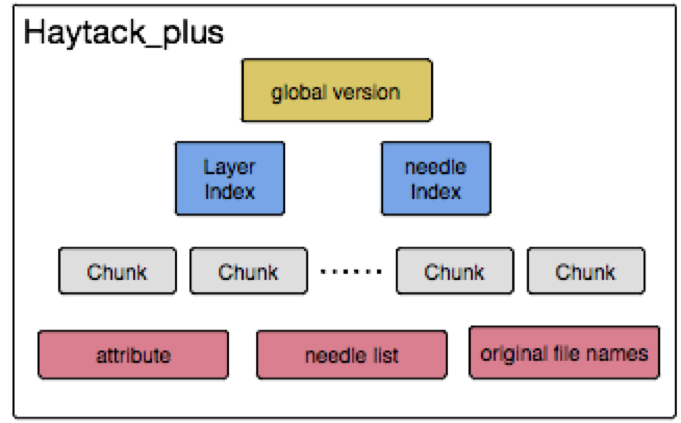
A、Haystack_plus 数据文件被拆分为多个 chunk 组织,chunk1,chunk2,chunk3……
B、分成多个 chunk 的好处:
1. 数据损坏时,不影响其它 chunk 的数据;
2. 数据恢复时,只需恢复损坏的 chunk。
C、每个 chunk 的 SHA1 值存放在 attribute 文件中。
4. 版本控制
由于 needle 在数据文件中按 key 有序存放,为不影响其顺序,新上传的文件无法加入 Haystack_plus,而是首先被保存到 hash 目录下,再通过定期自动合并方式,将新文件加入到 Haystack_plus 中。
合并时将从 needle_list 文件中读取所有 needle 信息,将删除的 needle 剔除,并加入新上传的文件,同时重新排序,生成 chunk 数据文件、索引文件等。
重新合并时将生成一个新版本 Haystack_plus。版本名称是所有用户的文件名排序的 SHA1 值的前 4 字节。
每半个月系统自动进行一次 hash 目录检查,查看是否有新文件,并计算下所有文件名集合的 SHA1,查看与当前版本号是否相同,不同时说明有新文件上传,系统将重新合并生成新的数据文件。
同时,系统允许在 hash 目录下超过指定的文件数时,再重新创建新版本,从而减少重新合并次数。

版本的控制记录在 global_version 文件中,每次创建一个新版本,版本号和对应的 crc32 将追加到 global_version 文件(crc32 用于查看版本号是否损坏)。
每次生成新版本时,自动通知程序重新载入索引文件、attribute 文件等。
5. 数据恢复
用户的文件将保存成三副本存放,因此 Haystack_plus 也会存放在 3 台不同的机器上。
恢复场景一:
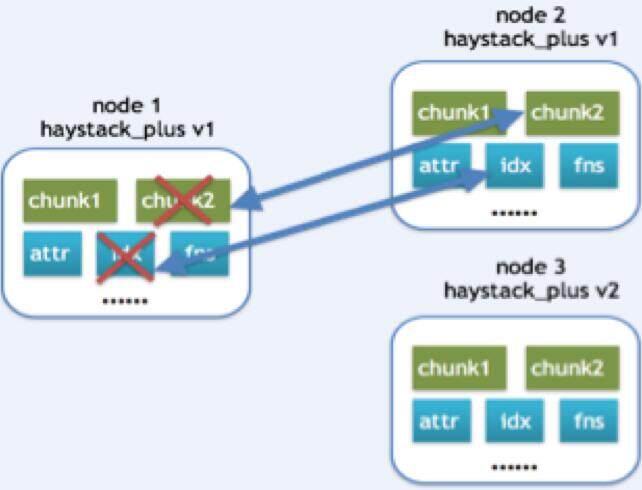
当一个 Haystack_plus 的文件损坏时,会在副本机器上,查找是否有相同版本的 Haystack_plus,如果版本相同,说明文件的内容都是一致,此时只需将要恢复的文件从副本机器下载下来,进行替换。
恢复场景二:
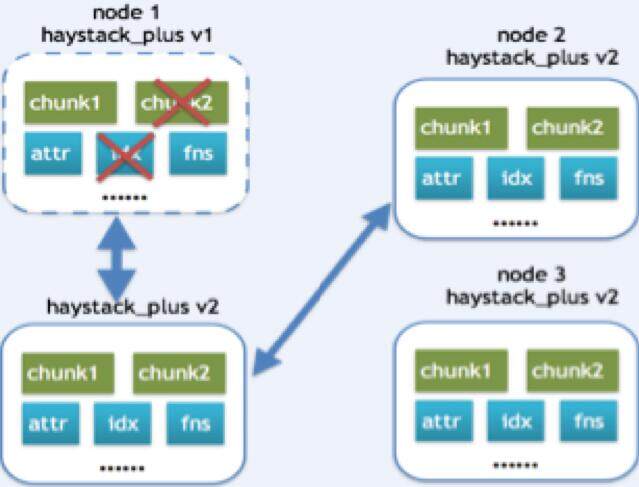
如果副本机器没有相同版本的 Haystack_plus,但存在更高版本,那此时可以将该版本的整个 Haystack_plus 从副本机器上拷贝下来,进行替换。
恢复场景三:
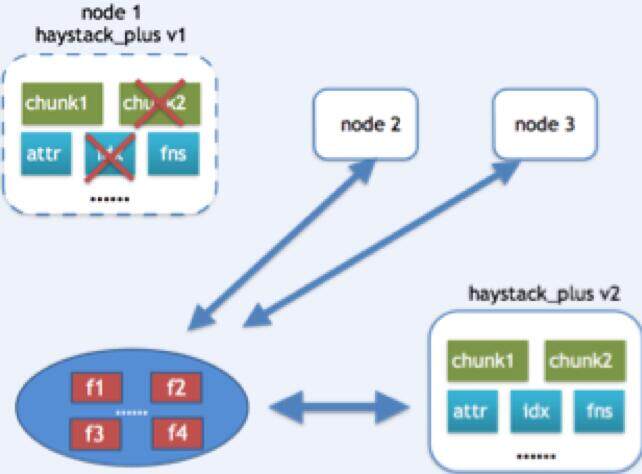
如果前两种情况都不匹配,那就从另外两台副本机器上,将所有文件都读到本地上的 hash 目录下,并将未损坏的 chunk 中保存的文件也提取到 hash 目录下,用所有文件重新生成新版本的 Haystack_plus。
Haystack_plus 效果如何
在使用 Haystack_plus 后一段时间,我们发现小文件的整体性能有显著提高,RPS 提升一倍多,机器的 IO 使用率减少了将近一倍。同时,因为优化了最小存储单元,碎片降低 80%。
使用该系统我们可以为用户提供更快速地读写服务,并且节省了集群的资源消耗。
作者简介:陈闯,花名“战士雷欧”,白山超级工程师。Linux 内核、Nginx 模块、存储架构资深开发人员,7 年以上存储架构、设计及开发经验,先后就职于东软、中科曙光、新浪、美团,擅长独立进行 Haystack、纠删码等各种项目研发,爱好不断降低 IO、挑战冗余度底线。白山滑板车选手专业十级,会漂移,正积极备战方庄街道第 6 届动感滑板车运动会,家庭梦想是为爱妻赢得无硅油洗发水。
感谢魏星对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




