
前 言
RTP(Real Time Prediction) [1] 平台是阿里内部一个通用的在线预测平台,广泛支持淘天、本地生活、AIDC、菜鸟、大文娱等搜索和推荐业务场景的 DLRM(Deep Learning Recommendation Model)部署。自 2022 年起,RTP 开始探索大规模 GPU-Disaggregation 技术的落地,运用 RDMA 高性能网络通信构建 GPU-CPU 全分离的分布式推理系统。这项工作在今年被收录至 NSDI25。借此机会,我想回顾并解读当年的做的 Ranking 技术,也算是对过去两年努力的一个交代。
DLRM 模型的特点
鉴于现在 LLM 很火,我们直接用表格对比一下两者在线部署角度的差异,以便更好地理解问题。如果想了解更多 DLRM 的信息,可以参考原文,或典中典 W&D [2] 以及我们的系统介绍 [3]。
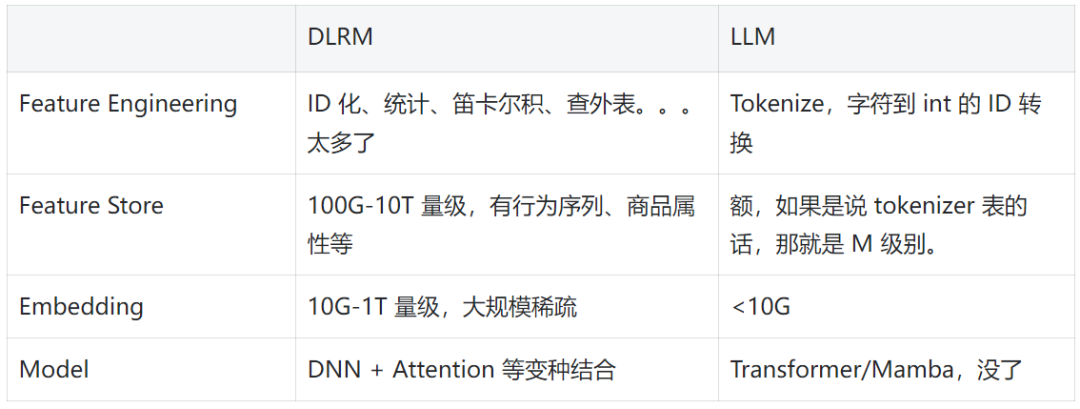
对应算力特点

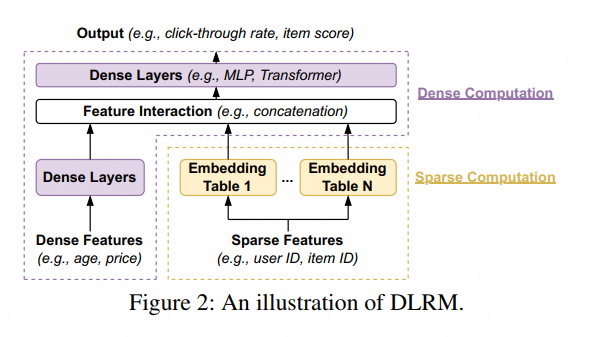
DLRM 算法工程同学还是很苦逼的,每天被算法同学用枪指着要上线特征、优化模型。而算法工程同学不光要完成功能,满足延迟需求,自己还要把成本优化下来。(大模型时代,部署工作确实好开展了一点,但更卷了)GPU 或者 CPU 上的优化不是本文讨论的重点,假设优化 [4][5] 都做了,到部署环节,还会碰到什么问题?

每个模型资源规格不一样,本来不是一个问题。反正做 AI 的人可以不懂 K8s,我就申请资源,那你就应该分配给我,CPU、MEM、GPU 在 yaml 里写好就可以了。但一般来说,我们的机器配置 CPU、MEM 都是成比例的,以阿里云 ECS 机器规格为例,CPU:MEM 几乎是严格的 1:4,对应的一台物理机上实际硬件其实也是 1:4 的比例,这样均匀的切才好卖。而如果一个模型的 CPU:MEM 需求比例不是 1:4 的话,或多或少存在浪费情况。
调度其实是在全局范围解装箱问题,想把 CPU 或 MEM 的坑填平是需要技巧的。
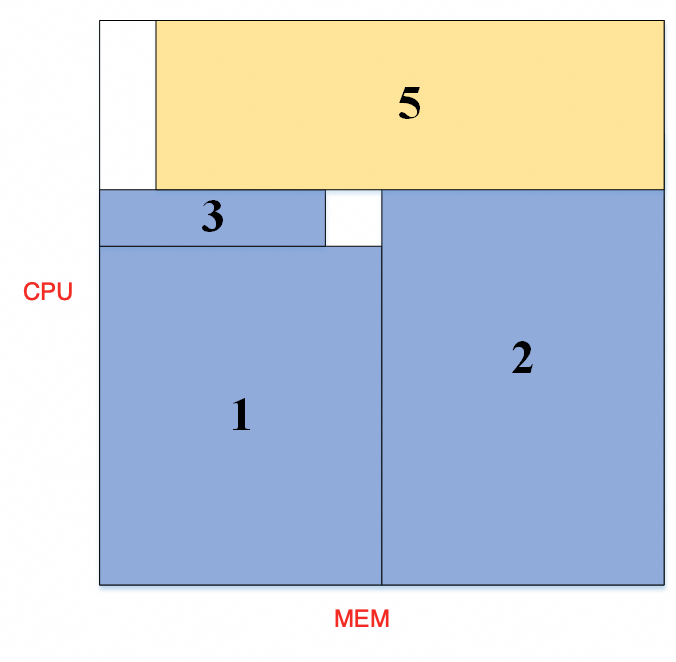
此时如果我们引入第三个资源维度 GPU。。。

Embedding 表或者 Feature 表太大,我们可以把它切分成多分,用分布式存储的方式解决,这样可以调和 CPU MEM 的比例;而 CPU 和 GPU 的比例怎么调和呢,怎样充分利用好 CPU 和 GPU 呢?这就来到了本篇论文的主题。
DLRM 部署的挑战
文章在 2.2 Challenges in DLRM Deployment 段给出了两个 Challenge。
C1: Resource allocation in GPU clusters with high allocation rates.
刚才我们是从乐观的角度看,调和好各个资源维度之后,资源分配更容易了。反过来想,如果比例不对会怎么样呢?从单机看,会存在某些维度资源的浪费;从全局看,会出现资源剩余很多但无法分配的现象。每年我们从 1 月到 8 月都生活的很快乐,从 9 月开始备战大促,大家就会把 K8s 小哥的头按在键盘上扩容机器、腾挪资源。不是他不努力,多样实例规格导致的碎片太严重了。

这是分配效率的问题。
C2: Resource provisioning during seasonal traffic spikes
seasonal 说的就是冬天的双十一和双十二,大家过不过节我不知道,反正我们是在公司过节的。如果每年如果只有这两天很热闹的话,剩下 363 天的集群水位都是平淡无奇的,我们就为了 2 天的峰值资源多付了 363 天的钱,这是 100 倍的成本上升。而从日常的角度来看,淘天主要流量来自国内,必然存在着白天的流量高峰和晚上的流量低谷,睡觉的 8 小时机器资源也是空闲的。
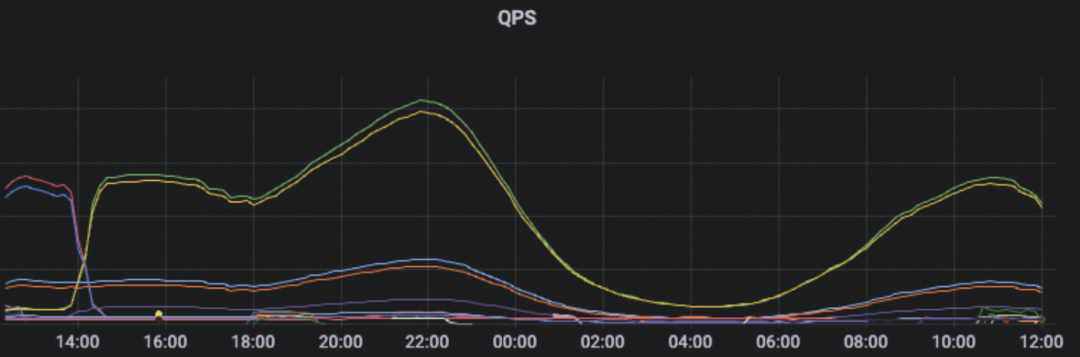
削峰填谷是很自然的提升资源利用率的手段。填谷,就是找到那些时效性要求低的任务在低谷期运行就可以了;削峰,就是让时效性低的任务让出资源,跑在线时效性高的服务。如果我们讨论的是搜推广 AI 在线服务,在 GPU 上做削峰填谷,很自然地就可以想到用 离线训练任务来共同完成削峰填谷,让资源在推理和训练上复用。
传统搜推广稀疏 ps-worker 架构的训练模型,资源需求跟在线服务类似,可以统一到几种规格上去。而当大家逐渐转向 dense 和大模型之后,情况发生了变化。现在是 8 卡 A100 无人问津、小红书上 H200 跳楼甩卖的年代,我们要让搜推广模型推理去用高性能训练卡。假设算法工程同学刚刚把实例规格调成了 32c128g 1xL20,这时候你说我们要用 8xH100 跑推理了,好像一个机架的 CPU 都不够他用啊。大算力 GPU 让单实例的计算资源比例调和更难了。

这是利用效率的问题。
总结一下
我们需要解决的几个问题和路径
提升分配效率 -> 减少规格数量 -> 资源比例归一化
提升利用效率 -> 削峰填谷 -> 训推复用资源 -> 推理用大算力 GPU -> 资源比例灵活化
DLRM Disaggregation
理想的困难
对于一个 AI 服务来说,我们应该让他的 CPU/MEM 的比例归一化,让他的 CPU/GPU 比例灵活化。对应论文中 CN(CPU 节点)和 HN(异构计算节点)两部分,CN 保持 CPU:MEM=1:4,CN:HN 做到任意的 n:m 灵活配比。从前我们有存算分离,现在我们可以发明算算分离!Disaggregation make ALI great again!

算算分离并不难,因为 RTP 系统已经是全图化的,我们只要把 CPU 子图和 GPU 子图切开,分别跑到两个容器实例,两边网络通信就好了。这个概念很容易实现出来,但实际上我们还要考虑更多问题。
在线服务多引入了一次网络通信开销,需要做到足够低的延迟和错误率。
通信数据量和网络带宽分别是多少?
网络上的距离多远,这个固有延迟有多少?
不同场景的 CTR/CVR 模型推理端到端延迟在 20-40ms 左右,如果 DLRM 大量的 Feature 直接通过 TCP RPC 传输,几乎会让端到端延迟翻倍。这是我们不能接受的。
训练怎样把资源释放给推理,两边的约束是怎样的?
推理的 GPU 部分 CPU 消耗够小么,是不是能跑上去很多 GPU 推理 worker,充分利用好训练单机多卡的算力?
推理能把训练 GPU 用起来么?用的够好么?
假设我们使用的 128c1024g 8GPU 4RNIC(200G) 的训练节点,平均每个 GPU 可以使用 16c,这个约束要求 CPU 上只能运行控制流,不放做任何模型逻辑。平均每个 GPU 12.5Gbyte/s 的网络带宽,而之前 CPU-> GPU 我们使用 PCIE Gen4 有 32Gbyte/s,这个速率够吗?从集群角度看,传统网络架构下交换机有一定收敛比,网卡容量够,交换机容量不一定够。
现实的选择
推理系统、调度系统、网络基础设施分别都要去各自解决一部分问题,4 Prism Design 段落讲的很全面。这里主要从推理系统方面展开讲讲实践上的选择。
GPU 和 CPU 的子图边界的传输需要足够小,以满足延迟要求。我们的实现上选择了传输 Feature Concat 后的结果。从传输角度上看这其实不是最优的。但在当时的情况下 GPU 上并没有足够的空间放 Embedding,而且 CPU 上我们有 Feature + Embedding 的 Fusion 优化,所以选择了架构调整最简单的方案。
搜推广模型大多用不好 GPU,模型不是算力瓶颈的。所以在使用大卡的时候,我们 考虑使用 MIG 来进一步提升利用效率,避免大马拉小车的情况。
通信模型应该足够简单,简化系统复杂度,减少出错环节(毕竟之前 CPU 和 GPU 在一起的时候可不会出现网络错误导致推理失败)。最好是 CPU 节点只访问一次 GPU 节点(GPU 节点是一个无循环依赖的完全独立子图)。而这个通信模型也有一定缺点,可能会导致延迟上升(可以仔细思考下为什么?)这个也是从简化系统角度考虑做的设计选择。
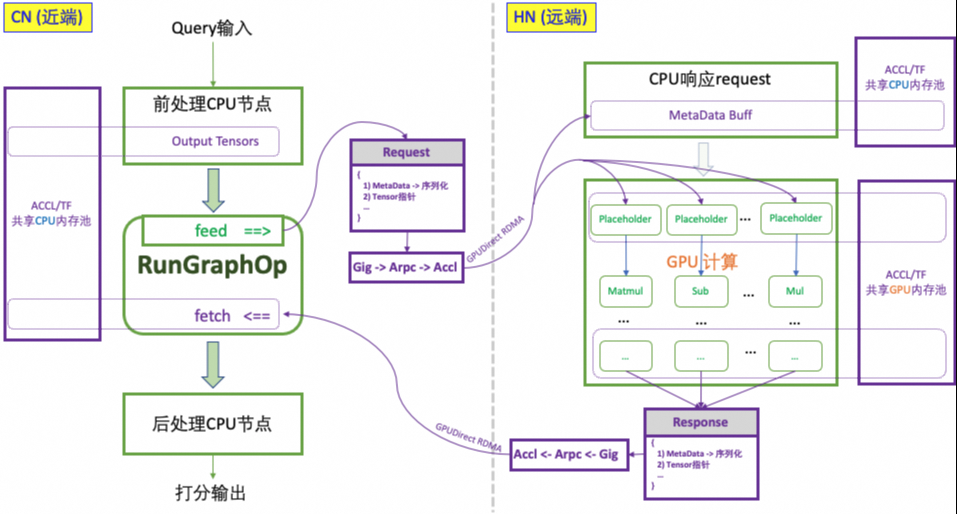
通信库方面,虽然 TensorFlow 原生支持了 RDMA,但并不够 serverless。我们期望能像 Grpc + istio 这样的组合去用 RDMA。这里我们融合了 ACCL[6] 和 ARPC 这两个库,达到了“像普通 TCP 通信一样用 RDMA”的效果。当然这里还有一些 trick,比如我们同时启用 RDMA GDR 和 CudaGraph,显存管理和 Graph 选择就要求我们打穿整个系统去实现。
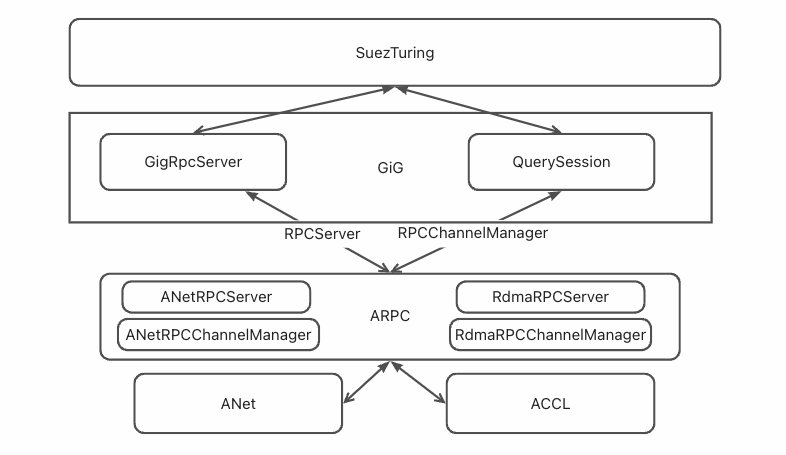
除了推理系统外,调度系统需要做到充分的拓扑感知,让通信路径足够短;网络架构方面,需要提供一个充分大能自由 RDMA 的网络域。这里面需要每个层次在一起 co-design。如果网络的设计是 pod 里混合 GPU/CPU 机型,调度会期望把一个推理服务的 CPU 和 GPU 节点都调度到一起,最小化推理延迟,但这样的设计会导致训练高带宽区域范围缩小;如果网络的设计更倾向于训练,跨 pod 做 RDMA 通信对网络来说是不小的挑战。这方面我不是专家,更多的信息可以参考 HPN[7] 。
插曲
当时整个系统开发测试联调完,我感觉问题不大,很稳。大家上线把,下次周会可以不用叫我了。确实上线也很顺利,继续扩容吧。

结果双十一压测的时候网络延迟异常飙高,所有人一脸懵逼。单机维度、交换机维度,各个指标拉出来大家看了几天,没什么眉目,日常状态和单独压测都稳如狗。人都摇齐了,项目室里除了思路啥都有。

碰到这种 bug 只能连蒙带猜,影响网络通信的还有什么呢?RDMA 只有 RTP 一个进程在用,总不能是 TCP 跟他打架把,但 TCP 流量带宽很低啊。于是我拿起压测工具做了一些违背祖宗的操作。最终定论是打开 QoS 情况下 TCP PPS 较高时(其实也没有很高)TCP 会严重影响 RDMA 通信。我们只能关闭 QoS,这个 BUG 报给网卡厂商确认了。
Cons
5.4 Prism at Scale: Production Deployment 这一节概述了整个系统生产化部署中获得的收益。

CX6 网卡的成本可能是个问题。特别在传统单机单卡的服务器上,可能插的不是 100G 网卡,还是上一代的千兆网卡,硬件条件上无法做 Disaggregation。而在历史机器上插新卡难度近似登天。
如果是买 ECS 的老铁,云服务商给你的不是一张完整的 CX6 网卡,带宽上有问题。另外云厂商给的也不一定是 商卡,是否支持 RDMA 可能也是个问题。
如果要训推复用的话,训练和推理机器必须放在一个能 RDMA 的网络域 下。最开始机房规划的时候没有做这个打算,后面很难做调整;另外 网络规模是有上限 的,在大模型时代,大家都是大卡,要怎样做机房计算和网络规划呢?其实这不光是服务器基础设施的问题,也是 AI 算法工程要理解的问题,只有联合设计才能最终实现高效的异构计算资源使用。
我们进一步考虑联合设计,如果这个集群的设计目标是支持大规模预训练任务,那就不存在潮汐性质,自然也难跟推理复用。训推一体的设计不适合大规模预训练任务,除非可以接受只在某些“大促节点”短暂地停掉任务。如果这个集群的设计目标是支持混合型任务,这些任务或资源量有限的,或是周期性的,如大模型的 CT/SFT、中等规模多媒体模型的训练、搜推广稀疏模型 ODL、数据清洗打标等,这些都适合训推一体的设计。
到更根本的问题上来,训推一体整体资源利用率优化带来的资源单价下降,是否能覆盖集群设计的额外成本(网卡、交换机等)?或者更抽象意义地看,我们的所有工作投入(人力资源 + 物理资源)是否换来了正向的全局收益?我们不断观测,但始终难以量化。
另外,高密度计算的爆炸半径 也是个问题。一张 H100 坏了,可能代表原来 8 个单卡 A10 实例宕机;一台训练机器的内存 ECC 错误,就是原来 64 个 A10 实例要迁移;那一个机柜散热有问题。。。

这是一般性问题和解法么?
一般来说,我们全盘接受论文的设定,就能按照论文的思路,逐步得到一个相似的结果。但是这个设定是否正确呢?对应论文提出的方法论是否通用呢?

如果是习惯使用云厂商 ECS 的厂子,可能已经早就已经被规格化蹂躏过了,在自己的业务特点下有一套成熟的适配方法论,努力凑,努力调和,并且可能会选择浪费一些 CPU,力求达到最佳的 GPU 使用率。Disaggregation 是一个理想,但不是一个必然选择。

如果你有自建机房、租用机房,以裸金属方式用服务器的话,那就有很大机会通过 Disaggregation 来解决资源利用率的问题。但厂子需要有相当的资源体量,才值得把 Disaggregation 落地。不过这里退一步讲,就算不做训推一体,只在推理上做 Disaggregation,也能提升资源利用率。
那所有模型都要做 Disaggregation 么?Graph Compiler 并不能在所有情况下都做的足够好,延迟可能不达标,甚至 Compile 不出来;而对于创新性的算法实验来说,资源效率并不是一个问题。我们需要根据模型和场景,见仁见智。
到 LLM 的一点思考

从 Ranking 转行大模型也两年了,算算时间这似乎是一篇遗作 [在吗]。在大模型上, Disaggregation 还在继续,Prefill/Decode 分离早早就开始烂大街了。PD 分离这种 Disaggregation 的出发点跟 DLRM 并不一致,它追求 1. 降低 Prefill 对 Decode 阶段的延迟影响,从而 2. 提高 Decode BatchSize 提升资源利用率,也就进一步 3. 提升吞吐降低成本。
从资源角度看,LLM PD Disaggregation 和 DLRM Disaggregation 的思路是一致的。DLRM Disaggregation 的出发点是 资源规格统一,目标是提高 GPU 和 CPU 的利用率;而 LLM PD Disaggregation 的出发点是 计算模式统一,目标是提高算力单元(TensorCore)和访存(HBM)的利用率。
但两者都存在一些硬伤。DLRM 中,GPU 肯定不能单独使用,必须搭配一定 CPU 做控制流逻辑。这部分的 CPU 必须被优化的足够少,我们才可能训练机器上启动足够多的实例用满 GPU。LLM PD Disaggregation 也类似,Prefill 虽然是算力瓶颈,但也要搭配一定的带宽;Decode 虽然是访存瓶颈,但肯定也要吃一些算力,这里的问题就比 DLRM 更复杂了。
Prefill 的 GPU 选型相对简单,L20/H20 这两个卡选,肯定用 L20 做 Prefill 而不是 H20。Decode 上我们应该怎样选型呢?这个讨论就比较复杂了,跟模型大小、模型结构都有关系。虽然我们内部已经大规模落地了 PD 分离系统,但在这方面我们的实践经验远没有当初在 DLRM 上丰富,等领悟更多了再来写一篇文章扒一扒。

还有一个思路,既然 H20 卡在做具体任务的时候资源有冗余,那么我们是不是能够在软件或者硬件层面上将一张大卡切分为“算力卡”和“带宽卡”,做单卡上 PD 分离。纯粹 CUDA 软件层面做显然是不靠谱的,显存在 HBM 上是打散分配的,不同任务有带宽争抢;硬件层面上,MIG 并不支持非均匀切分,这条路也并不可行。除非用一些高级的奇技淫巧。
结 语
其实 Disaggregation 还有一个好处,它自然地划分出不同 workload ,帮助你有针对性地观测、分析、优化。
其实 Disaggregation 还有一个好处,它减少了对训练和推理机型的差异化要求。在极致状态下我们只需要 CPU 和 GPU 两种服务器机型,那机型设计、原料供应等等都归一化了。不过现实没有这么美好啦,十万卡 H100 只在梦里,大家还是有啥能用就用啥吧 😄。
其实 Disaggregation 还有一个隐藏前提,就是 通信资源是接近无限、或者是容易被编排组合的。当通信不够用的时候,设想一下,引入 Disaggregation 反而让资源分配难度升维了。但我们的通信真的是无限的么?
感谢论文各位作者,以及背后默默支持的同学们。也大家来关注我们校招和社招岗位:
机器学习系统工程师
阿里控股 - 大模型推理系统工程师 -LLM
阿里控股 - 算子及编译优化工程师 -AI Infra
引用
[1] 深度预测平台 RTP 介绍
[2] Wide & Deep Learning for Recommender Systems
[4] 大规模深度学习预测场景下 codegen 的思考与应用
[5] 推荐场景 GPU 优化的探索与实践:CUDA Graph 与多流并行的比较与分析
[7] Alibaba HPN: A Data Center Network for Large Language Model Training
作者介绍
刘侃,2014 年加入阿里巴巴,经历过 问天 搜索引擎开发,负责过 RankService/RTP 系统,在机器学习系统、编译优化等方向有一定经验。目前是阿里巴巴智能引擎大模型推理系统负责人。
会议推荐
在 AI 大模型重塑软件开发的时代,我们如何把握变革?如何突破技术边界?4 月 10-12 日,QCon 全球软件开发大会· 北京站 邀你共赴 3 天沉浸式学习之约,跳出「技术茧房」,探索前沿科技的无限可能。
本次大会将汇聚顶尖技术专家、创新实践者,共同探讨多行业 AI 落地应用,分享一手实践经验,深度参与 DeepSeek 主题圆桌,洞见未来趋势。





