

本文介绍了如何将联机事务处理 (OLTP) 数据库从 MySQL 迁移到 Cloud Spanner。
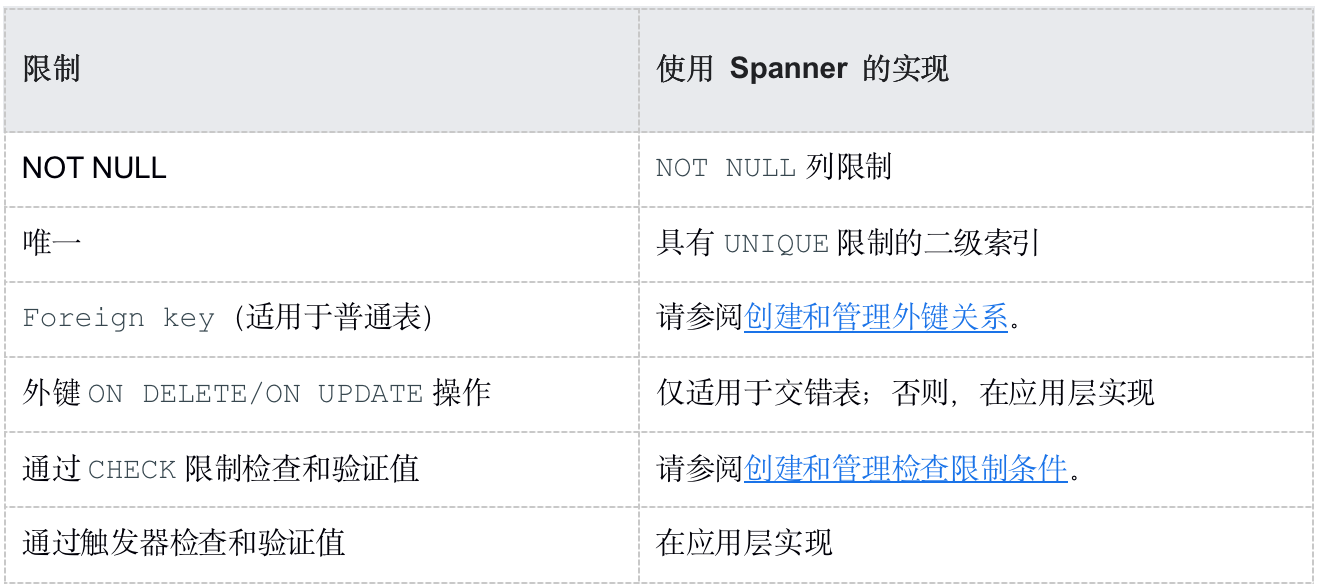
迁移限制
Spanner 使用的某些概念与其他企业数据库管理工具有所不同,因此您可能需要对应用架构进行某些调整,以充分利用其功能。您可能还需要使用 Google Cloud 中的某些其他服务作为 Spanner 的补充,以满足您的需求。
存储过程和触发器
Spanner 不支持在数据库级层运行用户代码,因此在迁移过程中,必须将由数据库级层存储过程和触发器实现的业务逻辑迁移到应用中。
序列
Spanner 未实现序列生成器;在 Spanner 中,使用单调递增的数字作为主键属于反模式(如下所述)。如需生成独一无二的主键,一种替代机制是使用随机 UUID。
如果由于外部原因需要使用序列,您必须在应用层实现它们。
访问权限控制
Spanner 仅支持使用身份和访问权限管理 (IAM) 访问权限和角色来控制数据库级层访问权限。Spanner 提供了预定义角色,这些角色可授予对数据库的读写或只读权限。如果您需要更精细的权限,则必须在应用层实现它们。一般情况下,应当仅允许应用对数据库执行读写操作。
如果您出于报告目的需要向用户公开数据库,并且希望使用精细的安全权限(例如,表级层/视图级层权限),我们建议您将数据库导出到 BigQuery 中。
数据验证限制
Spanner 在数据库层支持一组有限的数据验证限制。如果需要更复杂的数据限制,则必须在应用层实现它们。
下表讨论了 MySQL 数据库中常见的限制类型,以及如何使用 Spanner 来实现它们。
生成的列
Spanner 支持生成的列,其中列值将始终由作为表定义的一部分提供的函数生成。与在 MySQL 中一样,生成的列无法明确设置为 DML 语句中的提供值。
生成的列在执行 CREATE TABLE 或 ALTER TABLE 数据定义语言 (DDL) 语句期间被定义为列定义的一部分。AS 关键字后跟有效的 SQL 函数和所需的后缀关键字 STORED。STORED 关键字是 ANSI SQL 规范的一部分,表示函数结果将与表的其他列一起存储。
SQL 函数 Generation expression 可以包含任何确定性表达式、函数和运算符,且可以用在二级索引中或用作外部索引键。
如需详细了解如何管理此列类型,请参阅创建和管理生成的列。
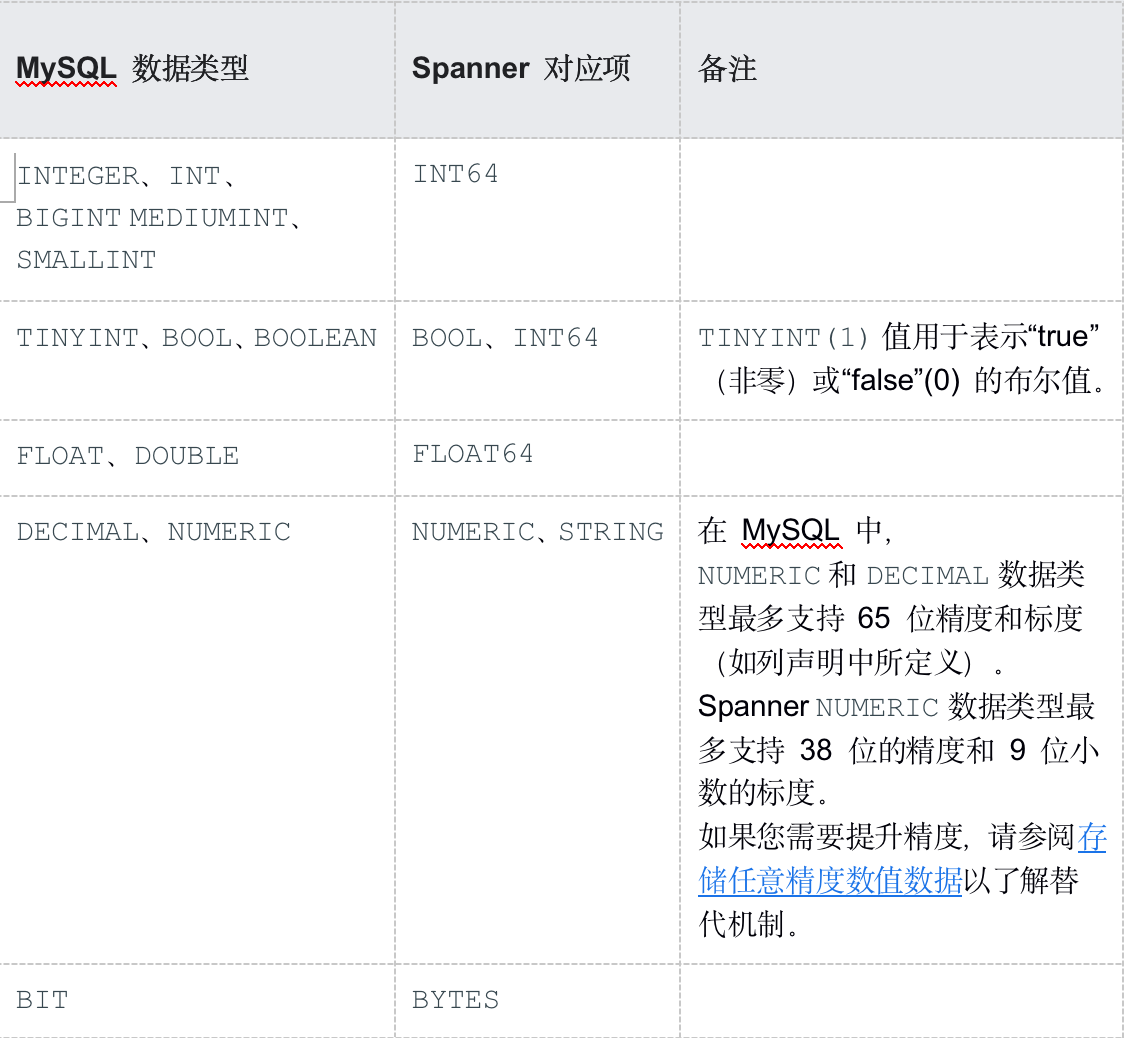
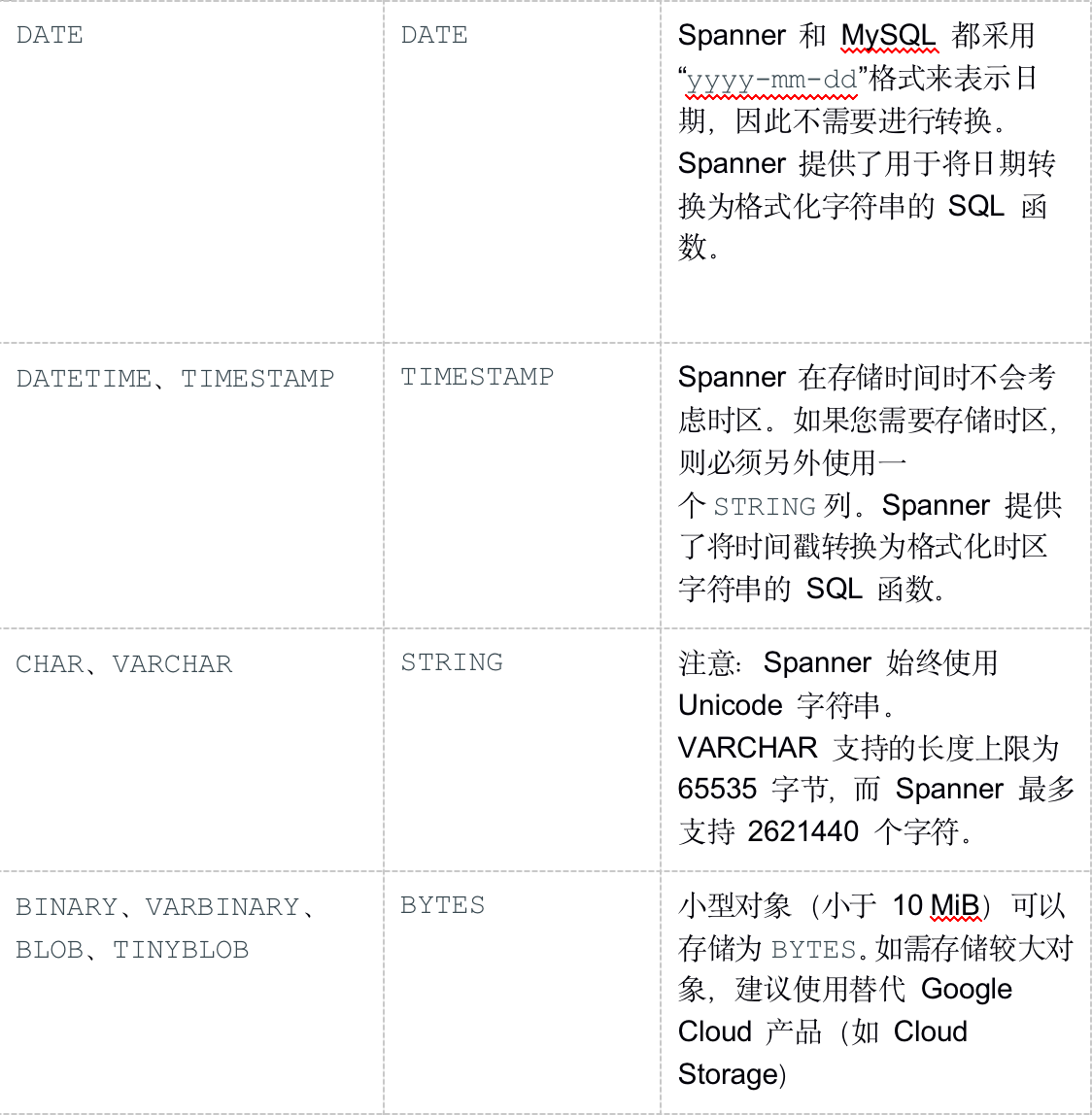
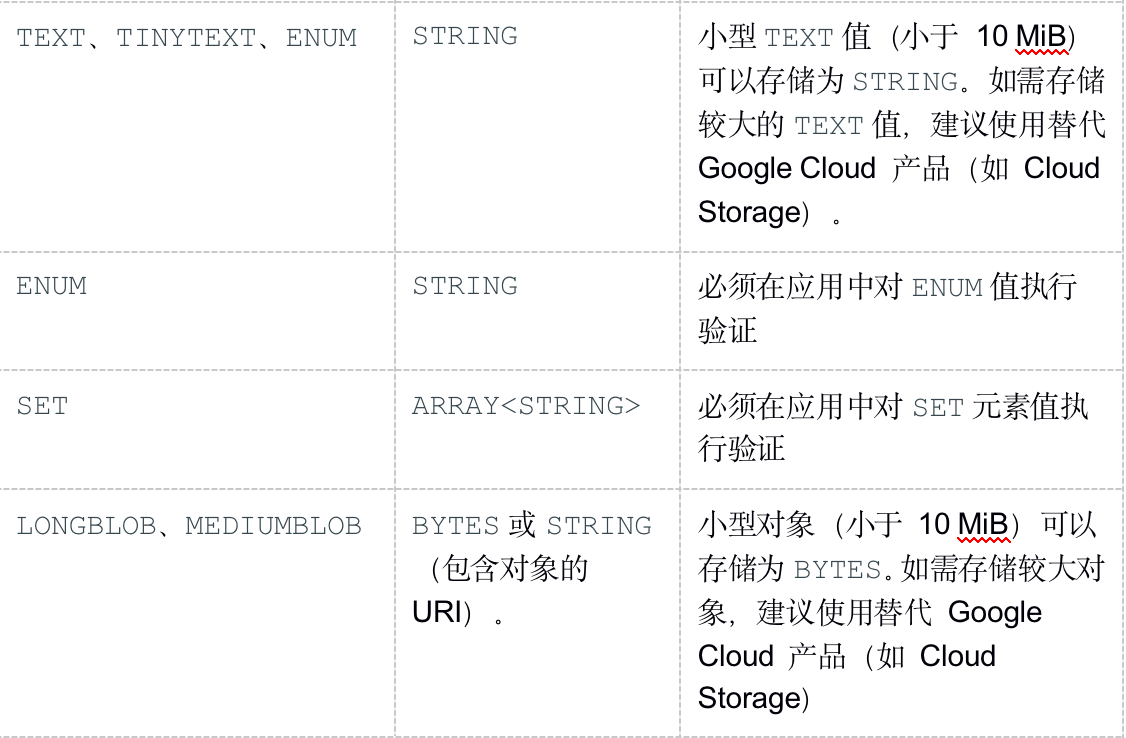
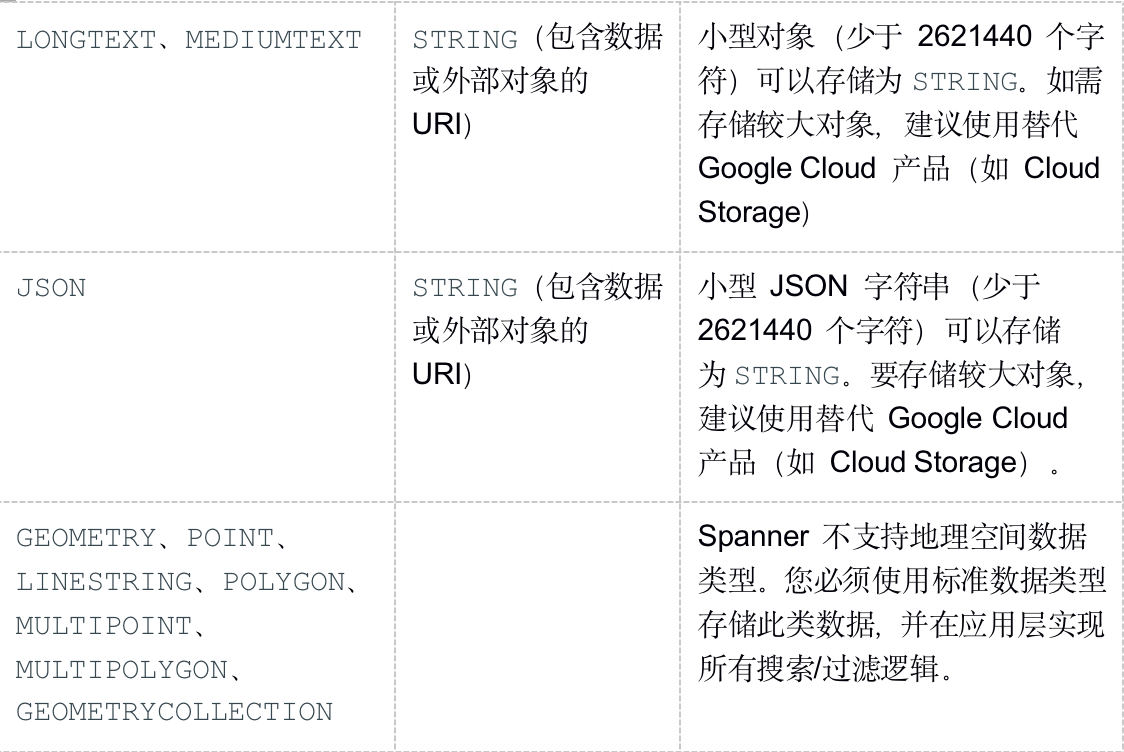
受支持的数据类型
MySQL 和 Spanner 支持的数据类型集有所不同。下表列出了 MySQL 数据类型及其在 Spanner 中的对应项。如需详细了解各种 Spanner 数据类型的定义,请参阅数据类型。
您可能需要按照“备注”列中的说明进一步转换数据,让 MySQL 数据能够融入您的 Spanner 数据库。例如,您可以先将一个大型 BLOB 作为对象存储在 Cloud Storage 存储分区(而非数据库)中,然后再将对该 Cloud Storage 对象的 URI 引用以 STRING 形式存储在数据库中。
迁移过程
迁移过程的整个时间安排如下所示:
转换架构和数据模型。
转换任何 SQL 查询。
迁移您的应用,使其可同时使用 MySQL 和 Spanner。
从 MySQL 批量导出您的数据,并使用 Dataflow 将这些数据导入 Spanner。
在迁移期间确保两个数据库保持一致。
将您的应用从 MySQL 中迁出。
转换数据库和架构
您可以将现有架构转换为 Spanner 架构来存储您的数据。为了使应用更易于修改,请确保转换的架构尽可能接近现有 MySQL 架构。不过,由于功能上存在差异,您可能需要进行一些更改。
如需了解如何提高吞吐量以及减少 Spanner 数据库中的热点,请参阅架构设计最佳做法。
主键
所有需要存储多个行的表都必须有一个主键,它由表的一个或多个列组成。表的主键用于唯一标识表中的各行;由于表行按主键排序,因此表本身充当主索引。
最好避免将单调递增或递减的列(例如序列或时间戳)指定为主键的第一部分,因为这可能会在键空间末尾发生插入操作时导致热点。热点是指对单一节点进行集中操作,在这种情况下,写入吞吐量会降低为该节点的容量,而无法享受到将所有写入操作负载平衡到各 Spanner 节点所带来的好处。
您可以采用以下方法来生成独一无二的主键值并降低产生热点的风险:
交换键的顺序,以确保包含单调递增或递减值的列不会成为键的第一个部分。
创建一个包含唯一键哈希值的列,以对唯一键进行哈希处理并将写入分布到逻辑碎片中,然后使用该哈希列(或结合使用哈希列和唯一键列)作为主键。这种方法有助于避免热点,因为新行在键空间内的分布更均匀。
使用通用唯一标识符 (UUID)(由 RFC 41122 定义)作为主键。建议使用版本 4 UUID,因为它使用位序列中的随机值。
对序列值进行位反转,以便在整个数值空间中大致均匀地分布后续数值的高位。
为表指定主键后,如果想更改主键,则必须删除该表并重新创建。如需详细了解如何指定主键,请参阅架构和数据模型 - 主键。
以下示例 DDL 语句将为音乐曲目数据库创建一个表:
交错表
Spanner 提供了一项可将两个表定义为具有一对多父子关系的功能。借助此功能,您可以在存储空间内将子数据行交错到其对应的父行旁边,从而有效地预联接表,并提高父项和子项一起查询时的数据检索效率。
子表的主键必须以父表的主键列开头。从子行的角度来看,父行主键称为外键。您最多可以定义 6 个级别的父子关系。
您可以为子表定义 on-delete 操作,以确定父行被删除时发生的情况:要么所有子行均被删除,要么当子行存在时父行不能删除。
以下示例演示了如何创建一个与之前定义的父级 Singers 表互相交错的 Albums 表:
创建二级索引
您还可以创建二级索引,以便将表中主键以外的数据编入索引。Spanner 实现二级索引的方式与表相同,因此要用作索引键的列值将受到与表主键相同的限制。这也意味着,索引具有与 Spanner 表相同的一致性保证。
使用二级索引查找值等效于使用表联接执行查询。您可以利用索引提高查询性能,方法是使用 STORING 子句将原始表的列值存储在二级索引中,并将该索引设为覆盖索引。
只有在索引本身存储了所有查询列(覆盖查询)时,Spanner 的查询优化工具才会自动使用二级索引。若要强制使用索引来查询原始表中的列,您必须在 SQL 语句中使用 FORCE INDEX 指令,例如:
您可以使用索引强制某一表列使用唯一值,方法是在该列上定义 UNIQUE 索引。该索引会阻止添加重复值。
以下示例 DDL 语句将为 Albums 表创建二级索引:
如果在数据加载后创建其他索引,则填充索引可能需要一些时间。建议您将索引添加速率限制为平均每天三次。如需详细了解如何创建二级索引,请参阅二级索引。如需详细了解有关索引创建方面的限制,请参阅架构更新。
转换任何 SQL 查询
Spanner 采用 ANSI 2011 扩展版 SQL 方言,并提供了许多有助于转换和聚合数据的函数和运算符。对于使用 MySQL 专用的方言、函数和类型的任何 SQL 查询,都需要进行转换才能与 Spanner 兼容。
不支持使用结构化数据作为列定义,但您可以在 SQL 查询中通过 ARRAY<> 和 STRUCT<> 类型来使用结构化数据。例如,您可以使用由 STRUCT 组成的 ARRAY(利用预联接的数据)编写一个返回艺术家的所有专辑的查询。如需了解详情,请参阅文档的子查询部分。
在执行 SQL 查询之前,您可以先使用 Cloud Console 中的 Spanner 查询界面来分析该查询。对大型表执行全表扫描时,查询费用通常很高,因此应谨慎使用。如需详细了解如何优化 SQL 查询,请参阅 SQL 最佳做法文档。
迁移应用以使用 Spanner
Spanner 提供了各种语言版本的一组客户端库,并且支持使用 Spanner 专有的 API 调用以及使用 SQL 查询和数据修改语言 (DML) 语句来读取和写入数据。对于某些查询(例如按键直接读取行),使用 API 调用时的执行速度可能更快,因为不需要转换 SQL 语句。
此外,您也可以通过 Java 数据库连接 (JDBC) 驱动程序,利用没有进行原生集成的现有工具和基础架构连接到 Spanner。
在迁移过程中,对于 Spanner 中不提供的功能,您必须在应用中实现它们。例如,如需实现用于验证数据值和更新一个相关表的触发器,您需要在应用中使用读写事务来读取现有行,验证限制,然后将更新后的行写入两个表。
Spanner 提供读写事务和只读事务,用于确保数据的外部一致性。另外,如果您需要读取一致的数据版本(如下所示),可以通过读取事务来应用时间戳边界:
过去某一确切时间(最多 1 小时前)的数据。
未来数据(在该时间到来之前,无法执行读取操作)。
与可接受的有界限过期设置对应的数据(在这种情况下,在截至过去某个时间点之前,系统将返回一致的视图,无需检查其他副本上提供的后续数据)。这可以带来性能优势,但同时也可能会读取过时的数据。
将数据从 MySQL 转移到 Spanner
如需将数据从 MySQL 转移到 Spanner,您必须将 MySQL 数据库导出为一种可移植的文件格式(例如 XML),然后使用 Dataflow 将该数据导入 Spanner。
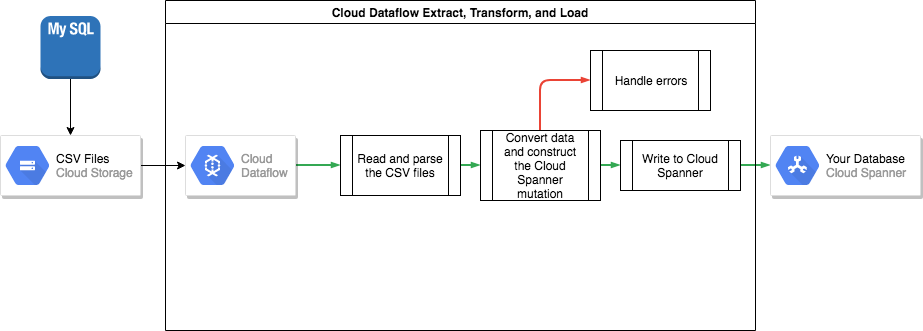
从 MySQL 批量导出数据
MySQL 附带的 mysqldump 工具可以将整个数据库导出到格式正确的 XML 文件。或者,您可以使用 SELECT … INTO OUTFILE SQL 语句为每个表创建 CSV 文件。但是,这种方法的缺点是一次只能导出一个表,这意味着您必须暂停应用或让数据库处于静默状态,这样数据库才能保持一致的状态以进行导出。
导出这些数据文件后,建议您将它们上传到 Cloud Storage 存储分区以供导入。
将数据批量导入 Spanner
由于 MySQL 与 Spanner 的数据库架构可能有所不同,因此您可能需要在导入过程中进行一些数据转换。如需执行这些数据转换并将数据导入 Spanner,最简单的方法是使用 Dataflow。Dataflow 是 Google Cloud 提供的一项分布式提取、转换和加载 (ETL) 服务。该服务为运行使用 Apache Beam SDK 编写的数据流水线以在多台机器上并行读取和处理大量数据提供了一个平台。
Apache Beam SDK 会要求您编写一个简单的 Java 程序来设置对数据的读取、转换和写入。Cloud Storage 和 Spanner 都会提供 Beam 连接器,因此您只需要编写数据转换代码。
如需查看有关从 CSV 文件读取数据并将数据写入 Spanner 的简单流水线示例,请参阅示例代码库。
如果在 Spanner 架构中使用交错的父子表,那么请注意,导入过程会先创建父行,然后再创建子行。为此,Spanner 导入流水线代码会依次导入根级表的所有数据、所有 1 级子表、所有 2 级子表,以此类推。
您可以直接使用 Spanner 导入流水线来批量导入数据,但这种方法需要使用正确的架构将数据存储在 Avro 文件中。
确保两个数据库保持一致
许多应用都有可用性要求,这使得应用无法在导出和导入数据所需的时间内保持脱机状态。因此,在将数据转移到 Spanner 时,应用仍会修改现有数据库。如此一来,您就需要复制 Spanner 数据库在应用运行期间发生的更新。
您可以通过多种方法让两个数据库保持同步,例如,捕获变更数据以及在应用中实现同步更新。
捕获变更数据
MySQL 没有原生的 Change Data Capture (CDC) 实用程序。但是,它提供了可以接收 MySQL 二进制日志 (Binlog) 并将其转换为 CDC 流的各种开源项目。例如,Maxwell 的守护进程可以为您的数据库提供 CDC 流。
您可以编写一个应用来订阅此流,并在经过数据转换后对 Spanner 数据库进行相同的修改。
通过应用同时更新两个数据库
您也可以将应用修改为向两个数据库写入数据。一个数据库(最初的 MySQL 数据库)被视为可靠数据源;在每次向该数据库写入数据之后,应用都会对整行内容进行读取和转换,并将其写入 Spanner 数据库。这样,应用就会不断使用最新数据来覆盖 Spanner 行中的内容。
如果您确定所有数据都已正确转移,则可以将数据源切换到 Spanner 数据库。如果在切换到 Spanner 时发现问题,这种机制提供了一条回滚路径。
验证数据一致性
随着数据不断流入 Spanner 数据库,您可以定期对 Spanner 数据和 MySQL 数据运行比较,以确保二者保持一致。如需验证一致性,您可以对两个数据源执行查询并比较查询结果。
借助 Dataflow,您可以使用 Join 转换对大型数据集执行详细比较。此转换采用 2 个键控数据集,并按键匹配值。然后可以比较匹配值是否相等。您可以定期运行此验证,直到一致性程度符合您的业务要求。
改用 Spanner 作为应用的可靠来源
确定数据迁移完毕后,即可将应用切换为使用 Spanner 作为数据源。这样一来,您就可以继续向 MySQL 数据库写回更改,从而使 MySQL 数据库保持最新状态,并可在出现问题时获得一条回滚路径。
最后,您可以停用并移除 MySQL 数据库更新代码,然后关闭现已作废的 MySQL 数据库。
导出和导入 Spanner 数据库
如需执行导出操作,您可以选择使用 Dataflow 模板将表从 Spanner 导出到 Cloud Storage 存储分区。生成的文件夹包含一组 Avro 文件和 JSON 清单文件(含导出的表)。这些文件有多种用途,具体如下:
备份数据库以实现数据保留政策合规性或灾难恢复。
将 Avro 文件导入其他 Google Cloud 产品(如 BigQuery)。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论