

近日,计算机视觉顶会 CVPR 2022 公布了会议录取结果,美图影像研究院(MT Lab)与北京航空航天大学可乐实验室(CoLab)联合发表的论文被接收。该论文突破性地提出分布感知式单阶段模型,用于解决极具挑战性的多人 3D 人体姿态估计问题。该方法通过一次网络前向推理同时获取 3D 空间中人体位置信息以及相对应的关键点信息,从而简化了预测流程,提高了效率。此外,该方法有效地学习了人体关键点的真实分布,进而提升了基于回归框架的精度。
多人 3D 人体姿态估计是当前的一个热点研究课题,也具有广泛的应用潜力。在计算机视觉中,基于单张 RGB 图片的多人 3D 人体姿态估计问题通常通过自顶向下或是自底向上的两阶段方法来解决,然而两阶段的方法需忍受大量的冗余计算以及复杂的后处理,其低效率深受诟病。此外,已有方法缺少对人体姿态数据分布的认知,从而无法准确地求解从 2D 图片到 3D 位置这一病态问题,以上两点限制了已有方法在实际场景中的应用。
美图影像研究院(MT Lab)与北京航空航天大学可乐实验室(CoLab)在 CVPR 2022 发表的论文,提出一种分布感知式单阶段模型,并利用这一模型从单张 RGB 图片中估计多个人在 3D 相机空间中的人体姿态。该方法将 3D 人体姿态表示为 2.5D 人体中心点和 3D 关键点偏移量,以适配图片空间的深度估计,同时这一表示将人体位置信息和对应的关键点信息进行了统一,从而使得单阶段多人 3D 姿态估计成为可能。
此外,该方法在模型优化过程中对人体关键点的分布进行了学习,这为关键点位置的回归预测提供了重要的指导信息,进而提升了基于回归框架的精度。这一分布学习模块可以与姿态估计模块在训练过程中通过最大似然估计一起学习,在测试过程中该模块被移除,不会带来模型推理计算量的增加。为了降低人体关键点分布学习的难度,该方法创新性地提出了一种迭代更新的策略以逐渐逼近目标分布。
该模型以全卷积的方式来实现,可以进行端到端的训练和测试。通过这样一种方式,该算法可以有效且精准地解决多人 3D 人体姿态估计问题,在取得和两阶段方法接近的精度的同时,也大大提升了速度。

论文链接:https://arxiv.org/abs/2203.07697
背景
多人 3D 人体姿态估计是计算机视觉中的经典问题,它被广泛地应用于 AR/VR、游戏、运动分析、虚拟试衣等,近年来随着元宇宙概念的兴起,更是让这一技术备受关注。目前,通常采用两阶段方法来解决该问题:自顶向下方法,即先检测图片多个人体的位置,之后对检测到的每个人使用单人 3D 姿态估计模型来分别预测其姿态;自底向上方法,即先检测图片中所有人的 3D 关键点,之后通过相关性将这些关键点分配给对应的人体。
尽管两阶段方法取得了良好的精度,但是需要通过冗余的计算和复杂的后处理来顺序性地获取人体位置信息和关键点位置信息,这使得速率通常难以满足实际场景的部署需求,因此多人 3D 姿态估计算法流程亟需简化。另一方面,在缺少数据分布先验知识的情况下,从单张 RGB 图片中估计 3D 关键点位置,特别是深度信息,是一个病态问题。这使得传统的应用于 2D 场景的单阶段模型无法直接向 3D 场景进行扩展,因此学习并获取 3D 关键点的数据分布是进行高精度多人 3D 人体姿态估计的关键所在。
为了克服以上问题,该论文提出了一种分布感知式单阶段模型(Distribution-Aware Single-stage model, DAS)用于解决基于单张图片的多人 3D 人体姿态估计这一病态问题。DAS 模型将 3D 人体姿态表示为 2.5D 人体中心点和 3D 人体关键点偏移,这一表示有效地适配了基于 RGB 图片域的深度信息预测。同时,它也将人体位置信息和关键点位置信息进行了统一,从而使得基于单目图片的单阶段多人 3D 姿态估计方法成为可能。另外,DAS 模型在优化过程中对 3D 关键点的分布进行学习,这为 3D 关键点的回归提供了极具价值的指导性信息,从而有效地提升了预测精度。此外,为了缓解关键点分布估计的难度,DAS 模型采用了一种迭代更新策略以逐步逼近真实分布目标,通过这样一种方式,DAS 模型可以高效且精准地从单目 RGB 图片中一次性获取多个人的 3D 人体姿态估计结果。
单阶段多人 3D 姿态估计模型
在实现上,DAS 模型基于回归预测框架来构建,对于给定图片,DAS 模型通过一次前向预测输出图片中所包含人物的 3D 人体姿态。DAS 模型将人体中心点表示为中心点置信度图和中心点坐标图两部分,如图 1 (a) 和 (b) 所示,其中,DAS 模型使用中心点置信度图来定位 2D 图片坐标系中人体投影中心点的位置,而使用中心点坐标图来预测 3D 相机坐标系内人体中心点的绝对位置。DAS 模型将人体关键点建模为关键点偏移图,如图 1 (c) 所示。DAS 模型将中心点置信度图建模为二值图,图中每个像素点表示人体中心点是否在该位置出现,如果出现则为 1,否则为 0。DAS 模型将中心点坐标图以稠密图的方式进行建模,图中每个像素点编码了出现在该位置的人物中心在 x、y 和 z 方向的坐标。关键点偏移图和中心点坐标图建模方式类似,图中每个像素点编码了出现在该位置的人体关键点相对于人体中心点在 x、y、z 方向的偏移量。DAS 模型可以在网络前向过程中以并行的方式输出以上三种信息图,从而避免了冗余计算。此外,DAS 模型可以使用这三种信息图简单地重建出多个人的 3D 姿态,也避免了复杂的后处理过程,与两阶段方法相比,这样一种紧凑、简单的单阶段模型可以取得更优的效率。
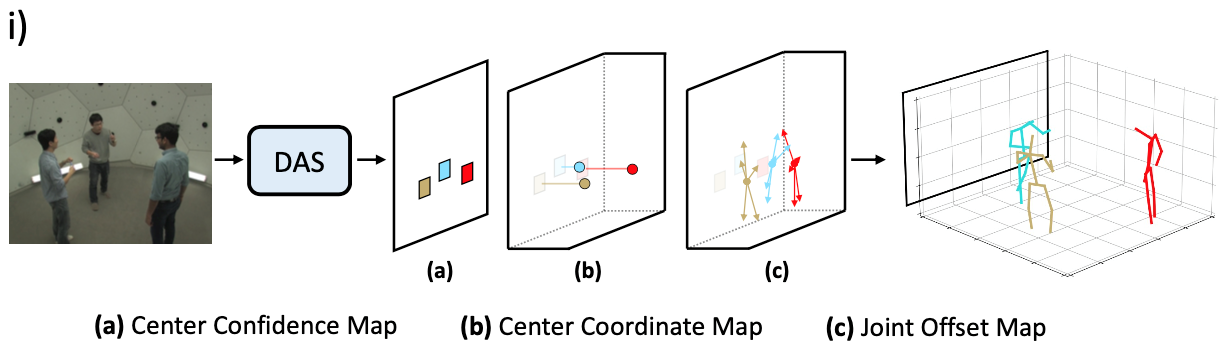
图 1 用于多人 3D 人体姿态估计的分布感知式单阶段模型流程图
分布感知学习模型
对于回归预测框架的优化,已有工作多采用传统的 L1 或者 L2 损失函数,但研究发现这类监督训练实际上是在假设人体关键点的数据分布满足拉普拉斯分布或者高斯分布的前提下进行的模型优化[12]。然而在实际场景中,人体关键点的真实分布极为复杂,以上简单的假设与真实分布相距甚远。与现有方法不同,DAS 模型在优化过程中学习 3D 人体关键点分布的真实分布,指导关键点回归预测的过程。考虑到真实分布不可追踪的问题,DAS 模型利用标准化流(Normalizing Flow)来达到对于模型预测结果概率估计的目标,以生成适合模型输出的分布,如图 2 所示。该分布感知模块可以同关键点预测模块一起在训练过程中通过最大似然估计的方法进行学习,完成学习之后,该分布感知模块会在预测过程中进行移除,这样一种分布感知式算法可以在不增加额外计算量的同时提升回归预测模型的精度。此外,用于人体关键点预测的特征提取于人体中心点处,这一特征对于远离中心点的人体关键点来说表示能力较弱,和目标在空间上的不一致问题会引起预测的较大误差。为了缓和这一问题,该算法提出了迭代更新策略,该策略利用历史更新结果为出发点,并整合中间结果附近预测值以逐步逼近最终目标,如图 3 所示。
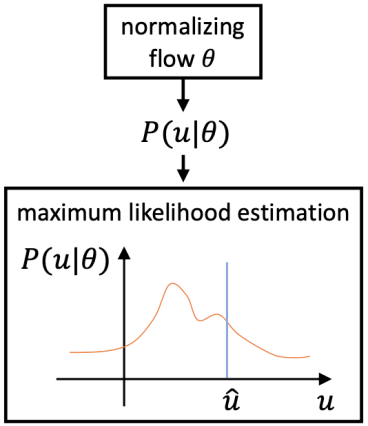
图 2 标准化流
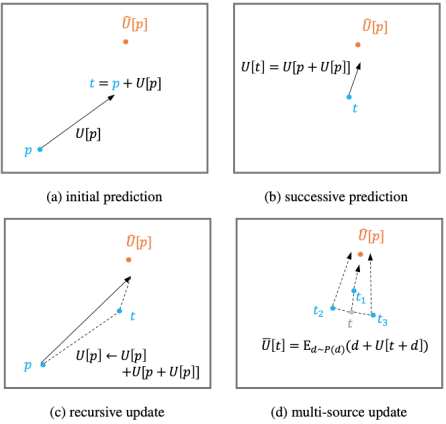
图 3 迭代优化策略
该算法模型通过全卷积网络(Fully Convolutional Networks, FCNs)实现,训练和测试过程都可以以端到端的方式进行,如图 4 所示。根据实验结果,如图 5 所示,单阶段算法和已有 state-of-the-art 两阶段方法相比,可以取得接近甚至更优的精度,同时可以大幅提升速度,证明了其在解决多人 3D 人体姿态估计这一问题上的优越性,详细实验结果可参考表 1 和表 2。根据单阶段算法的可视化结果,如图 6 所示,该算法能够适应不同的场景,例如姿势变化、人体截断以及杂乱背景等来产生精确的预测结果,这进一步说明了该算法的健壮性。
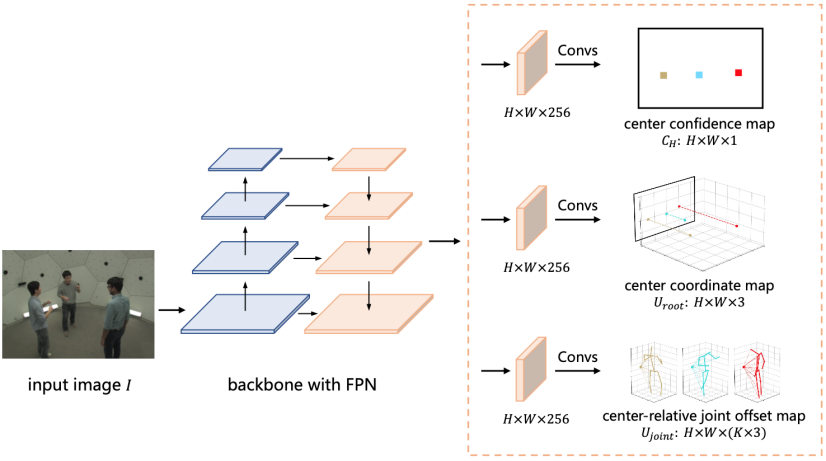
图 4 分布感知式单阶段多人 3D 人体姿态估计网络结构
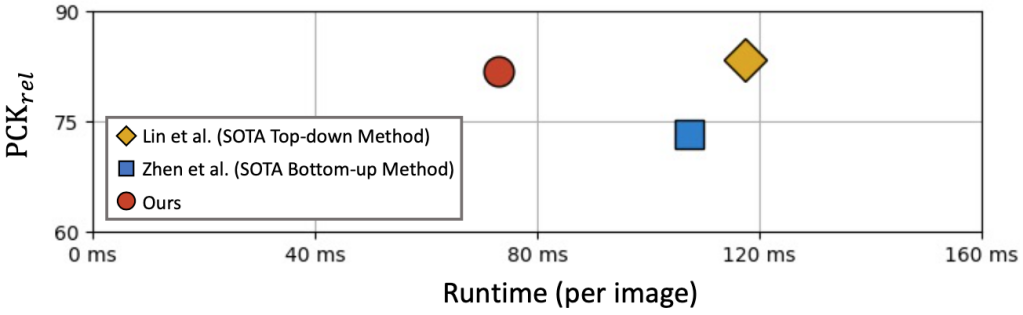
图 5 与现有 state-of-the-art 两阶段算法对比结果
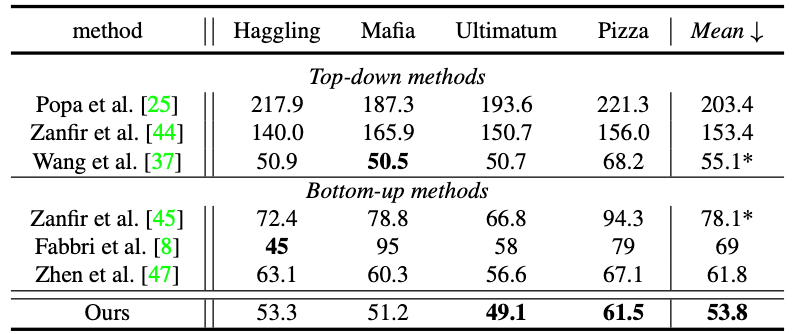
表 1 CMU Panoptic Studio 数据集结果比较
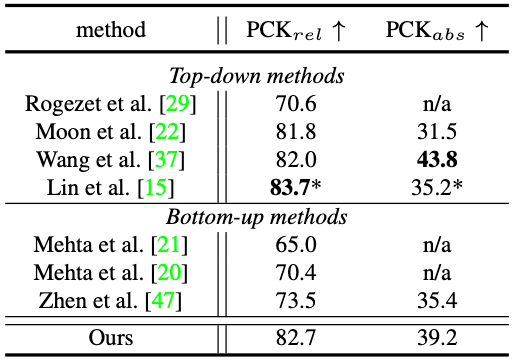
表 2 MuPoTS-3D 数据集结果比较
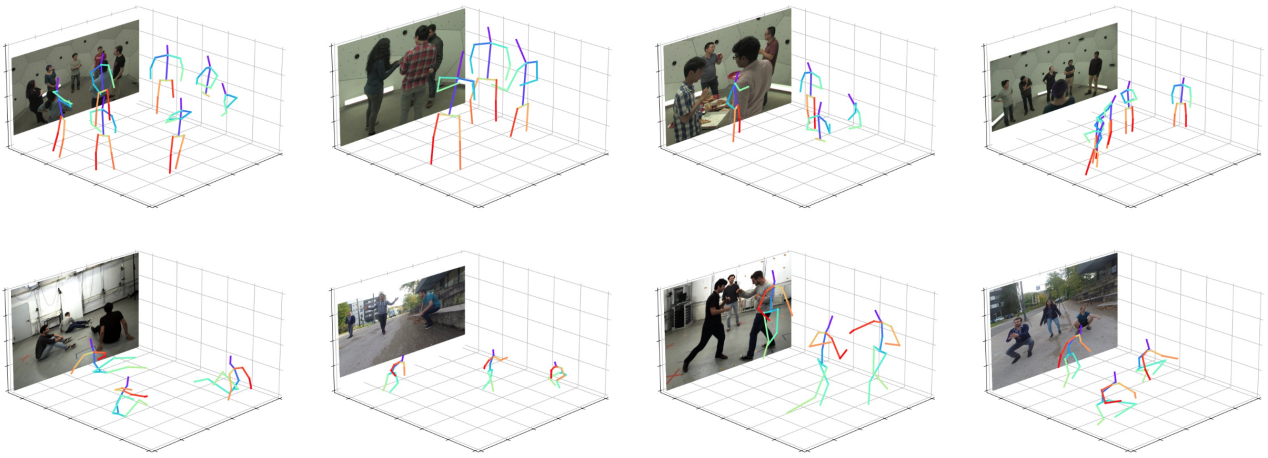
图 6 可视化结果
总结
在本论文中,来自美图和北航的研究者们创新性地提出了一种分布感知式单阶段模型,用于解决极具挑战性的多人 3D 人体姿态估计问题。与已有的自顶向下和自底向上这种两阶段模型相比,该模型可以通过一次网络前向推理同时获取人体位置信息以及所对应的人体关键点位置信息,从而有效地简化预测流程,同时克服了已有方法在高计算成本和高模型复杂度方面的弊端。另外,该方法成功将标准化流引进到多人 3D 人体姿态估计任务中以在训练过程中学习人体关键点分布,并提出迭代回归策略以缓解分布学习难度来达到逐步逼近目标的目的。通过这样一种方式,该算法可以获取数据的真实分布以有效地提升模型的回归预测精度。
引用文献:
[1] JP Agnelli, M Cadeiras, Esteban G Tabak, Cristina Vilma Turner, and Eric Vanden-Eijnden. Clustering and classifica- tion through normalizing flows in feature space. Multiscale Modeling & Simulation, 2010.
[12] Jiefeng Li, Siyuan Bian, Ailing Zeng, Can Wang, Bo Pang, Wentao Liu, and Cewu Lu. Human pose regression with residual log-likelihood estimation. In ICCV, 2021.
[15] Jiahao Lin and Gim Hee Lee. Hdnet: Human depth estima- tion for multi-person camera-space localization. In ECCV, 2020.
[47] Jianan Zhen, Qi Fang, Jiaming Sun, Wentao Liu, Wei Jiang, Hujun Bao, and Xiaowei Zhou. Smap: Single-shot multi- person absolute 3d pose estimation. In ECCV, 2020.
[48] Xingyi Zhou, Dequan Wang, and Philipp Kra ̈henbu ̈hl. Ob- jects as points. arXiv preprint arXiv:1904.07850, 2019.

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论