

1 概述
“猜你喜欢”是美团流量最大的推荐展位,位于首页最下方,产品形态为信息流,承担了帮助用户完成意图转化、发现兴趣、并向美团点评各个业务方导流的责任。经过多年迭代,目前“猜你喜欢”基线策略的排序模型是业界领先的流式更新的 Wide&Deep 模型[1]。考虑 Point-Wise 模型缺少对候选集 Item 之间的相关性刻画,产品体验中也存在对用户意图捕捉不充分的问题,从模型、特征入手,更深入地理解时间,仍有推荐体验和效果的提升空间。近年来,强化学习在游戏、控制等领域取得了令人瞩目的成果,我们尝试利用强化学习针对以上问题进行优化,优化目标是在推荐系统与用户的多轮交互过程中的长期收益。
在过去的工作中,我们从基本的 Q-Learning 着手,沿着状态从低维到高维,动作从离散到连续,更新方式从离线到实时的路径进行了一些技术尝试。本文将介绍美团“猜你喜欢”展位应用强化学习的算法和工程经验。第 2 节介绍基于多轮交互的 MDP 建模,这部分和业务场景强相关,我们在用户意图建模的部分做了较多工作,初步奠定了强化学习取得正向收益的基础。第 3 节介绍网络结构上的优化,针对强化学习训练不稳定、难以收敛、学习效率低、要求海量训练数据的问题,我们结合线上 A/B Test 的线上场景改进了 DDPG 模型,取得了稳定的正向收益。第 4 节介绍轻量级实时 DRL 框架的工作,其中针对 TensorFlow 对 Online Learning 支持不够好和 TF serving 更新模型时平响骤升的问题做了一些优化。
图 1 美团首页“猜你喜欢”场景
2 MDP 建模
在“猜你喜欢“展位中,用户可以通过翻页来实现与推荐系统的多轮交互,此过程中推荐系统能够感知用户的实时行为,从而更加理解用户,在接下来的交互中提供更好的体验。“猜你喜欢”用户-翻页次数的分布是一个长尾的分布,在图 2 中我们把用户数取了对数。可知多轮交互确实天然存在于推荐场景中。
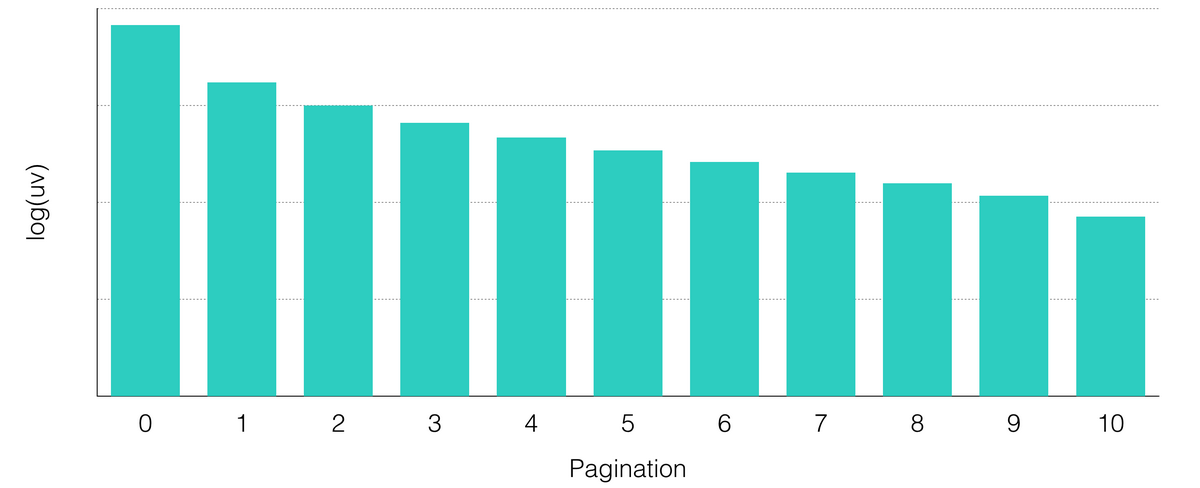
图 2 “猜你喜欢”展位用户翻页情况统计
在这样的多轮交互中,我们把推荐系统看作智能体(Agent),用户看作环境(Environment),推荐系统与用户的多轮交互过程可以建模为 MDP:
State:Agent 对 Environment 的观测,即用户的意图和所处场景。
Action:以 List-Wise 粒度对推荐列表做调整,考虑长期收益对当前决策的影响。
Reward:根据用户反馈给予 Agent 相应的奖励,为业务目标直接负责。
P(s,a):Agent 在当前 State s 下采取 Action a 的状态转移概率。
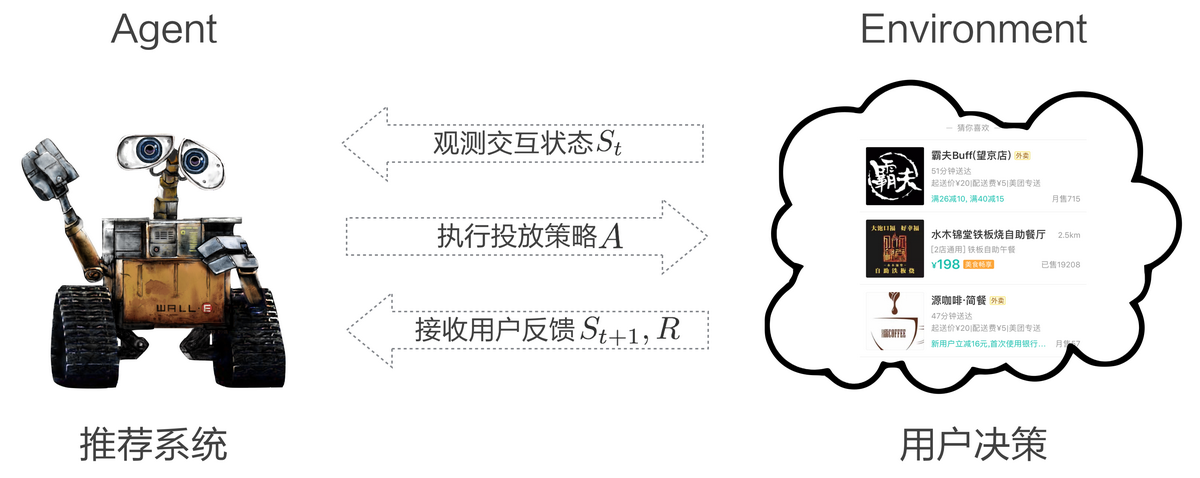
图 3 推荐系统与用户交互示意图
我们的优化目标是使 Agent 在多轮交互中获得的收益最大化:
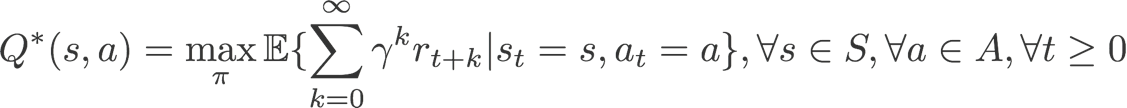
具体而言,我们把交互过程中的 MDP<a,s,r,p>建模如下:</a,s,r,p>
2.1 状态建模
状态来自于 Agent 对 Environment 的观察,在推荐场景下即用户的意图和所处场景,我们设计了如图 4 所示的网络结构来提取状态的表达。网络主要分为两个部分:把用户实时行为序列的 Item Embedding 作为输入,使用一维 CNN 学习用户实时意图的表达;推荐场景其实仍然相当依赖传统特征工程,因此我们使用 Dense 和 Embedding 特征表达用户所处的时间、地点、场景,以及更长时间周期内用户行为习惯的挖掘。
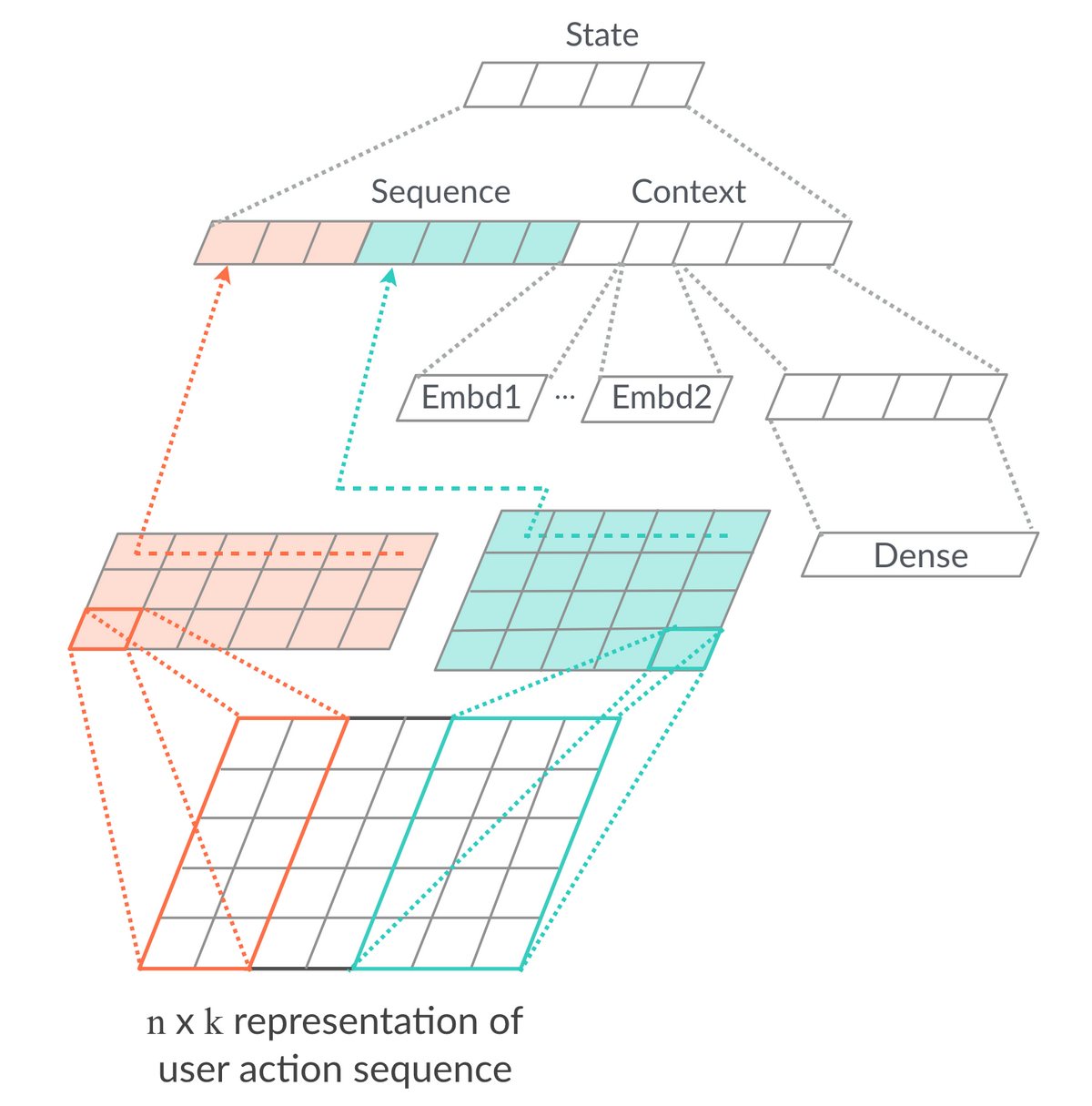
图 4 状态建模网络结构
这里我们介绍一下使用 Embedding 特征表达用户行为习惯挖掘的 Binary Sequence[2] 方法。我们通过特征工程对用户行为序列做各种维度的抽象,做成一些列离散的 N 进制编码,表示每一位有 N 种状态。例如统计用户在 1H/6H/1D/3D/1W 不同时间窗口内是否有点击行为编码成 5 位 2 进制数,把这些数字作为离散特征学习 Embedding 表达,作为一类特征处理方法。除此之外,还有点击品类是否发生转移、点击间隔的 gap 等等,在“猜你喜欢”场景的排序模型和强化学习状态建模中都取得了很不错的效果。原因是在行为数据非常丰富的情况下,序列模型受限于复杂度和效率,不足以充分利用这些信息,Binary Sequence 可以作为一个很好的补充。
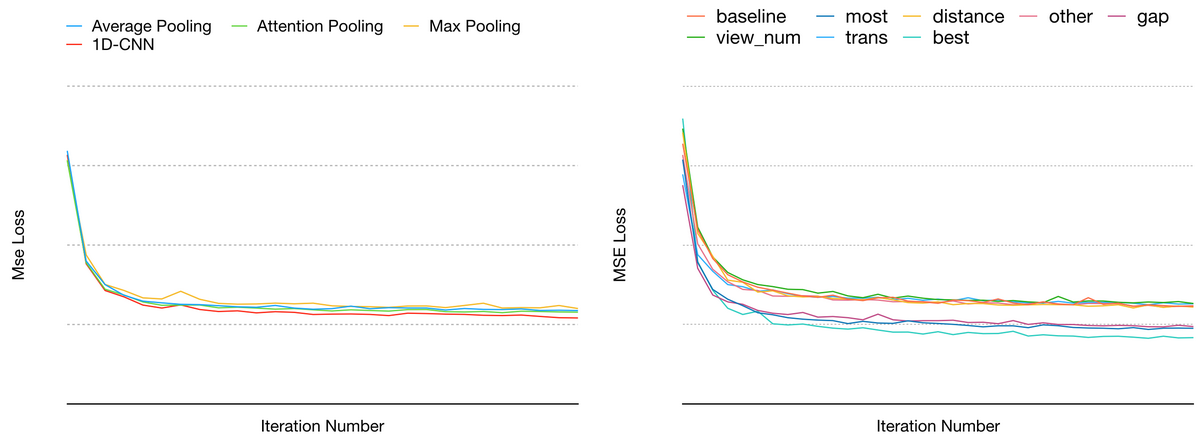
图 5 序列模型和特征工程效果对照
图 5 左侧是序列模型的部分,分别使用不同的 Pooling 方式和一维 CNN 离线效果的对比,右侧是 Dense 和 Embedding 特征的部分,分别加入用户高频行为、距离、行为时间间隔、行为次数、意图转移等特征,以及加入所有显著正向特征的离线效果。
2.2 动作设计
“猜你喜欢”目前使用的排序模型由两个同构的 Wide&Deep 模型组成,分别以点击和支付作为目标训练,最后把两个模型的输出做融合。融合方法如下图所示:
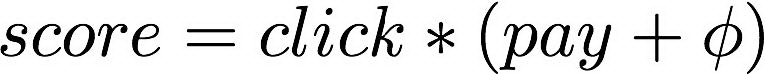
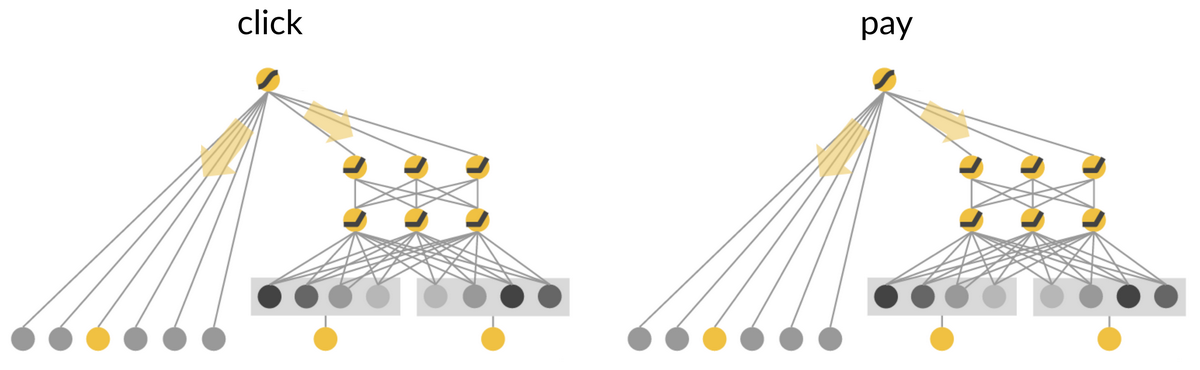
图 6 排序模型示意图
超参数 的物理意义是调整全量数据集中点击和下单模型的 Trade Off,通过综合考虑点击和下单两个任务的 AUC 确定,没有个性化的因素。我们以此为切入点,使用 Agent 的动作调整融合超参数,令:
a 是由 Agent 的策略生成 Action,这样做有两个好处:其一,我们知道一个较优解是 a=1,这种情况下强化学习策略和基线的排序策略保持一致,由于强化学习是个不断试错的过程,我们可以很方便地初始化 Agent 的策略为 a=1,从而避免在实验初期伤害线上效果。其二,允许我们根据物理意义对 Action 做 Clip,从而减轻强化学习更新过程不稳定造成的实际影响。
2.3 奖励塑形
“猜你喜欢”展位的优化核心指标是点击率和下单率,在每个实验分桶中分母是基本相同的,因此业务目标可以看成优化点击次数和下单次数,我们尝试将奖励塑形如下:
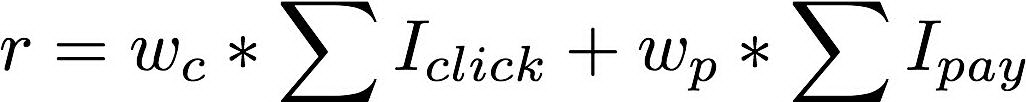
相对于关注每个 Item 转化效率的 Point Wise 粒度的排序模型,强化学习的目标是最大化多轮交互中的奖励收益,为业务目标直接负责。
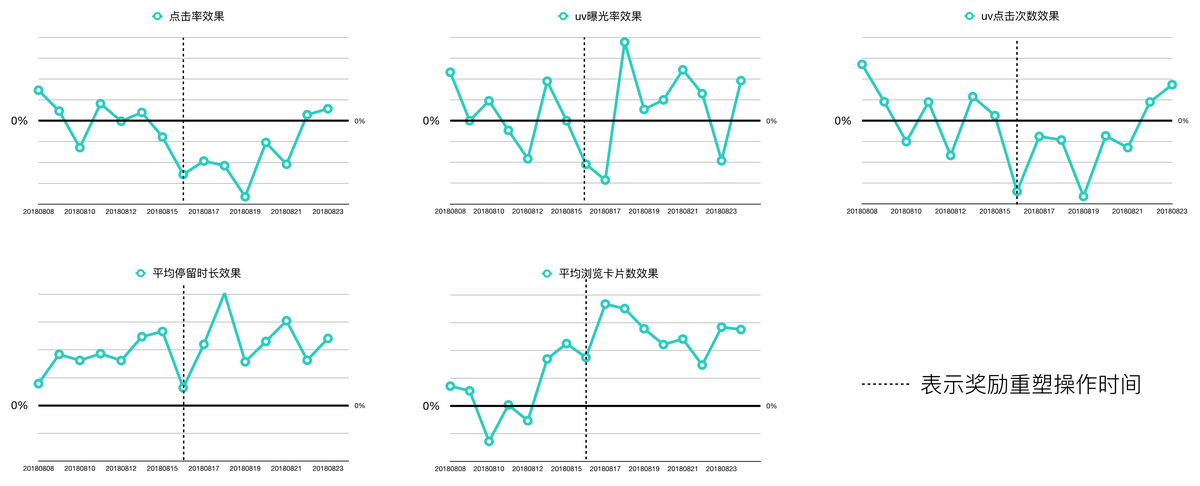
图 7 加入惩罚项前后的相对效果变化
在实验过程中我们发现,强化学习的策略可能上线初期效果很好,在点击和下单指标上都取得了一定的提升,但在后续会逐渐下降,如图 7 前半段所示。在逐层转化效率的分析中,我们发现强化学习分桶的设备曝光率和 UV 维度点击率有所降低,而用户停留时长和浏览深度稳定提升,这说明 Agent 学习到了让用户与推荐系统更多交互,从而获取更多曝光和转化机会的策略,但这种策略对于部分强烈下单意图用户的体验是有伤害的,因为这部分用户意图转化的代价变高了,因而对展位的期望变低。针对这种情况,我们在奖励塑形中加入两个惩罚项:
惩罚没有发生任何转化(点击/下单)行为的中间交互页面(penalty1),从而让模型学习用户意图转化的最短路;
惩罚没有发生任何转化且用户离开的页面(penalty2),从而保护用户体验。
修正后的奖励为:

由于用户体验是时间连续的,UV 维度的效果在报表上有一定的滞后性,约一周后点击率和万订单恢复到正向水平,同时用户停留时长和浏览深度有进一步提升,说明 Agent 确实学到了在避免伤害用户的前提下,从多轮交互中获取更多转化的策略,如图 7 后半段所示。
这一节我们介绍了 MDP 建模相关的工作。MDP 跟业务场景是强相关的,经验不是很容易迁移。就本文的场景而言,我们花了较多精力做状态表达的特征,这部分工作使强化学习得到了在自己的目标上取得正向收益的能力,因此对这部分介绍比较细致。动作设计是针对多目标模型融合的场景,是个业界普遍存在并且监督学习不太适用的场景,也能体现强化学习的能力。奖励塑形是为了缩小强化学习的目标和业务目标之间的 Gap,需要在数据洞察和业务理解上做一些工作。完成上述工作后强化学习在自己的目标和业务指标上已经能取得了一些正向效果,但不够稳定。另外由于策略迭代是个 Online Learning 的过程,实验上线后需要实时训练一周才能收敛并观察效果,这也严重影响了我们的迭代效率。针对这些情况我们针对模型做了一些改进。
3 改进的 DDPG 模型
在模型方面,我们在不断改进 MDP 建模的过程中先后尝试了 Q-Learning、DQN[3]和 DDPG[4]模型,也面临着强化学习中普遍存在更新不够稳定、训练过程容易不收敛、学习效率较低(这里指样本利用效率低,因此需要海量样本)的问题。具体到推荐场景中,由于 List-Wise 维度的样本比 Point-Wise 少得多,以及需要真实的动作和反馈作为训练样本,因此我们只能用实验组的小流量做实时训练。这样一来训练数据量相对就比较少,每天仅有几十万,迭代效率较低。为此我们对网络结构做了一些改进,包括引入具体的 Advantage 函数、State 权值共享、On-Policy 策略的优化,结合线上 A/B Test 框架做了十数倍的数据增强,以及对预训练的支持。接下来我们以 DDPG 为基石,介绍模型改进的工作。
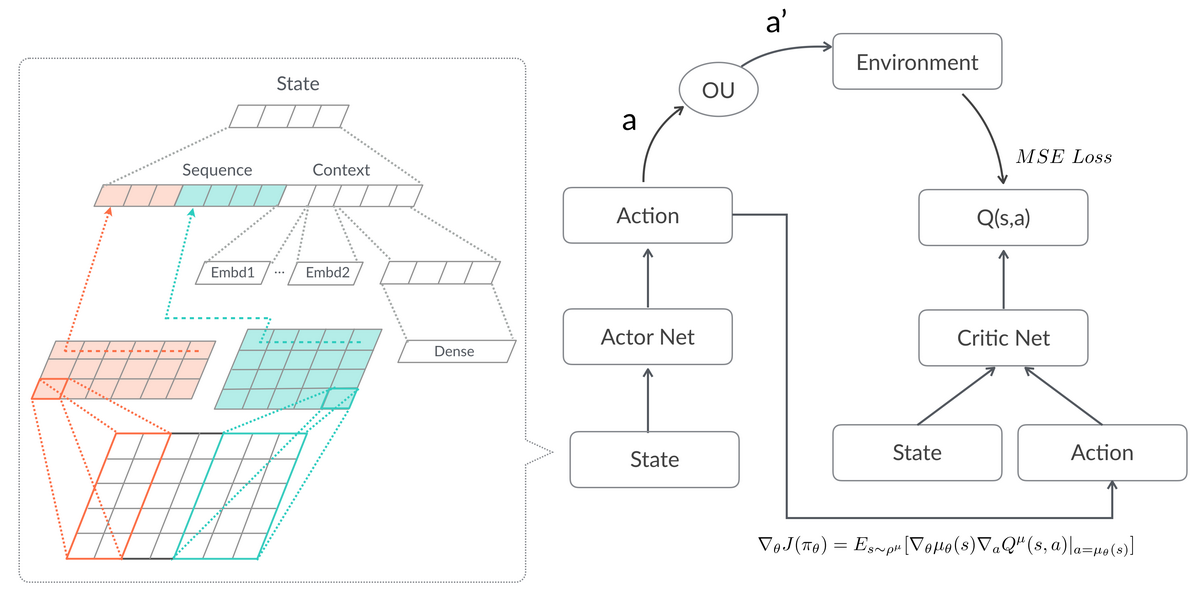
图 8 DDPG 模型
如图 8 所示,基本的 DDPG 是 Actor-Critic 架构。线上使用 Actor 网络,预测当前 State 下最好的动作 a,并通过 Ornstein-Uhlenbeck 过程对预测的 Action 加一个随机噪声得到 a’,从而达到在最优策略附近探索的目的。将 a’ 作用于线上,并从用户(Environment)获得相应的收益。训练过程中,Critic 学习估计当前状态 s 下采取动作 a 获得的收益,使用 MSE 作为 Loss Function:
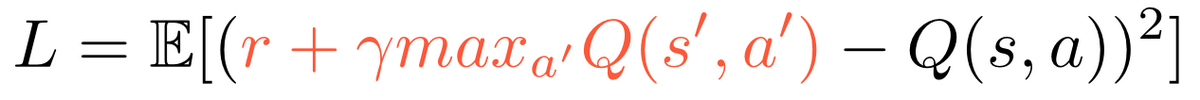
对参数求导:
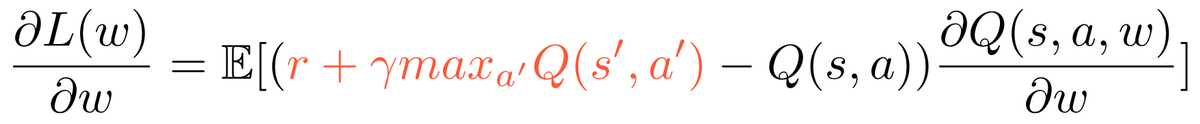
Actor 使用 Critic 反向传播的策略梯度,使用梯度上升的方法最大化 Q 估计,从而不断优化策略:
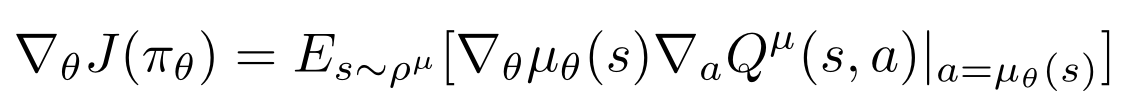
在确定性策略梯度的公式中, 是策略的参数,Agent 将使用策略 在状态 s 生成动作 a, 表示该策略下的状态转移概率。在整个学习过程中,我们不需要真的估计策略的价值,只需要根据 Critic 返回的策略梯度最大化 Q 估计。Critic 不断优化自己对 Q(s,a)的估计,Actor 通过 Critic 的判断的梯度,求解更好的策略函数。如此往复,直到 Actor 收敛到最优策略的同时,Critic 收敛到最准确的 Q(s,a)估计。
接下来基于这些我们介绍的 DDPG 模型改进的工作。
3.1 Advantage 函数
借鉴 DDQN[5]的优势函数 Advantage 的思路,我们把 critic 估计的 Q(s,a)拆分成两个部分:只与状态相关的 V(s),与状态、动作都相关的 Advantage 函数 A(s,a),有 Q(s,a) = V(s) + A(s,a),这样能够缓解 critic 对 Q 过高估计的问题。具体到推荐环境中,我们的策略只是对排序模型的融合参数做调整,收益主要是由状态决定的。
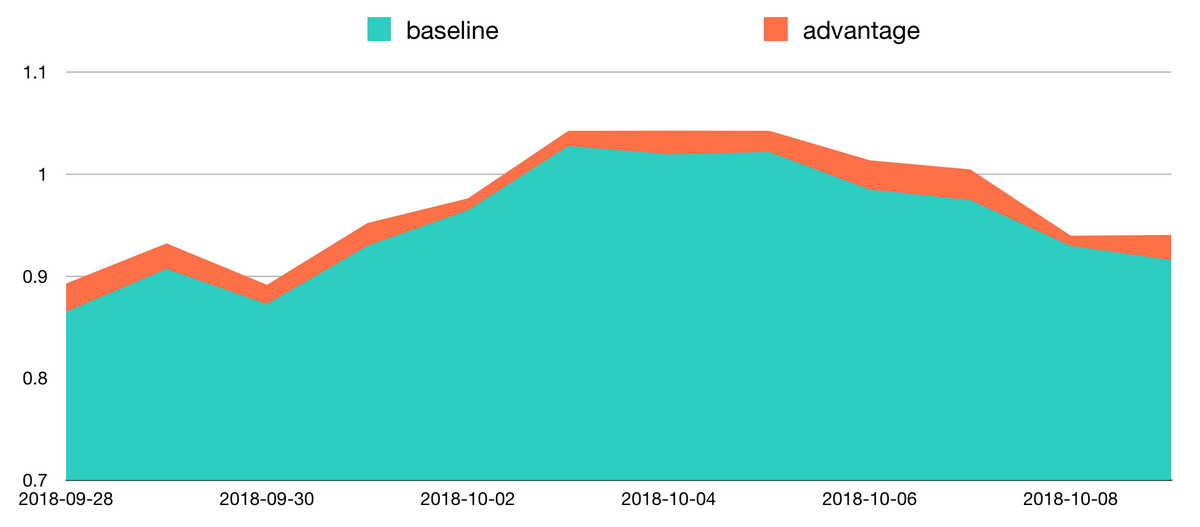
图 9 实验组与基线的 Q 值对比
如图 9 所示,在实际实验中观察 V(s)和 A(s,a)均值的比值大约为 97:3,可以验证我们的这一判断。在实际训练过程中,我们先根据状态和收益训练 V(s),再使用 Q(s,a)-V(s)的残差训练 A(s,a),很大程度上提升了训练稳定性,并且我们可以通过残差较为直观地观测到到当前策略是否优于基线。图 8 中 A(s,a)稳定大于 0,可以认为强化学习在自己的目标上取得了稳定的正向收益。
3.2 State 权值共享
受 A3C[6]网络的启发,我们观察到 DDPG 的网络中 Actor 和 Critic 网络中都有 State 的表达,而在我们的场景中大部分参数都集中在 State 的部分,在十万量级,其他参数只有数千,因此我们尝试把 State 部分的权重做共享,这样可以减少约一半的训练参数。
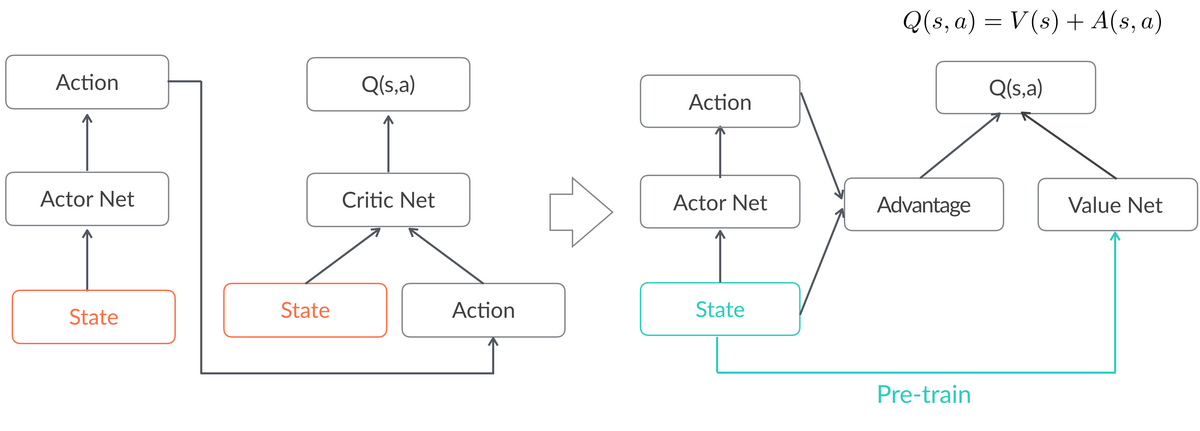
图 10 使用 advantage 函数并做 state 权值共享
改进后的网络结构如图 10 所示。对于这个网络结构,我们注意到有 V(s)的分支和动作不相关,意即我们不需要具体的 Action 也可以学习该 State 下 Q 的期望,这就允许我们在线下使用基线策略千万级的数据量做 预训练,线上也同时使用基线和实验流量做实时更新,从而提升训练的效果和稳定性。又因为这条更新路径包含了所有 State 的参数,模型的大部分参数都可以得到充分的预训练,只有 Action 相关的参数必须依赖 Online Learning 的部分,这就大幅提高了我们的实验迭代效率。原来我们需要上线后等待一周训练再观察效果,改进后上线第二天就可以开始观察效果。
3.3 On-policy
在 A2C[7]的论文里作者论述了他们的见解:同步 A2C 实现比异步实现的 A3C 表现要好。目前尚未看到任何证据证明异步引入的噪声能够提供任何性能收益,因此为了提升训练效率,我们采取了这个做法,使用同一套参数估计 Q_{t+1}和更新 Q_t,从而使模型参数再次减半。
3.4 扩展到多组并行策略
考虑多组强化学习实验同时在线的情况,结合 A/B Test 环境特点,我们把以上网络框架扩展到多 Agent 的情况。
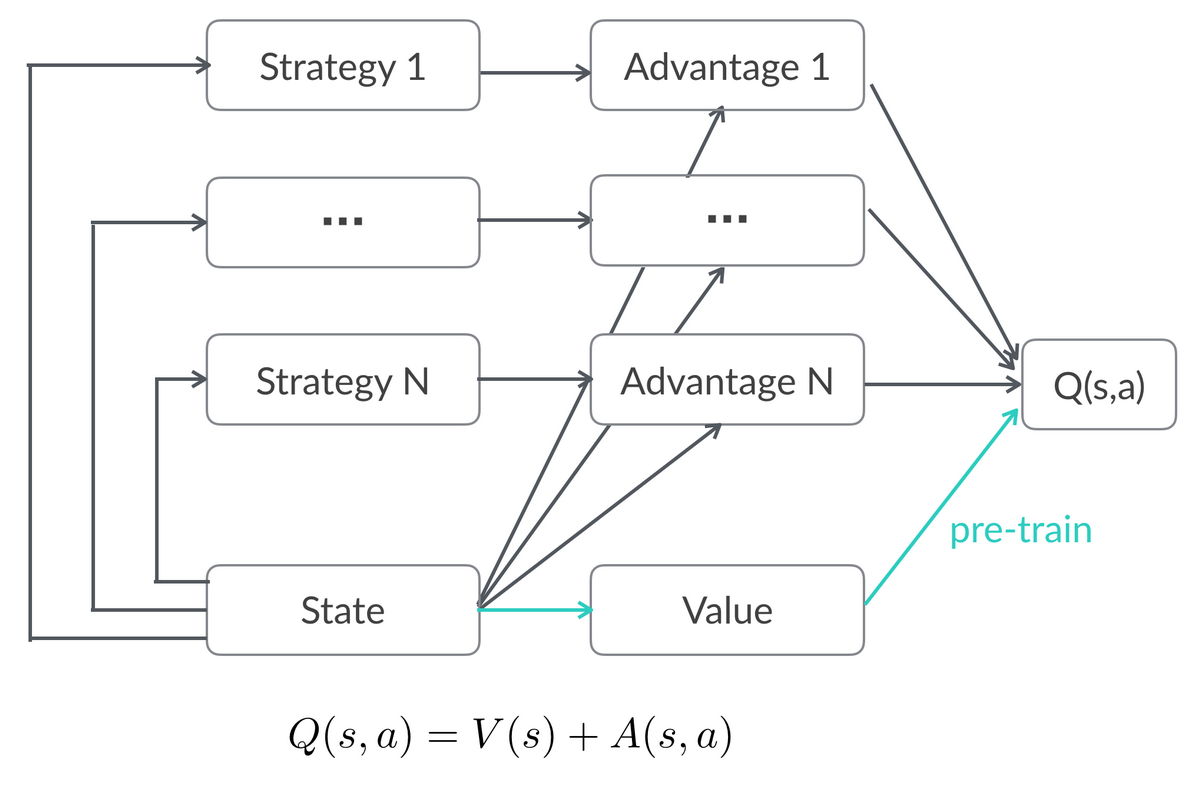
图 11 支持多组线上实验 DDPG 模型
如图 11 所示,线上多组实验共享 State 表达和 V(s)的估计,每个策略训练自己的 A(s,a)网络且能快速收敛,这样的结构一方面使训练过程更加稳定,另一方面为强化学习策略全量提供了可能性。
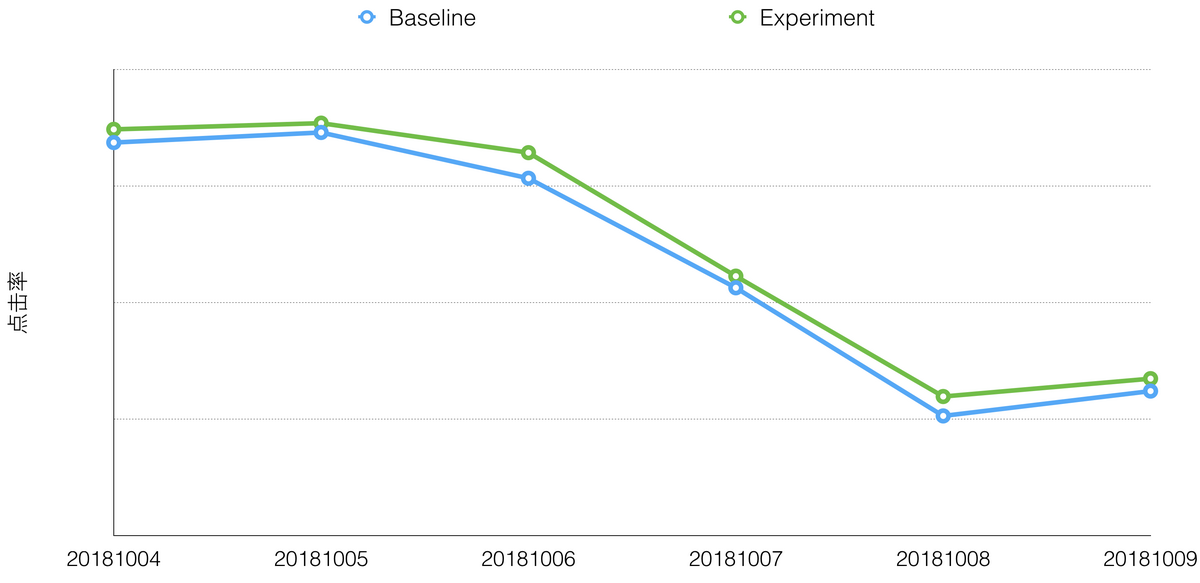
图 12 点击率分天实验效果
在 DDPG 的改造工作中,我们使用 Advantage 函数获得更稳定的训练过程和策略梯度。State 权值共享和 On-Policy 方法使我们的模型参数减少 75%。Advantage 函数和 State 权值共享结合,允许我们使用基线策略样本做数据增强,使每天的训练样本从十万量级扩展到百万量级,同时充分的预训练保证策略上线后能迅速收敛。经过这些努力,强化学习线上实验取得了稳定的正向效果,在下单率效果持平的情况下,周效果点击率相对提升 0.5%,平均停留时长相对提升 0.3%,浏览深度相对提升 0.3%。修改过的模型与 A2C 的主要区别是我们仍然使用确定性策略梯度,这样我们可以少估计一个动作的分布,即随机策略方差降至 0 的特例。图 12 表明强化实习的效果是稳定的,由于“猜你喜欢”的排序模型已经是业界领先的流式 DNN 模型,我们认为这个提升是较为显著的。
4 基于 TF 的轻量级实时 DRL 系统
强化学习通常是在一次次试错(Trial-and-Error)中学习,实时地改进策略并获得反馈能大幅提升学习效率,尤其在连续策略中。这一点在游戏场景下很容易理解,相应地,我们也在推荐系统中构建了实时深度学习系统,让策略更新更加高效。为了支持实时更新的 DRL 模型和高效实验,我们针对 Online Learning 的需求,基于 TensorFlow 及 TF Serving 做了一些改进和优化,设计并实现了一套特征配置化的实时更新的 DRL 框架,在实验迭代过程中沉淀了 DQN、DDQN、DDPG、A3C、A2C、PPO[8]等模型。系统架构如图 13 所示:
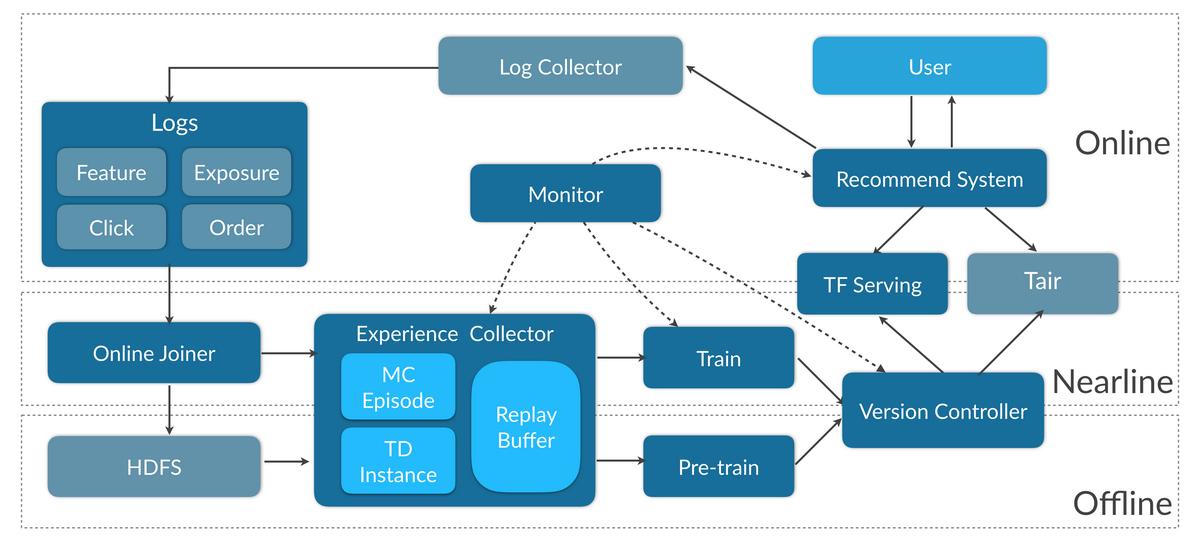
图 13 实时更新的强化学习框架
训练部分工作流如下:
Online Joiner 从 Kafka 中实时收集特征和用户反馈,拼接成 Point-Wise 粒度的 Label-Feature 样本,并把样本输出到 Kafka 和 HDFS,分别支持在线和离线更新。
Experience Collector 收集上述样本,合并为 List-Wise 的请求粒度,并根据请求时间戳拼接成列表形式的 MC Episode,再经过状态转移计算拆分成 形式的 TD Instance,输出 MC 或 TD 格式的样本支持 RL 训练。
Trainer 做输入特征的预处理,使用 TensorFlow 训练 DRL 模型。
Version Controller 负责调度任务保证实效性和质量,并把训练完成且指标符合预期模型推送到 TF Serving 和 Tair 中,这部分只需要 Actor 相关的参数。Tair 作为弥补 TF 在 Online Learning 短板辅助的 PS,后面会具体介绍。
Monitor 监控和记录整个训练流程中的数据量和训练指标,对不符合预期的情况发出线上告警。
新模型上线前会先做离线的 Pre-Train,使用基线策略的数据学习 State 的表达和 Value net。上线后实时同时更新 Actor,Advantage 和 Value 的参数。
线上预测部分,推荐系统的 Agent 从 Tair 获取预处理参数,并将处理后的特征喂给 TF Serving 做前向传播,得到 Action 并对展现给用户的排序结果做相应的干预。
针对 TensorFLow 对 Online Learning 支持比较弱,Serving 对千万级 Embedding 处理效率不高的问题,我们做了一些改进:
在线上特征的分布会随时间而改变,针对 Dense 特征我们自己维护增量的 Z-Score 算法对特征做预处理。
Embedding 特征的输入维度也经常发生变化,而 TF 不支持变长的 Input Dimention,为此我们维护了全量的 ID-Embedding 映射,每次训练让模型加载当前样本集合中的高频 Embedding。
千万级 Item Embedding 会大幅降低训练和预测的效率,为此我们把这部分映射在预处理中,把映射后的矩阵直接作为 CNN 的输入。
为了提升特征工程的实验效率,支持特征配置化生成模型结构。
此外,TF serving 在更新模型一两分钟内响应时间会骤然升高,导致很多请求超时,原因有二,其一,serving 的模型加载和请求共用一个线程池,导致切换模型使阻塞处理请求;其二,计算图初始化是 lazy 的,这样新模型后的第一次请求需要等待计算图初始化。这个问题在更新模型频 Low 对 online learning 支持比较弱繁的 Online Learning 场景影响较大,我们采用切分线程池和 warm up 初始化的方式解决。更具体的方案和效果可以参考美团另一篇技术博客[9]。
5 总结和展望
强化学习是目前深度学习领域发展最快的方向之一,其与推荐系统和排序模型的结合也有更多价值等待发掘。本文介绍了强化学习在美团“猜你喜欢”排序场景落地的工作,包括根据业务场景不断调整的 MDP 建模,使强化学习能够取得一定的正向收益;通过改进 DDPG 做数据增强,提升模型的鲁棒性和实验效率,从而取得稳定的正向收益;以及基于 TensorFlow 的实时 DRL 框架,为高效并行策略迭代提供了基础。
经过一段时间的迭代优化,我们在强化学习方面也积累了一些经验,与传统的监督学习相比,强化学习的价值主要体现在:
灵活的奖励塑形,能支持各种业务目标建模,包括不限于点击率、转化率、GMV、停留时长、浏览深度等,支持多目标融合,为业务目标直接负责。
充满想象空间的动作设计,不需要直接的 Label,而是通过网络来生成和评价策略,适合作为监督学习的补充。这点和 GAN 有相通之处。
考虑优化长期收益对当前决策造成的影响,Agent 与 Environment 交互频繁的场景更加能体现强化学习的价值。
同时强化学习作为机器学习的一个分支,很多机器学习的经验仍然适用于此。比如数据和特征决定效果的上限,模型和算法只是不断逼近它。对于强化学习而言特征空间主要包含在状态的建模中,我们强烈建议在状态建模上多做一些尝试,并信任模型有能力从中做出判断。再如,使用更多的训练数据降低经验风险,更少的参数降低结构风险的思路对强化学习仍然适用,因此我们认为 DDPG 的改进工作能够推广到不同业务的线上 A/B Test 场景中。此外,我们在训练过程中也遇到了强化学习对随机性敏感的问题[10],为此我们线上使用了多组随机种子同时训练,选择表现最好的一组参数用于实际参数更新。
在目前的方案中,我们尝试的 Action 是调整模型融合参数,主要考虑这是个排序问题中比较通用的场景,也适合体现强化学习的能力,而实际上对排序结果的干预能力是比较有限的。未来我们会探索不同品类、位置、价格区间等跟用户意图场景强相关属性的召回个数,调整排序模型隐层参数等方向。另外在解决学习效率低下的问题上,还将尝试 Priority Sampling 提高样本利用效率,Curious Networks 提升探索效率等方法。也欢迎对强化学习感兴趣的朋友们与我们联系,一起交流探索强化学习在工业界的应用与发展,同时对文章的错漏之处也欢迎大家批评指正。
参考文献
[1] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah. Wide & deep learning for recommender systems. CoRR, 2016.
[2] Yan, P., Zhou, X., Duan, Y. E-commerce item recommendation based on field-aware Factorization
Machine. In: Proceedings of the 2015 International ACM Recommender Systems Challenge, 2015.[3] Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Rusu, Andrei A, Veness, Joel, Bellemare,
Marc G, Graves, Alex, Riedmiller, Martin, Fidjeland, Andreas K, Ostrovski, Georg, et al. Humanlevel
control through deep reinforcement learning. Nature, 2015.[4] Lillicrap, T., Hunt, J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. Continuous control with deep reinforcement learning. In International Conference, 2015
on Learning Representations, 2016.[5] Wang, Z., de Freitas, N., and Lanctot, M. Dueling network architectures for deep reinforcementlearning. Technical report, 2015.
[6] Volodymyr Mnih, Adri
a Puigdomenech Badia, Mehdi Mirza, Alex Graves, Tim-othy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asyn-chronous methods for deep reinforcement learning. ICML, 2016[7] Y. Wu, E. Mansimov, S. Liao, R. Grosse, and J. Ba. Scalable trust-region method for deep reinforcementlearning using kronecker-factored approximation. arXiv preprint arXiv:1708.05144, 2017.
[8] Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; and Klimov,O. Proximal policy optimization algorithms. arXiv preprintarXiv:1707.06347, 2017
[9] 仲达, 鸿杰, 廷稳. 基于 TensorFlow Serving 的深度学习在线预估. MT Bolg, 2018
[10] P. Henderson, R. Islam, P. Bachman, J. Pineau, D. Precup, and D. Meger. Deep reinforcement learningthat matters. arXiv:1709.06560, 2017.
作者简介
段瑾,2015 年加入美团点评,目前负责强化学习在推荐场景的落地工作。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论