1.背景
在高性能计算中,作为数据载体的存储子系统是至关重要的一环,优秀的存储系统可以保证集群的计算效率及数据安全性。
从高性能计算作业运行的整个生命周期来看,数据的读写可以分为计算前后的原数据和结果数据读写以及计算过程中的中间数据读写。对于前者来说,原始数据和结果数据的存取影响的是计算任务加载和结果存放的时间,对于计算过程中的整体性能并没有根本的影响;而对于后者,中间数据的读写性能会影响到应用程序的整体运行性能,设计不佳的存储子系统会导致处理器时间浪费在 IO 等待上,不能有效的利用在计算本身。
AWS FSx for Lustre 提供了在 AWS 上的托管 Lustre 文件系统,可以在性能、可靠性、数据安全性和 AWS 服务集成等各个方面为提供强有力的存储支撑。
2.简要说明
AWS FSx for Lustre 基于 Lustre 构建,Lustre 是一个久经考验的文件系统,提供 POSIX 接口非常便于 Linux 平台应用的使用,普遍适用于高性能计算、机器学习、视频处理和 EDA 等多种应用负载。利用 AWS FSx for Lustre,我们可以在 AWS 迅速启动和运行一个 Lustre 文件系统,对数据提供亚毫秒级别对访问,并可以提供达到数百 GB/s 的吞吐或者百万级对 IOPS。特别的,AWS FSx for Lustre 具备和 AWS 其他云服务良好的集成,可以将长期数据存放于 S3,并将 FSx for Lustre 用于实时的计算作业,可使用 Direct Connect 或 VPN 将本地工作负载大批量迁移至云中,并可借助 VPC 进行访问控制,CloudWatch 进行监控和 CloudTrail 进行审计。
本文将使用 AWS ParallelCluster 构建一个云上的计算集群,并供给一个特定容量的 FSx for Lustre 文件系统,基于多节点并行 MPI 消息传递的测试工具来评估 FSx for Lustre 的存储性能,从而可以通过类似的方法对实际计算任务的性能需求提供参考依据。
AWS ParallelCluster 是由 AWS 支持的用于集群管理的开源工具,用于帮助使用者在 AWS 云平台上部署和管理高性能计算集群,并可以灵活定义计算资源和共享文件系统,同时也可以支持多种不同的调度器(SGE、Torque、Slurm、AWS Batch 等)对计算作有效的管理和调度。
3.测试架构
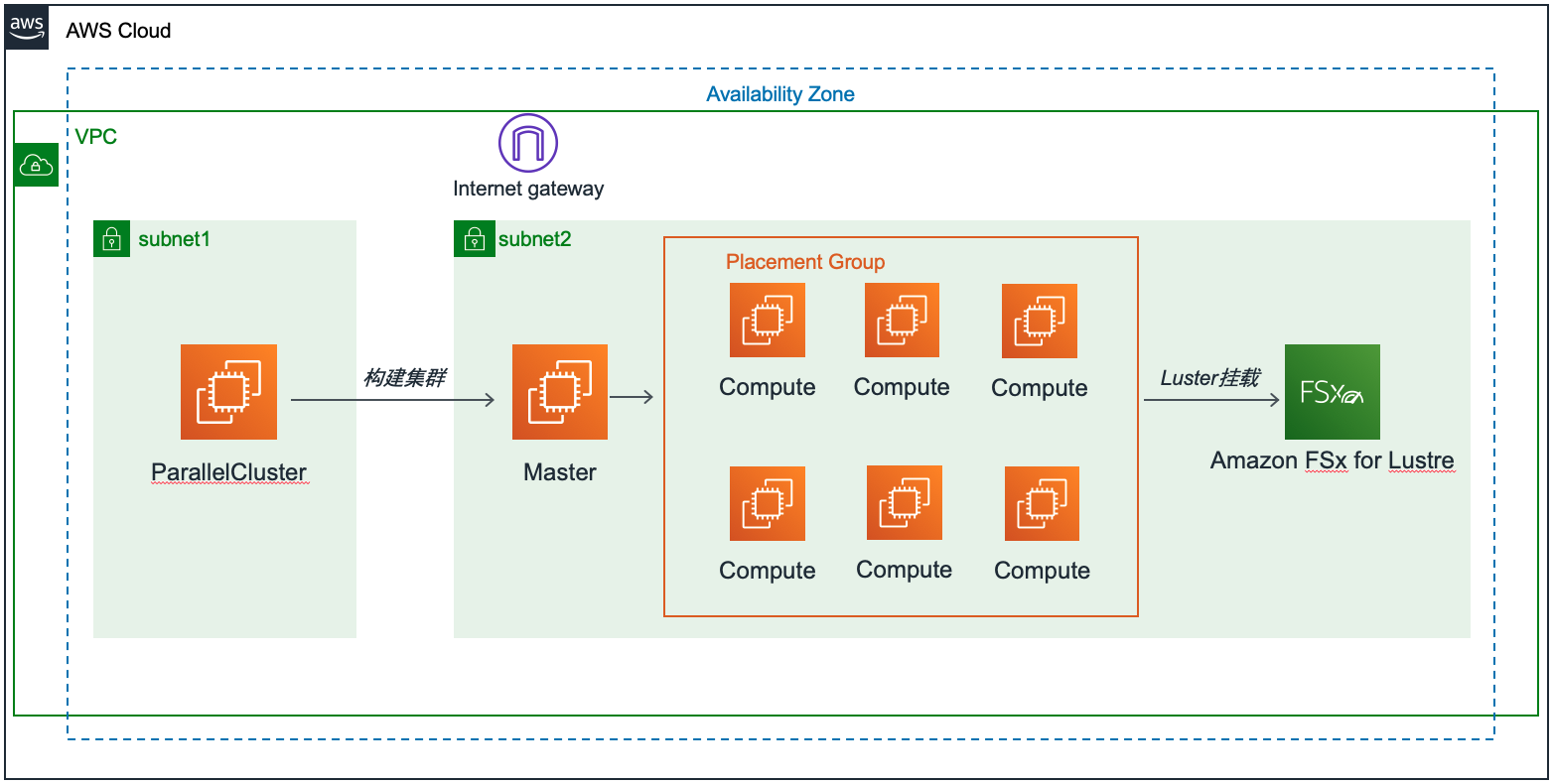
整个系统的架构设计如下,使用一个 9 个 c5.4xlarge 计算实例的集群,并配置 placement group 以充分利用性能,FSx for Lustre 的容量配置为 10800GB,所有资源配置在同一个 VPC 内,FSx for Lustre 的接口与实例处于同一子网。
典型的 Lustre 文件系统的体系结构如下,MDS/MDT 管理和存取所有的元数据,多个 OSS/OST 以 Lustre 对象的方式分布式存储所有的数据。在实际创建时,AWS FSx for Lustre 会以 1200GB 容量为一个 OST 的方式构建文件系统。当前的限制需要以 3600GB 为最小单元(3 个 OST),用其整数倍建立文件系统(未来会以 1200GB 为单位)。所以,在后续的测试中,所建立的 10800GB Lustre 文件系统会包括 9 个 OST,在未来数据实际存储时的可以据此设置合理的分片来提高每个文件的读写性能。同时,AWS FSx for Lustre 会以每 TB 200MBps 提供基线的读性能,并支持短时间的突增。
4.部署及配置
在子网 1 内部署一台 t2.micro 实例用于 ParallelCluster 安装节点。登陆该实例,AWS ParallelCluster 是一个 python 包,我们可将其安装在虚拟环境。
安装 virtualenv 和创建虚拟环境:
Bash
# yum install python3 -y
# python3 -m pip install --upgrade pip
# pip3 install --user --upgrade virtualenv
# virtualenv ~/zwtest
复制代码
激活新建的虚拟环境并安装 AWS ParallelCluster。
Bash
# source ~/zwtest/bin/activate
(zwtest)~# pip3 install --upgrade aws-parallelcluster
# pcluster version
复制代码
之后,需要创建一个配置模版,ParallelCluster 将会参照次模版调用 CloudFormation Stack 创建需要集群。如下是后续测试中使用的配置模版及其选项说明。
Bash
## AWS ParallelCluster config
[aws]
aws_region_name = us-east-1
[cluster zwcluster]
# Name of an existing EC2 KeyPair to enable SSH access to the instances.
key_name = xxxxxx.pem
# Settings section relating to VPC to be used
vpc_settings = zwhpcvpc
# EC2 instance type for master node
master_instance_type = c5.4xlarge
# EC2 instance type for compute nodes
compute_instance_type = c5.4xlarge
# Initial number of EC2 instances to launch as compute nodes in the cluster for schedulers other than awsbatch.
initial_queue_size = 9
# Boolean flag to set autoscaling group to maintain initial size and scale back for schedulers other than awsbatch.
maintain_initial_size = true
# Cluster scheduler
scheduler = torque
# Settings section relating to FSx for Lustre to be used
fsx_settings = zwfs
[vpc zwhpcvpc]
# ID of the VPC you want to provision cluster into
vpc_id = vpc-xxxxx
# ID of the Subnet you want to provision the Master server into
master_subnet_id = subnet-xxxxxx
[global]
cluster_template = zwcluster
update_check = true
sanity_check = true
[aliases]
ssh = ssh {CFN_USER}@{MASTER_IP} {ARGS}
[fsx zwfs]
# Defines the mount point for the Amazon FSx for Lustre file system on the master and compute nodes.
shared_dir = /fsx
# Specifies the storage capacity of the file system, in GiB
storage_capacity = 10800
复制代码
依照上述配置文件,ParallelCluster 将会建立一个如前图示的集群,master 与 compute 位于同一个子网内,同时新建一个 FSx for lustre 10800GB 的 lustre 文件系统,该文件系统被挂载在所有的 master 和 computer 上,无需再手动安装配置 lustre 客户端和挂载文件系统。同时,集群已经配置了基于 openmpi 的并行环境,后续使用此环境进行 lustre 文件系统性能的评估。
Bash
# pcluster create zwcluster
Beginning cluster creation for cluster: zwcluster
Creating stack named: parallelcluster-zwcluster
Status: parallelcluster-zwcluster - CREATE_COMPLETE
MasterPublicIP: xx.xxx.xxx.xx
ClusterUser: ec2-user
MasterPrivateIP: 192.168.0.186
复制代码
创建成功之后,我们可以查看到 master 的 IP 地址,使用指定的私钥,ssh 登陆 master 节点。确认到 lustre 文件系统已经被挂载。
Bash
# df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 16G 64K 16G 1% /dev
tmpfs tmpfs 16G 0 16G 0% /dev/shm
/dev/nvme0n1p1 ext4 17G 8.5G 8.2G 51% /
/dev/nvme1n1 ext4 20G 45M 19G 1% /shared
192.168.0.206@tcp:/fsx lustre 10T 41M 10T 1% /fsx
复制代码
同时,可以观察到该文件系统结构(1 个 MDT 和 9 个 OST)和容量。
Bash
# lfs df -h
UUID bytes Used Available Use% Mounted on
fsx-MDT0000_UUID 309.5G 8.6M 309.5G 0% /fsx[MDT:0]
fsx-OST0000_UUID 1.1T 4.6M 1.1T 0% /fsx[OST:0]
fsx-OST0001_UUID 1.1T 5.0M 1.1T 0% /fsx[OST:1]
fsx-OST0002_UUID 1.1T 5.6M 1.1T 0% /fsx[OST:2]
fsx-OST0003_UUID 1.1T 4.6M 1.1T 0% /fsx[OST:3]
fsx-OST0004_UUID 1.1T 5.1M 1.1T 0% /fsx[OST:4]
fsx-OST0005_UUID 1.1T 4.6M 1.1T 0% /fsx[OST:5]
fsx-OST0006_UUID 1.1T 4.6M 1.1T 0% /fsx[OST:6]
fsx-OST0007_UUID 1.1T 5.1M 1.1T 0% /fsx[OST:7]
fsx-OST0008_UUID 1.1T 4.6M 1.1T 0% /fsx[OST:8]
filesystem_summary: 9.9T 44.0M 9.9T 0% /fsx
复制代码
如果没有指定,ParallelCluster 默认的 mpi 实现会安装 OpenMPI-3.1.4,稍后的性能评估需要依赖 mpi 环境。
Bash
# mpirun –version
mpirun (Open MPI) 3.1.4
复制代码
准备 machinefile 配置文件,运行 mpi 应用时,可以根据设置来指定 compute node 和相应的进程分布。可以通过已经安装的 Torque 来查看集群中的 compute 节点。
Bash
# qnodes | grep ip-192.168.0 | sed "/uname/d"
复制代码
编辑类似如下的 machinefile,指定作业运行时参与计算的 compute 节点,和每个节点的进程数,我们的测试中,节点内部和节点之间均通过多进程的方式,通过 mpi 进行进程间的通信。
Bash
# cat mf
ip-192-168-0-38 slots=12
ip-192-168-0-189 slots=12
ip-192-168-0-10 slots=12
ip-192-168-0-110 slots=12
ip-192-168-0-41 slots=12
ip-192-168-0-249 slots=12
复制代码
至此,已经准备好了整个用于评估的环境。
5.性能评估
如前所述,9 个 compute 节点和 1 个 10800GB 的 Lustre 已经配置完成,接下来采用多客户端并发访问的方式评估存储子系统的性能情况,性能测试工具采用 IOR 以 MPI 并行的方式进行并发访问,在实际评估中,可以根据客户端节点数量以及 IOR 进程数的不同来评估存储系统的性能和变化曲线。另外,利用 MDtest 来评估集群中 MDS/MDT 元数据的性能。
当前版本的 IOR 已经包含了 MDtest,可以同时安装这两个工具,使用 mpicc 编译。
Bash
# git clone https://github.com/hpc/ior.git
# ior/bootstrap
# configure --prefix=/fsx/ior/ && make all && make install
复制代码
接下来就可以使用 IOR 多节点评估 FSx for Lustre 所建文件系统的带宽。使用如下参数避免 Client/Server cache 获取稳定的 Lustre 实际读写吞吐(blocksize 大小设置为 1048576m/totalprocesses)。
Bash
# mpirun -np totalprocesses -machinefile path/to/machineflie /fsx/ior/bin/ior -posix -vv -i 1 -w -r -k -F -g -C -e -b blocksize -t 1m -o path/to/outputfile
复制代码
结果如下,可以看到在 9 compute 节点,每节点 8 进程时的测试读写吞吐。
Bash
Options:
api : POSIX
apiVersion :
test filename : /fsx/ior_test_tmp/open_tmpfile8_9
access : file-per-process
type : independent
segments : 1
ordering in a file : sequential
ordering inter file : constant task offset
task offset : 1
tasks : 72
clients per node : 8
repetitions : 1
xfersize : 1 MiB
blocksize : 14.22 GiB
aggregate filesize : 1023.96 GiB
Results:
access bw(MiB/s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---------- --------- -------- -------- -------- -------- ----
Commencing write performance test: Fri Aug 30 15:59:21 2019
write 3200.44 14912512 1024.00 0.003124 327.62 0.001546 327.62 0
Commencing read performance test: Fri Aug 30 16:04:49 2019
read 3279.96 14912512 1024.00 0.001538 319.68 0.002255 319.68 0
Max Write: 3200.44 MiB/sec (3355.90 MB/sec)
Max Read: 3279.96 MiB/sec (3439.29 MB/sec)
复制代码
另外元数据的性能对于 Lustre 也是非常重要的评估角度,同样通过多节点 mdtest 的测试方式来评估文件创建删除,目录的创建删除等元数据操作。
Bash
# mpirun -np totalprocesses -machinefile path/to/machinefile /fsx/ior/bin/mdtest -i 2 -b 1 -z 1 -L -I 1000 -u -t -d mdtest/filepath
复制代码
结果如下,可以看到在 9 compute 节点,每节点 16 进程时的测试读写吞吐
Bash
mdtest-3.3.0+dev was launched with 144 total task(s) on 9 node(s)
Command line used: /fsx/ior/bin/mdtest '-i' '2' '-b' '1' '-z' '1' '-L' '-I' '1000' '-u' '-t' '-d' '/fsx/mdtest_test_tmp/'
Path: /fsx/mdtest_test_tmp
FS: 9.9 TiB Used FS: 0.0% Inodes: 7.2 Mi Used Inodes: 0.0%
Nodemap: 111111111111111100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
144 tasks, 144000 files/directories
SUMMARY rate: (of 2 iterations)
Operation Max Min Mean Std Dev
--------- --- --- ---- -------
Directory creation : 2003.402 1343.490 1673.444 329.951
Directory stat : 74243.416 70404.993 72514.780 1725.126
Directory removal : 11117.914 10603.446 10863.579 254.168
File creation : 31128.908 29821.901 30475.412 652.556
File stat : 75614.609 73975.184 74795.487 810.143
File read : 46362.201 45677.846 46019.063 338.446
File removal : 34709.737 33253.591 33985.424 723.575
Tree creation : 93.252 66.093 79.672 13.580
Tree removal : 156.525 91.639 124.082 32.443
-- finished at 08/31/2019 08:44:50 --
复制代码
6.结论
AWS FSx for Luster 可以快速的构建基于 AWS 的托管 Lustre 文件系统,满足应用系统对高性能文件系统的需求。可以使用 IOR 和 MDtest 对 AWS FSx for Lustre 文件系统进行有效评估,作为实际业务需求的评估依据。实际所能达到的性能和节点的规模以及并发度有直接的关联。本文的测试过仅为说明过程,请根据实际情况评估您的系统,并可以根据应用的情况进行不同手段的调优。
7.参考链接
https://docs.aws.amazon.com/parallelcluster/index.html
https://docs.aws.amazon.com/fsx/index.html
https://github.com/hpc/ior
作者介绍:
!
### [](https://amazonaws-china.com/cn/blogs/china/tag/%E8%B5%B5%E4%BC%9F/)
AWS 解决方案架构师,主要
复制代码
本文转载自 AWS 技术博客。
原文链接:
https://amazonaws-china.com/cn/blogs/china/application-performance-evaluation-aws-fsx-lustre-parallel-file-system-hpc/

















评论