总体技术架构
基于单节点部署的 Harbor 随着存储内容和运行日志的增加,系统的存储空间会趋紧饱和。本文将研究和部署基于 Ceph 的分布式 harbor 部署方案。
根据参考文献【1】,在前期部署基于 Ceph 的分部署 Harbor 集群时需要准备五台物理服务器,并且统一软件安装如下:
针对上述相关必备软件的安装可以参考小编之前的文章进行部署和安装。在资源划分上 harbor 分部署集群和 ceph 集群进行了复用。其中一台服务器作为 Nginx 负载均衡,另外 Harbor 节点和 Ceph 节点进行了一定的服用。其中一台服务器作为共享数据库。其资源分配如下所示:
Nginx ——10.10.13.1
Admin——10.10.13.21
Node0——10.10.13.22
Node1——10.10.13.30
Mysql ——10.10.13.31
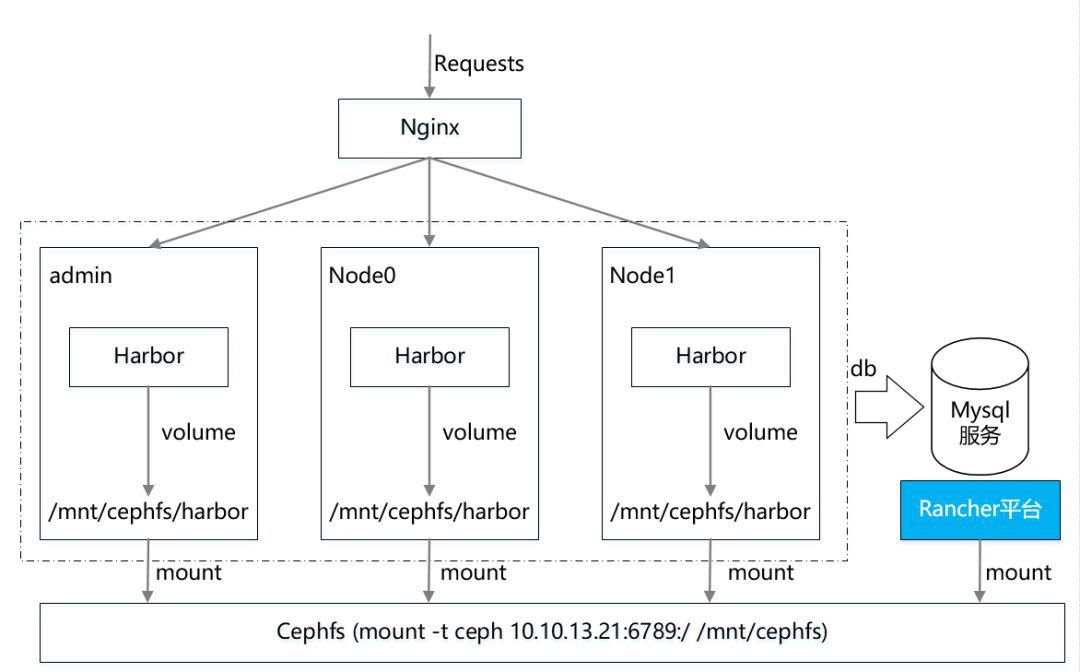
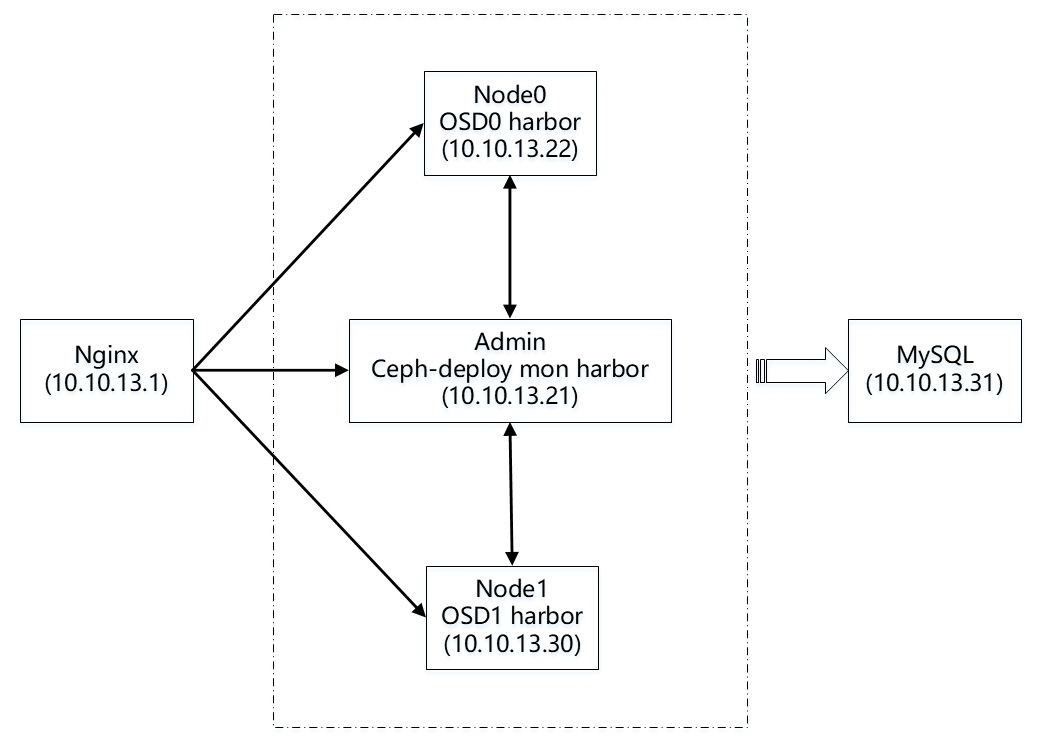
需要说明一下,Ceph 存储集群搭建,admin 作为 ceph-deploy 和 mon,Node0 作为 OSD0,Node1 作为 OSD1(根据参考文献【1】建议多配置几个 mon,组成 HA 高可用),并且将创建的 cephfs mount 到这三个节点上,同事在这三个节点上部署 Harbor 服务组成一个镜像仓库集群(这样 Harbor 就可以直接挂载本地 cephfs 路径上了)。此外,再提供一个节点 Nginx 作为负载均衡将请求均衡到这三个节点,最后再提供一个节点 Mysql 作为外部数据库存储,建议做成 HA 高可用,鉴于目前资源有限,暂时选用一台服务器作为数据库服务器,后续可以采用容器服务来进行替代。
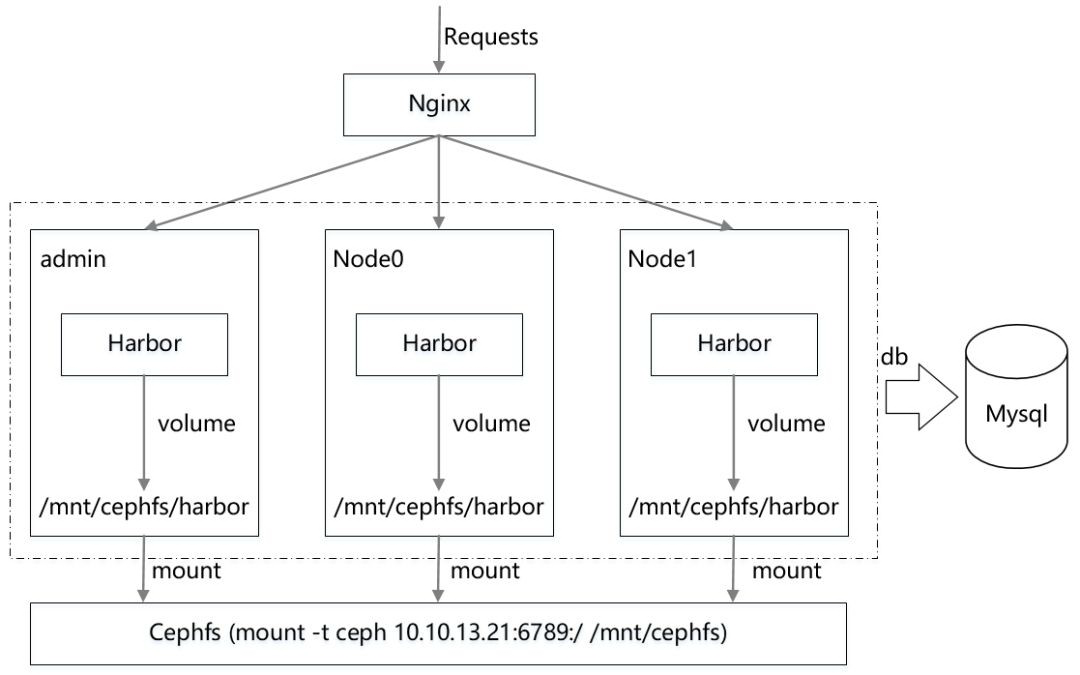
其总体技术架构如下图所示:
图 1 总体技术架构
这里需要说明的是,由于目前资源有限,上述总体技术架构只能保证数据安全,既不会因为 Harbor 节点本身出现故障,从而导致数据丢失的问题。并且 harbor 多节点能够共享数据。解决目前现有的单节点 harbor 系统数据冗余的情况出现数据丢失和存储空间无法扩展的问题。真正在生产系统上应用,还需要注意 Harbor 集群节点的数据快速同步等问题。真正做到数据实时性访问等。而针对镜像数据共享,我们参考文献【1】实现了多 Harbor 服务共享后端存储的方式,即通过 Ceph 分布式存储方案来解决。
图 2 技术实现图
结合上图,每一个 Harbor 节点上都 mount 配置好的 cephfs,然后配置每一个 Harbor 服务的各个组件 volume 都挂载 cephfs 路径,最后通过统一的入口 Nginx 负载均衡将流量负载到各个 Harbor 服务上,来实现整体 Harbor 集群的“高可用”。
但是还需要注意的是,在本方案中将默认 harbor-db 数据库组件拆出来,让其连接外部 Mysql 数据库(默认 Harbor 会在每个节点上都启动 Mysql 服务进行数据存储,这样数据就无法实现统一,即使我们将 Mysql 数据库存储在 cephfs 上,三个节点共用同一份数据,但是依然不可行,因为 Mysql 多个实例之间无法共享一份 Mysql 数据文件。
Ceph 介绍及部署
Ceph 是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph 项目最早起源于 Sage 就读博士期间的工作(最早的成果于 2004 年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。Redhat 及 Open Stack 都可与 Ceph 整合以支持虚拟机镜像的后端存储【2】。
1、Ceph 架构
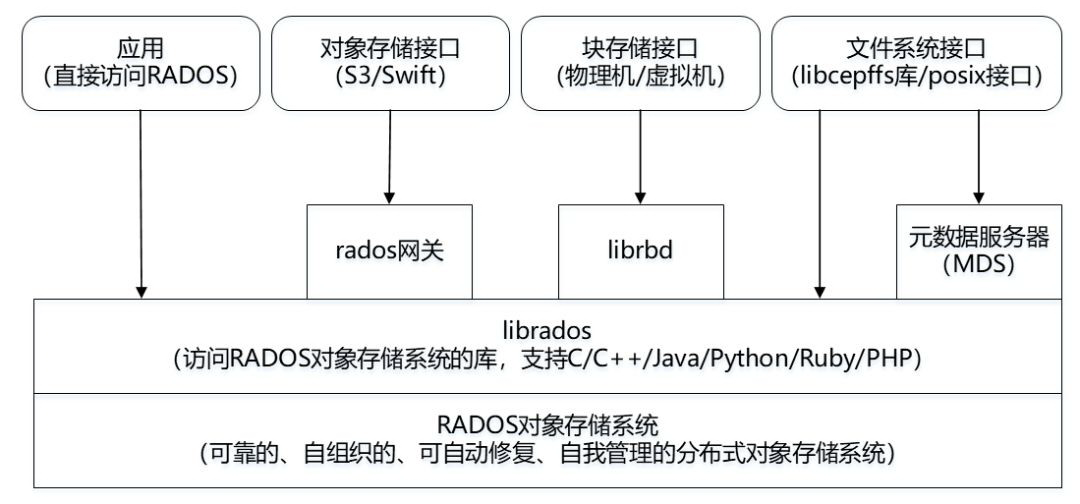
Ceph 主要基于 RADOS 对象存储系统来实现可靠的、自动修复、自我管理的分布式对象存储系统。上层通过 librados 封装了一层接口,支持 C/C++/Java/Python/Ruby/PHP 等。支持三种接口:
图 3 Ceph 架构图
2、Ceph 核心组件及概念介绍
Monitor
一个 Ceph 集群需要多个 Monitor 组成的小集群,它们通过 Paxos 同步数据,用来保存 OSD 的元数据。
OSD
OSD 全程 Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个 Ceph 集群一般都有多个 OSD。
MDS
MDS 全称 Ceph Metadata Server,是 CephFS 服务依赖的元数据服务。
Object
Ceph 最底层的存储单元是 Object 对象,每个 Object 包含元数据和原始数据。
PG
PG 全称 Placement Groups,是一个逻辑的概念,一个 PG 包含多个 OSD。引入 PG 这一层其实是为了更好的分配数据和定位数据。
RADOS
RADOS 全称 Reliable Autonomic Distributed Object Store,是 Ceph 集群的精华,用户实现数据分配、Failover 等集群操作。
Librados
Librados 是 Rados 提供库,因为 RADOS 是协议很难直接访问,因此上层额 RBD、RGW 和 CephFS 都是通过 librados 访问的,目前提供 PHP、Ruby、Java、Python、C 和 C++支持。
CRUSH
CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
RBD
RBD 全称 RADOS block device,是 Ceph 对外提供的块设备服务。
RGW
RGW 全称 RADOS Gateway,是 Ceph 对外提供的对象存储服务,接口与 S3 和 Swift 兼容。
CephFS
CephFS 全称 Ceph File System,是 Ceph 对外提供的文件系统服务。
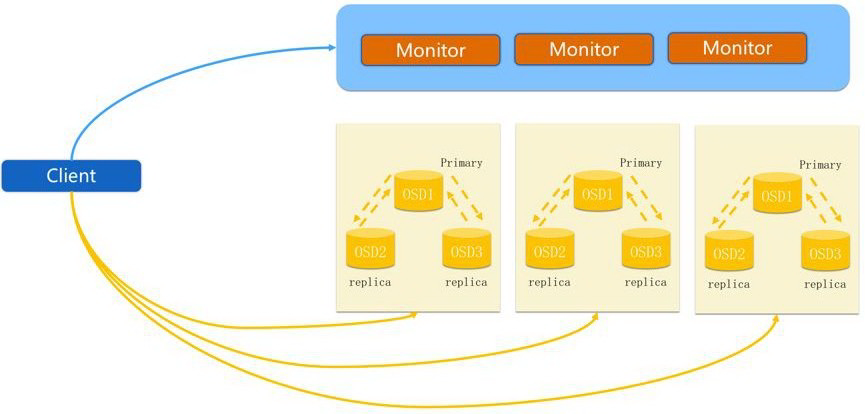
3、Ceph IO 流程及数据分布
图 4 Ceph IO 流程图
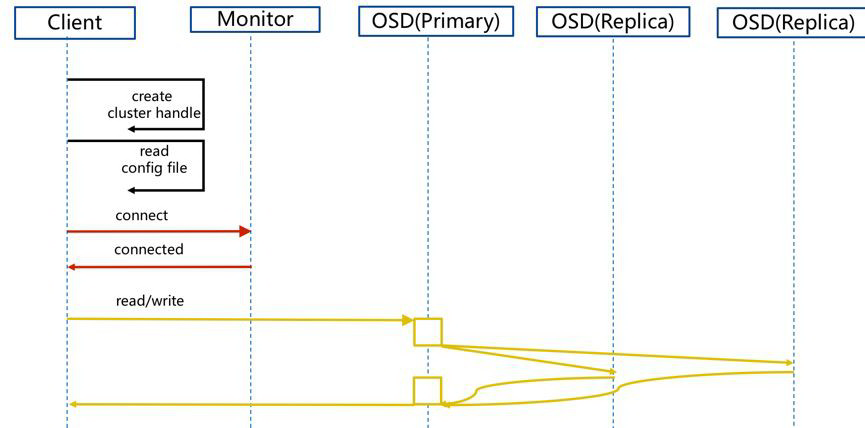
图 5 正常 Ceph IO 流程图
依据上述流程图所示,其正常 IO 流程如下:
(1)client 创建 cluster handle;
(2)client 读取配置文件;
(3)client 连接上 monitor,获取集群 map 信息;
(4)client 读取 IO,根据 crush map 算法请求对应的主 OSD 数据节点;
(5)主 OSD 数据节点同时写入另外两个副本节点数据;
(6)等待主节点以及另外两个副本节点写完数据状态;
(7)主节点及副本节点写入状态都成功后,返回给 client,IO 写入完成。
上述描述属于正常 Ceph IO 流程。针对新主 IO 流程、算法流程以及 Pool 和 PG 分布等流程具体可以参考文献【2】等。
4、Ceph 集群部署
介绍完 Ceph 相关概念和实现流程,在本次 Ceph 部署采用四台物理服务器作为 Ceph 集群节点进行部署。根据参考文献【3】的描述,在部署 Ceph 集群时,需要安装相关的软件及版本如下:
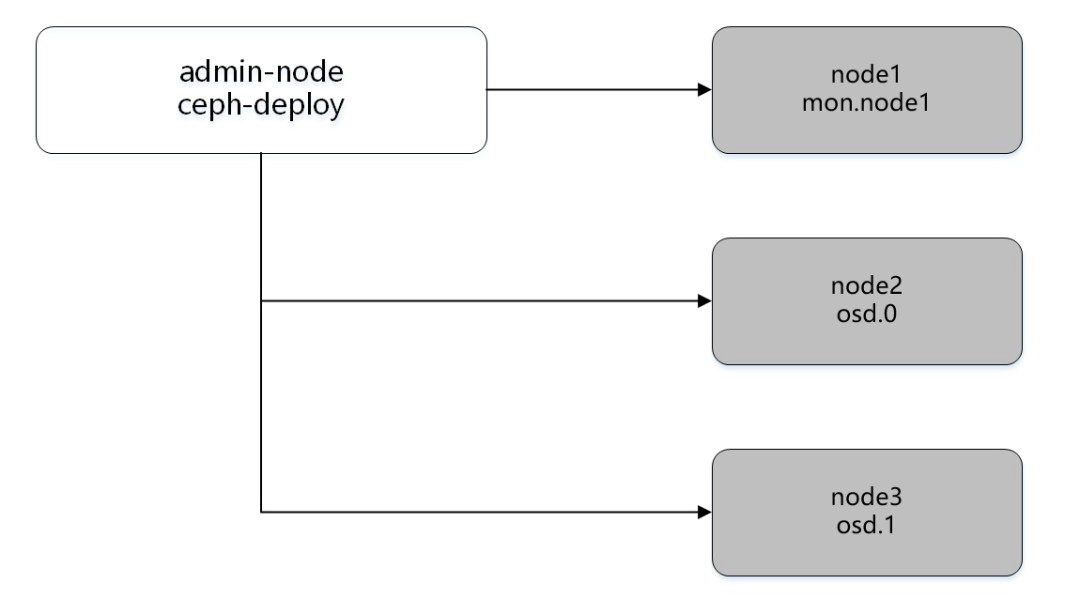
根据 Ceph 官方文档中建议安装一个 ceph-deploy 管理节点和一个三节点的 Ceph 存储集群来研究 Ceph 的基本特性,结构图如下:
图 6 Ceph 部署结构图
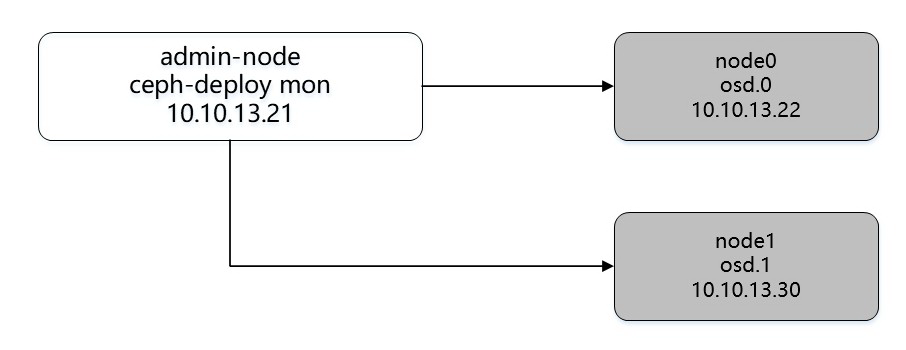
不过由于资源有限,所以小编在解决方案中少用了一个节点,将 mon.node1 节点的 Monitor 功能迁移到 admin-node 节点上,所以集群结构图如下图所示:
图 7 Ceph 实际部署结构图
Ceph 分布式存储集群有三大组件组成,分为:Ceph Mointor、Ceph OSD、Ceph MDS,MDS 非必须安装,只有当使用 CephFS 文件存储时才需要安装。因此暂时不安装 MDS。
4.1 配置节点
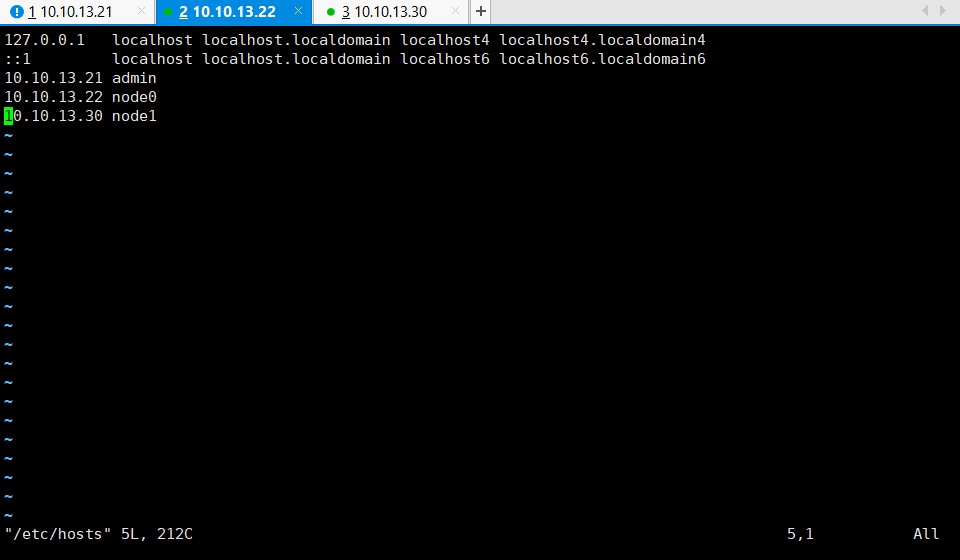
为了方便后续安装,以及 ssh 方式连接各个节点,首先修改各个节点的 Hostname 以及配置 Hosts 如下:
图 8 配置节点
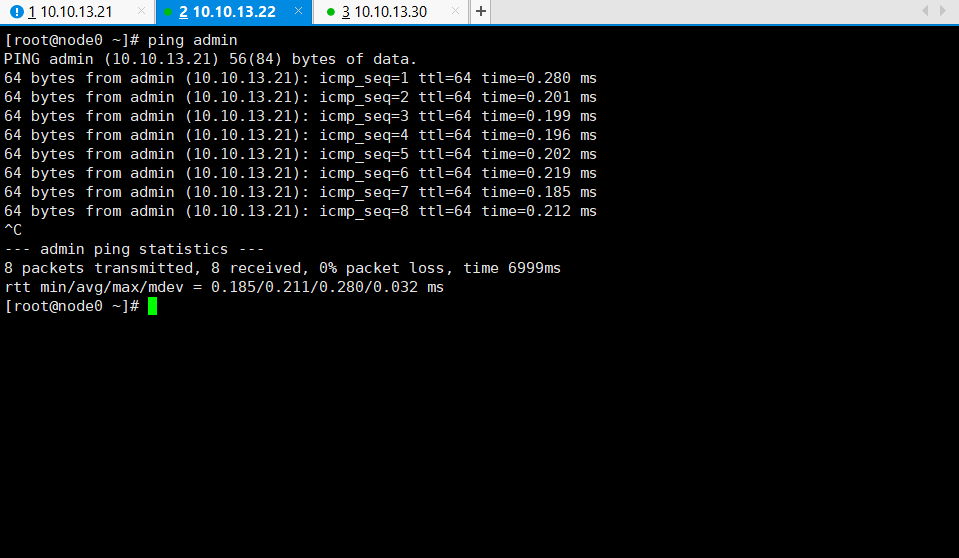
需要在所有节点上都需要进行上述的配置。在配置完成以后,需要 ping 一下是否可以互相访问。如下图所示:
图 9 检测 ping 各节点
4.2 安装部署工具 ceph-deploy
Ceph 提供部署工具 ceph-deploy 来方便安装 Ceph 集群,我们只需要在 ceph-deploy 节点上安装即可,这里对应的就是 admin-node 节点。把 Ceph 仓库添加到 ceph-deploy 管理节点,然后安装 ceph-deploy。根据 centos7 版本,安装相关依赖库,执行如下命令:
$ sudo yum install -y yum-utils && sudo yum-config-manager --add-repo po https://dl.fedoraproject.org/pub/epel/7/x86_64/ &&/ && sudo yum install --nogpgcheck -y epel-release && sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && sudo rm /etc/tc/yum.repos.d/d.d/.d/dl.fedoraproject.org*
复制代码
#添加 Ceph 源:
$ sudo vim /etc/tc/yum.repos.d/c.d/.d/ceph.repo[Ceph-noarch]name=Ceph noarch packagesbaseurl=rl=http://download.ceph.com/rpm-jewel/el7/noarchenaenabled=1gpgcheck=1type=rpm-mdgpgkey=ey=https://download.ceph.com/keys/release.ascpripriority=1
复制代码
#安装 ceph-deploy
$ sudo yum update && sudo yum install ceph-deploy
复制代码
4.3 安装 NTP 和 OpenSSH
根据官方建议,在所有 Ceph 节点上安装 NTP 服务(特别时 Ceph Monitor 节点),以免因时钟漂移导致故障。
#yum 安装 ntp
sudo yum install ntp ntpdate ntp-doc
复制代码
#校对系统时钟
ntpdate 0.cn.pool.ntp.org
复制代码
后续操作,ceph-deploy 节点需要使用 ssh 方式登录各个节点完成 ceph 安装配置工作,所以要确保各个节点上有可用的 SSH 服务。
# yum 安装 openssh
$ sudo yum install openssh-server
复制代码
# 查看 ssh 版本
$ ssh -VOpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017
复制代码
4.4 创建 Ceph 用户
ceph-deploy 工具必须以普通用户登录 Ceph 节点,且此用户拥有无密码使用 sudo 的权限,因为它需要在安装软件及配置文件的过程中,不必输入密码。官方建议所有 Ceph 节点上给 ceph-deploy 创建一个特定的用户,为了方便起见,小编使用 cephd 这个账户作为特定的用户,而且每个节点上(admin-node、node0、node1)上都需要创建该账户,并且拥有 sudo 权限。
# 在 Ceph 集群各节点进行如下操作
# 创建 ceph 特定用户
$ sudo useradd -d /home/cephd -m cephd$ sudo passwd cephd
复制代码
# 添加 sudo 权限
$ echo "cephd ALL = (root)NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephd$ sudo chmod 0440 /etc/sudoers.d/cephd```1
接下来在ceph-deploy节点(admin-node)上,切换到cephd用户,生成SSH密钥并把其公钥分发到各Ceph节点上,注意使用cephd账户生成,且提示输入密码时,直接回车,因为它需要免密码登录到各个节点。
\# ceph-deploy(admin-node)上执行
\# 生成ssh密钥
复制代码
$ ssh-keygen

复制代码
将公钥复制到 node0 节点
$ ssh-copy-id cephd@node0
将公钥复制到 node1 节点
$ ssh-copy-id cephd@node1
复制完毕,测试一下在ceph-deploy管理节点免密码登录各个节点
复制代码
$ ssh node0
Last login: Fri Dec 8 15:50:08 2018 from admin
$ ssh node1
Last login: Fri Dec 8 15:49:27 2018 from admin
测试没问题,接下来,修改ceph-deploy管理节点上的~/.ssh/config文件,这样无需每次执行ceph-deploy都要指定-usename cephd.这样做同时也简化了ssh和scp的用法。
复制代码
$ vim ~/.ssh/config
Host node0
Hostname node0
User cephd
Host node1
Hostname node1
User cephd
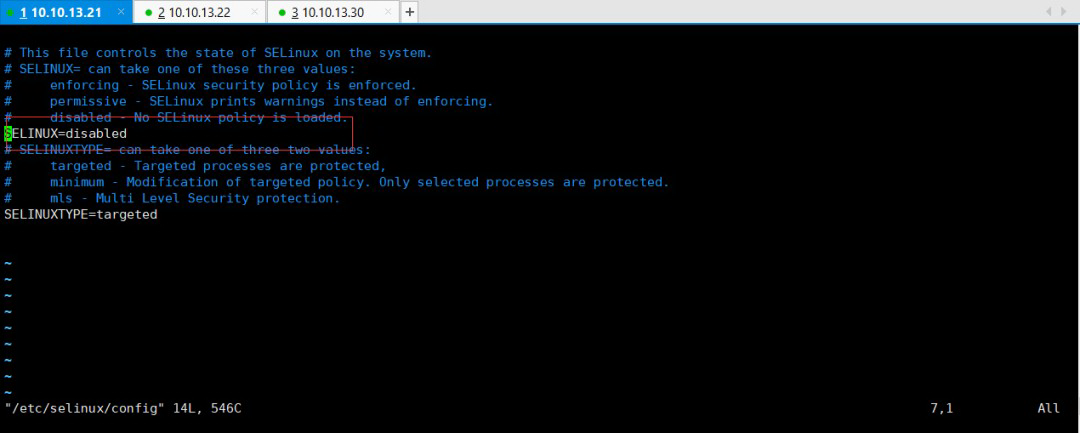
注意为了方便安装,建议将SELinux设置为Permissive或者disabled。
\# 永久生效配置
复制代码
$ sudo vim /etc/selinux/config
SELINUX=disabled #这里设置为 disabled
SELINUXTYPE=targeted
### 5、Ceph存储集群搭建
经过上述一系列的预检设置后,小编就可以开始Ceph存储集群的搭建了。集群结构为admin-node(ceph-deploy、Monitor)、node0(osd.0)、node1(osd.1)。首先要提一下的是,如果再安装过程中出现了问题,需要重新操作的时候,需要清理搭建的这个集群的话,可以使用以下命令:
复制代码
ceph-deploy(admin-node)上执行
清理配置
ceph-deploy purgedata admin node0 node1
ceph-deploy forgetkeys
清理 Ceph 安装包
ceph-deploy purge admin node0 node1
好了,现在开始搭建。首先Cephd用户创建一个目录ceph-cluster并进入到该目录执行如下操作。
\#创建执行目录
复制代码
$ mkdir ~/ceph-cluster && cd ~/ceph-cluster
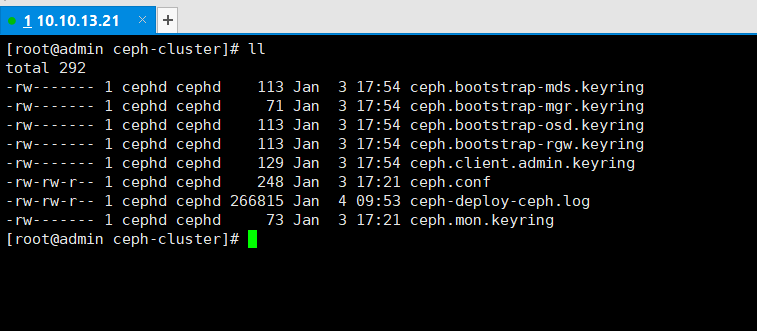
$ ceph-deploy new admin
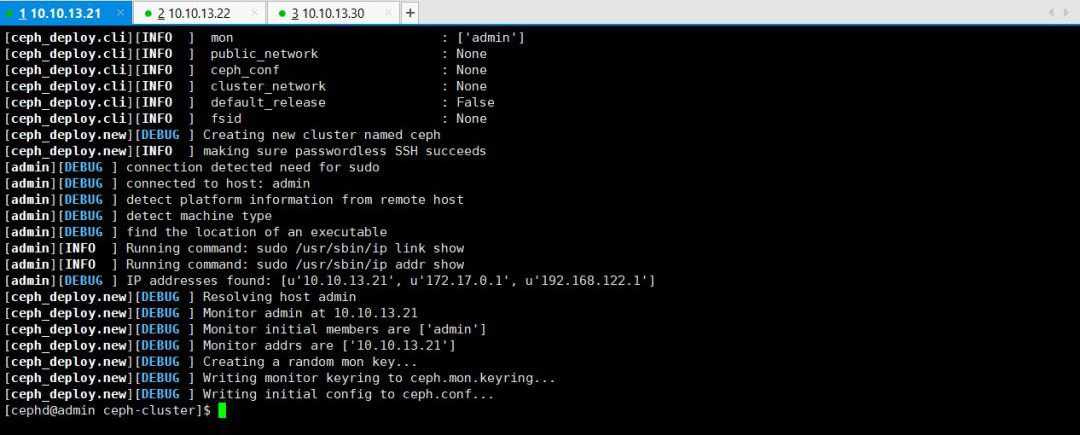
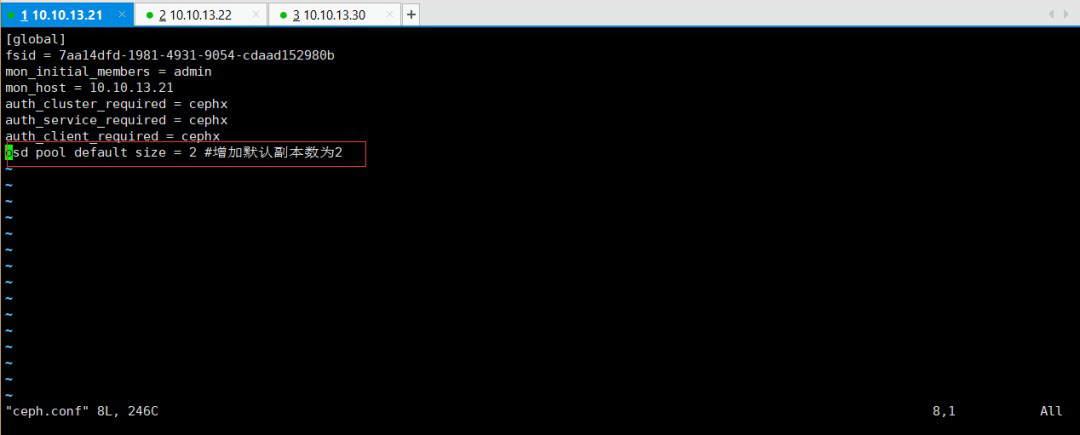
此时,我们会发现ceph-deploy会在ceph-cluster目录下生成几个文件,ceph.conf为ceph配置文件,ceph-deploy-ceph.log为ceph-deploy日志文件,ceph.mon.keyring为ceph monitor的密钥环。
接下来,我们需要修改ceph.conf配置文件,增加副本数为2,因为我们有两个OSD节点。
然后,我们需要通过ceph-deploy在各个节点安装ceph
复制代码
$ ceph-deploy install admin node0 node1
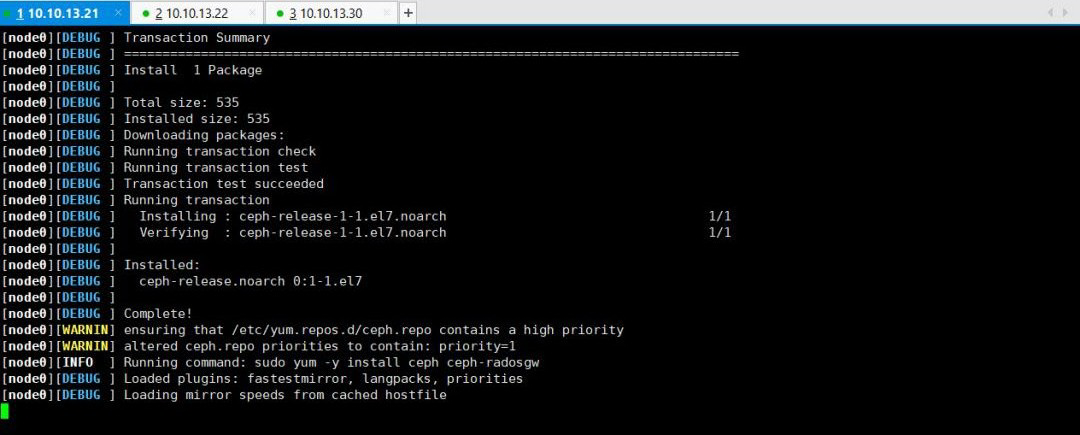
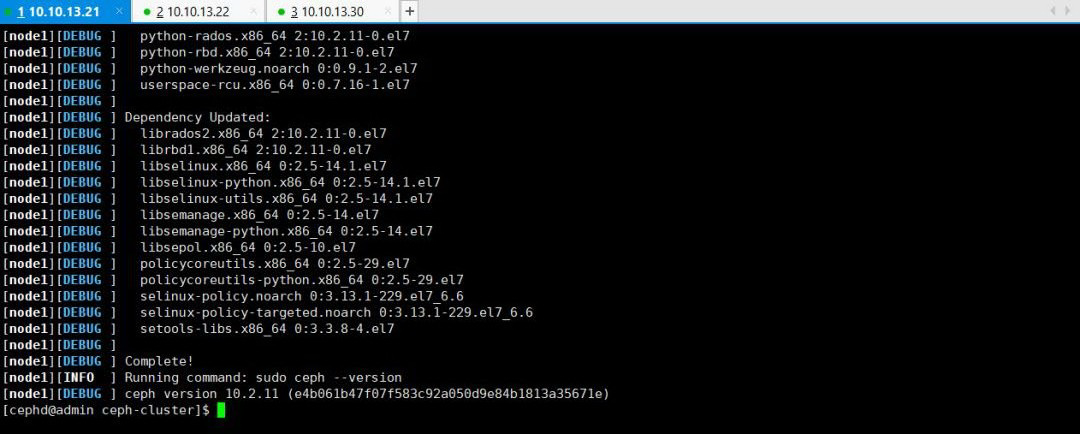
此过程需要等待一段时间,因为ceph-deploy会SSH登录到各node上去,依次执行安装ceph依赖的组件包。
在等待安装完毕之后,接下来需要初始化monitor节点并手机所有密钥。
复制代码
$ ceph-deploy mon create-initial
执行完毕后,会在当前目录下生成一系列的密钥环,应该是各组件之间访问所需要的认证信息。
至此,ceph monitor已经成功启动了。接下来需要创建OSD了,OSD是最终数据存储的地方,这里我们准备了两个OSD节点,分别是osd.0和osd.1。官方建议为OSD及其日志使用独立硬盘或者分区作为存储空间,不过由于条件不具备,所以在本地磁盘上创建目录,来作为OSD的存储空间。
\# ceph-deploy(admin-node)上执行
复制代码
$ ssh node0
$ sudo mkdir /var/local/osd0
$ sudo chown -R ceph:ceph /var/local/osd0
$ exit
$ ssh node1
$ sudo mkdir /var/local/osd1
$ sudo chown -R ceph:ceph /var/local/osd1
$ exit
注意:执行chown -R ceph:ceph操作,是将osd0和osd1目录的权限赋予ceph:ceph,否则,接下来执行ceph-deploy osd activate时会出现权限报错。
接下来,需要ceph-deploy节点执行prepare OSD操作,目的时分别在各个OSD节点上创建一些后边激活OSD需要的信息。
复制代码
$ ceph-deploy osd prepare node0:/var/local/osd0 node1:/var/local/osd1

接下来需要激活 activate OSD.
复制代码
$ ceph-deploy osd activate node0:/var/local/osd0 node1:/var/local/osd1
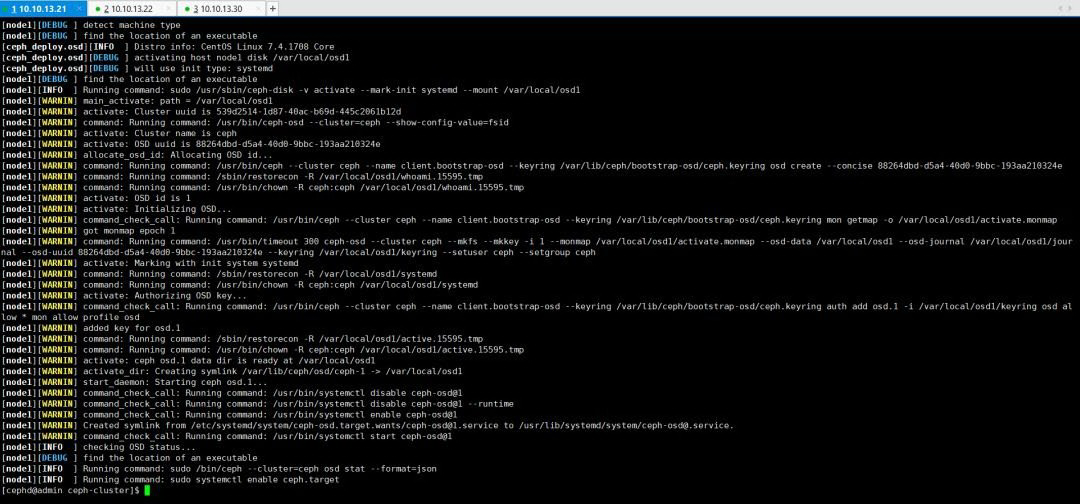
最后一步,通过ceph-deploy admin将配置文件和admin密钥同步到各个节点,以便在各个node上使用ceph命令时,无需指定monitor地址和ceph.client.admin.keyring密钥。
复制代码
$ ceph-deploy admin admin node0 node1
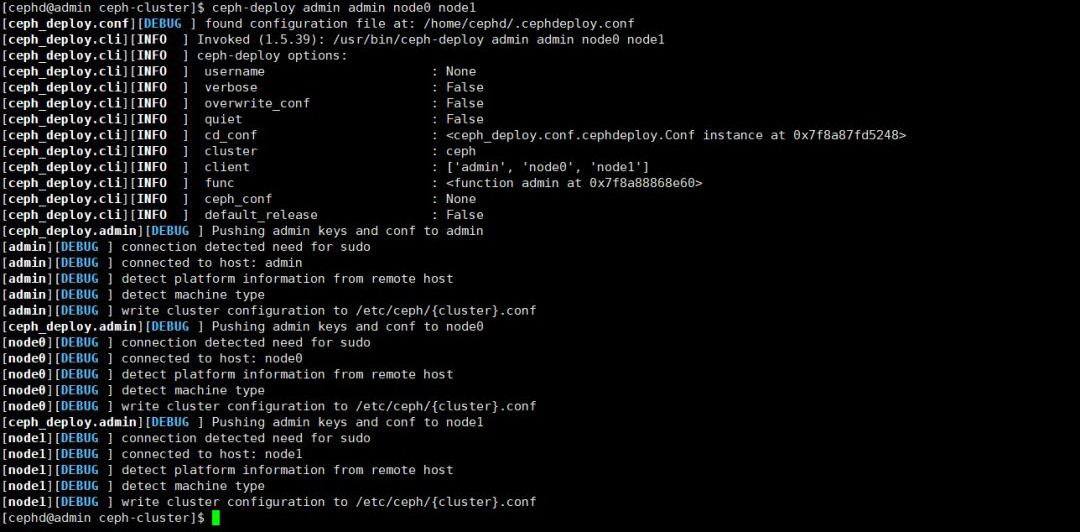
至此,Ceph存储集群已经搭建完毕了。可以查看以下集群是否启动成功。
\# 查看集群状态
复制代码
$ ceph -s

\# 查看集群健康状况
复制代码
$ ceph health
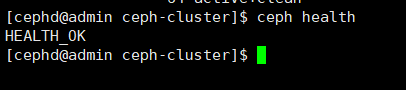
\# 查看集群OSD信息
复制代码
$ ceph osd tree
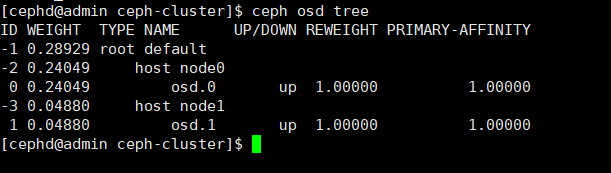
通过上述的检查,目前ceph集群已经安装部署完成,并且能够正常运行。
### 6、CephFS文件系统创建
在部署完成ceph集群以后,需要创建CephFS文件系统。具体执行如下:
复制代码
在 admin-node(ceph-deploy) 节点操作
创建 MDS 元数据服务器
$ ceph-deploy mds create admin node0 node1
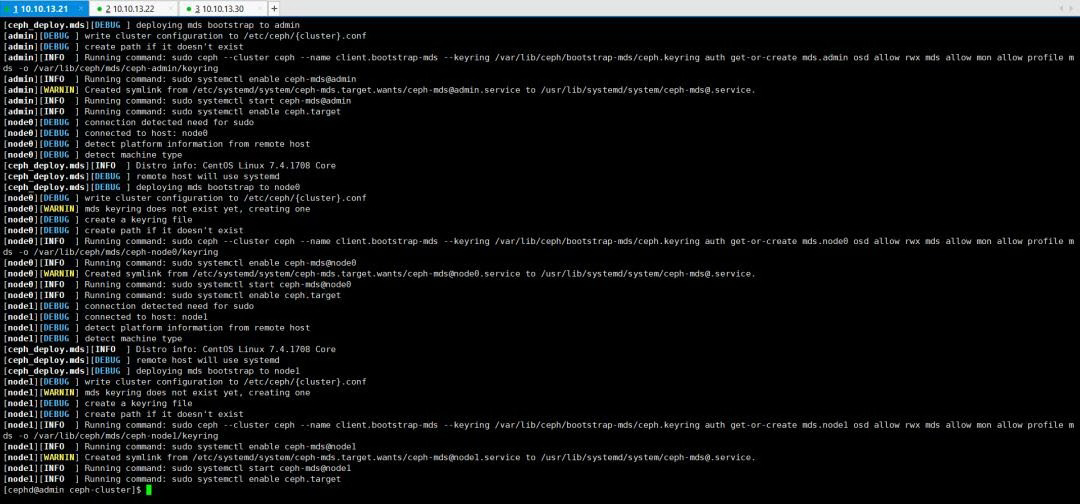
复制代码
查看 MDS 状态
$ ceph mds stat

复制代码
创建 cephFS
$ ceph osd pool create cephfs_data 128
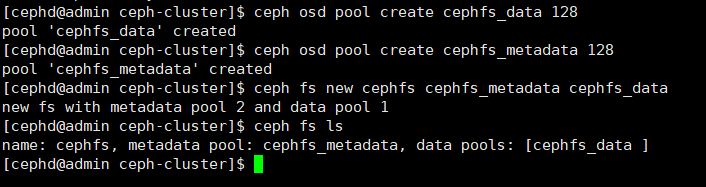
复制代码
挂载 cephFS
$ sudo mount -t ceph 10.10.13.21:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/admin.secret
$ df -h

接下来,将开始后续的Harbor部署已经相关数据库的迁移等。
## 数据库迁移
根据总体技术架构,单独设置一台服务器作为Mysql数据库进行独立提供数据库服务。由于Harbor本身提供数据库服务,尤其采用高可用的话,多实例Harbor之间无法实现数据共享,因此需要独立部署一个数据库服务器,让所有Harbor实例都统一指定访问这一个数据库系统,维护同一套数据,从而保证了数据的一致性。
### 1、Mariadb数据库部署
根据文献【4】通过yum方式直接在线部署Mariadb,由于MySQL已经被Mairadb所取代,所以本例直接安装的Mariadb,具体安装过程在此不再赘述,只是针对版本问题尤其需要提醒各位。由于后期数据库迁移过程中,Harbor的数据库采用的是10.2的版本,而系统默认安装Mariadb版本是5.5。因此两者相差较大,在直接进行数据库迁移时会出现很多字段对不上,从而导致数据库迁移失败。因此还是需要保证软件版本的一致性。
根据参考文献【4】,数据库成功部署,如下图所示:
在成功部署数据库以后,需要启动Mysql服务,执行如下执行:
复制代码
$ sudo systemctl start mariadb
### 2、迁移db数据
在迁移Harbor的db数据需要按照单节点的方式首先启动Harbor,具体的过程在此不再赘述。
经过启动单节点Harbor服务时,已经有一部分数据存储到harbor-db数据里面去了,而且Harbor启动时也会创建好所需要的数据库、表和数据等。这里我们只需要进入Harbor-db容器中,将registry数据库dump一份,然后Copy到当前节点机器上。
\# 进入harbor-db容器
复制代码
$ docker exec -it <harbor-db 容器 ID> bash
\# 备份数据到默认目录/tmp/registry.dump
复制代码
$ mysqldump -u -root -p registry > registry.dump
Enter password: XXXXX
$ exit
$ docker cp <harbor-db 容器 ID>:/tmp/registry.dump /home/cephd/harbor/
挑选一台安装好mysql-client,直接连接外部数据库操作。执行以下指令:
复制代码
$ mysql -h 10.10.13.31 -P 3306 -u root -p <db_password>
通过root用户方式访问数据库,为了方便后续操作,创建一个专门的账户harbor,并赋予所有操作权限。执行以下Mysql指令:
复制代码
mysql> CREATE USER ‘harbor’@’%’ IDENTIFIED BY ‘XXXXXX’;
mysql> GRANT ALL ON . TO ‘harbor’@’%’;
mysql> FLUSH PRIVILEGES;
接下来便是通过harbor账户登录到数据库,创建数据库registry,并导入dump数据。
复制代码
$ mysql -h 10.10.13.31 -P 3306 -u harbor -pXXXXX
mysql> CREATE DATABASE IF NOT EXISTS registry default charset utf8 COLLATE utf8_general_ci;
mysql> USE registry;
Database changed
mysql> source /home/cephd/harbor/registry.dump;
经过上述指令执行,就已经成功将外部数据库搞定了。剩下的工作就是对Harbor组件进行配置,从而使得Harbor在访问数据库时自动连接外部数据库。
### 3、修改配置使用外部db
首先,既然我们已经有外部数据库了,那么就不需要Harbor再启动harbor-db服务了,只需要配置连接外部数据即可。因此就需要删除docker-compose.yml中mysql相关配置。如下图所示:
复制代码
删除以下 mysql 配置
mysql:
image: vmware/harbor-db:v1.5.3
container_name: harbor-db
restart: always
volumes:
- /data/database:/var/lib/mysql:z
networks:
- harbor
env_file:
- ./common/config/db/env
depends_on:
- log
logging:
driver: “syslog”
options:
syslog-address: “tcp://127.0.0.1:1514”
tag: “mysql”
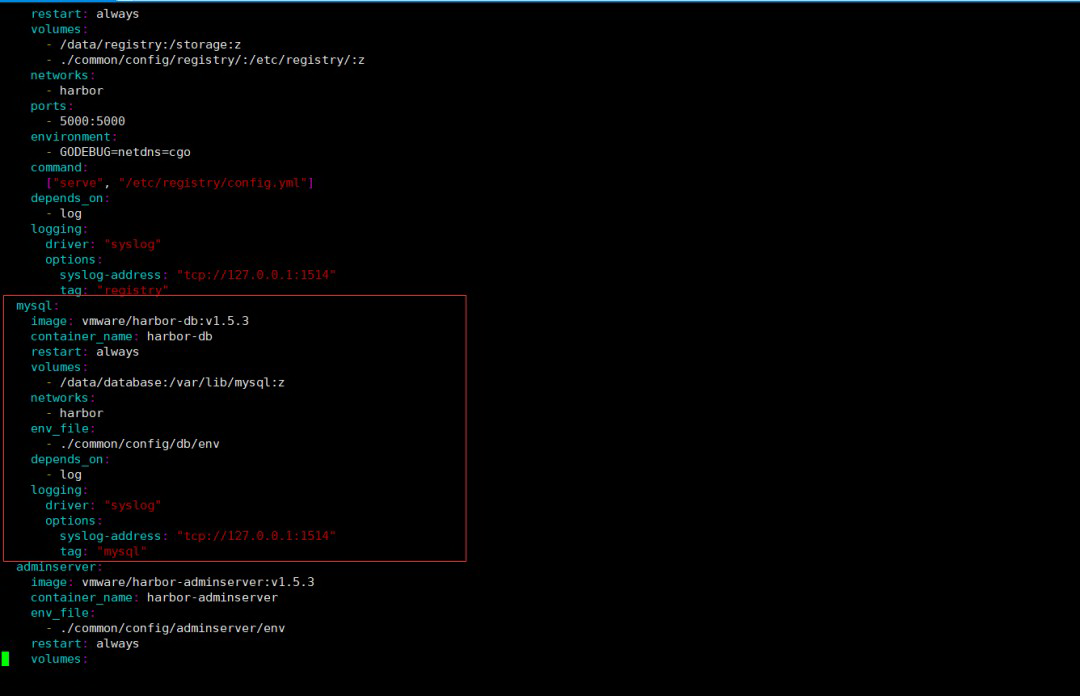
\# 删除depends_on中mysql部分
复制代码
depends_on:
# - mysql # 此处删除
- registry
- ui
- log

其次,还需要修改./common/config/adminserver/env配置,这里面主要存放的是一些配置信息,里面就有配置Mysql的连接信息。因为该文件是执行install.sh的时候根据./common/templates/adminserver/env配置生成的,所以即使我们修改了,也是一次性的,重新install又会覆盖掉,所以可以直接修改./common/templates/adminserver/env该文件就一劳永逸了。
复制代码
修改 ./common/templates/adminserver/env 文件
……
MYSQL_HOST=10.10.13.31
MYSQL_PORT=3306
MYSQL_USR=harbor
MYSQL_PWD=XXXXXX
MYSQL_DATABASE=registry
……
RESET=true
注意:这里一定要设置RESET=true因为只有设置了该开关,Harbor才会在启动时覆盖默认配置,启用我们配置的信息。
再次启动Harbor服务,看一下能否启动成功,能否正常连接配置的外部数据库。
\# 重启 Harbor 服务
复制代码
$ ./install.sh
\# 查看 Harbor 各组件容器启动状态,harbor-db服务已经删除

\# 查看UI和jobservice日志,是否连接上Mysql
复制代码
查看 UI 和 jobservice 日志,是否连接上 Mysql
$ cat /mnt/cephfs/harbor/log/ui.log | grep database

通过日志发现,Harbor已经成功启动了,并且harbor-db服务组件按照设计也没有启动,日志显示连接外部数据库也没有问题,通过浏览http://10.10.13.21(harbor部署节点)看一下之前操作的数据是否能够正常显示出来。http://10.10.13.21(harbor部署节点)看一下之前操作的数据是否能够正常显示出来。
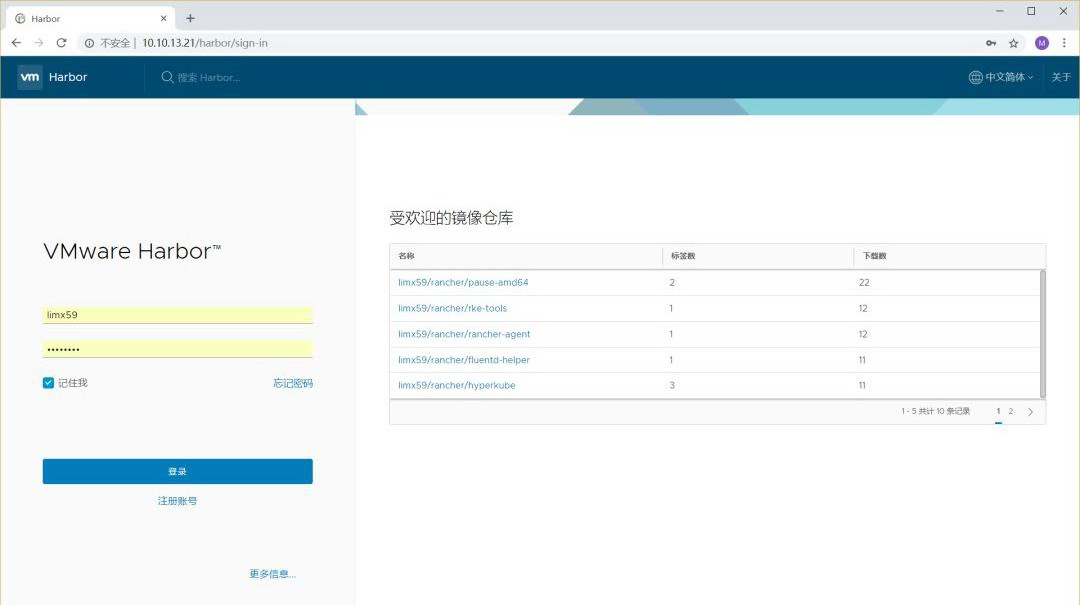
发现之前创建的帐号和导入的镜像数据都可以访问。说明原先在harbor-db服务中创建的数据库和相关账户信息等内容都已经成功迁移到外部数据库中,并且启动的Harbor服务能够正常访问外部数据库。那么多节点的Harbor集群都是按照此方法创建harbor服务,并且将Harbor服务连接和访问统一的外部数据库从而维持一套统一的数据库操作,在此不再赘述。剩下的工作就是针对多节点的Harbor服务如何实现通过以的IP地址访问,在此通过Nginx方式来实现负载均衡访问。
## Nginx负载均衡
为了保持原有的Rancher容器集群在访问原有的单节点Harbor配置不用改变,我们将原先的Harbor单节点服务器10.10.13.1作为Nginx服务器,这样通过Nginx进行访问分发到之前创建的3台Harbor服务器上,这样原有的Rancher容器集群访问地址就不需要进行修改了。
为了快速安装Nginx,我们根据参考文献【2】采用Docker方式启动Nginx服务。首先创建配置文件,当Nginx服务启动时,就可以根据配置文件进行负载均衡。
复制代码
创建 default.conf 配置文件
$ mkdir /root/nginx
$ vim default.conf
upstream service_harbor {
server 10.10.13.21;
server 10.10.13.22;
server 10.10.13.30;
ip_hash;
}
server {
listen 80;
server_name 10.10.13.1;
index index.html index.htm;
#access_log /var/log/nginx/host.acces.log main;
location / { add_header Access-Control-Allow-Orgin *; proxy_next_upstream http_502 http_504 error timeout invalid_header; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_pass http://10.10.13.1; client_max_body_size 1024m #设置接口客户端body最大长度为1024M }
access_log /var/log/harbor.access.log; error_log /var/harbor.error.log;
error_page 404 /404.html;
error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; }
复制代码
}
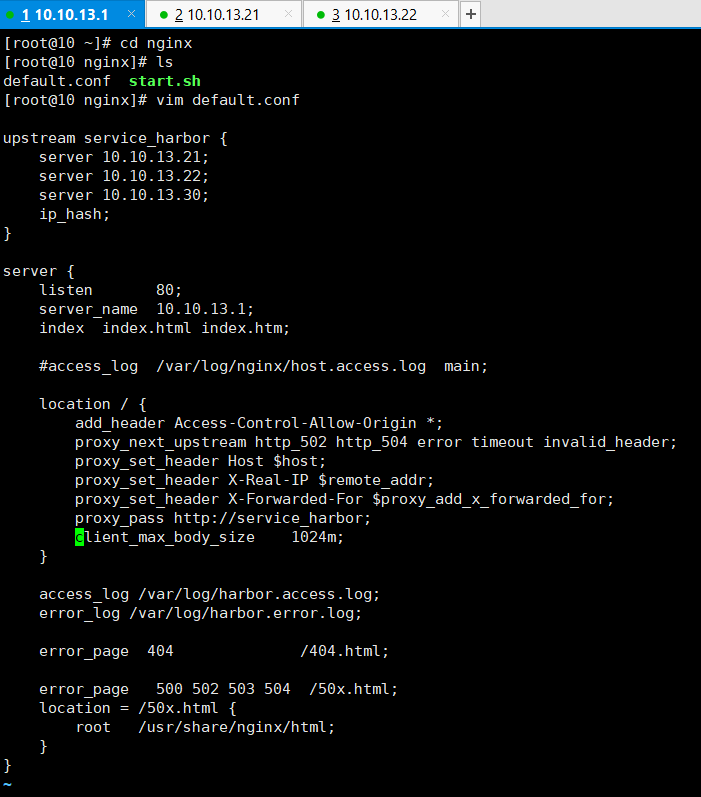
\# Docker 启动 Nginx服务, 挂载上边配置文件覆盖默认配置,并开放80端口
复制代码
$ docker run --name nginx-harbor -p 80:80 -v /root/nginx/default.conf:ro -d nginx
通过浏览器访问Nginx地址 http://10.10.13.1 能否能够访问Harbor UI。
至此,已经创建完成了基于Ceph的高可用Harbor部署。目前的基础资源可以使用一段时间了。不过还需要有几点还需要继续改进的地方。
* Mysql数据库可以通过分部署方式提供服务。比如可以通过基于容器平台的Mysql主从、PXE等方式部署Mysql分布式集群,由底层容器平台提供数据库服务;* HA高可用部署还可以参数调优的方式,可以进一步提高负载均衡性能;* 底层CephFS文件系统还可以持续进行HA高可用。从现有的Ceph进行承载发现在数据访问等方便确实比原先的单节点Harbor要慢一些。
### 1、基于容器平台提供Mysql服务
由于目前主流的容器平台包括:DC/OS、Kubernetes等都可以提供Mysql分部署服务能力,包括PXE、主从服务等都具备高可用的解决方案。具体解决方案已经开源。具体可以参考以下链接:
* Mysql的多主模式(PXE)
<https://github.com/limx59/percona-xtradb-cluster>
* Mysql的主从模式
<https://github.com/limx59/mysql>
其技术架构可以参考如下:
剩下来研究Rancher平台(容器云平台)直接挂载Cephfs实现底层存储,对上提供Mysql服务,以便供Harbor进行独立数据库的访问。
上述代码已经上传到Github上,大家可以根据自己需要自行下载,具体链接如下:
<https://github.com/limx59?tab=repositories>
## 参考文献
【1】基于Harbor和Cephfs搭建高可用Docker镜像仓库集群:
<https://blog.csdn.net/aixiaoyang168/article/details/78909038>
【2】Ceph介绍及原理架构分享:
<https://www.jianshu.com/p/cc3ece850433>
【3】初试Centos7上Ceph存储集群搭建:
<https://blog.csdn.net/aixiaoyang168/article/details/78788703>
【4】Mariadb数据库的部署及管理:
<https://blog.csdn.net/weixin_40658000/article/details/78595631>
复制代码
















评论