

北京时间 8 月 7 日,TensorFlow 官方在 Medium 博客上更新了一篇文章,宣布为模型优化工具包添加了一项新功能:半精度浮点量化工具,据介绍,该工具能够在几乎不损失精度的情况下,将训练模型缩小一半,还能改善 CPU 和硬件加速器延迟。
TensorFlow 团队将训练后的半精度浮点量化作为模型优化工具包的一部分,这一套工具包括了混合量化,全整数量化和修剪等功能。
通过牺牲极少的精度,训练后的半精度浮点量化成功缩小了 TensorFlow Lite 模型的尺寸(高达 50%),并将模型常数(如权重和偏差值)从全精度浮点(32 位)为精度降低的浮点数据类型(IEEE FP16)。
训练后的半精度浮点是训练 TensorFlow Lite 模型的好工具,因为它对精度的影响极小并且模型尺寸显着减小。
感兴趣的读者可以点击这里查看相关文档,以便解不同的量化选项和方案。

降低精度的好处
降低精度有很多好处,特别是在部署到边缘时:
模型尺寸减少 2 倍。模型中的所有常量值都存储在 16 位浮点数而不是 32 位浮点数中。由于这些常数值通常在整个模型尺寸中占主导地位,因此通常会将模型的尺寸减小约一半。
精确度损失可忽略不计。深度学习模型经常能够在推理上产生良好的结果,同时使用比最初训练时更少的精度。在对几个模型的实验中,研发人员发现推理质量几乎没有损失(见下面的结果)。
尺寸缩小 2 倍,精度折衷可忽略不计
训练后的半精度浮点量化对精度的影响很小,但可以使深度学习模型的大小缩小约 2 倍。例如,以下是 MobileNet V1 和 V2 型号以及 MobileNet SSD 型号的一些结果。MobileNet v1 和 v2 的准确度结果基于ImageNet图像识别任务。在COCO对象识别任务上评估 SSD 模型。
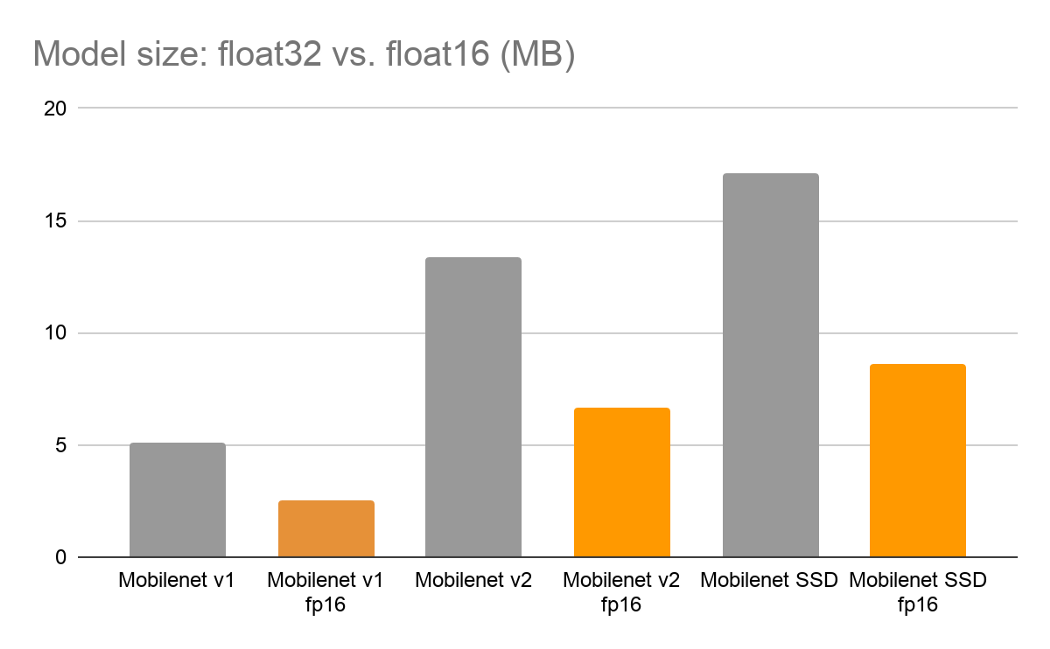
模型准确性
通过将标准 Mobilenet float32 模型和 fp16 变体分别在:ILSVRC 2012 图像分类任务,以及 COCO 对象检测任务上进行了评估,研发人员得到了如下的结果:
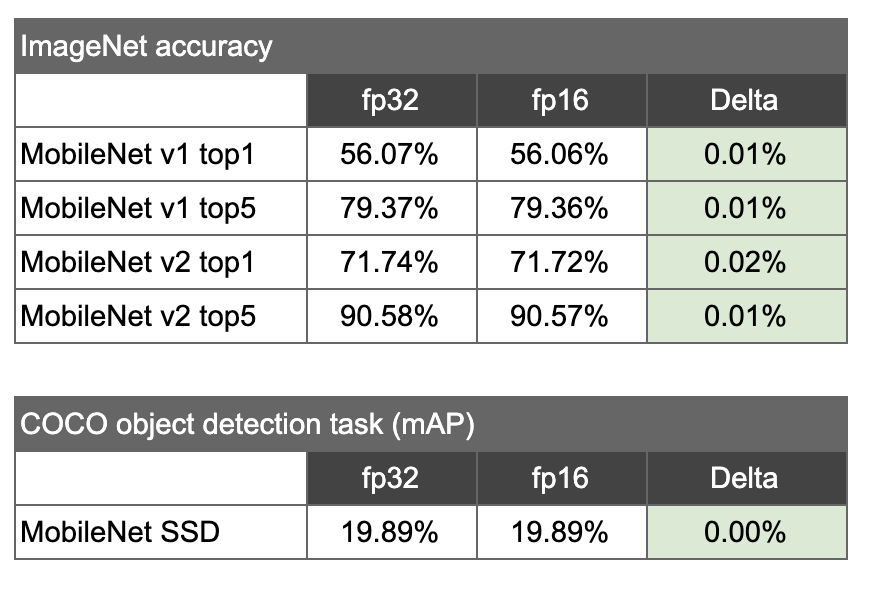
如何启用后训练半精度浮点量化
开发者可以在 TensorFlow Lite 转换器上指定训练后的半精度浮点量化,方法是使用训练好的 float32 模型,将优化设置为 DEFAULT,并将目标规范支持的类型设置为半精度浮点常量:
转换模型后即可直接运行,就像任何其他 TensorFlow Lite 模型一样。默认情况下,模型将通过将 16 位参数“上采样”为 32 位,然后在标准 32 位浮点运算中执行操作来在 CPU 上运行。
开发者还可以在 GPU 上运行模型。研发团队已经增强了 TensorFlow Lite GPU 代理,以接收精简参数并直接运行(不需要像在 CPU 上那样转换为 float32)。在应用程序中,开发者可以通过 TfLiteGpuDelegateCreate 功能创建GPU代理。指定代理的选项时,请务必设置 precision_loss_allowed 为 1:
有关 GPU 代理的概述,请参阅此链接:
查看使用半精度浮点量化的工作示例请点这里:

InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论