

互动直播、线上会议、在线医疗和在线教育是实时音视频技术应用的重要场景,而这些场景对高可用、高可靠、低延时有着苛刻的要求,很多团队在音视频产品开发过程中会遇到各种各样的问题。例如:流畅性,如果在视频过程中频繁卡顿,基本上就很难有良好的互动;回声消除,经过环境反射被麦克风重新采集并传输,这也会影响互动效果;国内外互通,越来越多的产品选择出海,海内外互通也是技术上需要解决的点;海量并发,这对音视频产品的抗压能力而言是很大的挑战。
5 月 29 日,在 「QCon 北京全球软件开发大会」上,由声网 Agora 技术 VP 冯越作为专题出品人发起的「实时音视频专场」,邀请到了来自新东方、伴鱼英语、声网 Agora 的技术专家,与大家分享了下一代视频引擎架构、大规模实施音视频系统的难点与跳转、语音测评及本地化实践、前端音视频播放器的研究与实践等话题。
1 声网下一代视频引擎架构探索
随着音视频技术快速发展,音视频实时互动在多个领域(社交娱乐、在线直播、医疗等)中都得到了广泛的应用。同时伴随着 AI 技术在图象处理中的快速发展,融合了 AI 算法的高级视频前处理功能也得到了越来越多的应用。场景的丰富多变对下一代视频灵活可扩展功能提出了很高的要求。
声网 Agora 负责下一代视频引擎架构设计的架构师李雅琪首先为大家带来了关于《声网下一代视频引擎架构探索与实践》的分享。

为了能更好地满足对于视频体验的场景丰富性、用户差异性以及对直播体验的需求,声网将下一代视频处理引擎设计原则和目标总结为以下四个方面:
1、要满足不同的用户对集成的差异化需求;
2、要做到灵活可扩展,可以快速的支撑各种新业务和新技术场景落地;
3、要做到快速可靠,对于视频处理引擎核心系统要提供丰富强大的可能,且能够极大地降低开发人员心智负担。
4、要做到性能优越可监控,要持续优化视频直播处理引擎性能,同时提高监控手段,实现质量数据透明。
针对上述四个设计目标,声网具体采用了哪些软件设计的方法呢?
由于引擎的使用者是天然分层的,一部分使用者要求低代码快速上线,需要引擎尽可能提供贴近他业务的功能的 API;而另外一部分用户,希望引擎可以为他们提供更多的核心视频处理能力,在这之上可以按照自己的需求定制视频处理业务。因此,根据这个用户形态声网也采取了业务组合加核心功能的分层业务设计,High Level API 面向业务提供易用性,Low Level API 提供核心功能和灵活性。为了把灵活编排能力作为视频处理引擎的能力开放给开发者,让开发者可以通过灵活自由的 API 组合,根据不同的业务需求进行灵活编排,声网的视频处理引擎核心架构采用了 Microkernel Architecture 的架构模式,分离了整个引擎的变量和不变量。通过微内核的架构模式实现灵活可扩展的目标: 各个模块功能可以快速扩展,视频处理管线也可以通过搭积木式的组合来实现业务的灵活编排。
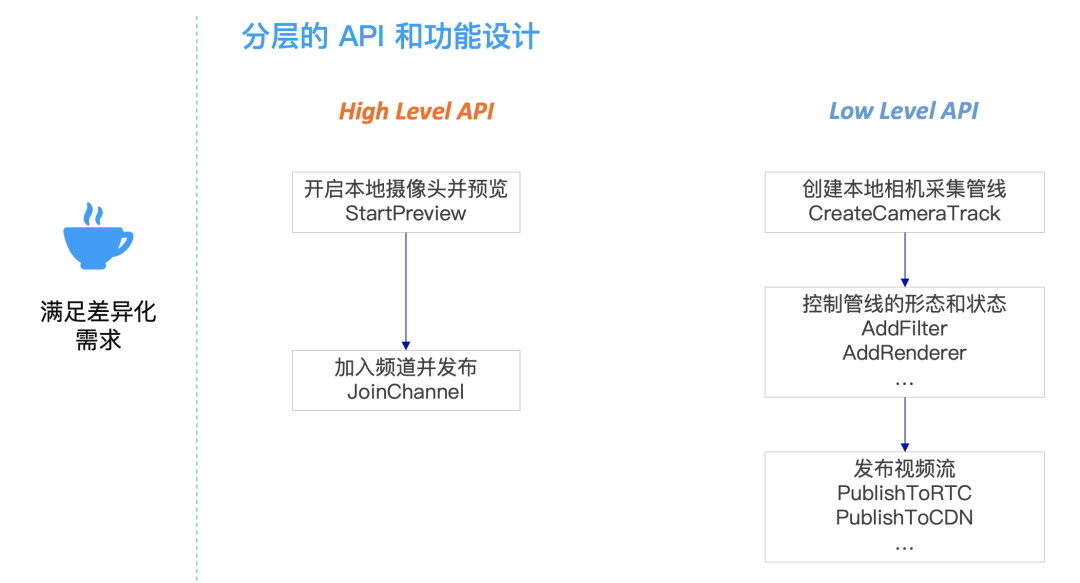
如果我们没有一个稳定可靠的核心系统,一个开发人员要从零开始在视频处理管线上开发一个美颜插件,需要考虑其自身业务逻辑以外的很多问题: 模块的位置、数据格式转换、线程模型、内存管理、属性配置等问题,针对这一系列工程相关的集成问题声网将解决方案固化到底层核心系统当中,为用户提供了丰富强大的基础功能。这套视频引擎核心系统包括了基础视频处理单元、管线搭建和控制、视频基础格式算法支持以及系统基础设施等功能。有了这个核心系统,集成就会变得非常简单,插件只要按照核心系统接口协议约定,实现相关的封装接口就可以了。丰富强大的核心系统功能极大地降低了模块开发者的心智负担,从而帮助开发者提升整体的研发效能。
在性能优越可监控部分,声网优化了移动端数据处理链路,分离了控制面和数据面,提升了整体数据视频的传输效率。另外还构建了视频处理特性相关的内存池来降低系统资源消耗。最终实现了全链路视频质量监控机制,使视频优化性能达到闭环反馈的效果。
2 自研大规模实时音视频系统的难点与挑战
来自声网 Agora 的行业架构师董海冰作为 RTC 领域的长期深耕者在大会中为大家普及了 RTC 相关的基础概念,同时也详细分析了 RTC 的场景特点以及在自研过程中的架构设计和难点。最后,对于 RTC 未来的发展方向也分享了他自己的看法。
相较于传统互联网应对大规模、高并发已经较为成熟的解决方案:缓存、异步、分布式,实时音视频领域所面临的挑战其实会更为复杂。“实时”要控制在 1 秒以内才能叫做“实时”。比如做缓存,其时间都是秒级别的,或者分钟级别的,很少出现毫秒级别。实时音视频(RTC)在应对大规模、高并发场景时,需要考虑到音视频质量、流畅性、低时延、可伸缩以及可用性等问题,这是做实时音视频和传统互联网很不一样的地方,也意味着其解决方案也会更为复杂。

在开发过程中,用户常见的挑战有开发成本、网络搭建、质量监控、音频处理和最后测试等问题。在分享中,董海冰就举了一个音频自研的例子。首先,音频传输最关键要解决的问题有 3 个:无声 / 声音小、回声、噪声 / 杂音。其次,弱网对抗能力也非常重要,在网络发生变化的时候,怎么通过码率和帧率调整能够缓解变化,同时要解决在智能路由算法里面实现最优路径的选择与传输等问题。另一个挑战就是多维度的质量评估,而且要做到实时化的评估,同时和动态调整形成一个闭环,这样才是最好的方式,能够在弱网对抗里面起到比较好的作用。而对于使用开源服务端的难点,董海冰也对几个常见的方案(Jitsi/Jitsi VideoBridge、Kurento、Licode/Erizo、Pion、Janus)进行了探讨与分享。
除了服务端的开发,实时音视频的运维及质量监控也与传统的互联网方式有些不同。比如在运维方面,除了常见的容灾规划、容器化部署、自动化运维、性能分析及日志系统外,实时音视频中的运维还需要面对全球网络(跨区域、跨运营商)、Lastmile 策略等挑战。
如果用户选择了自研的方式,可能还会面对大规模连麦、RTC 录制 / 回放方案、运营成本的控制等问题。但即便我们需要面对和解决如此多的困难和挑战,不能忽略的是实时音视频技术正在被应用在越来越多的场景下,也拥有着越来越多的可能性。
MetaVerse 译作元宇宙,是近期比较热的一个概念。在现实生活中我们可以把它理解为是一种角色转换,在虚拟世界中是另一种全新体验,实现多种虚拟世界角色的切换。VRCHAT 也是类似的,通过 VR 来做社交或者娱乐,帮助大家进行更好的线上交互,这很可能是未来互联网的发展和探索的方向。董海冰提到,作为自研团队不能闭门造车,要紧跟时代脉搏和行业发展趋势,尽可能把自己的力量投入在自己核心业务和擅长的方面,大家一起把实时音视频这个领域做得更好。
3 新东方云教室 Web 端音视频播放器实践
线上教育应该是近两年大家最为熟悉的实时音视频应用场景之一,此次专场,我们邀请到了来自新东方云教室前端交互架构师李便茹为大家分享新东方是如何实现线下到线上快速迁移的最佳实践。

新东方在 18 年底开始做自己的云教室,2020 年过年期间一个礼拜,做到了从支撑万级的并发跃进到了支撑 30 万并发。
新东方云教室是一套完整的在线上课解决方案,提供 saas 服务,其显著的一个特点就是更新迭代的节奏非常快。如果在端上做原生开发,比如与 PC、Windows、移动端与安卓和 iOS,那么更新迭代一定是赶不上节奏的,因此他们将策略定为客户端内嵌 H5 页面,除实时音视频外,交互功能基本由 H5 实现。Web 适配到各个端,这就是最快的开发模式。
实时音视频(RTC)延时是百毫秒级,最多不会超过 500 毫秒,人耳是基本感知不到的。在线上教育中会有小班课和大班课两种不同的场景。小班课对于低延时的实时互动要求就会比较高,但对于一些大学的课程和讲座,或是名师公开演讲的大班课场景如果用 RTC 的话,成本其实相对就会较高一些了。针对大班课,新东方云课堂采用了 H5 超大班型的方法,支持百万人同时上课,老师端用 RTMP 推流,学生端依然走 HTTP 拉流。
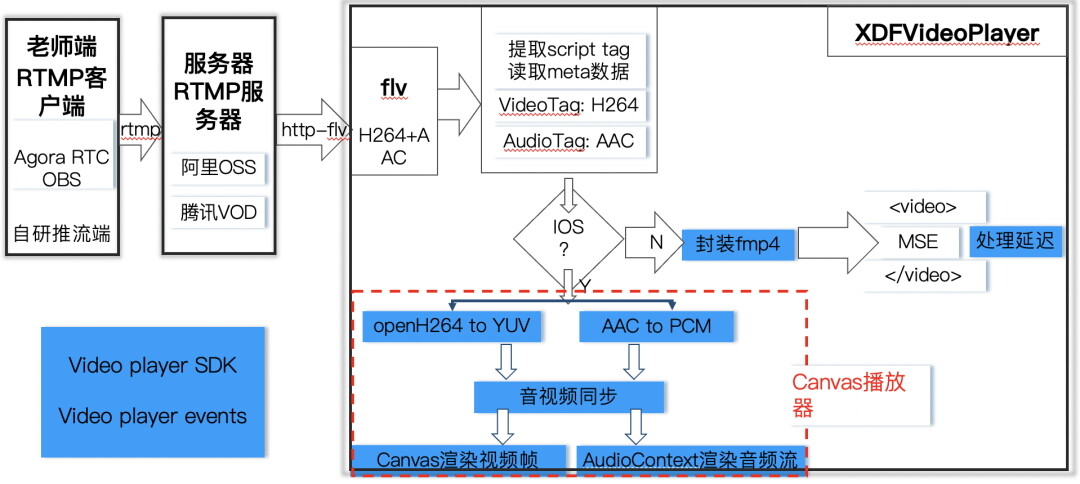
Web 直播播放器架构图
对于未来可扩展部分,如果云教室的视频编码采用 H.265 的标准,那么压缩就会比 H.264 小一半,网络压力就减少了很多。H5 拥有应用范围广泛且支持跨平台的优势,能够实现同一套方案适配不同客户端,快速开发一套产品,就能够快速上线。自研通用播放器可以更改输入源流,定制化或者快开发。
4 语音测评和本地化
为了可以更好地提供教育服务,近两年在线教育平台也结合深度学习实现了许多新的功能,语音测评就是其中一项,尤其在英语教育中少儿口语的测评次数需求量巨大。如何降低测评时延,提升评测服务的体验,同时降低服务器压力和成本?来自伴鱼技术中台 AI 算法负责人黄智超分享了《语音测评和本地化》。

语音评测是通过机器替代人工,为少儿口语发音进行智能打分的一项功能。语音测评在伴鱼的实践,主要包括算法和框架选择、声学模型训练、效果和速度的优化。算法方面,伴鱼选择的是用深度神经网络和隐马儿可夫,主要原因是深度学习框架目前非常成熟。而框架选择是 kaldi,语音界使用人数最多,而且资料齐全。
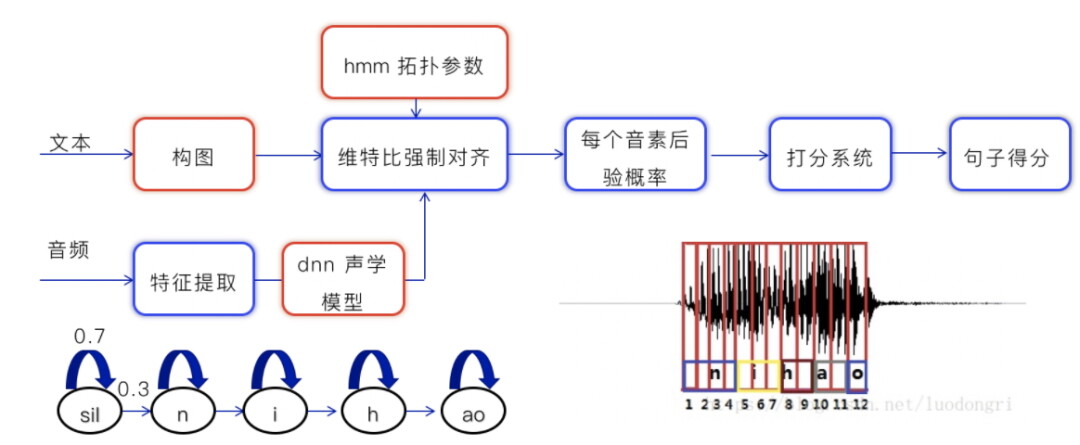
深度神经网络和隐马尔可夫算法 (dnn + hmm) 的测评过程如上图所示。首先要训练一个 dnn 声学模型,训练 hmm 拓扑参数,训练完之后,我们会对输入的文本进行构图,对音频进行特征提取,然后经过声学模型。经过一个打分模型后,得出句子得分。
在这个过程中,数据筛选、声学模型的训练、评测准确率的优化都是关键。黄智超在之后的分享中还详细分享了伴鱼的语音评测在本地化的过程中模型体积优化、测评服务鲁棒性,以及如何解决异常 Case 分析困难等问题与经验。
原文链接:




