

就像生活中所有的美好事物一样,Serverless(无服务器)也有其缺点。
其中一个缺点就是臭名昭著的“冷启动”(Cold Start)。在本文中,我们将介绍“冷启动”是什么,影响 Serverless 启动延迟的因素有哪些,以及如何减轻它们对应用程序的影响。
什么是冷启动?
“冷启动”是指函数服务于特定调用请求时的状态。
Serverless 函数由一个或多个微容器提供。当某个请求传入时,我们的函数将会检查是否已有某个容器正在运行来为该调用提供服务。
当某个空闲容器已经可用时,我们称之为“热”(“warm”)容器。如果没有现成的容器,函数将启动一个新的容器,这就是我们所说的“冷启动”。
当处于“冷态”(Cold State)的函数被调用时,完成请求将需要额外的时间,因为启动新容器会有延迟。这就是冷启动的问题:它们使得应用程序的响应变慢了。在 21 世纪的“即时时代”(instant-age),这可能是一个大问题。
冷启动是怎样工作的?
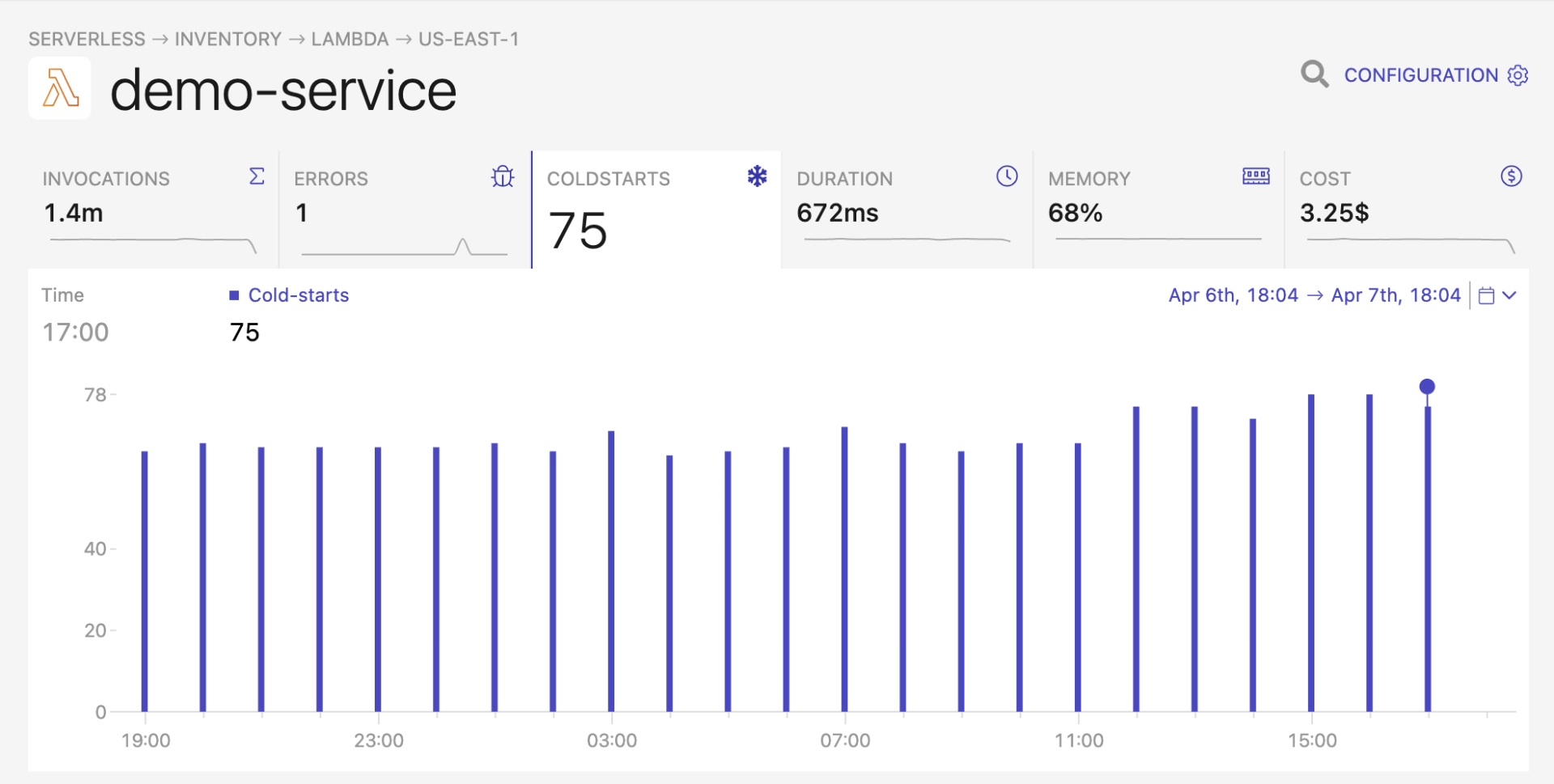
现在,我们已经知道了什么是“冷启动”,那么让我们深入了解一下它们的工作原理。其内部工作原理可能会因你所使用的服务(AWS Lambda、Azure Functions 等)或开源项目(OpenFaas、Kubeless、OpenWhisk 等)的不同而不同,但一般来说,这些原则适用于所有的 Serverless 计算架构。
当请求由某个 Serverless 容器提供服务之后,该容器通常能保持活动状态并允许空闲一段时间。容器编排系统将根据其参数来决定是否关闭以及何时关闭该容器。
这是一种权衡:保持容器处于活动状态将能节省启动资源并加快后续的请求速度,但会增加空闲的时间成本。
AWS Lambda 通常能使容器“保活”(保持活动状态)30-45 分钟。有时还不止这些(特别是对于在 VPC 内运行的 Lambda),但它不是一个文档化或承诺的参数,所以不要盲目地信任它。
当容器从“冷态”开始启动时,函数需要:
从外部持久化存储中获取代码包;
逐步启动(Spin up)容器;
在内存中加载程序包代码;
运行函数的处理程序(handler)方法/函数。
这些步骤需要一段时间才能完成,尤其是第 1 到第 3 步。当容器已经变“热”后,它会直接跳到第 4 步,这样可以节省大量的时间并能使应用程序的响应更快。
启动延迟如何改善?
“冷启动”的影响从几百毫秒到几秒或几十秒不等。导致冷启动延迟的主要因素有:
内存大小:分配给函数的内存越多,启动速度越快;
运行时:与编译运行时(Java、.NET、C#)相比,通常脚本语言(Python、Ruby、Javascript)在启动时的性能要好得多; 我的意思是,速度能提高 100 倍,这是很重要的;
VPC:在虚拟私有云中运行的函数会有额外的延迟,通常要多一到两秒才能启动;尝试着将你的函数设计为运行于 VPC 之外;
代码包大小:包越大,启动新容器所需的时间越长,尽管如此,这可能是影响启动延迟最不重要的因素了。
如何解决或缓解容器的启动延迟?
以下 6 种策略可以解决或至少可以缓解容器启动延迟对 Serverless 应用程序的影响:
监控性能并记录相关指标
增加内存分配
选择更快的运行时
将共享数据保存在内存中
压缩程序包的大小
保留一个预热的函数池
使用时间序列预测
监控性能并记录相关指标
我们讨论了导致容器启动延迟的基础设施因素,但我们的代码也是一个主要因素。我们需要不断地监控应用程序的性能,以便识别性能瓶颈以及导致执行时间增加或减少的原因。
为了做到这一点,建议在函数执行期间始终记录时间戳,并监控函数调用历史记录中的持续时间异常值。 每当它的性能低于预期时,查看日志并确定代码的哪些部分导致了性能的下降。
AWS X-Ray 和 Dashbird 等服务支持这种开箱即用的分析,能为你在性能优化过程中节省大量的时间。 如果你在专业项目的生产环境中运行 Serverless 函数,则必须要使用此类服务。
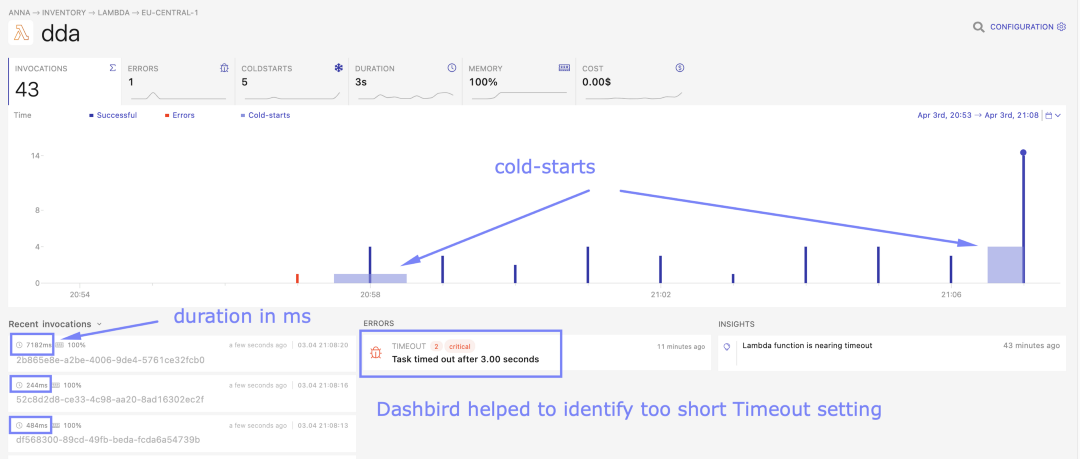
增加内存分配
据观察,分配了更多的内存的函数往往能更快地启动新容器。如果在你的用例中,成本不是问题,那么可以考虑为你的函数分配更多的内存以获得最佳的启动性能。
为对启动时间敏感的工作负载选择更快的运行时
像 Python 和 Ruby 这样的脚本语言比编译后的运行时性能要好得多。Yan Cui 在 AWS Lambda 中对不同语言的启动时间做了一个非常棒的比较。
Python 的性能最好,其启动时间比 Java、C# 和 NodeJS 等竞争者快了 100 倍。只要有可能,请考虑使用轻量级语言(如 Python)编写 Serverless 函数。
尽管 Python 脚本的执行速度较慢(由于它的解释性质),但减少的启动延迟可能能抵消并提供更好的整体性能(以及降低来自云供应商的费用)。
通过在主事件处理函数之外加载来将共享数据保留在内存中
Serverless 函数通常有一个处理程序(Handler)方法/函数作为底层基础设施和代码之间的接口。该函数通常会将一个事件和上下文作为参数传递给我们的函数,然后神奇的事情就发生了。
有趣的是,我们可以在这个方法/函数之外运行代码。假设每次调用我们的函数时,它都需要导入一个相同的三方库,或者可能从外部持久化存储中获取对象。我们可以在调用处理程序方法/函数之前在处理程序外部执行这些操作,而不是在调用处理程序方法/函数之后再执行这些操作。
只要容器保持活动状态,在处理程序之外声明并执行的所有内容都将保留在容器的内存中。当它再次被调用时(从“热”状态),数据的导入或获取将不需要再次运行,可以直接从内存中获取并使用它们,从而加快了代码的执行时间。
这不会加快冷启动,但会减少后续请求的启动时间。总的来说,我们的应用程序将会有更好的性能。
压缩程序包的大小
当我们为 Serverless 函数打包代码时,通常会将所有的东西都放到压缩文件中(从 README 文件到不必要的三方库文件)。
在部署到生产环境之前,清理我们的包是很重要的,删除函数运行时不使用或不需要的所有内容。这将有助于减少内部网络延迟,从而缩短冷启动时间——该函数将获取更小的包文件。
保留一个预热的函数池
如果你仍然无法忍受冷启动的延迟时间,那么最后的办法是设置常规作业来保留一组预热的函数池。工作原理如下:
对函数进行配置,以快速识别短路的预热调用并终止请求,而无需运行整个函数代码。这可以通过向函数传递一个预先确定的事件来实现,例如: {"warm": true}。当函数检测到该事件参数时,只需尽可能快地终止执行。
设置一个常规作业(例如 CRON),每隔几分钟调用一次函数。具体时间视情况而定。AWS Lambda 通常能使容器“保活”(保持活动状态)约 30-45 分钟,但其变化很大。
通过调用该函数,Serverless 底层系统将启动一个新容器并使其“保活”一段时间。如果有一个预热过了的容器,它会因为最近的热调用而保活更长的时间。当真实的用户请求你的 API 时,该容器将能用于更快的响应。
Jeremy Dale 是一个开源且有趣的软件包,可用于帮助管理 AWS Lambda 的“加热策略”(warming strategies),你可以深入了解一下它。Serverless 框架还有一个有用的插件。
注意并发影响:如果你只为你的函数保活了一个容器,但进入了两个并发请求,其中一个将从热态提供服务,但第二个将是冷启动。
这是因为只有一个容器是热的,它一次只能满足一个请求。如果你的应用程序通常服务于多个并发请求,那么你需要在“加热策略”中考虑到这一点。
用时间序列预测预热策略
如果你真的担心冷启动延迟,并且你的应用程序负载在并发请求的数量上显示出很大的差异,那么你可能需要稍微增加一些策略。
你可以使用时间序列预测来预测每个时间点应加热多少个容器。StatsModels 是一个开源项目,它提供了处理时间序列的最常用算法。这里有一个很好的教程可以帮忙你入门。
我们需要的基本上是一个双轴时间序列样本:
特定时间段内的一系列间隔(例如,过去 3 个月内每间隔 10 分钟)
在该时间间隔内,函数处理的最大并发请求数
我们会定期(例如,每 10 分钟)运行一次时间序列预测,以预测在下一个时间间隔(例如,下一个 10 分钟)内需要同时运行多少个容器。调整加热策略以确保预热相应数量的容器。
使用统计预测的一个积极的方面是,它将返回标准差(Standard Deviation,SD)。考虑到数据和 SD 的概率分布,你可以估计预测的置信水平。
假设你希望自己的预测 99% 都是确定的;你需要获取的所需容器预测数量,并将 SD 乘以一个系数。这个系数取决于你的数据分布。例如,如果是正态分布,这个系数将是 2.58。如果你想要更深入得了解这个主题,请阅读更多有关置信区间的内容。
原文链接:
https://hackernoon.com/how-to-solve-the-problem-of-cold-starts-in-serverless-systems

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 1 条评论