

在自然语言处理领域,预训练语言模型在多项 NLP 任务都获得了不错的提升。从 ELMo、GPT、BERT 到 XLNet、RoBERTa,预训练语言模型在 GLUE、SQuAQ 和 RACE 三个榜单频频刷新纪录。最近,微软提出了一种新的预训练语言模型“DeBERTa”。它从两方面改进 BERT 和 RoBEARTa,实验表明,DeBERTa 在许多下游 NLP 任务上表现都优于 RoBERTa 和 BERT。本文是 AI 前线第 109 篇论文导读,我们将对这项研究工作进行详细解读。
概览
Transformer 已经成为神经语言建模中最有效的神经网络结构。与按顺序处理文本的递归神经网络(RNNs)不同,Transformers 应用自关注并行地计算输入文本中的每个单词的注意力权重,该权重衡量每个单词对另一个单词的影响,从而能够实现比 RNNs 更好的并行大规模模型训练。自 2018 年以来,我们看到了一组基于 Transformer 的大规模预训练语言模型(PLMs)的兴起,如 GPT、BERT、RoBERTa、XLNet、UniLM、ELECTRA、T5、ALUM、StructBERT 和 ERINE。这些 PLMs 使用特定于任务的标签进行了微调,并在许多下游自然语言处理(NLP)任务中实现了新的突破。
本文提出了一种新的基于 Transformer 的神经语言模型 DeBERTa(Decoding enhanced BERT with discentanged attention),它被证明比 RoBERTa 和 BERT 作为 PLM 更有效,并且经过微调后,在一系列 NLP 任务中取得了更好的效果。
DeBERTa 对 BERT 模型做了两个修改:
第一,与 BERT 不同,DeBERTa 使用一种分离的注意机制来进行自我注意。在 BERT 中,输入层中的每个单词都是用一个向量表示的,这个向量是单词(内容)嵌入和位置嵌入的总和,而 DeBERTa 中的每个单词都是用两个向量表示的,这两个向量分别对其内容和位置进行编码,并且单词之间的注意力权重是根据单词的位置和内容来计算的内容和相对位置。这是因为观察到一对词的注意力权重不仅取决于它们的内容,而且取决于它们的相对位置。例如,当单词“deep”和“learning”相邻出现时,它们之间的依赖性要比出现在不同句子中时强得多。
第二,DeBERTa 在预训练时增强了 BERT 的输出层。在模型预训练过程中,将 BERT 的输出 Softmax 层替换为一个增强的掩码解码器(EMD)来预测被屏蔽的令牌。这是为了缓解训练前和微调之间的不匹配。在微调时,我们使用一个任务特定的解码器,它将 BERT 输出作为输入并生成任务标签。然而,在预训练时,我们不使用任何特定任务的解码器,而只是通过 Softmax 归一化 BERT 输出(logits)。因此,我们将掩码语言模型(MLM)视为任何微调任务,并添加一个任务特定解码器,该解码器被实现为两层 Transformer 解码器和 Softmax 输出层,用于预训练。
我们将通过一个综合的实证研究表明,这两种技术大大提高了训练前的效率和下游任务的执行。与 RoBERTa Large 相比,使用一半训练数据训练的 DeBERTa 模型在一系列 NLP 任务中的表现都比较好,在 MNLI 上提高了+0.9%(90.2% vs 91.1%),在 SQuAD v2.0 上提高了+2.3%(88.4% vs 90.7%),在 RACE 提高了+3.6%(83.2% vs 86.8%)。
方法
分散注意力机制
对于序列中位置 i 处的令牌,我们使用两个向量{H i}和{P i | j }来表示,这两个向量分别表示在 j 的位置,令牌的内容和其的相对位置。令牌 i 和 j 之间交叉注意力得分的计算可以分解为四个部分,如下所示
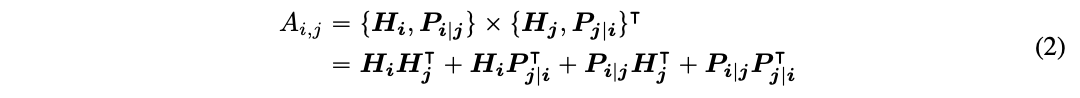
也就是说,一个词对的注意力权重可以计算为四个注意力得分的总和,使用在其内容和位置上的分散矩阵作为内容到内容、内容到位置、位置到内容和位置到位置。
现有的相对位置编码方法[19,21]在计算注意力权重时使用单独的嵌入矩阵来计算相对位置偏差。这相当于仅使用(2)中的内容对内容和内容对位置项计算注意力权重。我们认为,词对的注意力权重不仅取决于词对的内容,而且取决于词对的相对位置,因此词对的位置对内容项也很重要,只有同时使用内容对位置和位置对内容项才能完全建模。由于我们使用了相对位置嵌入,因此位置到位置项不提供太多附加信息,并且在我们的实现中从(2)中移除。
以单头注意为例,标准的自我注意力可以表述为:
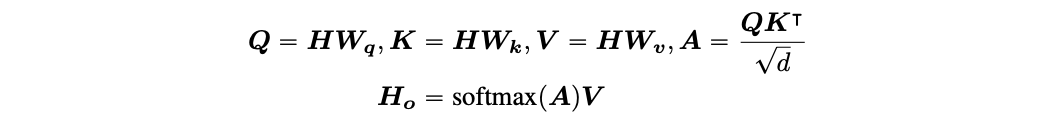
其中,H ∈ R Nxd 表示输入隐藏向量,Ho ∈ R Nxd 表示自我注意的输出,Wq,Wk,Wv ∈R d x d 表示投影矩阵,A ∈ R NxN 表示注意力矩阵,N 表示输入序列的长度,d 表示隐藏状态的维数。
k 表示为最大相对距离,δ (i,j )∈ [0,2k ) 作为从令牌 i 到令牌 j 的相对距离,定义为:
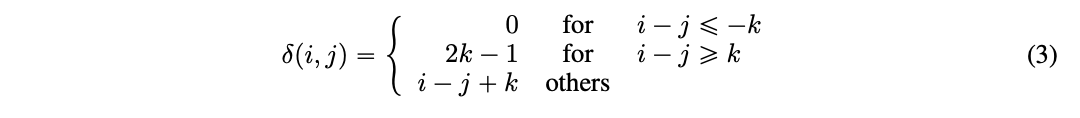
我们可以将具有相对位置偏差的分散自注意力表示为(4),其中 Qc、Kc 和 Vc 分别是使用投影矩阵 Wq,c ,Wk,c,Wv,c ∈ R dxd 生成的投影内容向量,P ∈ R 2k xd 表示跨所有层共享的相对位置嵌入向量(即在正向传播期间保持不变),Qr 和 Kr 分别是使用投影矩阵 Wq,r,Wk,r ∈ R d x d 生成的投影相对位置向量。
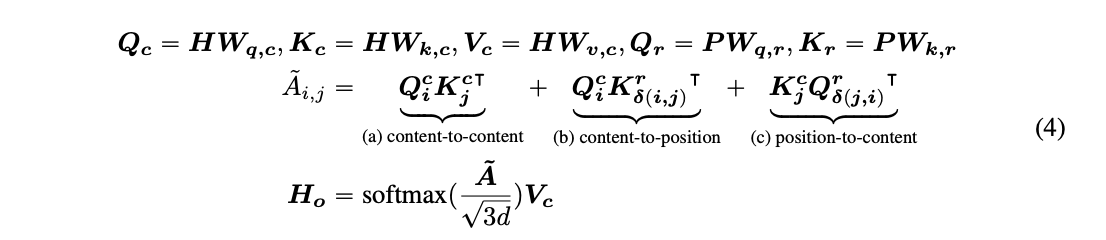
A^i,j 是注意矩阵 A^的元素,表示从令牌 i 到令牌 j 的注意力得分。Qci 是 Qc 的第 i 行。Kcj 是 Kc 的第 j 行。Krδ(i,j)是关于相对距离δ(i,j)的 Kr 的第 i 行的δ(i,j)。Qrδ(j,i)是关于相对距离δ(j,i)的 Qr 的第 i 行δ(j,i)。注意,这里我们使用δ(j,i)而不是δ(i,j)。这是因为对于给定的位置 i,位置到内容计算 j 处的关键内容相对于 i 处的查询位置的注意力权重,因此相对距离是δ(j,i)。位置到内容项计算为 K(c j) Qrδ(j,i) (T)。内容到位置的项以类似的方式计算。
最后,对于稳定模型训练(尤其是对于大型 PLMs)而言,应用一个比例因子 1/√(3d)在 A^上非常重要。
高效实现
对于长度 N 的输入序列,需要 O(N^2d)的空间复杂度来存储每个令牌的相对位置嵌入。然而,以内容到位置为例,我们注意到由于δ(i,j) ∈[0,2k) 以及所有可能的相对位置的嵌入始终是 Kr ∈ R 2k x d 的子集,因此我们可以在所有查询的注意力计算中重用 Kr。
在实验中,我们将训练前的最大相对距离 k 设置为 512。算法 1 可以有效地计算出分散的注意力权重。根据(3)设δ为相对位置矩阵,即δ[i,j]=δ(i,j)。我们没有为每个查询分配不同的相对位置嵌入矩阵,而是将每个查询向量 Qc[i,:]乘以 K T r ∈ R d x2k,如第 3 行 5 所示。然后,我们使用相对位置矩阵δ作为索引来提取注意力权重,如第 6-10 行所示。为了计算内容注意得分的位置,我们通过将每个键向量 Kc[j,:]乘以 Q T r 来计算 A^p->c[:,j],即注意矩阵 A^p->c 的列向量,如第 11 行 13 所示。最后,我们通过相对位置矩阵δ作为索引提取相应的注意力得分,如第 14 行和第 18 行所示。这样,我们不需要分配内存来存储每个查询的相对位置嵌入,从而将空间复杂度降低到 O(kd)(用于存储 Kr 和 Qr)。

增强型掩码解码器
在标准的 BERT 预训练期间,我们通过词汇表将与掩码令牌对应的最终隐藏向量输送给输出 Softmax 层。在微调过程中,我们将 BERT 输出输入到一个特定于任务的解码器中,该解码器具有一个或多个特定任务的解码层,如果输出是概率,则再加上一个 Softmax 层。为了减少预训练和微调之间的不匹配,我们将 MLM 和其他下游任务一样对待,并用包含一个或多个 Transformer 层和一个 Softmax 输出层的增强型掩码解码器(EMD)替换 BERT 的输出 Softmax。这使得结合 BERT 和 EMD 进行预训练的 DeBERTa 成为一个编码器-解码器模型。
为满足多个需求,我们设计了用于预训练的 DeBERTa 模型体系结构。首先,编码器应该比解码器深得多,因为前者用于微调。其次,编解码模型的参数个数需要与 BERT 的参数个数相似,使得预训练耗费与 BERT 相同。第三,DeBERTa 的预训练编码器应该类似于 BERT,这样它们在下游任务上的微调成本和性能是可比较的。
以 12 层 BERT 基模型为基线进行比较。实验中使用的预训练 DeBERTa 结构由 11 层 Transformer 组成的编码器,2 层 Transformer 共享参数的解码器和一个 Softmax 输出层组成。因此,该模型具有与 BERT-base 相似的自由参数。在对 DeBERTa 模型进行预训练后,我们对 11 层编码器和 1 层解码器进行叠加,以恢复标准的 BERT 基结构进行微调。
此外,在将编码器输出向量输入 EMD 进行 MLM 预训练时,我们对其进行了一个虽小但重要的修改。BERT 的作者建议不要用[MASK]令牌替换所有掩码令牌,保持 10%不变。尽管这是为了缓解微调和预训练之间的不匹配,因为在下游任务的输入中从来没有出现过[MASK],但是该方法遭受信息泄漏的影响,即预测以令牌本身为条件的掩码令牌。为了解决这个问题,我们在将这些被掩码但未改变的令牌输入解码器进行预测之前,将它们的编码器输出向量替换为相应的绝对位置嵌入向量。
实验
这一节将对 DeBERTa 在各种 NLP 任务上的表现进行评估。
主要结果
根据之前关于 BERT、RoBERTa 和 XLNet 的论文,我们使用大型和基模型来报告结果。
1 大型模型的性能表现
我们按照 BERT 的设置预训练我们的大型模型,不过我们使用的是 BPE 词汇表。对于训练数据,我们使用 Wikipedia(English Wikipedia dump;12GB)、BookCorpus(6GB)、OPENWEBTEXT(public Reddit content;38GB)和 STORIES(CommonCrawl 的子集;31GB)。重复数据消除后的总数据大小约为 78GB。我们使用 6 台 DGX-2 机器和 96 个 V100 GPU 来训练模型。单个模型训练,batch size 设置为 2K,1M 的 steps,大约需要 20 天的时间。
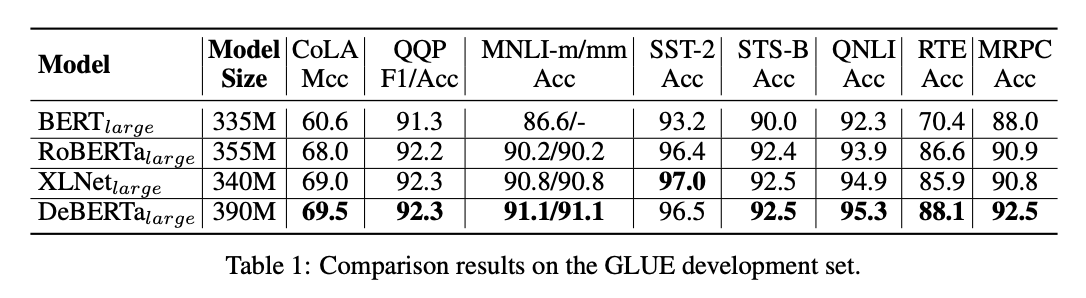
我们在表 1 中总结了 8 个 GLUE 任务的结果,其中比较了 DeBERTa 和以前的模型(参数约为 350M)的 BERT、RoBERTa 和 XLNet。注意,RoBERTa 和 XLNet 使用 160G 训练数据,而 DeBERTa 使用 78G 训练数据。RoBERTa 和 XLNet 被训练了 500K 步,一步 8K 个样本,超过训练样本 40 亿次。我们对 DeBERTa 进行 100 万步的训练,每一步有 2 千个样本。这相当于其训练样本的 20 亿次 pass,约占 RoBERTa 或 XLNet 的一半。
表 1 显示,与 BERT 和 RoBERTa 相比,DeBERTa 在所有任务中始终表现得更好。同时,DeBERTa 在八项任务中有六项优于 XLNet。特别是,MRPC(1.7%超过 XLNet,1.6%超过 RoBERTa)、RTE(2.2%超过 XLNet,1.5%超过 RoBERTa)和 CoLA(0.5%超过 XLNet,1.5%超过 RoBERTa)的改进非常显著。
注意,MNLI 经常被用作一项指示性任务,以监测预训练的进度。DeBERTa 在 MNLI 上的表现明显优于所有现有相同参数量的模型,并打破了一个新的 state-of-the-art(SOTA)。
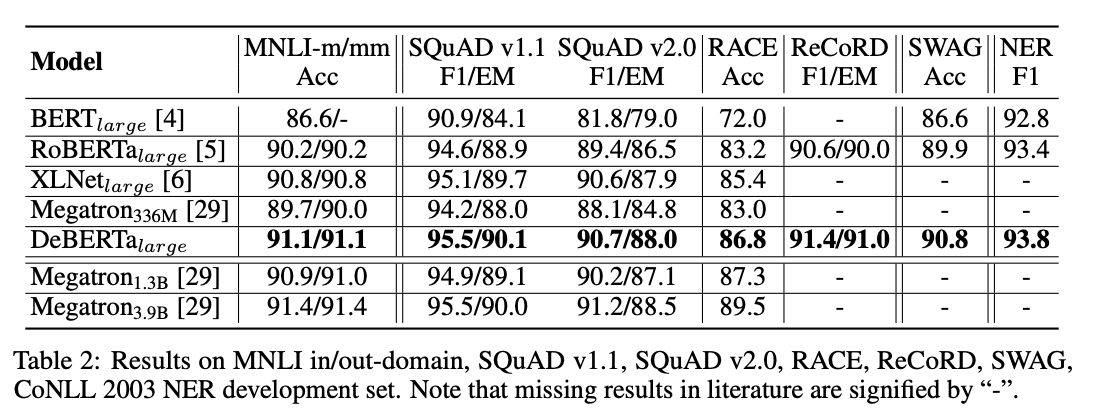
我们根据额外的基准来评估 DeBERTa:(1)问答:SQuAD v1.1、SQuAD v2.0、RACE、ReCoRD 和 SWAG;(2)自然语言推理:MNLI;(3)NER:CoNLL-2003。为了进行比较,我们还将 Megatron 分为三种不同的模型尺寸:Megatron 336M、Megatron 1.3B 和 Megatron 3.9B,它们使用与 RoBERTa 相同的数据集进行训练。请注意,Megatron336M 的模型大小与上述其他模型相似。
我们将结果总结在表 2 中。与之前的 SOTA 模型(包括 BERT、RoBERTa、XLNet 和 Megatron336M)相比,DeBERTa 在这 7 项任务中的表现始终更优。以 RACE 为例,DeBERTa 的性能明显优于之前的 SOTA XLNet,提高了 1.4%(86.8% vs 85.4%)。尽管 Megatron1.3B 是 DeBERTa 的 3 倍大,但我们观察到,DeBERTa 在四个基准中的三个方面仍然可以超过 Megatron1.3B。结果表明,在不同的下游任务中,DeBERTa 算法都具有较好的性能。我们相信,DeBERTa 在更大的模型尺寸下可以表现得更好,未来我们将继续这个方向的研究工作。
2 Base 模型的性能表现
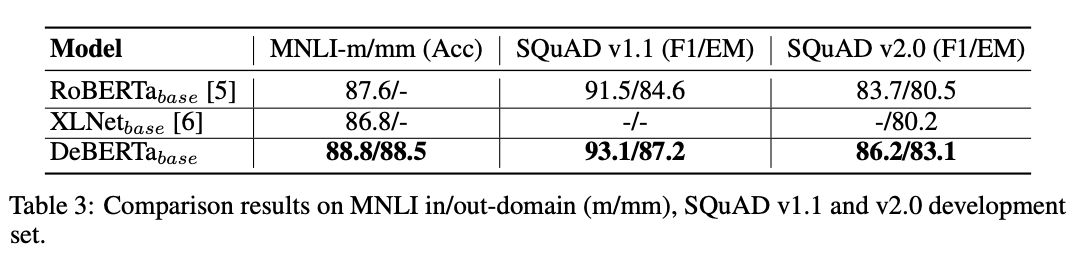
Base 模型预训练的设置与大型模型的设置类似。Base 模型结构遵循 BERT 的 Base 模型结构,即 L=12,H=768,A=12。我们使用带有 64 个 V100 GPU 的 4 个 DGX-2 来训练 Base 模型,batch size 为 2048,step 为 1M,训练 Base 模型大约需要 10 天。我们使用相同的 78G 文本数据训练 DeBERTa,并将其与使用 160G 文本数据训练的 RoBERTa 和 XLNet 进行比较。
我们将结果总结在表 3 中。在这三项任务中,DeBERTa 的表现超越了 RoBERTa 和 XLNet,在大型机型上的改进要比后者更多。例如,在 MNLI-in-domain 设置(MNLI-m)中,DeBERTa base 比 RoBERTa base 获得 1.2%(88.8% vs 87.6%),比 XLNetbase 获得 2%(88.8% vs 86.8%)。
模型分析
在这一节中,我们首先提出了一个消融研究,以量化不同要素在 DeBERTa 中的相对贡献。接下来,对 DeBERTa 和 RoBERTa 在注意力模式上的差异展开说明。最后,我们研究了模型训练效率的收敛性。我们使用基模型设置运行分析实验,其中 Wikipedia+图书语料库数据用于模型预训练,并且模型可以在带有 16 V-100 GPU 的 DGX-2 机器上在 7 天内进行 1 M 步 batch size 为 256 的预训练。
1 消融研究
为了验证我们的实验设置,我们从头开始训练 RoBERTa 基模型。我们称之为重新训练的 RoBERTa RoBERTa-ReImp base。为了研究 DeBERTa 中不同成分的相对贡献,我们设计了三种变体:
EMD 是没有 EMD 的 DeBERTa 基模型。
C2P 是没有等式 4 中的内容定位项(c)的 DeBERTa 基模型。
P2C 是没有位置到内容项(式 4 中的(b))的 DeBERTa 基模型。由于 XLNet 也使用相对位置偏差,该模型接近 XLNet+EMD。
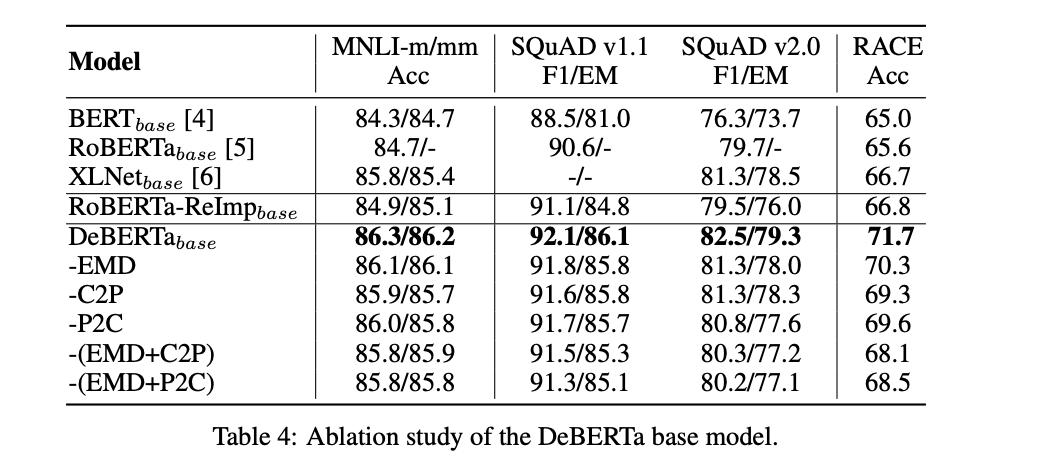
表 4 总结了四个基准数据集的结果。
首先,比较 RoBERTa 和 RoBERTa-ReImp,我们发现它们在所有四个基准数据集上的性能表现相似。因此,我们可以确信的将 RoBERTa-ReImp 作为比较的坚实基线。其次,我们看到删除 DeBERTa 中的任何一个组件都会导致所有基准测试的性能下降。例如,去除 EMD(-EMD)在 SQuAD v2.0 上 分别导致 1.4%(71.7% vs 70.3%)、0.3%(92.1% vs 91.8%)、1.2%(82.5% vs 81.3%)、0.2%(86.3% vs 86.1%)和 0.1%(86.2% vs 86.1%)的损失。类似地,删除内容到位置或位置到内容都会导致所有基准的一致性能下降。正如预期的那样,删除两个组件会导致性能更严重的恶化。
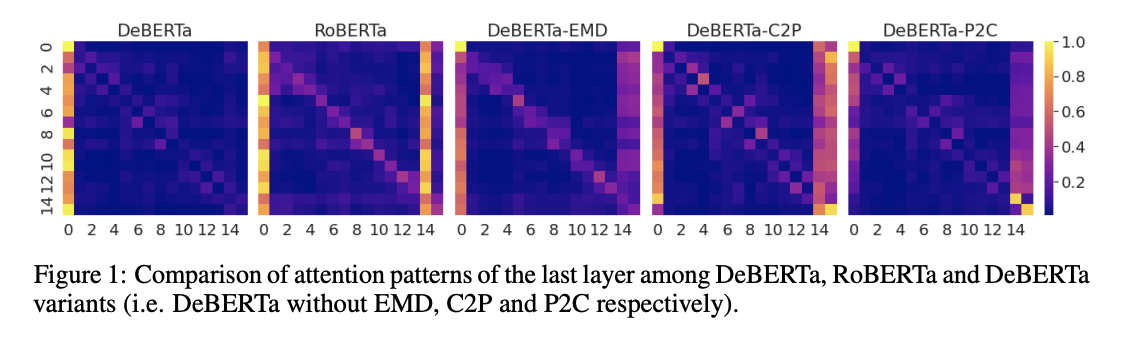
2 注意力机制模式
为了理解为什么 DeBERTa 的表现不同于 RoBERTa,我们在图 1 的最后一个自我注意力层中展示了他们的注意力模式,在这里我们还描述了三个 DeBERTa 变体的注意力模式以进行比较。
比较 RoBERTa 和 DeBERTa,我们发现两个明显的差异。
首先,RoBERTa 有一个清晰的对角线效应,让令牌关注自己,这在 DeBERTa 是没有观察到的。这可以归因于 EMD 的使用,在 EMD 中,被屏蔽但未更改的令牌的向量被其位置嵌入替换。这似乎可以通过检测 DeBERTa-EMD 的注意力模式来验证,其中对角线效应比原始 DeBERTa 要亮。第二,RoBERTa 注意力模式中存在垂直条带,主要是由高频的 functional 令牌(如“a”、“the”或标点符号)引起的。
对于 DeBERTa,条带出现在第一列中,表示[CLS]标记。我们推测,对于一个好的预训练模型来说,对[CLS]标记的重点关注是可取的,因为该标记的向量通常用作下游任务中整个输入序列的上下文表示。我们还观察到,垂直条带效应在三个 DeBERTa 变体的模式中相当明显。
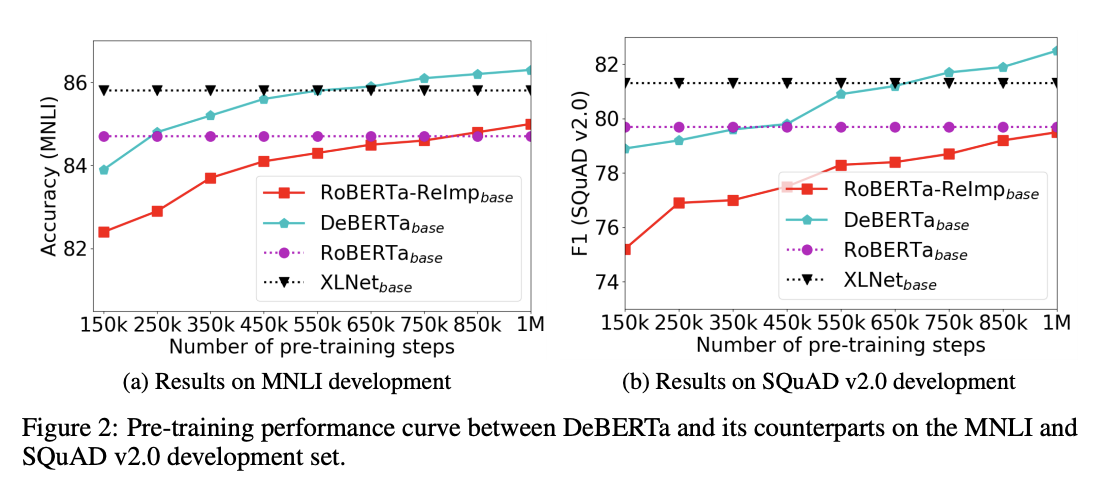
3 预训练模型的有效性
为了研究模型预训练的收敛性,我们将微调后的下游任务的性能绘制为预训练步骤数的函数。如图 2 所示,对于 RoBERTa-ReImp base 模型和 DeBERTa base 模型,我们每 100K 个预训练步骤 dump 一个检查点,然后在两个下游任务(MNLI 和 SQuAD v2.0)上微调检查点,并分别报告准确性和 F1 分数。
作为参考,我们复制了原始 RoBERTa 基模型[5]和 XLNet 基模型[6]的最终模型性能,并将它们绘制为平面点线。结果表明,在预训练的训练过程中,DeBERTa 的表现一直优于 RoBERTa-ReImp,并且收敛速度更快。
结论
本文提出了两种改进 BERT 预训练的方法:第一种方法是分散注意机制,该机制使用两个向量分别对每个单词的内容和位置进行编码来表示每个单词,并使用分散矩阵计算单词之间在内容和相对位置上的注意力权重;第二个方法是一个增强的掩码解码器,它取代了输出的 Softmax 层来预测用于 MLM 预训练的掩码令牌。使用这两种技术,新的预训练语言模型 DeBERTa 在许多下游 NLP 任务上表现都优于 RoBERTa 和 BERT。
这项工作展示了探索自我注意的分散词表示的潜力,以及使用任务特定解码器改进语言模型预训练的潜力。
论文原文链接:
https://arxiv.org/pdf/2006.03654.pdf

InfoQ 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论