

在当今的数字转型时代,应用程序和 Web 服务之间的相互对话是不可避免的,我们需要通过 API 来实现这些应用程序之间的通信。各种协议和规范定义了消息通过网络传递的语义和语法,最终形成了一种 API 架构。
在本文中,我们将探讨如何使用 GraphQL 和 Ballerina 将 MySQL 数据库中的数据作为 API 公开出来。GraphQL 是一种抽象了底层数据源的规范,借助 GraphQL,开发人员能够灵活地使用他们喜欢的编程语言处理数据源,如数据库或 REST API。
GraphQL 是什么
GraphQL 是一种应用层服务器端技术,由 Facebook 于 2012 年开始开发,并于 2015 年公开发布,用于优化 REST API 调用。GraphQL 既可以被视为一种 API 查询语言,也可以被视为一种服务器端运行时,用于执行由用户定义的查询。
GraphQL 的操作类型如下:
查询(读取);
突变(写入/更新);
订阅(连续读取)。
这些操作都只是一个字符串,需要根据 GraphQL 查询语言规范进行构造。GraphQL 对网络层或消息体的格式没有特别要求,不过最常用的一般是 HTTP 和 JSON。
GraphQL 是更好的 REST
在过去的十年中,REST 已经成为一种流行的 API 设计架构。REST 和 GraphQL 可以被认为是解决同一问题(通过 Web 服务访问数据)的两种不同的方法。但是,随着客户端对 API 的访问需求发生了快速变化,REST API 已经变得太不灵活了。推出 GraphQL 的目的是为了支持更灵活、更高效的数据访问行为。下面列出了选择 GraphQL 而不是 REST 的一些关键原因。
避免过度获取或获取不足
过度获取意味着获取的信息超过了你的需要。这在使用 REST 时非常常见,因为它总是从给定的端点返回固定的数据集,而客户端实际上具有特定的数据需求。获取不足意味着特定端点没有提供足够的所需信息,客户端不得不发出额外的请求来获取所需的数据。但在使用 GraphQL 时,你可以使用查询语法定义所需信息的结构,然后通过单个 API 请求就可以获取所需的信息。
客户端可以快速进行产品迭代
通常,REST API 需要根据客户端应用程序需要的视图来提供端点。如果客户端应用程序发生了变化,它需要的数据可能比以前多也可能比以前少。因此,为了满足新的需求,需要调整 REST API。如果使用的是 GraphQL,由于客户端可以指定准确的数据需求,所以只需要在客户端做出更改,服务器端不需要做任何额外的工作。
支持基于模式和类型系统的开发方式
GraphQL 有一个强大的类型系统,可用于定义通过 API 公开出来的数据,所有这些类型都可以使用 GraphQL 模式定义语言(SDL)写到模式中。模式成了客户端和服务器端之间的契约,不同的团队可以基于定义好的模式分别处理前端和后端的代码逻辑。
为什么选择 Ballerina
你可以使用任何流行的编程语言来构建 GraphQL 应用程序,如 Go、Java、Node.js 等。我们选择Ballerina是因为它提供了很多附加价值:
Ballerina 是一种开源的云编程语言,它让网络服务的调用、组合和创建变得更加容易。
它是一种现代的、工业级的、用于集成和开发网络服务和应用程序的通用语言。
由于具有网络感知类型系统、对网络服务和资源的一流支持、对各种技术(包括 GraphQL)的内置支持以及序列图语法等特性,使得开发者体验更加直观。
有两种设计 GraphQL 端点的方法:
模式优先方法:需要使用 GraphQL 模式来创建 GraphQL 服务。
代码优先方法:模式是不必需的,可以直接使用代码编写端点,然后生成模式。
Ballerina 使用代码优先的方法来设计 GraphQL 端点。Ballerina 的 GraphQL 实现使用 HTTP 作为底层协议。在下一节中,我们将探讨这些特性如何帮助你开发 GraphQL 应用程序。
一个书店示例
GraphQL 服务器的数据源可以是任何东西,如数据库、另一个 API 或提供数据的服务等。此外,GraphQL 可以与任意的数据源组合发生交互。这个示例演示了如何使用 Ballerina 实现 GraphQL 服务器,将 MySQL 数据库中的数据以及通过另一个 API 调用获取的数据公开出来。
MySQL 数据库中保存了与书店相关的数据,包括书籍和作者的信息。与书籍相关的其他信息通过Google Books API获得。书店的客户端可以通过 GraphQL API 完成以下这些操作:
获取所有书籍的详细信息;
通过提供书名获取书籍的详细信息;
向数据库中添加新书。
上述操作的信息来源如下:
书名、出版年份、ISBN、作者姓名、作者国籍——从数据库获取;
平均评分和评分计数——通过 ISBN 查询 Google Books API。

这个示例使用 MySQL 数据库和 Google Books API 作为数据源
这个示例的所有源代码都可以在 Github 上找到。
用示例数据填充数据库
首先用示例数据填充 MySQL 数据库。Bookstore 数据库有两张表,“Book”和“Author”,包含以下这些字段。
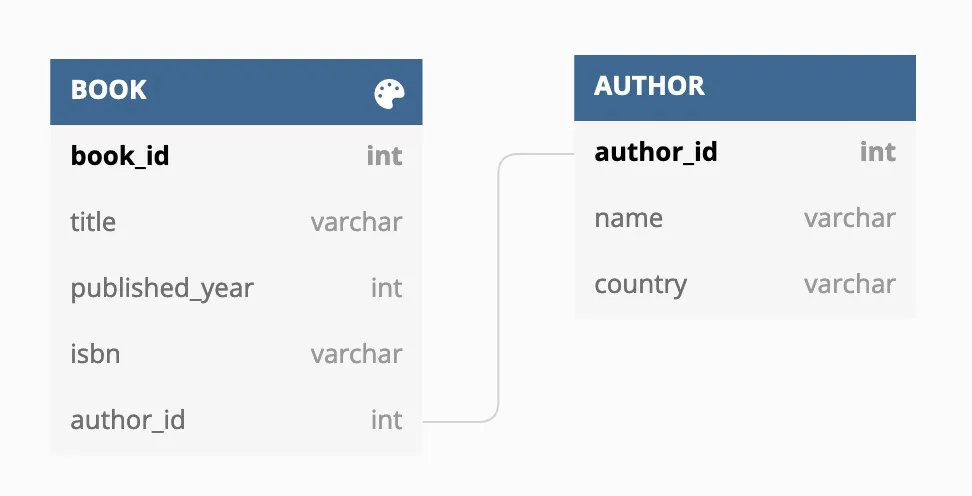
Bookstore 的数据库模式
可以在 data.sql 文件中找到创建数据库、表和填充数据的 SQL 语句。如果将这些语句保存到一个文件中,请在数据库中执行以下命令。
使用 Ballerina 实现 GraphQL 服务
创建 Ballerina 项目
通过执行下面的命令创建一个 Ballerina 项目。有关 Ballerina 项目结构的更多细节,请参考“Organize Ballerina code”。
1 个目录,2 个文件。
因为这是一个服务,不需要 main.bal 文件,所以可以把它删除。
创建记录类型
添加一个叫作“bookservice.bal”的 Ballerina 文件,用于实现 GraphQL 服务逻辑。第一步先定义用于表示书籍和作者数据的记录类型。在 Ballerina 中,记录是特定类型字段的集合。其中有命名的键,并定义了字段的类型。{|和|}分隔符表示这个记录类型只包含所描述的字段。
下面的“BookDetails”记录表示从数据库中获取到的书籍的详细信息。
接下来创建用于表示从 Google Books API 获取到的数据的记录类型。在创建所需的记录之前,需要分析一下根据指定 ISBN 从 Google Books API 获取的的 JSON 响应消息的格式。它返回一个 JSON 对象,其中包含了一个“items”的数组。它还有另一个叫作“volumeInfo”的对象,这个对象包含了与书籍评论相关的信息,字段名分别为“averageRating”和“ratingsCount”。

在 Ballerina 中有两种处理 JSON 的方式。你可以直接使用内置的“json”类型,或者将 JSON 转换成用户定义的“anydata”子类型。下面的示例使用了第二种方法,直接将响应消息映射成记录,因为 Ballerina 的 HTTP 客户端数据绑定为此提供了很好的支持。因为你只对与书籍评级相关的字段感兴趣,所以可以只用这些字段来创建记录。另外,你用不到字段名为“items”的中间对象,所以这里可以使用匿名记录,因为你不需要通过名称引用这个记录类型。
创建服务对象
Ballerina 记录类型和服务类型都可以作为 GraphQL 的对象类型。记录的字段被映射到 GraphQL 对象的字段,记录字段的类型被映射到 GraphQL 对应字段的类型。
服务类型中的每一个资源方法表示 GraphQL 对象的一个字段,资源方法可以有输入参数,这些输入参数被映射到相应字段的参数。
使用记录类型作为对象有局限性,因此,在这个示例中,我们使用服务类型来表示“Book”对象。
在这个服务中,“BookDetails”是一个 final 的只读字段,在初始化后不能被赋值。
Ballerina GraphQL 服务中的资源可以有层级资源路径。如果出现了层级路径,例如下面的 author/…,就会为每一个同名的中间路径段创建一个对象类型。路径段下的每一个子路径都将作为所创建类型的一个字段。
创建 GraphQL 服务
现在开始编写 GraphQL 服务。Ballerina 对基于网络的交互提供了一流的支持,因此编写服务就变得很简单。服务对象支持通过远程方法和资源方法进行网络交互。监听器提供了网络和服务对象之间的接口。
首先,你需要导入 ballerina/graphql 模块。然后,你通过指定要监听的端口来创建 GraphQL 监听器对象,并将其附加到服务上。
资源方法以 REST 的方式公开服务,而远程方法则以过程方式公开服务。Ballerina 服务可以有资源方法和远程方法,资源方法用于表示 GraphQL 查询类型,远程方法用于表示可变类型。
下一步是加入远程函数或资源函数。allBooks 和 bookByName 是通过 GraphQL 查询获取书籍数据的资源函数,因此,它们返回“Book”数组。要将新书添加到数据库中,可以调用“addBook”远程方法。它将书籍的信息作为输入参数,并返回一个 int 值,这个值表示已插入的书籍的索引,如果发生错误就返回-1。

Ballerina GraphQL 服务
下一步是实现数据访问逻辑,也就是实现远程方法和资源方法。
完整的代码在bookservice.bal中。服务的代码如下所示。与 DB 交互和 API 调用相关的 getBooks、addBookData 和 getBookReviews 函数的更多细节请参阅下一小节。
实现数据访问逻辑
由于本例使用 MySQL 数据库作为后端数据存储,因此需要提供查询数据库和添加新记录的功能。Ballerina 为 DB 交互提供了一流的支持。
现在,在项目中添加另一个名为bookdatastore.bal的文件,用于 DB 交互和 API 调用相关的实现。首先,你需要创建一个 MySQL 数据库客户端,并导入ballerinax/mysql、ballerina/sql和ballerinax/mysql.driver模块。
你可以在初始化客户端时提供配置信息,不过本例使用了Ballerina的配置功能来提供配置信息。用户可以根据不同的环境通过外部输入来改变系统行为,而且敏感数据(如密码)不会通过代码暴露出来。在定义了配置数据库所需的可配置记录之后,就可以按照如下方式创建 DB 客户端。
然后可以通过项目中的Config.toml文件来提供配置信息。
现在添加一个 HTTP 客户端,用于从 Google Books API 获取所需的数据。你需要导入ballerina/http模块,并按照如下方式创建客户端。
这样,你就完成了这个场景的实现。完整的访问数据库的代码可以在bookdatastore.bal中找到。
使用生成的图表
因为存在多个实体之间的交互,所以集成用例就变得很复杂。因此,理解整个流程和顺序对于维护、改进和解释场景来说至关重要。Ballerina 内置了图表功能,可以基于已编写的代码生成完整的序列图。图表可以作为代码的文档,相比直接阅读源代码,这种方式更易于理解程序。你可以使用Ballerina VSCode插件查看和编辑这些图表。
下面是 getBooks 方法对应的图表。其他方法也有类似的图标,你可以使用 VSCode 插件查看和编辑它们。
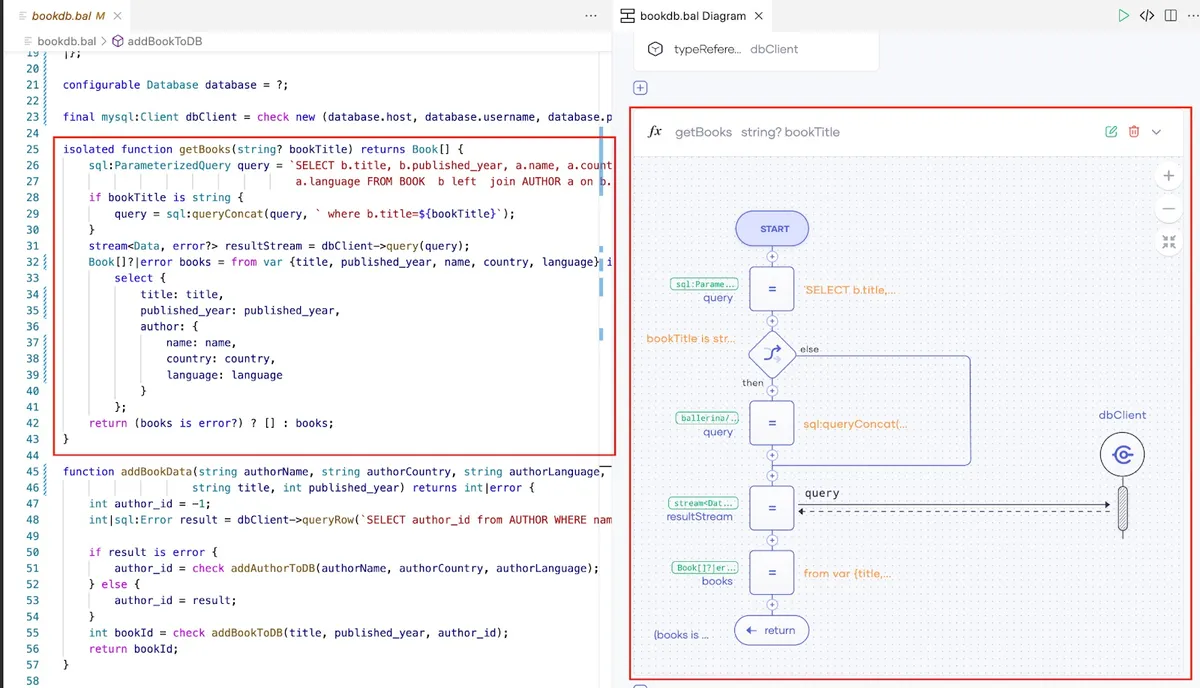
基于源代码生成的 Ballerina 图表
运行 Bookstore 服务
现在,让我们运行并测试 GraphQL 服务。要运行这个服务,需要在 bookstore 项目的根目录下执行下面的命令:
如果你使用 GraphQL 客户端工具连接到这个服务,它将显示下面这个的模式:
测试 Bookstore 服务
要调用 GraphQL 服务器,需要使用客户端。你可以在命令行中使用 curl 向端点发送 HTTP POST 请求,并将 GraphQL 查询作为 JSON 传递给它。另外,你也可以使用Ballerina GraphQL客户端工具为给定的 GraphQL 模式(SDL)和 GraphQL 查询生成 Ballerina 客户端。如果你喜欢使用图形用户界面,可以使用GraphiQL或Altair等。
所有请求的端点都是http://localhost:4000/bookstore。
示例请求 1:获取所有书籍的书名
GraphQL 查询:
响应:
使用 curl 命令发送相同的请求:
示例请求 2:获取所有书籍更多的信息
这就是 GraphQL 真正强大的地方。用户可以按照自己需要的格式请求所需的信息,无需指定不同的端点,只需修改查询即可。你可以看到这里的一些评级是“null”,因为 Google Books API 调用返回的一些 JSON 响应没有包含这些信息。
GraphQL 查询:
响应:
使用 curl 命令发送相同的请求:
示例请求 3:指定输入参数获取书籍的详细信息
GraphQL 查询:
响应:
使用 curl 命令发送相同的请求:
示例请求 4:将数据插入数据库
GraphQL 查询:
响应:
使用 curl 命令发送相同的请求:
总结
在现代应用程序开发中,GraphQL 可能是比 REST 更好的选择。Ballerina 为网络抽象提供了的一流的支持,可以通过简单而强大的方式开发 GraphQL 服务。在我们的示例中,我们实现了一个书店的 GraphQL 应用场景,结合了多个后端数据源,包括 MySQL 数据库和 Google Books API。
你可以访问ballerina.io来了解更多关于 Ballerina 的信息。
你可以通过检查问题来参与 Ballerina GraphQL 的模块开发。
示例项目的完整源代码可以在这里找到。
更多信息
可以参考以下资源了解更多关于 Ballerina GraphQL 的信息:
作者简介:
Anupama Pathirage 是 WSO2 的工程总监、工程经理和 Ballerina 语言的开发者。她为 Ballerina 的各个方面(如编译器、运行时、事务、表、数据库客户端和数据处理等)做出了贡献。Anupama 拥有软件架构硕士学位和斯里兰卡莫拉图瓦大学计算机科学与工程系一等荣誉学士学位。Anupama 在 DZone、InfoQ 和 Medium 上发表文章,并定期在国际技术大会上发表演讲。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论