

1. 背景
在 Chatbot 整体解决方案中, 既有面向任务型的 taskbot(诸如订机票、查天气等), 也有更偏向知识问答的 qabot,而在客服场景下,最基础的类型也是这类。如果从知识库的形式来区分 qabot,可以有 基于「文档」的 doc-qabot、基于「知识图谱」的 kg-qabot、基于「问答对」的 faq-qabot 等。我们这里重点关注的是最后一种 faq-qabot(也简称 faqbot), 这种形式的方案对用户而言易理解易维护,也是目前 chatbot 解决方案中不可缺的一部分。
faqbot 就是将 query 匹配到一条「问答对」上,从技术的角度看,有两大类方法, 一是 text classification, 二是 text matching,它们各有适合的场景,前者适合咨询量大且比较稳定的 faq,后者适合长尾或时常变化的 faq。
店小蜜是我们提供给阿里平台商家的一套智能客服解决方案。在店小蜜中, 基于 Faq 的问答是个很基础的部分,我们在这个领域,在文本分类和文本匹配上进行了各方面的研究和实践, 在本篇中重点对文本匹配的基础模型进行介绍。
「文本匹配」是 NLP 方向的一个重要研究领域,有着悠久的历史,很多 NLP 任务都与此相关,比如 natual language inference、parahparase identification、answer selection 等,都可以归结成「文本匹配」问题。
有很多人研究这个课题, 当前优秀的匹配模型有哪些?这些模型有什么异同?这些模型存在哪些问题?这些都是我们展开这个项目需要先分析和回答的问题。我们通过分析 SNLI 榜单上的模型,有几个结论:
优秀的匹配模型都可以归纳成 embed-encode-interacte-aggregate-predict 五个步骤, interact 部分主要是做 inter-sentence alignment;
在 interact 步骤中的对齐操作,设计会比较复杂;而且很多模型只有一次 interact 步骤;
也有些更深的模型结构,会做多次的 inter-sentence alignment, 但因为较深的模型面临着梯度消失、难以训练的问题;
不管是参数量还是响应时间,支撑像店小蜜这样对实时性能要求比较高的场景,都不是很理想。
所以我们在设计的时候, 要求我们的模型在更少的参数量、更简洁的模型结构、更少的 inference cost, 保证更容易训练、更适合部署到生产环境, 在这几个前提下, 我们也希望能借鉴深层网络的优势,让我们可以很方便地加深我们的网络层次, 让模型有更强的表达能力。
2. 模型
我们通过对学术界提出的各种模型,诸如 Decomposable Attention Model、CAFE、DIIN 等, 归纳总结,一个匹配模型的整体框架基本上有 Embedding Layer、Encoder Layer、Interaction Layer、Aggregation Layer 和 Prediction Layer 五层, 只是每一层都有不同的设计,我们实现一种可插拔的匹配模型框架, 每层都有一些典型的实现。
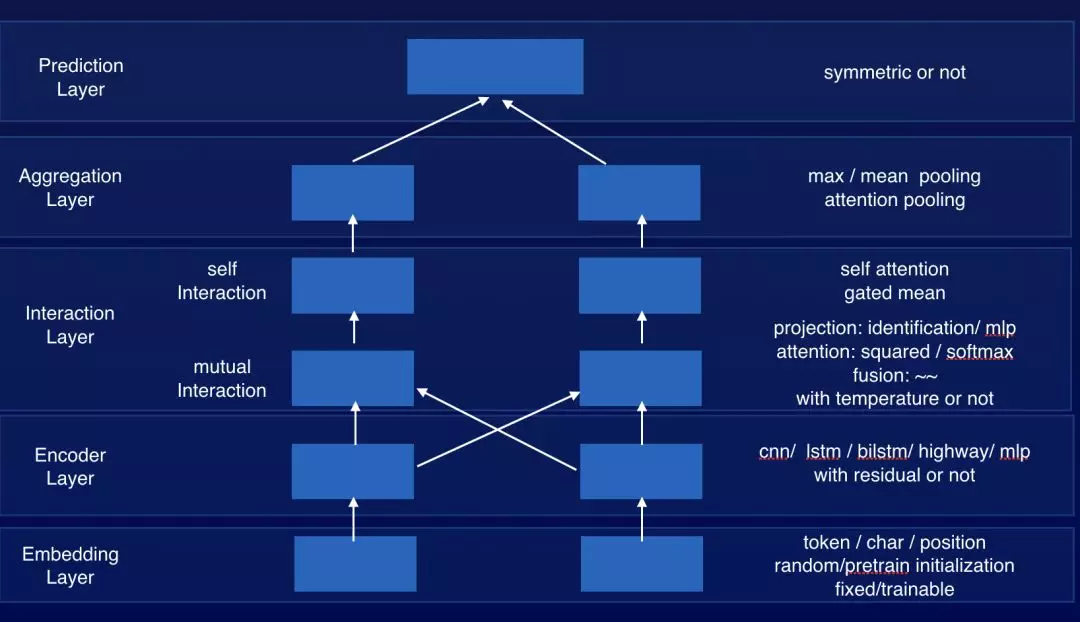
为了增强我们模型框架的表达能力, 我们将 Encoder+Interaction Layer 打包成一个 Block, 通过堆叠多个 Block, 通过多次的 inter-sentence alignment,可以让我们的模型更充分地理解两句文本之间的匹配关系。
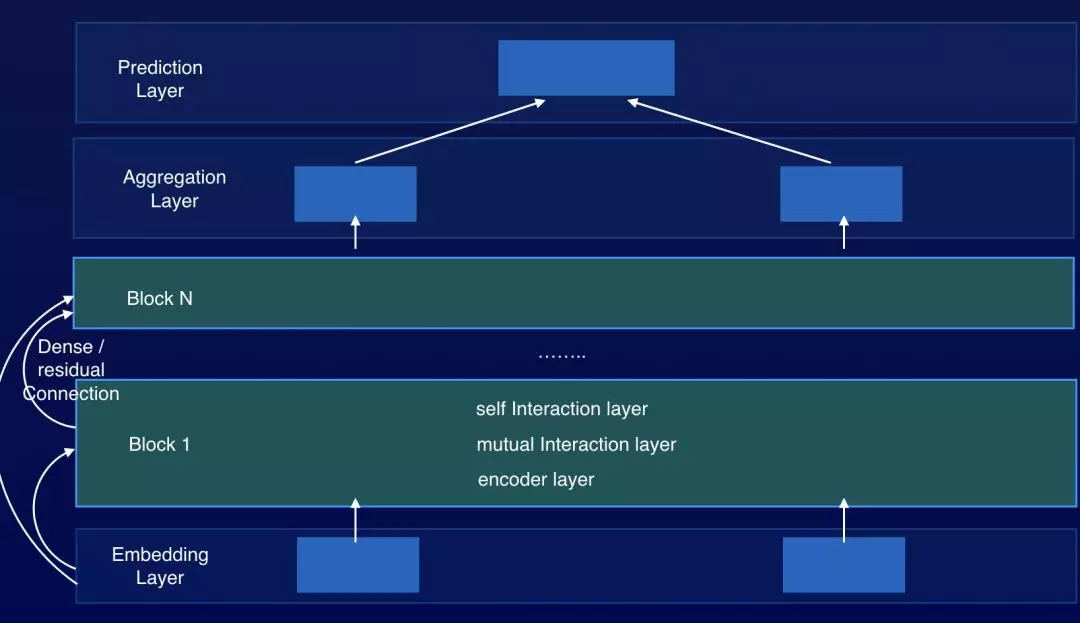
我们基于这种框架,通过大量试验得到一个模型结构 RE2, 可以在各类公开数据集、和我们自己的业务数据上都能得到最优的结果,如下图所示。
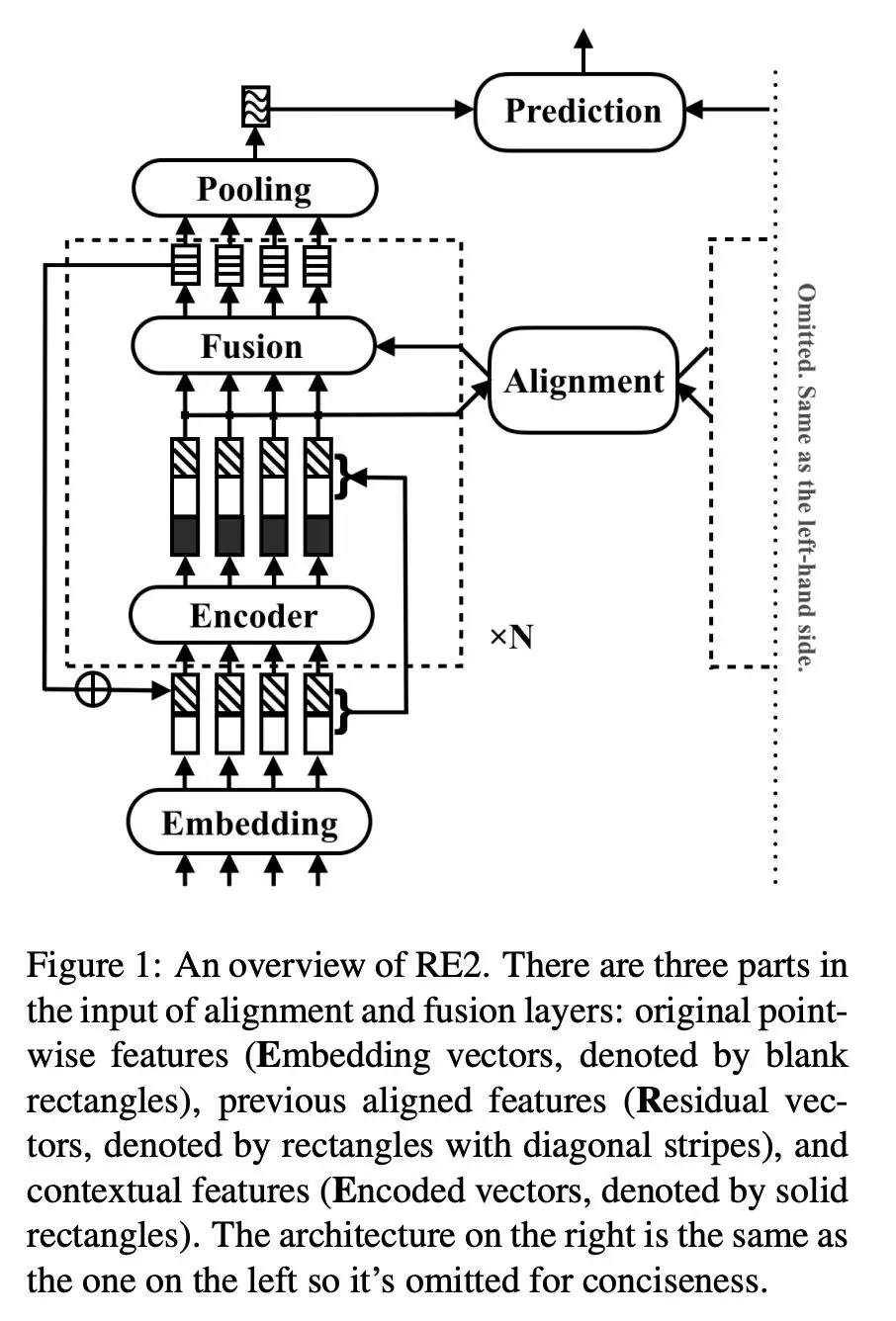
RE2 包括有 N 个 Block, 多个 Block 的参数完全独立。在每个 Block 内有一个 encoder 产出 contextual representation, 然后将 encoder 的输入和输出拼在一起,做 inter-sentence alignment,之后通过 fusion 得到 Block 的输出。第 i 个 Block 的输出,会通过 Augmented Residual Connection 的方式与这个 Block 的输入进行融合, 作为第 i+1 个 Block 的输入。
下面我们详细介绍每个部分:
2.1 Augmented Residual Connection
连续的 Block 之间用 Augmented Residual Connection 来连接, 我们将第 n 个 Block 第 i 个位置的输出记作:,是个全零的向量。
第一个 Block 的输入为, 也就是 Embeddling Layer 的输出, 在 Augmented Residual Connection 中,第 n 个 block 的输入为:
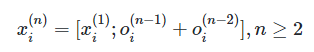
其中 [;] 表示拼接操作;
在 interaction layer 的输入中,存在三种信息, 一是 original point-wise information, 在这里就是原始的词向量,在每个 Block 中都会使用这份信息;二是通过 encoder 编码得到的 contextual information;三是之前两层 Block 经过对齐加工过的信息。这三份信息,对最终的结果都有不可替代的作用, 在试验分析中会展显这一点。在我们这里 encoder 使用两层 CNN(SAME padding)。
2.2 Alignment Layer
这块我们使用 Decomposable Attention Model(Parikh et al., 2016)的对齐机制:
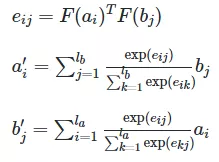
2.3 Fusion Layer
这块我们参考 CAFE 中对 concat、multiply、sub 三个操作分别通过 FM 计算三个 scalar 特征值, 我们针对这三个操作, 用独立的三个全连接网络计算三个 vector 特征, 之后将三个 vector 拼接并用进行 projection。
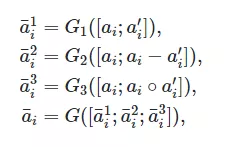
2.4 Prediction Layer
输出层就比较常规,针对文本相似度匹配这类任务, 我们使用对称的形式:
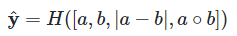
针对文本蕴含、问答匹配这类任务, 我们使用
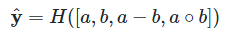
其中 H 表示多层全联接网络;
3. 试验
3.1 数据集
要验证模型效果,我们选择三类 NLP 任务, Nature Language Inference、Paraphrase Identification、Question Answering, 选用 SNLI、MultiNLI、SciTail、Quora Question Pair、Wikiqa 这样几份公开数据集。评估指标,前两个任务选用 Acc, 后一个任务选择 MAP/MRR。
3.2 实现细节
我们用 Tensorflow 实现模型, 用 Nvidia P100 GPU 训练模型, 英文数据集使用 NLTK 分词并统一转小写、去除所有标点。序列长度不做限制,每个 batch 中的序列统一 pad 到这个 batch 中最长序列长度,词向量选用 840B-300d Glove 向量,在训练过程中 fix 住,所有 OOV 词初始化为 0 向量,训练中不更新这些参数。所有其他参数使用 He initialization, 并用 Weight normalization 归一化;每个卷积层或全联接层之后,有 dropout 层,keep rate 设为 0.8;输出层是两层前馈网络;Block 数量在 1-5 之间调参。
在这几份公开数据集上, 隐层大小设为 150;激活函数使用 GeLU 激活函数。优化算法选用 Adam,学习率先线性 warmup 然后指数方式衰减,初始学习率在 1e-4~ 3e-3 之间调参;batch size 在 64~512 之间调参。
3.3 结果
我们在这几份公开数据集上,均取得 state-of-art 的结果(不使用 BERT 的情况下):
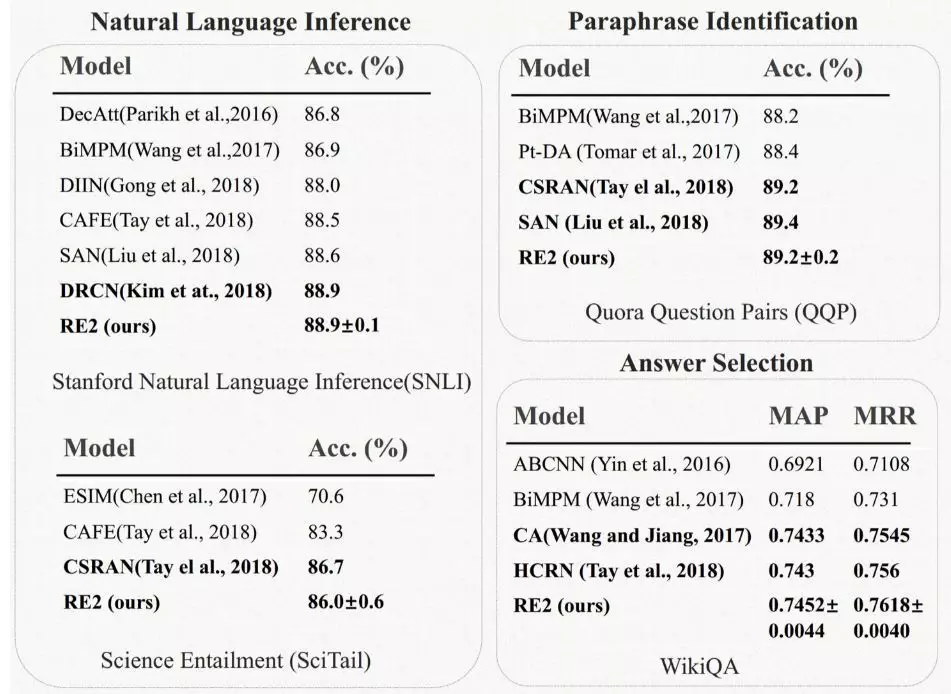
同样这个模型性能上也有很良好的表现,参数量和 inference speed 都有很强的竞争力, 从而可以在我们店小蜜这样的工业场景中得到广泛应用,给我们匹配准确率这样的业务指标上带来显著的提升。
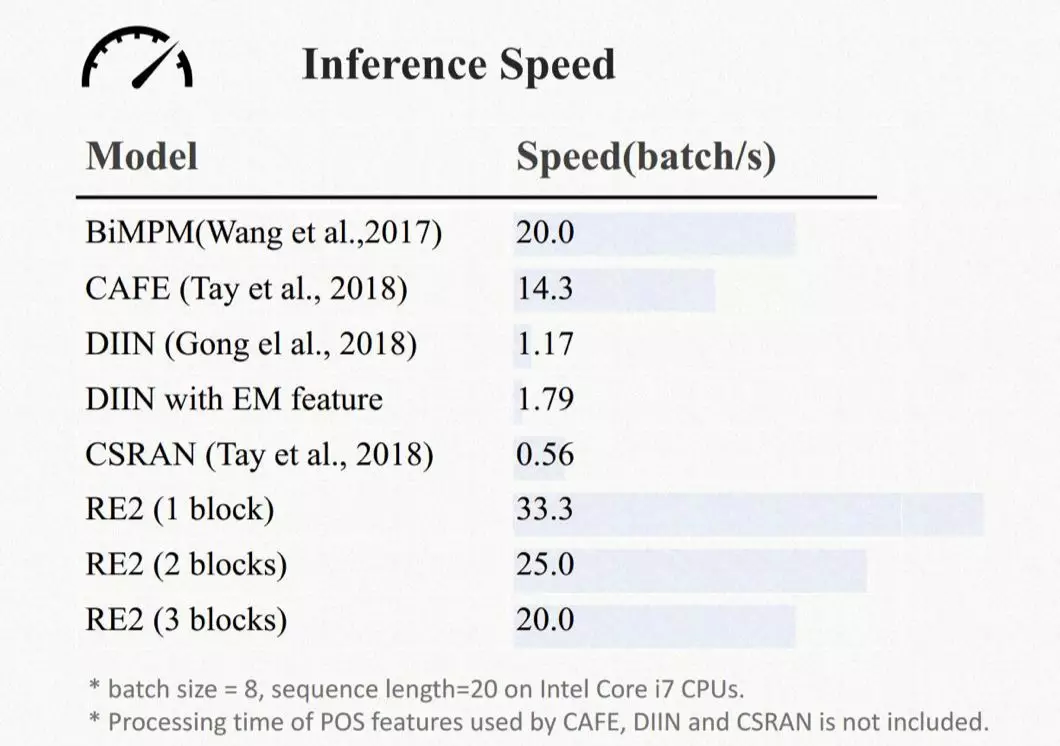
3.4 结果分析
★ 3.4.1 Ablation study
我们构造了四个 baseline 模型, 分别是:
w/o enc-in: alignment layer 只使用 encoder 的输出;
w/o residual:去除所有 block 之间的 residual 连接;
w/o enc-out: 去除所有 encoder,alignment layer 只使用 block 的输入;
highway: 使用 highway 网络融合 encoder 的输入和输出,而不是直接拼接。
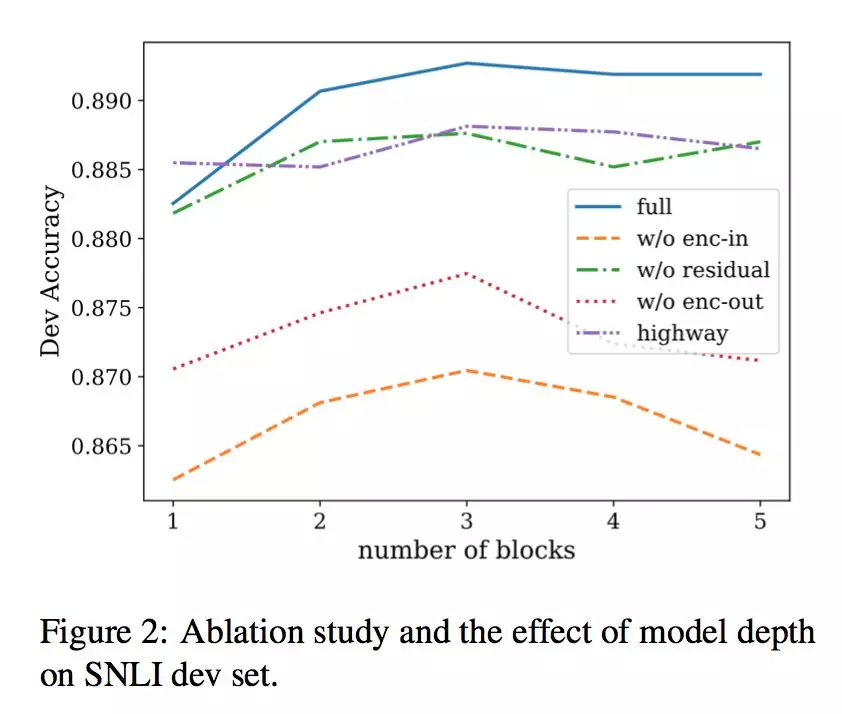
在 SNLI 上得到的结果如图所示。通过 1)3)和完整模型的对比, 我们发现 alignment layer 只使用 encoder 的输出或只使用 encoder 的输入,都会得到很差的结果,说明原始的词向量信息、之前 Block 产出的 align 信息、当前 Block 中 encoder 产出的上下文信息,对最终的结果都是缺一不可的。通过 2)和完整模型的对比,我们发现 Block 之间 residual 连接发挥了作用;而 4)和完整模型的对比显示,我们直接拼接的方式是个更优解。
★ 3.4.2 Block 数量的影响
如上图所示,通过 Augmented Residual Connection 连接的网络,更容易在深层网络中生效,能够支撑更深的网络层次,而其他 baseline 模型,在 Block 数量大于 3 时, 效果会有很明显的下降,并不能支撑更深层模型的应用。
★ 3.4.3 Occlusion sensitivity
前面讲过, 在 alignment layer 的输入中,其实是三类信息的拼接:原始的词向量信息、之前 Block 产出的 align 信息、当前 Block 中 encoder 产出的上下文信息, 为了更好地理解这三份信息对最终结果的影响,我们参照机器视觉中相关工作, 进行了 Occlusion sensitivity 的分析。我们在 SNLI-dev 数据上,使用包含 3 个 Block 的一个 RE2 模型,分别将某层 Block 中 alignment layer 输入特征的某部分 mask 成 0 向量,然后观察在 entailment、neutral 、 contradiction 三个类别上的准确率变化:
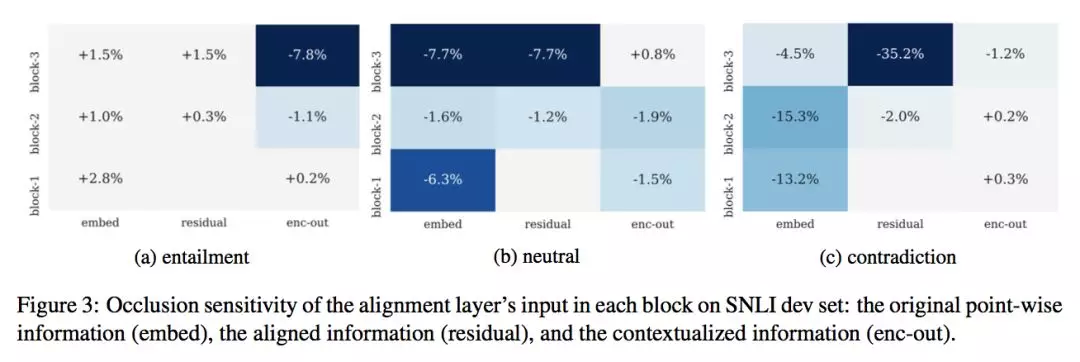
可以得到几个分析结论:
mask 原始的词向量信息, 会对 neutral 和 contradiction 类的识别带来比较大的损失, 说明原始词向量信息在判断两个句子差异性上发挥着重要作用;
mask 之前 Block 产出的 alignment 信息, 会对 neutral 和 contradiction 类带来比较大的影响,尤其是最后一层 Block 的这部分信息对最终的结果影响最大, 说明 residual connection 使得当前 Block 能更准确地关注应该关注的部分;
mask 住 Encoder 的输出结果, 对 entailment 的影响更大,因为 encoder 是对 phrase-level 的语义进行建模, encoder 的产出更有助于 entailment 的判断;
★ 3.4.4 Case study

我们选了一个具体的 case 分析多层 Block 的作用。
这个 case 中, 两句话分别是“A green bike is parked next to a door”“The bike is chained to the door”。在第一层 Block 中,是词汇/短语级别的对齐, 而“parked next to”和“chained to”之间只有很弱的连接,而在第三层 Block 中, 可以看到两者已经对齐, 从而模型可以根据“parked next to”和“chained to”之间的关系,对两句话整体的语义关系做出判断。从中也可以看到,随着 Block 的递增, 每层 Block 的 alignment 关注的信息都随之进行着调整,通过不止一次的 alignment, 可以让模型更好地理解两句话之间的语义关系。
4. 业务结果
在店小蜜中,自定义知识库是由商家维护,我们提供知识定位方案;在店小蜜无法给出准确回复时, 我们会推荐相关知识,这里的文本匹配模型,也主要用在店小蜜的这两个业务模块。我们重点优化了 7 个大类行业模型(服饰、美妆洗护、鞋、电器、茶酒零食、母婴、数码)、一个大盘基础模型和相关知识推荐模型。在保证覆盖率的情况下, 7 类主营行业准确率从不到 80%提升到 89.5%,大盘基础模型准确率提升到 84%,知识推荐有效点击从 14%左右提升到 19.5%。
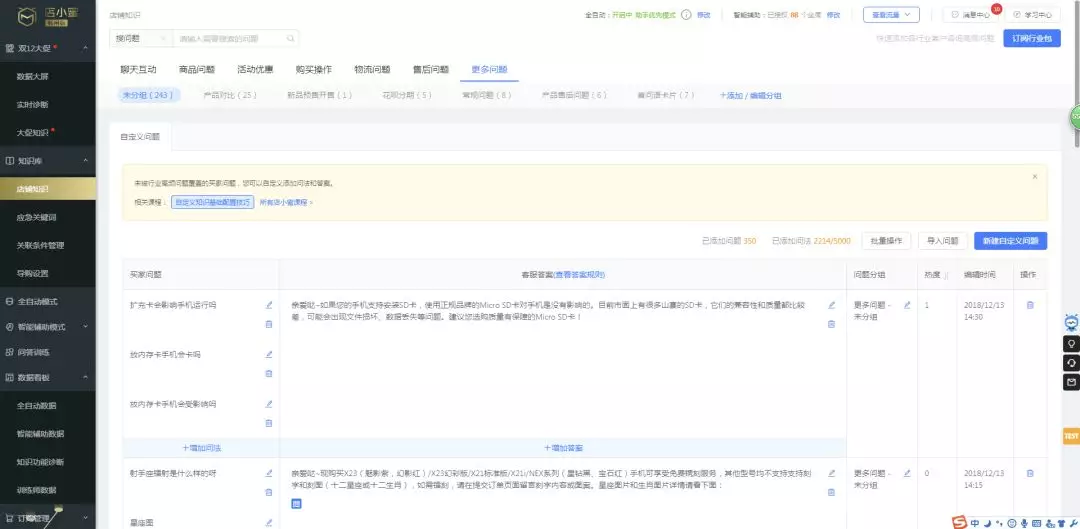
店小蜜自定义知识库后台配置:
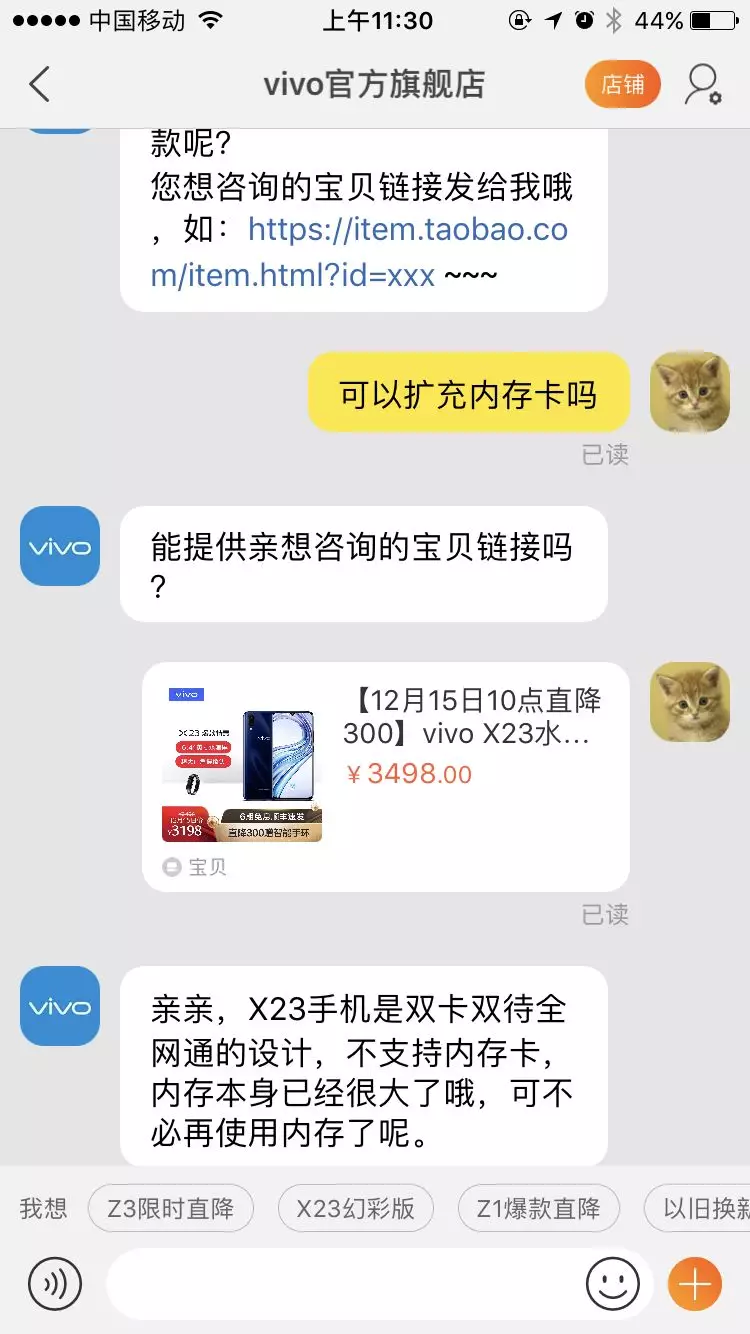
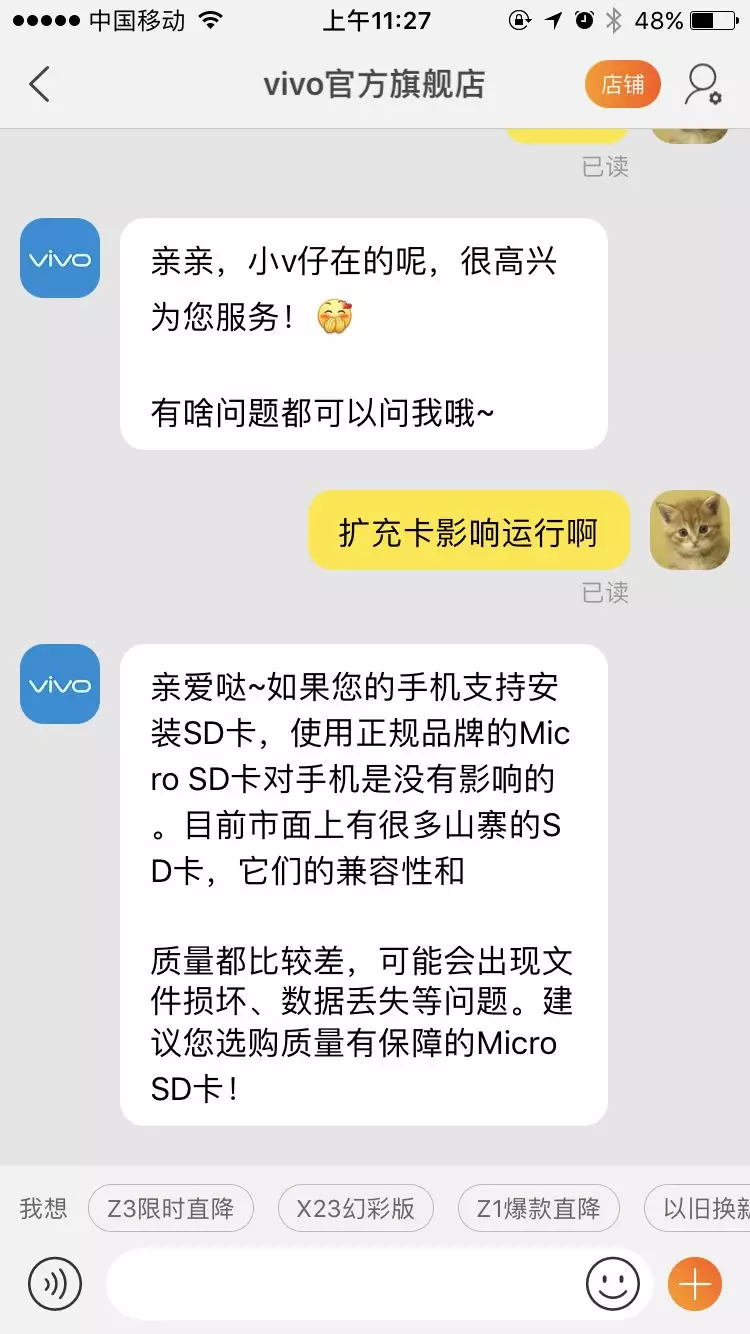
店小蜜旺旺咨询示例:
总结展望
我们在工业场景下,实现了一个简洁同时具有很强表达能力的模型框架,并在公开数据集和业务数据集上取得很好的结果。
这种「通用」的语义匹配模型,已经对当前的业务带来很大的提升, 但是,针对店小蜜这样的业务场景, 是否在不同行业不同场景下可以得到更合适更有特色的解决方案,比如融合进商品知识、活动知识等外部知识做文本匹配。
怎么进一步完善 FaqBot 的技术体系,比如在文本分类、Fewshot 分类等方向,也是我们团队的一个重点工作。
随着 BERT 模型的出现,NLP 各项任务都达到了新的 SOTA。然而 BERT 过于庞大,对计算资源的需求很高,因此我们想利用 Teacher-Student 框架将 BERT 模型的能力迁移到 RE2 模型上。
本文转载自公众号阿里技术(ID:ali_tech)。
原文链接:
https://mp.weixin.qq.com/s/JDkWX6hpyAV15zjk3xOsGQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论