
1. 背景介绍
『聚合解决的是“让数据有的比”的问题,聚合的成功率和准确率直接奠定了用户在网站进行比价体验的基调。』
在酒店频道,聚合一直被认为是业务的基础和核心。因为无论是 Qunar 最开始定位的报价搜索,还是现在转型的比价平台,业务模式决定了我们要从众多代理商和渠道获取大量的酒店数据并对其进行整合, 所以聚合解决的是一个“让数据有的比”的问题 ,不夸张的说,聚合的成功率和准确率直接奠定了用户在网站进行比价体验的基调。
酒店聚合的职责简单归纳就是:
将不同代理商来源的酒店数据(酒店 tree)统一到 Qunar 酒店下,为比价平台提供酒店对应关系的映射。
例如以下这组聚合关系:

目前酒店聚合算法主要参考 酒店名、地址、城市、 坐标、电话这几类数据进行判定,名称和地址作为重点参考内容,在大多数场景下可直接决定聚合结果;坐标和电话由于来源数据规范等问题(如坐标系不一致,酒店电话和代理商电话掺杂提供),仅做辅助判定。
2. 痛点难点
『各国地址信息命名本地化、差异大;基于对文本相似度的计算,对于酒店名和地址中的信息解析能力有限。』
国际酒店在 Qunar 起步较晚,各类基础数据,特别是聚合层面的数据积累有限,且 国际代理商数据参差不齐,数据的规范化程度较差 ,再加上运营资源有限,依靠 人工为数据建立聚合关系成本高、效率低、不现实 。基于以上这些情况,我们急需提高国际酒店自动聚合算法的能力。本文将介绍过去一年中针对国际几个重点国家进行的聚合算法优化的情况,希望能给到有类似业务痛点的同学一些解题思路和参考。
目前国际酒店聚合的痛点与难点集中在以下两个方面:
A. 不同国家间地址信息的本地化差异

如上图所示,地址的组成格式在各个国家之间都有差异且其中夹杂着本地化的信息(图中标红的部分)。
B. 原有算法针对文本相似度计算,对于酒店名和地址中的信息解析能力有限
酒店聚合算法的本质是针对两个酒店信息进行文本相似度的计算,满足一定的相似度分值后即可判定为二者存在聚合关系。但对于类似名称,地址类的长文本数据,其本身就包含多种成分,如品牌,分店,酒店行业词,路名,门牌号,城市等,且这些成分的重要程度是有所区别的。
比如“永正”作为品牌信息几乎可以直接锁定“北京永正商务酒店”,然而“商务酒店”作为行业词,由于信息太过模糊,几乎不能定位到任何具体的酒店。如果不能把这些成分区分清楚而直接进行文本相似度计算,就可能出现把下列两家酒店聚合到一起的错误。

如下图所示,目前的国际酒店聚合算法对于酒店名和地址中的详细成分几乎无法拆分。

3. 优化思路
『整理高频次出现的名称及地址格式,形成各种分词结果;从文本匹配变为将分词结果与可能模式进行匹配,针对相似度进行加权评分计算。』
上文提到,酒店名和地址可细分出多种不同成分,其中重要的部分可归纳为:
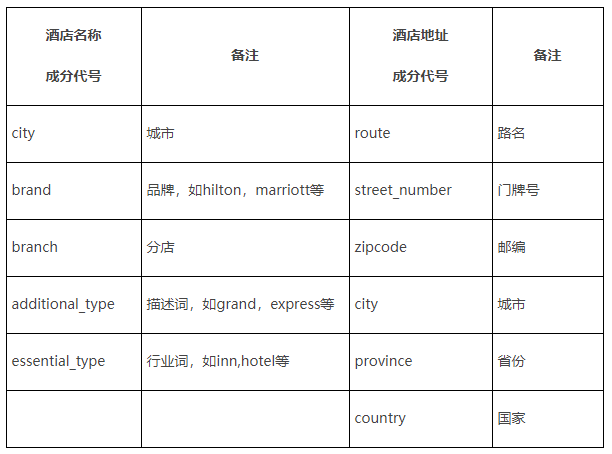
其中 城市层级,品牌,poi 字典 以 qunar 酒店基础信息为基底,配合代理商数据,酒店官网扩充覆盖及同义词;
通过对酒店名分词并进行反向高频统计,配合运营人工筛选,可整理出酒店 描述词 和 行业词 字典;
酒店地址中的路名信息由于存在大量本地化内容,这部分关键字词典需要分地区(一般是按国家维度)对地址分词并统计高频结果,配合官方数据(google,Wikipedia 等)筛选整理。
基于目前库内已有的酒店数据,我们对名称和地址的组成格式进行统计,整理出高频率出现的格式,具体如下图截取的片段所示:

通过引入这种模式匹配的概念,就可以很容易的从给定的酒店名和地址中抽取出各类成分信息,举例如下:
酒店名拆分示例

酒店地址拆分示例

【划重点】
优化后的一次完整聚合流程如下:
一条待聚合的酒店数据进入;
基于预先收集的各类型词汇(品牌,城市,国家)的词典,对酒店名和地址数据进行解析,找出其中所有可能的分词结果;
将分词结果与所有可能的模式进行匹配,选出合法匹配中的最优解作为解析结果;
根据解析出的关键成分(品牌+分店名,路名+门牌号)在已聚合数据中进行全文检索,初筛出相似度最高的 n 条结果作为候选集;
在待聚合和各候选酒店之间,针对各个成分进行对比,对比出的基于字符串的相似度(匹配的可能性有:完全一致,包含,前缀,后缀等)结果配合各个成分本身的权重(如酒店名中:品牌>分店>行业词>城市),最终算出一个综合的分数;
在某些特殊情况下进行打分的调整:如路名相同,门牌号不同,减分;如联系电话相同或坐标距离相近,加分;
选择相似度得分最高的候选酒店作为最终候选者,判断得分是否高于给定的聚合分数线,是则可认为聚合成功。
4. 优化成果
针对国际重点的八个国家,我们按照模式匹配的方式优化了聚合算法,收效成果如下图所示:
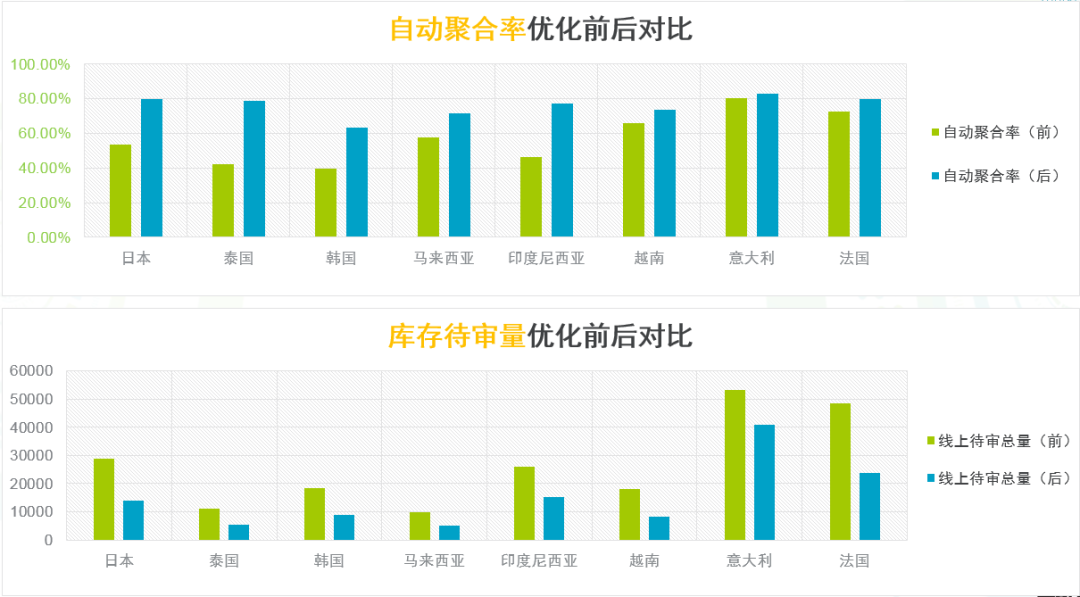
后续还将继续分享国际酒店房型的聚合经验,欢迎各位多多交流,共同进步。
作者介绍:
王刚,2013 年加入 Qunar,目前主要负责国际酒店供应链系统,专注于基础数据集成,竞对分析,搜索 & 聚合算法等领域。
本文转载自公众号 Qunar 技术沙龙(ID:QunarTL)。
原文链接:




