

微软和谷歌一直积极致力于训练深度神经网络的新模型,并推出了各自的新框架,Microsoft PipeDream和Google GPipe。二者使用了类似的原理来扩展深度学习模型的训练能力,具体细节在相应的研究论文中分别给出(参见PipeDream和GPipe的论文)。
作为深度学习生命周期中的一个组成环节,训练工作在模型扩展到一定规模时是十分具有挑战性的。虽然训练一个实验性的基本模型相对简单,但训练的复杂性会随模型的质量和规模呈线性增长。例如,在2014年ImageNet视觉识别竞赛中,具有 400 万参数的GoogleNet以 74.8%的正确率胜出。三年后,2017 年 ImageNet 竞赛的胜出者 SENet(Squeeze-and-Excitation Networks)给出了 82.7%的正确率,但模型规模增大了 36 倍多,达 1.458 亿个参数。同一时期,GPU 内存规模只增长了约三倍.
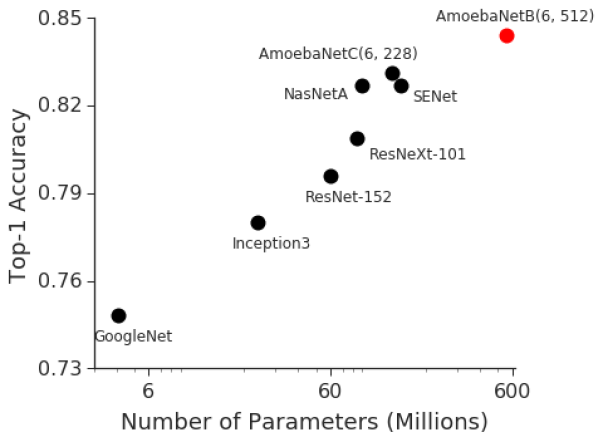
模型规模的扩展意在实现更高的正确率,但会使模型训练愈发具有挑战性。上面的例子说明,依赖改进 GPU 架构去实现更高效的训练是难以持续的策略,继续实现训练的扩展需要分布式计算方法,将工作负载并行化到各个计算节点上。训练并行化这一理念并不难理解,但是其实现是非常复杂的。开发人员需考虑如何将模型的知识获取分区到不同的节点,随后如何将各部分重新整合为一个整体的模型。训练并行化是深度学习模型扩展的必须手段。针对挑战,谷歌和微软两家公司各自付出了长达多月的努力来做研究和工程化,并分别发布了 GPipe 和 PipDream。
Google GPipe
Gpipe 聚焦于扩展深度学习的训练负载。在深度学习模型中,人们常常忽视训练过程的复杂性对架构的影响。训练数据集的规模正越来越大,也越来越复杂。例如在医疗领域,常会涉及需使用数百万张高分辨图像训练的模型。这类模型通常需要很长的训练时间,消耗高昂的内存和 CPU 成本。
可行的深度学习模型并行方法分为数据并行和模型并行。数据并行方法使用大规模集群,将数据分布到各个节点。模型并行则将模型迁移到 GPU 和 TPU 等加速器上,借助这些专用硬件来加速模型的训练。从更高层次看,几乎所有的训练数据集都可以按照一定的逻辑实现并行化,但是并非所有的模型皆可并行。一些深度学习模型能分解为一些可并行独立训练的分支,相应的经典策略是将计算划分为分区,不同的分区指派给相应的模型分支。但该策略并不能很好地应用于具有序贯(sequential)层堆叠结构的深度学习,这对实现高效的并行计算提出了挑战。
GPipe 使用了称为“流水线”(pipelining)的方法,实现数据并行和模型并行的结合。具体而言,GPipe 提供分布式集群学习软件库,基于同步随机梯度下降(SGD)和流水线并行实现训练,适用于所有具有多个序贯层的 DNN。GPipe 将模型分区到多个加速器上,自动将训练中的 mini-batch 切分为更小粒度的 micro-batche。模型通过在加速器上的并行执行,最大化训练过程的可扩展性。
下图展示的 GPipe 模型中,具有多个序贯层的神经网络被分区到四个加速器。其中 F(K)是第 K 个分区的前向传播计算组合,B(k)是相应的后向传播函数。B(k)计算依赖于前一层的 B(k+1)计算以及中间层激活的 F(k)。图中上半部分显示由于网络的顺序处理本质,导致资源利用率不高。下半部分显示 GPipe 通过将输入的 mini-batch 切分为更小粒度的 macro-batch 处理,实现了加速器的同时并行处理。
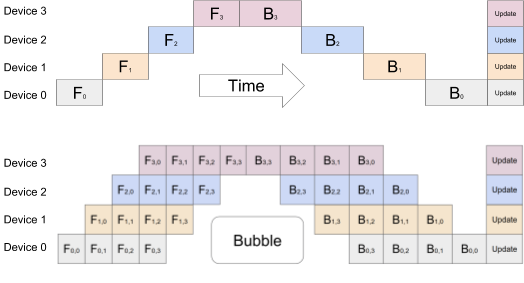
图片来源:https://arxiv.org/pdf/1811.06965.pdf
Microsoft PipeDream
数月前,微软研究院提出了意在提高分布式深度学习效率的项目系列Fiddle。PipeDream 是 Fiddle 中率先发布的项目,聚焦于实现深度学习模型训练的并行化目标。
不同于其它系统,PipeDream 针对 GPipe 在数据并行和模型并行中同样面对的一些挑战,采用了一种称为“流水线并行”(pipeline parallelism)的方法扩展深度学习模型训练水平。通常,数据并行方法在基于云的架构中实现训练时存在较高的通信成本问题,长期来看会拖累 GPU 的计算速度。另一方面,模型并行技术不能有效地利用硬件资源,并将根据特定硬件部署实现模型切分的重任甩给了程序开发人员。
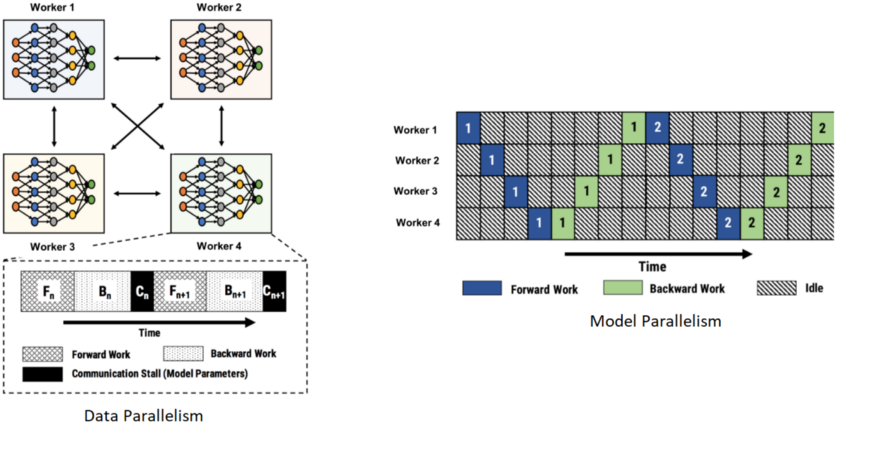
图片来源:https://www.microsoft.com/en-us/research/uploads/prod/2019/08/fiddle_pipedream_sosp19.pdf
使用流水线并行技术,PipeDream 解决了一些存在于数据并行和模型并行方法中的挑战性问题。流水线并行计算将 DNN 模型的序贯层划分为多个阶段(stage),每个阶段包括了一组模型中连续的层,映射给单独的 GPU,去执行阶段中所有层的前向传播和后向传播计算。
对于给定的深度神经网络,PipeDream 会根据对单个 GPU 的性能精简分析,自动判定如何划分 DNN 运算符,实现各个阶段的计算负载均衡,同时最小化计算平台的通信量。PipeDream 支持在模型多样(包括计算和通信)和平台多样(包括互联拓扑和层级带宽)情况下实现高效的负载均衡。相比数据并行和模型并行,PipeDream 的并行训练方法具有多种优点。例如,PipeDream 降低了工作节点的相互通信量,因为流水线并行中每个工作节点只需向其他节点传输部分的梯度和激活(activation)输出。此外,PipeDream 实现了计算和通信的分离,使得并行化更易于实现。
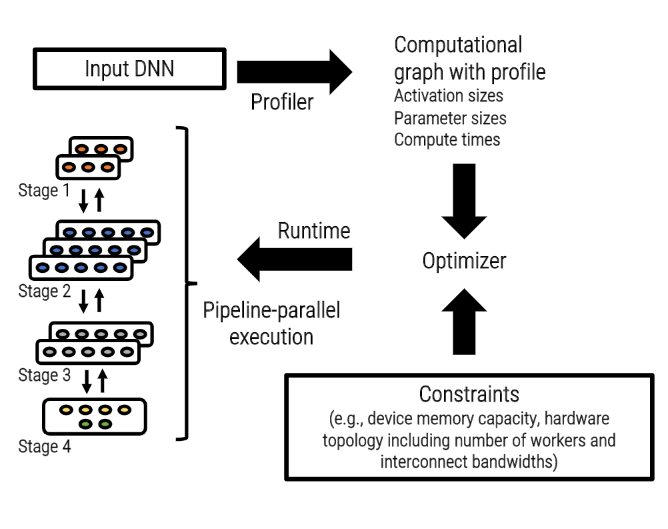
图片来源:https://www.microsoft.com/en-us/research/uploads/prod/2019/08/fiddle_pipedream_sosp19.pdf
训练并行化是构建规模更大、更精确深度学习模型的关键挑战之一,也是深度学习社区中一个活跃的研究方向,需有效结合并发编程技术和深度学习模型的本质来达成目标。当前,深度学习开发人员要实现模型训练的并行化,初出茅庐的 GPipe 和 PipeDream 无疑是两种最具创造力的选项。
原文链接:

InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论