

互联网快速发展的当下,数据存储计算的需求与日俱增。华为在 GIV 2025 报告中指出,预计到 2025 年,全球每年新增数据存储量为 180ZB,企业的数据利用率将会达到 86%。
随着 5G、IoT、VR/AR、自动驾驶等技术的发展,会涌现更多大数据应用的创新,面对海量数据分析带来的算力需求不均、数据结构的多样化、高并发作业等诸多挑战,传统大数据平台存算一体耦合在同一集群,主要基于本地 HDFS 作为大数据存储。
这种存算一体的大数据技术架构随着存储量的增长计算成本也随之线性增长,无法灵活配置存储及算力,难以满足企业海量数据分析追求极致性价比的一些典型场景,需要通过大数据计算存储分离方案来解决。
在离线分析场景中
离线批处理,分析类型多,数据量大,大数据开发需求爆发式增长,对存储和算力需求不一。当存储空间或计算资源不足时,企业只能同时对两者进行扩容,虽然能保证性能最优,但存算资源,扩容成本高,利用率低。通过大数据计算存储分离方案,计算不够扩计算,存储不够扩存储,计算资源根据任务负载动态扩缩容机器,最大限度降低企业使用成本,提升资源利用率。
在日志留存场景中
存储周期变长(例如 2 个月变成 6 个月),但算力并不需要显著增加,通过大数据计算分离方案可降低计算的配置和成本。
在一些为了提高效率的场景中
有时需要关闭闲置的计算集群,但由于计算集群中存在数据,关闭闲置的计算集群会导致数据丢失,无法实现真正的弹性计算,存算分离可保证数据不丢失。
作为国内首家弹幕式直播分享网站,斗鱼已成为国内排名第一的电竞娱乐一站式直播分享平台,以游戏直播为主,涵盖了体育、综艺、娱乐等多种直播内容,每天都在为成千上万的观众分享欢乐。
据头榜 2019 年 12 月数据显示,斗鱼日均活跃观众 1485.56 万人次,累积弹幕总数 9 亿 7073 万,活跃主播 32.38 万人次,平均在线时长达 5 小时以上,累积付费礼物 4 亿 6146 万……每月将会产生 PB 级数据量。
与此同时,直播黑产(主播刷榜、渠道推广、非法充值等等)也越来越猖獗,斗鱼自建的大数据分析平台面临数据量和计算量大但要严格控制成本的困难,在有限的投入下提升斗鱼风控平台投诉排查效率。
在 HUAWEI CONNECT 2019 大会期间,李瑞(斗鱼风控代表)表示:
斗鱼大数据分析平台目前是自建集群基于开源 CDH,随着业务规模越来越大,面临数据量大、计算量大,维护成本高的困难,需要寻求稳定高性价比的解决方案。
通过严格的业务模拟、比拼测试后,华为云“存算分离+鲲鹏”大数据解决方案适用斗鱼大数据数据增速快于计算的业务场景。其在读写性能、复杂计算、简单计算、数据倾斜等方面均优于 IDC 本地大数据计算集群,整体性能得到大幅提升。
那么,华为云“存算分离+鲲鹏”大数据解决方案为直播代表斗鱼带来了哪些价值:
存算分离性价比高,极致弹性 大幅提升大数据集群资源利用率
华为云“存算分离+鲲鹏”大数据解决方案针对传统存算一体大数据架构中扩容困难、资源利用率低等问题,
采用计算存储分离架构:
存储基于公有云对象存储实现 11 个 9 的高可靠,无限容量,支撑企业数据量持续增长;
计算资源支持 0~N 弹性扩缩,百节点 3 分钟发放。存算分离后,计算节点可实现真正的极致弹性伸缩;
数据存储部分基于 OBS 的跨 AZ 等能力实现更高可靠性,无需担心地震、挖断光纤等突发事件。
存储和计算资源可以灵活配置,根据业务需要各自独立进行弹性扩展,可使资源匹配更精准、更合理,让大数据集群资源利用率大幅提升,综合分析成本降低 50%,帮助斗鱼实现性价比最优。同时:
通过高性能的计算存储分离架构,针对对象存储数据访问效率深度优化(元数据操作、写入算法优化等),实现存储加速;
通过分布式高性能缓存,异构存储模型,支持热数据加速访问,实现缓存加速;
通过高性能 shuffle、高效的 SQL 优化器,实现计算引擎加速;支持多数据源的计算下压,性能相比开源提升 1 倍。
基于多级加速技术支持,助力斗鱼离线大数据分析效率大幅提升。
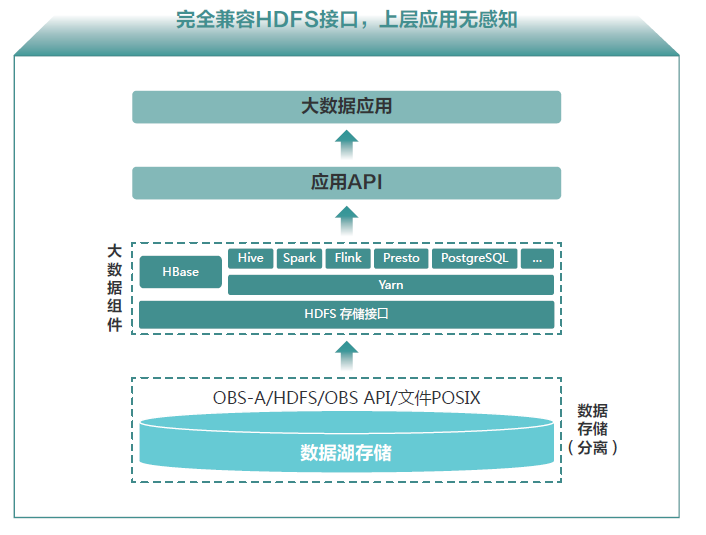
图 1 华为云存算分离大数据架构
鲲鹏加持 为大数据提供更高算力
在计算层,华为云“存算分离+鲲鹏”大数据解决方案基于鲲鹏处理器的多核高并发能力、自研 EulerOS,可为用户提供包括裸金属服务器,云服务器,容器和 Serverless 在内的多种粒度的大数据算力,大数据分布式场景性能可提升 25%,可轻松处理 PB 级数据作业,帮助斗鱼解决 IDC 算力不够的问题,为斗鱼在海量数据多并发作业提供可扩展的分析能力。
开放生态 全面兼容,0 改造上云
华为云坚持开放生态路线, “存算分离+鲲鹏”大数据解决方案完全兼容开源原生接口,全面兼容主流的大数据生态,让斗鱼大数据应用从 IDC“0 改造”平滑移植上华为云。
同时提供一份数据支持多引擎的能力,即同一份数据存放在 OBS 上供多引擎调度(传统批、流、交互式,以及 AI 引擎),数据“0”搬迁,减少数据冗余,支持多种业务计算诉求,实现真正数据湖,帮助斗鱼减少重复投资,轻松应对海量存储,提升业务分析效率。未来双方还将在 AI,视频云服务,5G+Cloud+直播创新等领域进一步合作,打造更好的用户体验。
华为云“存算分离+鲲鹏”大数据解决方案为客户和伙伴提供高性价比、极致弹性伸缩、多元计算引擎的业界领先大数据解决方案,使得客户和伙伴可以更加聚焦业务,创造价值,打破数据孤岛,助力企业数字化转型。
本文转载自华为云产品与解决方案站公众号。
原文链接:https://mp.weixin.qq.com/s/KSO9f2N5MY36pDmC_xSTLQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论