这篇文章已经是整个 Rack 系列文章的第五篇了,在前面的文章中我们见到了多线程模型、多进程模型以及事件驱动的 I/O 模型,对于几种常见的 webserver 已经很了解了,其实无论是 Ruby 还是其他社区对于 webserver 的实现也就是这么几种方式:多线程、多线程和 Reactor。
在这篇文章中要介绍的 Puma 只是混合了两种 I/O 模型,同时使用多进程和多线程来提高应用的并行能力。
文中使用的 Puma 版本是 v3.10.0,如果你使用了不同版本的 Puma,原理上的区别不会太大,只是在一些方法的实现上会有一些细微的不同。
Rack 默认处理器
Puma 是目前 Rack 中优先级最高的默认 webserver,如果直接使用 rackup 命令并且当前机器上安装了 puma,那么 Rack 会自动选择 Puma 作为当前处理 HTTP 请求的服务器:
Ruby
def self.default pick ['puma', 'thin', 'webrick']end
$ rackupPuma starting in single mode...* Version 3.10.0 (ruby 2.3.3-p222), codename: Russell's Teapot* Min threads: 0, max threads: 16* Environment: development* Listening on tcp://localhost:9292Use Ctrl-C to stop
复制代码
通过在 Rack::Handler 下创建一个新的 module Puma 再实现类方法 .run,我们就可以直接将启动的过程转交给 Puma::Launcher 处理:
Ruby
module Rack module Handler module Puma def self.run(app, options = {}) conf = self.config(app, options) events = options.delete(:Silent) ? ::Puma::Events.strings : ::Puma::Events.stdio launcher = ::Puma::Launcher.new(conf, :events => events)
yield launcher if block_given? begin launcher.run rescue Interrupt puts "* Gracefully stopping, waiting for requests to finish" launcher.stop puts "* Goodbye!" end end end endend
复制代码
启动器 Launcher
Puma 中的启动器确实没有做太多的工作,大部分的代码其实都是在做配置,从 ENV 和上下文的环境中读取参数,而整个初始化方法中需要注意的地方也只有不同 @runner 的初始化了:
Ruby
From: lib/puma/launcher.rb @ line 44:Owner: Puma::Launcher
def initialize(conf, launcher_args={}) @runner = nil @events = launcher_args[:events] || Events::DEFAULT @argv = launcher_args[:argv] || [] @config = conf @config.load
Dir.chdir(@restart_dir)
if clustered? @events.formatter = Events::PidFormatter.new @options[:logger] = @events
@runner = Cluster.new(self, @events) else @runner = Single.new(self, @events) end
@status = :runend
复制代码
在 #initialize 方法中,@runner 的初始化是根据当前配置中的 worker 数决定的,如果当前的 worker > 0,那么就会选择 Cluster 作为 @runner,否则就会选择 Single,在初始化结束之后会执行 Launcher#run 方法启动当前的 Puma 进程:
Ruby
From: lib/puma/launcher.rb @ line 165:Owner: Puma::Launcher
def run previous_env = ENV.to_h
setup_signals @runner.run
case @status when :halt log "* Stopping immediately!" when :run, :stop graceful_stop when :restart log "* Restarting..." ENV.replace(previous_env) @runner.before_restart restart! when :exit # nothing endend
复制代码
在这个简单的 #run 方法中,Puma 通过 #setup_singals 设置了一些信号的响应过程,在这之后执行 Runner#run 启动 Puma 的服务。
启动服务
根据配置文件中不同的配置项,Puma 在启动时有两种不同的选择,一种是当前的 worker 数为 0,这时会通过 Single 启动单机模式的 Puma 进程,另一种情况是 worker 数大于 0,它使用 Cluster 的 runner 启动一组 Puma 进程。
在这一节中文章将会简单介绍不同的 runner 是如何启动 Puma 进程的。
单机模式
Puma 单机模式的启动通过 Single 类来处理,而定义这个类的文件 single.rb 中其实并没有多少代码,我们从中就可以看到单机模式下 Puma 的启动其实并不复杂:
Ruby
From: lib/puma/single.rb @ line 40:Owner: Puma::Single
def run output_header "single"
if daemon? log "* Daemonizing..." Process.daemon(true) redirect_io end
load_and_bind @launcher.write_state @server = server = start_server
begin server.run.join rescue Interrupt # Swallow it endend
复制代码
如果我们启动了后台模式,就会通过 Puma 为 Process 模块扩展的方法 .daemon 在后台启动新的 Puma 进程,启动的过程其实和 Unicorn 中的差不多:
Ruby
From: lib/puma/daemon_ext.rb @ line 12:Owner: #<Class:Process>
def self.daemon(nochdir=false, noclose=false) exit if fork Process.setsid exit if fork
Dir.chdir "/" unless nochdir
if !noclose STDIN.reopen File.open("/dev/null", "r") null_out = File.open "/dev/null", "w" STDOUT.reopen null_out STDERR.reopen null_out end
0end
复制代码
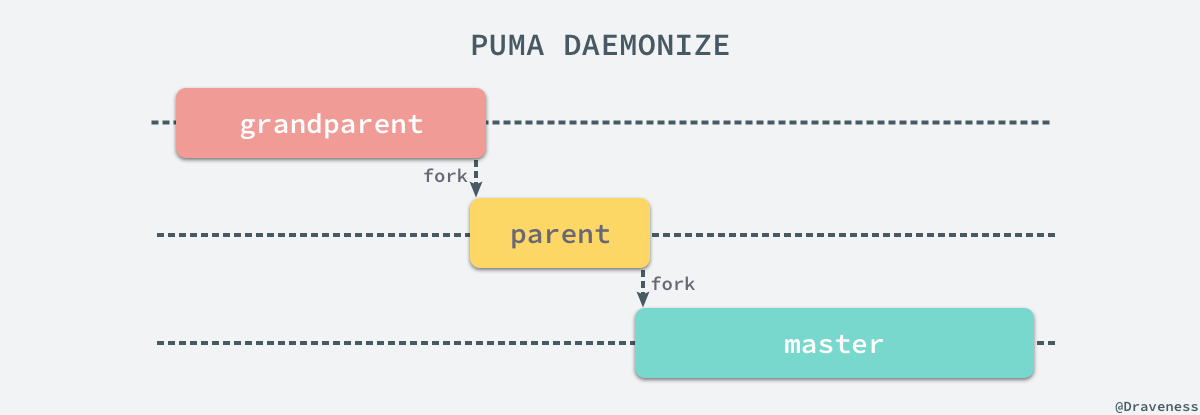
在 Puma 中通过两次 fork 同时将当前进程从终端中分离出来,最终就可以得到一个独立的 Puma 进程,你可以通过下面的图片简单理解这个过程:
当我们在后台启动了一个 Puma 的 master 进程之后就可以开始启动 Puma 的服务器了,也就是 Puma::Server 的实例:
Ruby
From: lib/puma/runner.rb @ line 151:Owner: Puma::Runner
def start_server min_t = @options[:min_threads] max_t = @options[:max_threads]
server = Puma::Server.new app, @launcher.events, @options server.min_threads = min_t server.max_threads = max_t server.inherit_binder @launcher.binder
if @options[:mode] == :tcp server.tcp_mode! end
unless development? server.leak_stack_on_error = false end
serverend
复制代码
这里有很多不是特别重要的代码,需要注意的是 Server 初始化的过程以及最大、最小线程数的设置,这些信息都是通过命令行或者配置文件传入的,例如 puma -t 8:32 表示当前的最小线程数为 8、最大线程数为 32 个,Puma 会根据当前的流量自动调节同一个进程中的线程个数。
服务在启动时会创建一个线程池 ThreadPool 并传入一个用于处理请求的 block,这个方法的实现其实非常长,这里省略了很多代码;
Ruby
From: lib/puma/server.rb @ line 255:Owner: Puma::Server
def run(background=true) queue_requests = @queue_requests
@thread_pool = ThreadPool.new(@min_threads, @max_threads, IOBuffer) do |client, buffer| process_now = false
begin if queue_requests process_now = client.eagerly_finish else client.finish process_now = true end rescue MiniSSL::SSLError, HttpParserError => e # ... rescue ConnectionError client.close else if process_now process_client client, buffer else client.set_timeout @first_data_timeout @reactor.add client end end end
if queue_requests @reactor = Reactor.new self, @thread_pool @reactor.run_in_thread end
@thread = Thread.new { handle_servers } @threadend
复制代码
上述代码创建了一个新的 Reactor 对象并在一个新的线程中执行 #handle_servers 接受客户端的请求,文章会在后面介绍请求的处理。
集群模式
如果在启动 puma 进程时使用 -w 参数,例如下面的命令:
$ puma -w 3[20904] Puma starting in cluster mode...[20904] * Version 3.10.0 (ruby 2.3.3-p222), codename: Russell's Teapot[20904] * Min threads: 0, max threads: 16[20904] * Environment: development[20904] * Process workers: 3[20904] * Phased restart available[20904] * Listening on tcp://0.0.0.0:9292[20904] Use Ctrl-C to stop[20904] - Worker 2 (pid: 20907) booted, phase: 0[20904] - Worker 1 (pid: 20906) booted, phase: 0[20904] - Worker 0 (pid: 20905) booted, phase: 0
$ ps aux | grep pumadraveness 20909 0.0 0.0 4296440 952 s001 S+ 10:23AM 0:00.01 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn pumadraveness 20907 0.0 0.1 4358888 12128 s003 S+ 10:23AM 0:00.07 puma: cluster worker 2: 20904 [Desktop]draveness 20906 0.0 0.1 4358888 12148 s003 S+ 10:23AM 0:00.07 puma: cluster worker 1: 20904 [Desktop]draveness 20905 0.0 0.1 4358888 12196 s003 S+ 10:23AM 0:00.07 puma: cluster worker 0: 20904 [Desktop]draveness 20904 0.0 0.2 4346784 25632 s003 S+ 10:23AM 0:00.67 puma 3.10.0 (tcp://0.0.0.0:9292) [Desktop]
复制代码
上述命令就会启动一个 Puma 的 master 进程和三个 worker 进程,Puma 集群模式就是通过 Puma::Cluster 类来启动的,而启动集群的方法 #run 仍然是一个非常长的方法,在这里仍然省去了很多的代码:
Ruby
From: lib/puma/cluster.rb @ line 386:Owner: Puma::Cluster
def run @status = :run
output_header "cluster" log "* Process workers: #{@options[:workers]}"
read, @wakeup = Puma::Util.pipe
Process.daemon(true) spawn_workers
begin while @status == :run begin res = IO.select([read], nil, nil, WORKER_CHECK_INTERVAL)
if res req = read.read_nonblock(1) result = read.gets pid = result.to_i
if w = @workers.find { |x| x.pid == pid } case req when "b" w.boot! when "t" w.dead! when "p" w.ping!(result.sub(/^\d+/,'').chomp) end else log "! Out-of-sync worker list, no #{pid} worker" end end
rescue Interrupt @status = :stop end end
stop_workers unless @status == :halt ensure read.close @wakeup.close endend
复制代码
在使用 #spawn_workers 之后,当前 master 进程就开始通过 Socket 监听所有来自 worker 的消息,例如当前的状态以及心跳检查等等。
#spawn_workers 方法会通过 fork 创建当前集群中缺少的 worker 数,在新的进程中执行 #worker 方法并将 worker 保存在 master 的 @workers 数组中:
Ruby
From: lib/puma/cluster.rb @ line 116:Owner: Puma::Cluster
def spawn_workers diff = @options[:workers] - @workers.size return if diff < 1
master = Process.pid
diff.times do idx = next_worker_index pid = fork { worker(idx, master) }
debug "Spawned worker: #{pid}" @workers << Worker.new(idx, pid, @phase, @options) endend
复制代码
在 fork 出的新进程中,#worker 方法与单机模式中一样都创建了新的 Server 实例,调用 #run 和 #join 方法启动服务:
Ruby
From: lib/puma/cluster.rb @ line 231:Owner: Puma::Cluster
def worker(index, master) title = "puma: cluster worker #{index}: #{master}" $0 = title
server = start_server server.run.joinend
复制代码
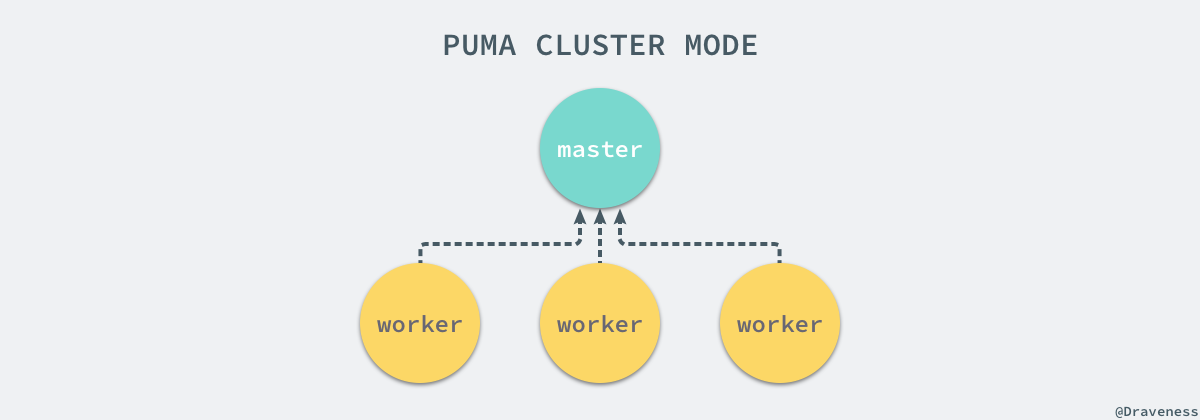
与 Unicorn 完全相同,Puma 使用了一个 master 进程来管理所有的 worker 进程:
虽然 Puma 集群中的所有节点也都是由 master 管理的,但是所有的事件和信号会由各个接受信号的进程处理的,只有在特定事件发生时会通知主进程。
处理请求
在 Puma 中所有的请求都是通过 Server 和 ThreadPool 协作来响应的,我们在 #handler_servers 方法中通过 IO.select 监听一组套接字上的读写事件:
Ruby
From: lib/puma/server.rb @ line 334:Owner: Puma::Server
def handle_servers begin sockets = @binder.ios pool = @thread_pool
while @status == :run begin ios = IO.select sockets ios.first.each do |sock| begin if io = sock.accept_nonblock client = Client.new io, @binder.env(sock) pool << client pool.wait_until_not_full end rescue Errno::ECONNABORTED io.close rescue nil end rescue Object => e @events.unknown_error self, e, "Listen loop" end end rescue Exception => e # ... endend
复制代码
当有读写事件发生时会非阻塞的接受 Socket,创建新的 Client 对象最后加入到线程池中交给线程池来处理接下来的请求。
Ruby
From: lib/puma/thread_pool.rb @ line 140:Owner: Puma::ThreadPool
def <<(work) @mutex.synchronize do if @shutdown raise "Unable to add work while shutting down" end
@todo << work
if @waiting < @todo.size and @spawned < @max spawn_thread end
@not_empty.signal endend
复制代码
ThreadPool 覆写了 #<< 方法,在这个方法中它将 Client 对象加入到 @todo 数组中,通过对比几个参数选择是否创建一个新的线程来处理当前队列中的任务。
重新回到 ThreadPool 的初始化方法 #initialize 中,线程池在初始化时就会创建最低数量的线程保证当前的 worker 进程中有足够的工作线程能够处理客户端的请求:
Ruby
From: lib/puma/thread_pool.rb @ line 21:Owner: Puma::ThreadPool
def initialize(min, max, *extra, &block) @mutex = Mutex.new
@todo = []
@spawned = 0 @waiting = 0
@min = Integer(min) @max = Integer(max) @block = block @extra = extra
@workers = []
@mutex.synchronize do @min.times { spawn_thread } endend
复制代码
每一个线程都是通过 Thread.new 创建的,我们会在这个线程执行的过程中执行传入的 block:
Ruby
From: lib/puma/thread_pool.rb @ line 21:Owner: Puma::ThreadPool
def spawn_thread @spawned += 1
th = Thread.new(@spawned) do |spawned| todo = @todo block = @block mutex = @mutex
extra = @extra.map { |i| i.new }
while true work = nil
continue = true
mutex.synchronize do work = todo.shift end
begin block.call(work, *extra) rescue Exception => e STDERR.puts "Error reached top of thread-pool: #{e.message} (#{e.class})" end end
mutex.synchronize do @spawned -= 1 @workers.delete th end end
@workers << th thend
复制代码
在每一个工作完成之后,也会在一个互斥锁内部使用 #delete 方法将当前线程从数组中删除,在这里执行的 block 中将客户端对象 Client 加入了 Reactor 中等待之后的处理。
Ruby
@thread_pool = ThreadPool.new(@min_threads, @max_threads, IOBuffer) do |client, buffer| begin client.finish rescue MiniSSL::SSLError => e # ... else process_client client, buffer endend
复制代码
如过当前任务不需要立即处理,就会向 Reactor 加入任务等待一段时间,否则就会立即由 #process_client 方法进行处理,其中调用了 #handle_request 方法尝试处理当前的网络请求:
Ruby
From: lib/puma/server.rb @ line 439:Owner: Puma::Server
def process_client(client, buffer) begin while true case handle_request(client, buffer) when false return when true return unless @queue_requests buffer.reset unless client.reset(@status == :run) client.set_timeout @persistent_timeout @reactor.add client return end end end rescue StandardError => e # ... ensure # ... endend
复制代码
用于处理网络请求的方法 #handle_request 足足有 200 多行,代码中处理非常多的实现细节,在这里实在是不想一行一行代码看过去,也就简单梳理一下这段代码的脉络了:
Ruby
From: lib/puma/server.rb @ line 574:Owner: Puma::Server
def handle_request(req, lines) env = req.env client = req.io
# ...
begin status, headers, res_body = @app.call(env)
headers.each do |k, vs| # ... end
fast_write client, lines.to_s res_body.each do |part| fast_write client, part client.flush end ensure body.close endend
复制代码
我们在这里直接将这段代码压缩至 20 行左右,你可以看到与其他的 webserver 完全相同,这里也调用了 Rack 应用的 #call 方法获得了一个三元组,然后通过 #fast_write 将请求写回客户端的 Socket 结束这个 HTTP 请求。
并发模型
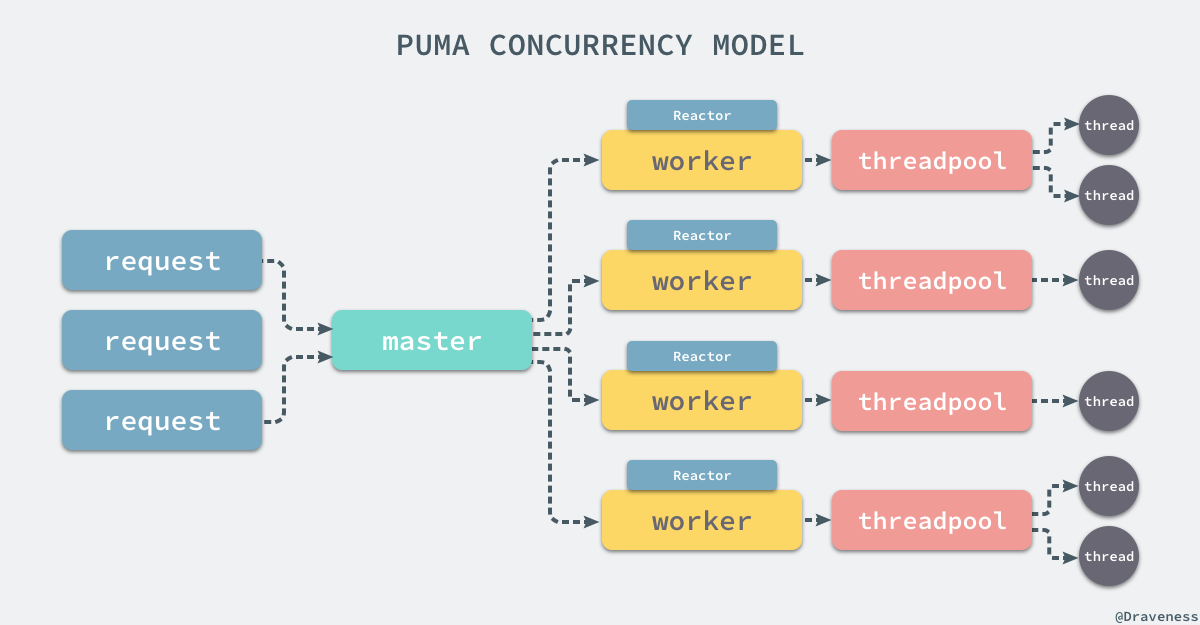
到目前为止,我们已经对 Puma 是如何处理 HTTP 请求的有一个比较清晰的认识了,对于每一个 HTTP 请求都会由操作系统选择不同的进程来处理,这部分的负载均衡完全是由 OS 层来做的,当请求被分配给某一个进程时,当前进程会根据持有的线程数选择是否对请求进行处理,在这时可能会创建新的 Thread 对象来处理这个请求,也可能会把当前请求暂时扔到 Reactor 中进行等待。
Reactor 主要是为了提高 Puma 服务的性能存在的产物,它能够让当前的 worker 接受所有请求并将它们以队列的形式传入处理器中;如果当前的系统中存在慢客户端,那么也会占用处理请求的资源,不过由于 Puma 是多进程多线程模型的,所以影响没有那么严重,但是我们也经常会通过反向代理来解决慢客户端的问题。
总结
相比于多进程单线程的 Unicorn,Puma 提供了更灵活的配置功能,每一个进程的线程数都能在一定范围内进行收缩,目前也是绝大多数的 Ruby 项目使用的 webserver,从不同 webserver 的发展我们其实可以看出混合方式的并发模型虽然实现更加复杂,但是确实能够提供更高的性能和容错。
Puma 项目使用了 Rubocop 来规范项目中的代码风格,相比其他的 webserver 来说确实有更好的阅读体验,只是偶尔出现的长方法会让代码在理解时出现一些问题。
相关文章
关于图片和转载
本作品采用知识共享署名 4.0 国际许可协议进行许可。
转载时请注明原文链接,图片在使用时请保留图片中的全部内容,可适当缩放并在引用处附上图片所在的文章链接,图片使用 Sketch 进行绘制,你可以在 [](https://draveness.me/draveness.me/sketch-sketch) 一文中找到画图的方法和素材。
复制代码
本文转载自 Draveness 技术博客。
原文链接:https://draveness.me/rack-puma


















评论