
背景介绍
近年来,在众多自然语言处理模型中最具有代表性的就是 BERT,它以优异的性能赢得了广大算法工程师的青睐。但是,在有些生产环境中,BERT 庞大的参数量不仅在推理时占用过多的计算资源,也不利于后续模型的扩展迭代。作业帮的业务体量较大,每天会生产大量的文本数据。这些数据均需要经过自然语言处理模型来生成业务可以直接使用的文本分类标签。在实际生产阶段,我们的场景具有如下特点:1.标签分了多期进行建设和产出,每期的标签在不同的场景有不同的阈值;2.每个时期的标签之间既存在独立性又存在依赖性;3.每个时期的有监督数据较少,一般的机器学习模型很难取得较好的线上效果,因此每一期的标签都是基于 BERT 进行 fine-tune 和部署。
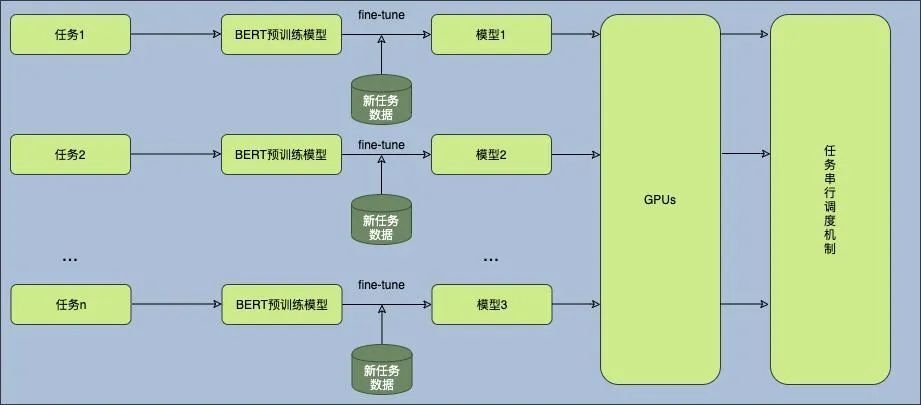
目前我们的模型训练及部署流程如上图所示。结合作业帮的实际业务场景特点和使用方式,我们面临如下问题: 1)每当新的任务需求提出后,都需要对 BERT 进行微调来满足。2)随着任务数量的增加,服务器上部署的 BERT 数量也会不断上升,导致占用较多的 GPU 计算资源,而且任务之间的调度也会变得更加复杂。因此,本文将以上述场景作为对象,探讨在研究平替 BERT 过程中的发现和结果,并对比它们的各项性能指标。最终目标是找到一个和 BERT 推理效果基本持平,但占用更少计算资源(特别是减少 GPU 计算资源),同时具有优秀扩展性的解决方案。
可行的替换方案
方案选择
为了减少计算资源,将 BERT 进行轻量化处理是一个不错的选择。目前主要的轻量化方法如下:知识蒸馏:知识蒸馏是一种教师-学生(Teacher-Student)训练结构,通常是使用训练好的教师模型提供知识,学生模型通过蒸馏训练来获取教师模型的知识。它能够以轻微的性能损失为代价,将复杂教师模型中蕴含的知识迁移到相对简单的学生模型中。剪枝:在不改变模型结构的情况下,去掉模型中作用较小的连接,从而减小模型的维度。量化:将高精度的参数类型转换为精度较低的参数类型,从而减小模型的尺寸和计算时间消耗。我们希望新模型不仅可以尽量接近 BERT 的推理效果,而且还能够显著减少推理时计算资源的消耗。因此,新模型需要具有以下特征:1.模型参数量少。这样有利于进行快速迭代,且有较快的推理速度。2.在文本分类任务上表现良好。考虑到生产环境中积累了大量的基于 BERT 的标签数据以及平替模型的特点,我们选用的方案是:结合知识蒸馏中 Teacher-Student 方式和主动学习的思路,使用 BERT 对 TextCNN 的推理结果进行筛选,并根据 TextCNN 的输出 loss 和概率分布,通过数据增强的方式迭代 TextCNN 的训练,从而使 TextCNN 的推理效果逼近 BERT。流程如下图所示:
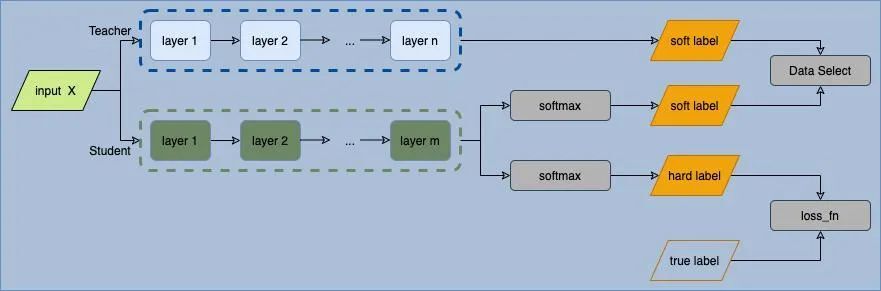
训练数据
作业帮的实际业务数据具有以下特征:a.在时间上呈现周期性;b.某些数据具有相同的表达范式;c.正负例样本之间存在较多的竞争性表述,如“表扬”相关的正例表述应该为“求表扬”,如“为什么我不在表扬榜上?”。而对于“谁在表扬榜”的表述则应该为负例;d.数据中的表情符号繁杂,具有某些特殊表情的数据可以代表某一类别;e.由于 ASR 或者 OCR 的识别精准度,会导致数据的质量较低。基于上面提到的特征,本文对数据进行了如下处理方式:1)拉取长时间范围内的数据,让时间范围尽量包括多个数据周期。2)为了保证训练数据的覆盖完整性,我们使用了如下采样方式:l 多样性抽样:根据标签的类别,使用 BERT 的[CLS]符号对不同的标签数据进行聚类,得到每个标签下不同表述的种子数据,再使用种子数据进行多样性抽样。l 随机抽样:对预处理后的语料进行随机抽样,保证训练数据的分布不会发生大的偏移。l 不确定性抽样:根据 BERT 预测的结果,筛选出模型决策边界附近的数据。对于这部分数据,如果在时间和人力成本允许的情况下,可以进行人工标注,否则直接将这部分数据直接舍弃。3)去重语句中多余的符号:对表情符号做分类统计,筛选出一些特殊的范式作为语料的前处理,对无用语料进行过滤(如在我们的实际生产环境中,可以直接将满足这些范式的句子标记成负例)。4)训练集的划分:训练集和测试集的划分最好在时间上有一定的隔离,比如测试集选用时间范围距离较近的数据,训练集则选用时间范围较远的数据,这样既可以验证数据对周期性,也可以测试模型的泛化能力。
训练方式

模型迭代训练的完整流程如上图所示:首先,训练基础的 TextCNN。然后,根据决策指标评估 TextCNN 模型。如果模型满足指标需求,则在替换 BERT 前我们还需要采样近七天的数据测试 TextCNN 的泛化能力。若不满足指标需求,则需要分析 TextCNN 输出的 loss 以及标签得分,确定下一轮训练数据的采样策略来有目的性的富集训练数据。最后,迭代上述流程,迭代的轮次可以根据预设的指标设置。
效果评估
评估指标
评价指标主要基于测试集数据,以 BERT 推理结果为金标准,对比 TextCNN 和 BERT 之间的差距,具体指标如下:
a.精准率:
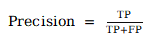
b.召回率:
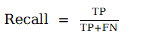
c.F1-score:
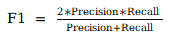
d.推理速度:
主要评估 TextCNN 在 CPU 环境下的运行速度。其中,对于 Preicison、Recall 的指标,均以 BERT 推理结果为基准计算。
效果评估
根据训练流程,我们可以观察某类标签在迭代三轮情况下,其指标的相关变化,如下表所示:
首先,在第一轮迭代时,使用和训练 BERT 一致的语料训练 TextCNN,其相关指标都比较低。我们对 loss 排序后筛选出来低分 loss 发现 TextCNN 容易陷入到某些关键词的表述中。如我们需要识别“求表扬”的数据,在结果数据中我们找到两个比较典型的例子:Ø“谁在表扬单上呢” vs. “表扬单上没有我呢”对于两个句子,我们真正要筛选出后者的表达方式。那么,前者是典型的竞争性负例。在实验过程中产生的更多句子中,我们发现 TextCNN 由于竞争性负例,出现了严重的过拟合现象。进一步地,本着将 TextCNN 逼近 BERT 的目标,我们对抽样好的数据分别使用训练好的 TextCNN 和 BERT 进行打分,然后对比两个模型的得分结果,并进行如下操作:1.对于一个样本,若 BERT 分数高于某阈值而 TextCNN 分数低于某阈值,那么就认为该样本为竞争性负例;2.将在 BERT 决策边界附近的样本直接舍弃(在条件允许的情况下,这部分数据可以在进行人工重新标注后再放回训练集中)在经过上述步骤之后,我们进行第二轮迭代。从指标结果上看,该步骤可以有效的提升 TextCNN 的精确率。由于模型的召回率还比较低。比如对于“求表扬”标签,我们对 BERT 的预测该类别[CLS]向量进行简单的聚类分析发现,这类标签的表述有:Ø“为什么我没上榜”Ø“为什么我不在表扬榜”Ø“为什么我没有小红花”Ø“怎么不夸我呢”Ø“表扬时,怎么没有念到我的名字”同样的,对比 TextCNN 的聚类结果,我们发现召回的数据大部分集中在某一两类的表述上。基于此,我们进行了第三轮迭代:使用[CLS]向量对训练数据进行了召回,发现确实存在表述不平衡的情况。因此,针对低召回的问题,我们使用多样性抽样的方式对不同的标签的进行了数据增强。实验结果表明可以有效的提升模型的召回率。
总结
总体流程可以分为训练 TextCNN 基础模型、提升 TextCNN 的精确率以及提升 TextCNN 的召回率三个主要部分。在每个流程部分中根据 loss 和模型输出的概率分布,针对不同问题采样不同的数据。在满足指标设定的前提下,让 TextCNN 逼近 BERT 的推理结果。在迭代过程中,我们舍弃了 BERT 决策边界附近的样本。从实际应用的角度考虑,这些数据基本也不会漏到下游的应用中,因此舍弃这部分样本也是合理的。在生产环境中还需要考虑一个问题是 TextCNN 输出概率阈值的设定。针对这个问题,我们拉取了不同日期的历史数据,在预设指标的情况下,动态的搜索了合理的阈值。
模型部署
由于生产环境中涉及的模型较多,因此需要考虑模型同时推理时带来的计算资源的负载均衡问题。我们使用了任务队列的方式部署模型:首先,根据不同模型的优先级配置不同任务的先后顺序;然后,对不同任务数量的运行进行压力测试,设置合理的任务并发数量。具体部署如下图所示:
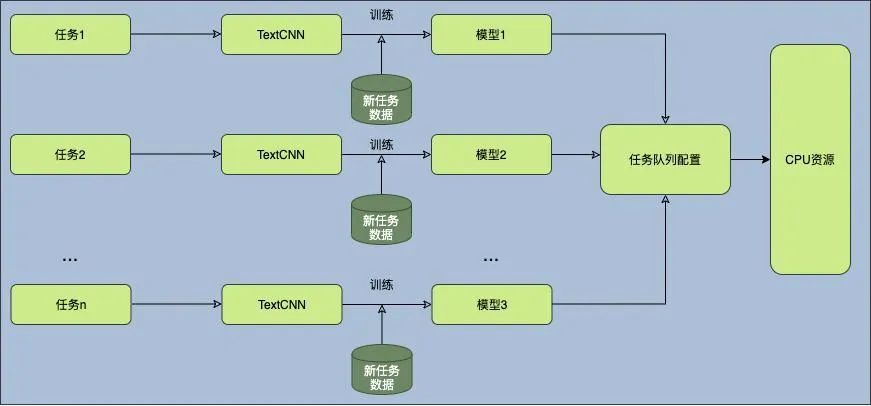
TextCNN 部署上线后,同一分类任务在不同的配置下,推理速度(服务平均吞吐能力)对比如下表所示。
(备注:本方案因为是离线处理模式,因此忽略单条数据处理时延指标,仅考虑整体吞吐能力)我们基于 400k~800k 的数据量,对比了如下几种部署方式的吞吐能力:lBERT@GPU:GPU(2080 Ti)单卡 lBERT@CPU:1 核 CPUlTextCNN@CPU:1 核、5 核、20 核从表中对比数据可以看出,TextCNN@CPU 的吞吐能力很强大。5 核 CPU 配置就可以接近 4.8 倍的 BERT@GPU(单卡)吞吐能力。而且在实际场景中,CPU 资源往往更廉价更容易扩容,可以轻松大幅缩短整体离线任务的处理时间。我们一个实际的线上任务,之前是 BERT@2GPU,需要耗时 2 个小时完成,平替为 TextCNN@20CPU 方案后,只需要 26 分钟左右即可完成。大幅提前了数据产出时间,为下游应用争取到了更多的时间窗口。
技术总结展望
本文涉及的场景具有以下三个主要的特征:1.有大量的历史数据积累,有利于采用不同的采样策略来针对性的增强训练数据;2.部署的 BERT 模型数量多,不利于后续标签的更新和维护。同时占用的 GPU 资源较多,不利于算力成本的维护;3.允许平替模型在指标上有较低的损失。因此,从场景特征出发,本文借鉴蒸馏中 Teacher-Student 的思想以及主动学习的方法,探索了 TextCNN 替换 BERT 的效果。经过几轮迭代后,平替版的 TextCNN 可以满足业务需求,释放了宝贵的 GPU 资源,处理时间大幅缩短,而且比较利于后续进一步扩展更多的文本分类任务。




