
1. 引言
Hibernate 是最流行的对象关系映射(ORM)引擎之一,它提供了数据持久化和查询服务。
在你的项目中引入 Hibernate 并让它跑起来是很容易的。但是,要让它跑得好却是需要很多时间和经验的。
通过我们的使用 Hibernate 3.3.1 和 Oracle 9i 的能源项目中的一些例子,本文涵盖了很多 Hibernate 调优技术。其中还提供了一些掌握 Hibernate 调优技术所必需的数据库知识。
我们假设读者对 Hibernate 有一个基本的了解。如果一个调优方法在 Hibernate 参考文档(下文简称 HRD)或其他调优文章中有详细描述,我们仅提供一个对该文档的引用并从不同角度对其做简单说明。我们关注于那些行之有效,但又缺乏文档的调优方法。
2.Hibernate 性能调优
调优是一个迭代的、持续进行的过程,涉及软件开发生命周期(SDLC)的所有阶段。在一个典型的使用 Hibernate 进行持久化的 Java EE 应用程序中,调优会涉及以下几个方面:
- 业务规则调优
- 设计调优
- Hibernate 调优
- Java GC 调优
- 应用程序容器调优
- 底层系统调优,包括数据库和 OS。
没有一套精心设计的方案就去进行以上调优是非常耗时的,而且很可能收效甚微。好的调优方法的重要部分是为调优内容划分优先级。可以用 Pareto 定律(又称“80/20 法则”)来解释这一点,即通常 80% 的应用程序性能改善源自头 20% 的性能问题 [5]。
相比基于磁盘和网络的访问,基于内存和 CPU 的访问能提供更低的延迟和更高的吞吐量。这种基于 IO 的 Hibernate 调优与底层系统 IO 部分的调优应该优先于基于 CPU 和内存的底层系统 GC、CPU 和内存部分的调优。
范例 1
我们调优了一个选择电流的 HQL 查询,把它从 30 秒降到了 1 秒以内。如果我们在垃圾回收方面下功夫,可能收效甚微——也许只有几毫秒或者最多几秒,相比 HQL 的改进,GC 方面的改善可以忽略不计。
好的调优方法的另一个重要部分是决定何时优化 [4]。
积极优化的提倡者主张开始时就进行调优,例如在业务规则和设计阶段,在整个 SDLC 都持续进行优化,因为他们认为后期改变业务规则和重新设计代价太大。
另一派人提倡在 SDLC 末期进行调优,因为他们抱怨前期调优经常会让设计和编码变得复杂。他们经常引用 Donald Knuth 的名言“过早优化是万恶之源” [6]。
为了平衡调优和编码需要一些权衡。根据笔者的经验,适当的前期调优能带来更明智的设计和细致的编码。很多项目就失败在应用程序调优上,因为上面提到的“过早优化”阶段在被引用时脱离了上下文,而且相应的调优不是被推迟得太晚就是投入资源过少。
但是,要做很多前期调优也不太可能,因为没有经过剖析,你并不能确定应用程序的瓶颈究竟在何处,应用程序一般都是这样演化的。
对我们的多线程企业级应用程序的剖析也表现出大多数应用程序平均只有 20-50% 的 CPU 使用率。剩余的 CPU 开销只是在等待数据库和网络相关的 IO。
基于上述分析,我们得出这样一个结论,结合业务规则和设计的 Hibernate 调优在 Pareto 定律中 20% 的那个部分,相应的它们的优先级更高。
一种比较实际的做法是:
- 识别出主要瓶颈,可以预见其中多数是 Hibernate、业务规则和设计方面的(其数量视你的调优目标而定;但三到五个是不错的开端)。
- 修改应用程序以便消除这些瓶颈。
- 测试应用程序,然后重复步骤 1,直到达到你的调优目标为止。
你能在 Jack Shirazi 的《Java Performance Tuning》 [7] 一书中找到更多关于性能调优阶段的常见建议。
下面的章节中,我们会按照调优的大致顺序(列在前面的通常影响最大)去解释一些特定的调优技术。
3. 监控和剖析
没有对 Hibernate 应用程序的有效监控和剖析,你无法得知性能瓶颈以及何处需要调优。
3.1.1 监控 SQL 生成
尽管使用 Hibernate 的主要目的是将你从直接使用 SQL 的痛苦中解救出来,为了对应用程序进行调优,你必须知道 Hibernate 生成了哪些 SQL。JoeSplosky 在他的《The Law of Leaky Abstractions》一文中详细描述了这个问题。
你可以在 log4j 中将org.hibernate.SQL包的日志级别设为 DEBUG,这样便能看到生成的所有 SQL。你还可以将其他包的日志级别设为 DEBUG,甚至 TRACE 来定位一些性能问题。
3.1.2 查看 Hibernate 统计
如果开启hibernate.generate.statistics,Hibernate 会导出实体、集合、会话、二级缓存、查询和会话工厂的统计信息,这对通过SessionFactory.getStatistics()进行的调优很有帮助。为了简单起见,Hibernate 还可以使用 MBean“org.hibernate.jmx.StatisticsService”通过 JMX 来导出统计信息。你可以在这个网站找到配置范例 。
3.1.3 剖析
一个好的剖析工具不仅有利于 Hibernate 调优,还能为应用程序的其他部分带来好处。然而,大多数商业工具(例如 JProbe [10])都很昂贵。幸运的是 Sun/Oracle 的 JDK1.6 自带了一个名为“Java VisualVM” [11] 的调试接口。虽然比起那些商业竞争对手,它还相当基础,但它提供了很多调试和调优信息。
4. 调优技术
4.1 业务规则与设计调优
尽管业务规则和设计调优并不属于 Hibernate 调优的范畴,但此处的决定对后面 Hibernate 的调优有很大影响。因此我们特意指出一些与 Hibernate 调优有关的点。
在业务需求收集与调优过程中,你需要知道:
- 数据获取特性包括引用数据(reference data)、只读数据、读分组(read group)、读取大小、搜索条件以及数据分组和聚合。
- 数据修改特性包括数据变更、变更组、变更大小、无效修改补偿、数据库(所有变更都在一个数据库中或在多个数据库中)、变更频率和并发性,以及变更响应和吞吐量要求。
- 数据关系,例如关联(association)、泛化(generalization)、实现(realization)和依赖(dependency)。
基于业务需求,你会得到一个最优设计,其中决定了应用程序类型(是 OLTP 还是数据仓库,亦或者与其中某一种比较接近)和分层结构(将持久层和服务层分离还是合并),创建领域对象(通常是 POJO),决定数据聚合的地方(在数据库中进行聚合能利用强大的数据库功能,节省网络带宽;但是除了像 COUNT、SUM、AVG、MIN 和 MAX 这样的标准聚合,其他的聚合通常不具有移植性。在应用服务器上进行聚合允许你应用更复杂的业务逻辑;但你需要先在应用程序中载入详细的数据)。
范例 2
分析员需要查看一个取自大数据表的电流 ISO(Independent System Operator)聚合列表。最开始他们想要显示大多数字段,尽管数据库能在 1 分钟内做出响应,应用程序也要花 30 分钟将 1 百万行数据加载到前端 UI。经过重新分析,分析员保留了 14 个字段。因为去掉了很多可选的高聚合度字段,从剩下的字段中进行聚合分组返回的数据要少很多,而且大多数情况下的数据加载时间也缩小到了可接受的范围内。
范例 3
过 24 个“非标准”(shaped,表示每小时都可以有自己的电量和价格;如果所有 24 小时的电量和价格相同,我们称之为“标准”)小时会修改小时电流交易,其中包括 2 个属性:每小时电量和价格。起初我们使用 Hibernate 的 _select-before-update_ 特性,就是更新 24 行数据需要 24 次选择。因为我们只需要 2 个属性,而且如果不修改电量或价格的话也没有业务规则禁止无效修改,我们就关闭了 _select-before-update_ 特性,避免了 24 次选择。
4.2 继承映射调优
尽管继承映射是领域对象的一部分,出于它的重要性我们将它单独出来。HRD [1] 中的第 9 章“继承映射”已经说得很清楚了,所以我们将关注 SQL 生成和针对每个策略的调优建议。
以下是 HRD 中范例的类图:
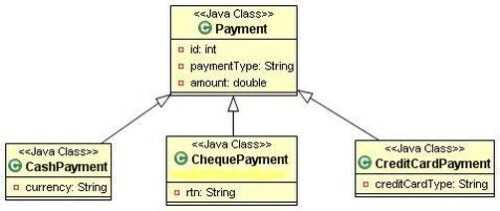
4.2.1 每个类层次一张表
只需要一张表,一条多态查询生成的 SQL 大概是这样的:
select id, payment_type, amount, currency, rtn, credit_card_type <b>from</b> payment
针对具体子类(例如 CashPayment)的查询生成的 SQL 是这样的:
select id, amount, currency <b>from</b> payment <b>where</b> payment_type=’CASH’
这样做的优点包括只有一张表、查询简单以及容易与其他表进行关联。第二个查询中不需要包含其他子类中的属性。所有这些特性让该策略的性能调优要比其他策略容易得多。这种方法通常比较适合数据仓库系统,因为所有数据都在一张表里,不需要做表连接。
主要的缺点整个类层次中的所有属性都挤在一张大表里,如果有很多子类特有的属性,数据库中就会有太多字段的取值为 null,这为当前基于行的数据库(使用基于列的 DBMS 的数据仓库处理这个会更好些)的 SQL 调优增加了难度。除非进行分区,否则唯一的数据表会成为热点,OLTP 系统通常在这方面都不太好。
4.2.2 每个子类一张表
需要 4 张表,多态查询生成的 SQL 如下:
<span color="#800000">select</span> id, payment_type, amount, currency, rtn, credit_card type, case when c.payment_id <span color="#800000"><b>is</b> <b>not</b> <b><span color="#0080ff">null</span></b> <b>then</b></span> 1 when ck.payment_id <span color="#800000"><b>is</b> <b>not</b> <b><span color="#0080ff">null</span></b> <b>then</b></span> 2 when cc.payment_id <span color="#800000"><b>is</b> <b>not</b> <b><span color="#0080ff">null</span></b> <b>then</b></span> 3 when p.id <span color="#800000"><b>is</b> <b>not</b> <b><span color="#0080ff">null</span></b> <b>then</b></span> 0 <span color="#800000"><b>end</b> <b>as</b></span> clazz <b><span color="#800000">from</span></b> payment p <span color="#800000"><b>left</b> <b>join</b></span> cash_payment c <b><span color="#800000">on</span></b> p.id=c.payment_id <span color="#800000"><b>left join</b></span> cheque_payment ck <b><span color="#800000">on</span></b> p.id=ck.payment_id <span color="#800000"><b>left</b> </span><b><span color="#800000">join</span> </b> credit_payment cc <b><span color="#800000">on</span></b> p.id=cc.payment_id;
针对具体子类(例如 CashPayment)的查询生成的 SQL 是这样的:
<span color="#800000">select</span> id, payment_type, amount, currency <b><span color="#800000">from</span></b> payment p <span color="#800000"><b>left</b> <b>join</b></span> cash_payment c <b><span color="#800000">on</span></b> p.id=c.payment_id;
优点包括数据表比较紧凑(没有不需要的可空字段),数据跨三个子类的表进行分区,容易使用超类的表与其他表进行关联。紧凑的数据表可以针对基于行的数据库做存储块优化,让 SQL 执行得更好。数据分区增加了数据修改的并发性(除了超类,没有热点),OLTP 系统通常会更好些。
同样的,第二个查询不需要包含其他子类的属性。
缺点是在所有策略中它使用的表和表连接最多,SQL 语句稍显复杂(看看 Hibernate 动态鉴别器的长 CASE 子句)。相比单张表,数据库要花更多时间调优数据表连接,数据仓库在使用该策略时通常不太理想。
因为不能跨超类和子类的字段来建立复合索引,如果需要按这些列进行查询,性能会受影响。任何子类数据的修改都涉及两张表:超类的表和子类的表。
4.2.3 每个具体类一张表
涉及三张或更多的表,多态查询生成的 SQL 是这样的:
<span color="#800000">select</span> p.id, p.amount, p.currency, p.rtn, p. credit_card_type, p.clazz <span color="#800000"><b>from</b> (<b>select</b></span> id, amount, currency, <b><span color="#0080ff">null</span></b> <b><span color="#800000">as</span></b> rtn,<b><span color="#0080ff">null</span></b> <b><span color="#800000">as</span></b> credit_card type, 1 <b><span color="#800000">as</span></b> clazz <b><span color="#800000">from</span></b> cash_payment <span color="#800000"><b>union</b> <b>all</b></span> <b><span color="#800000"> select</span></b> id, amount, <b><span color="#0080ff">null</span></b> <b><span color="#800000">as</span></b> currency, rtn,<b><span color="#0080ff">null</span></b> <b><span color="#800000">as</span></b> credit_card type, 2 <b><span color="#800000">as</span></b> clazz <b><span color="#800000">from</span></b> cheque_payment <span color="#800000"><b>union</b> <b>all</b></span> <b><span color="#800000"> select</span></b> id, amount, <b><span color="#0080ff">null</span></b> <b><span color="#800000">as</span></b> currency, <b><span color="#0080ff">null</span></b> <b><span color="#800000">as</span></b> rtn,credit_card type, 3 <b><span color="#800000">as</span></b> clazz <b><span color="#800000">from</span></b> credit_payment) p;
针对具体子类(例如 CashPayment)的查询生成的 SQL 是这样的:
<span color="#800000">select</span> id, payment_type, amount, currency <b><span color="#800000">from</span></b> cash_payment;优点和上面的“每个子类一张表”策略相似。因为超类通常是抽象的,所以具体的三张表是必须的 [开头处说的 3 张或更多的表是必须的],任何子类的数据修改只涉及一张表,运行起来更快。
缺点是 SQL(from 子句和 union all 子查询)太复杂。但是大多数数据库对此类 SQL 的调优都很好。
如果一个类想和 Payment 超类关联,数据库无法使用引用完整性(referential integrity)来实现它;必须使用触发器来实现它。这对数据库性能有些影响。
4.2.4 使用隐式多态实现每个具体类一张表
只需要三张表。对于 Payment 的多态查询生成三条独立的 SQL 语句,每个对应一个子类。Hibernate 引擎通过 Java 反射找出 Payment 的所有三个子类。
具体子类的查询只生成该子类的 SQL。这些 SQL 语句都很简单,这里就不再阐述了。
它的优点和上节类似:紧凑数据表、跨三个具体子类的数据分区以及对子类任意数据的修改都只涉及一张表。
缺点是用三条独立的 SQL 语句代替了一条联合 SQL,这会带来更多网络 IO。Java 反射也需要时间。假设如果你有一大堆领域对象,你从最上层的 Object 类进行隐式选择查询,那该需要多长时间啊!
根据你的映射策略制定合理的选择查询并非易事;这需要你仔细调优业务需求,基于特定的数据场景制定合理的设计决策。
以下是一些建议:
- 设计细粒度的类层次和粗粒度的数据表。细粒度的数据表意味着更多数据表连接,相应的查询也会更复杂。
- 如非必要,不要使用多态查询。正如上文所示,对具体类的查询只选择需要的数据,没有不必要的表连接和联合。
- “每个类层次一张表”对有高并发、简单查询并且没有共享列的 OLTP 系统来说是个不错的选择。如果你想用数据库的引用完整性来做关联,那它也是个合适的选择。
- “每个具体类一张表”对有高并发、复杂查询并且没有共享列的 OLTP 系统来说是个不错的选择。当然你不得不牺牲超类与其他类之间的关联。
- 采用混合策略,例如“每个类层次一张表”中嵌入“每个子类一张表”,这样可以利用不同策略的优势。随着你项目的进化,如果你要反复重新映射,那你可能也会采用该策略。
- “使用隐式多态实现每个具体类一张表”这种做法并不推荐,因为其配置过于繁缛、使用“any”元素的复杂关联语法和隐式查询的潜在危险性。
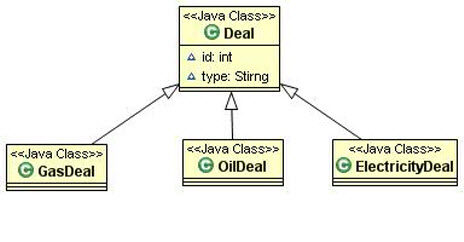
范例 4
下面是一个交易描述应用程序的部分领域类图:
开始时,项目只有 GasDeal 和少数用户,它使用“每个类层次一张表”。
OilDeal 和 ElectricityDeal 是后期产生更多业务需求后加入的。没有改变映射策略。但是 ElectricityDeal 有太多自己的属性,因此有很多电相关的可空字段加入了 Deal 表。因为用户量也在增长,数据修改变得越来越慢。
重新设计时我们使用了两张单独的表,分别针对气 / 油和电相关的属性。新的映射混合了“每个类层次一张表”和“每个子类一张表”。我们还重新设计了查询,以便允许针对具体交易子类进行选择,消除不必要的列和表连接。
4.3 领域对象调优
基于4.1**** 节中对业务规则和设计的调优,你得到了一个用 POJO 来表示的领域对象的类图。我们建议:
4.3.1 POJO 调优
- 从读写数据中将类似引用这样的只读数据和以读为主的数据分离出来。
只读数据的二级缓存是最有效的,其次是以读为主的数据的非严格读写。将只读 POJO 标识为不可更改的(immutable)也是一个调优点。如果一个服务层方法只处理只读数据,可以将它的事务标为只读,这是优化 Hibernate 和底层 JDBC 驱动的一个方法。 - 细粒度的 POJO 和粗粒度的数据表。
基于数据的修改并发量和频率等内容来分解大的 POJO。尽管你可以定义一个粒度非常细的对象模型,但粒度过细的表会导致大量表连接,这对数据仓库来说是不能接受的。 - 优先使用非 final 的类。
Hibernate 只会针对非 final 的类使用 CGLIB 代理来实现延时关联获取。如果被关联的类是 final 的,Hibernate 会一次加载所有内容,这对性能会有影响。 - 使用业务键为分离(detached)实例实现 equals() 和 hashCode() 方法。
在多层系统中,经常可以在分离对象上使用乐观锁来提升系统并发性,达到更高的性能。 - 定义一个版本或时间戳属性。
乐观锁需要这个字段来实现长对话(应用程序事务)[译注:session 译为会话,conversion 译为对话,以示区别]。 - 优先使用组合 POJO。
你的前端 UI 经常需要来自多个不同 POJO 的数据。你应该向 UI 传递一个组合 POJO 而不是独立的 POJO 以获得更好的网络性能。
有两种方式在服务层构建组合 POJO。一种是在开始时加 3.2 载所有需要的独立 POJO,随后抽取需要的属性放入组合 POJO;另一种是使用 HQL 投影,直接从数据库中选择需要的属性。
如果其他地方也要查找这些独立 POJO,可以把它们放进二级缓存以便共享,这时第一种方式更好;其他情况下第二种方式更好。
4.3.2 POJO 之间关联的调优
- 如果可以用 one-to-one、one-to-many 或 many-to-one 的关联,就不要使用 many-to-many。
- many-to-many 关联需要额外的映射表。
尽管你的 Java 代码只需要处理两端的 POJO,但查询时,数据库需要额外地关联映射表,修改时需要额外的删除和插入。 - 单向关联优先于双向关联。
由于 many-to-many 的特性,在双向关联的一端加载对象会触发另一端的加载,这会进一步触发原始端加载更多的数据,等等。
one-to-many 和 many-to-one 的双向关联也是类似的,当你从多端(子实体)定位到一端(父实体)。
这样的来回加载很耗时,而且可能也不是你所期望的。 - 不要为了关联而定义关联;只在你需要一起加载它们时才这么做,这应该由你的业务规则和设计来决定(见范例 ****5)。
另外,你要么不定义任何关联,要么在子 POJO 中定义一个值类型的属性来表示父 POJO 的 ID(另一个方向也是类似的)。 - 集合调优
如果集合排序逻辑能由底层数据库实现,就使用“order-by”属性来代替“sort”,因为通常数据库在这方面做得比你好。
集合可以是值类型的(元素或组合元素),也可以是实体引用类型的(one-to-many 或 many-to-many 关联)。对引用类型集合的调优主要是调优获取策略。对于值类型集合的调优,HRD [1] 中的 20.5 节“理解集合性能”已经做了很好的阐述。 - 获取策略调优。请见4.7节的范例5。
范例 5
我们有一个名为 ElectricityDeals 的核心 POJO 用于描述电的交易。从业务角度来看,它有很多 many-to-one 关联,例如和 Portfolio、Strategy 和 Trader 等的关联。因为引用数据十分稳定,它们被缓存在前端,能基于其 ID 属性快速定位到它们。
为了有好的加载性能,ElectricityDeal 只映射元数据,即那些引用 POJO 的值类型 ID 属性,因为在需要时,可以在前端通过 portfolioKey 从缓存中快速查找 Portfolio:
<span color="#0080ff"><property</span> <span color="#800000">name</span>=<i>"<span color="#0000ff">portfolioKey</span>"</i> <span color="#800000">column</span>=<span color="#0000ff"><i>"PORTFOLIO_ID" </i><span color="#800000">type</span>=<i>"</i>integer<i>"</i>/></span>这种隐式关联避免了数据库表连接和额外的字段选择,降低了数据传输的大小。
4.4 连接池调优
由于创建物理数据库连接非常耗时,你应该始终使用连接池,而且应该始终使用生产级连接池而非 Hibernate 内置的基本连接池算法。
通常会为 Hibernate 提供一个有连接池功能的数据源。Apache DBCP 的 BasicDataSource[13] 是一个流行的开源生产级数据源。大多数数据库厂商也实现了自己的兼容 JDBC 3.0 的连接池。举例来说,你也可以使用 Oracle ReaApplication Cluster [15] 提供的 JDBC 连接池 [14] 以获得连接的负载均衡和失败转移。
不用多说,你在网上能找到很多关于连接池调优的技术,因此我们只讨论那些大多数连接池所共有的通用调优参数:
- 最小池大小:连接池中可保持的最小连接数。
- 最大池大小:连接池中可以分配的最大连接数。
如果应用程序有高并发,而最大池大小又太小,连接池就会经常等待。相反,如果最小池大小太大,又会分配不需要的连接。 - 最大空闲时间:连接池中的连接被物理关闭前能保持空闲的最大时间。
- 最大等待时间:连接池等待连接返回的最大时间。该参数可以预防失控事务(runaway transaction)。
- 验证查询:在将连接返回给调用方前用于验证连接的 SQL 查询。这是因为一些数据库被配置为会杀掉长时间空闲的连接,网络或数据库相关的异常也可能会杀死连接。为了减少此类开销,连接池在空闲时会运行该验证。
4.5 事务和并发的调优
短数据库事务对任何高性能、高可扩展性的应用程序来说都是必不可少的。你使用表示对话请求的会话来处理单个工作单元,以此来处理事务。
考虑到工作单元的范围和事务边界的划分,有 3 中模式:
- 每次操作一个会话。每次数据库调用需要一个新会话和事务。因为真实的业务事务通常包含多个此类操作和大量小事务,这一般会引起更多数据库活动(主要是数据库每次提交需要将变更刷新到磁盘上),影响应用程序性能。这是一种反模式,不该使用它。
- 使用分离对象,每次请求一个会话。每次客户端请求有一个新会话和一个事务,使用 Hibernate 的“当前会话”特性将两者关联起来。
在一个多层系统中,用户通常会发起长对话(或应用程序事务)。大多数时间我们使用 Hibernate 的自动版本和分离对象来实现乐观并发控制和高性能。 - 带扩展(或长)会话的每次对话一会话。在一个也许会跨多个事务的长对话中保持会话开启。尽管这能把你从重新关联中解脱出来,但会话可能会内存溢出,在高并发系统中可能会有旧数据。
你还应该注意以下几点。
- 如果不需要 JTA 就用本地事务,因为 JTA 需要更多资源,比本地事务更慢。就算你有多个数据源,除非有跨多个数据库的事务,否则也不需要 JTA。在最后的一个场景下,可以考虑在每个数据源中使用本地事务,使用一种类似“Last Resource Commit Optimization”[16] 的技术(见下面的范例 ****6)。
- 如果不涉及数据变更,将事务标记为只读的,就像4.3.1**** 节提到的那样。
- 总是设置默认事务超时。保证在没有响应返回给用户时,没有行为不当的事务会完全占有资源。这对本地事务也同样有效。
- 如果 Hibernate 不是独占数据库用户,乐观锁会失效,除非创建数据库触发器为其他应用程序对相同数据的变更增加版本字段值。
范例 6
我们的应用程序有多个在大多数情况下只和数据库“A”打交道的服务层方法;它们偶尔也会从数据库“B”中获取只读数据。因为数据库“B”只提供只读数据,我们对这些方法在这两个数据库上仍然使用本地事务。
服务层上有一个方法设计在两个数据库上执行数据变更。以下是伪代码:
复制代码
因为insertBidRequestsInDatabaseB()是 saveIsoBids () 中的最后一个方法,所以只有下面的场景会造成数据不一致:
在 saveIsoBids() 执行返回时,数据库“A”的本地事务提交失败。
但是,就算 saveIsoBids() 使用 JTA,在两阶段提交(2PC)的第二个提交阶段失败的时候,你还是会碰到数据不一致。因此如果你能处理好上述的数据不一致性,而且不想为了一个或少数几个方法引入 JTA 的复杂性,你应该使用本地事务。
(未完待续)
关于作者
Yongjun Jiao是 SunGard Consulting Services 的技术主管。过去 10 年中他一直是专业软件开发者,他的专长包括 Java SE、Java EE、Oracle 和应用程序调优。他最近的关注点是高性能计算,包括内存数据网格、并行计算和网格计算。
Stewart Clark是 SunGard Consulting Services 的负责人。过去 15 年中他一直是专业软件开发者和项目经理,他的专长包括 Java 核心编程、Oracle 和能源交易。
[译注:由于原文较长,中译版分两次发布]
查看英文原文: Revving Up Your Hibernate Engine

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论