── 分布式计算开源框架 Hadoop 入门实践(一)
在 SIP 项目设计的过程中,对于它庞大的日志在开始时就考虑使用任务分解的多线程处理模式来分析统计,在我从前写的文章《Tiger Concurrent Practice -- 日志分析并行分解设计与实现》中有所提到。但是由于统计的内容暂时还是十分简单,所以就采用 Memcache 作为计数器,结合 MySQL 就完成了访问控制以及统计的工作。然而未来,对于海量日志分析的工作,还是需要有所准备。现在最火的技术词汇莫过于“云计算”,在 Open API 日益盛行的今天,互联网应用的数据将会越来越有价值,如何去分析这些数据,挖掘其内在价值,就需要分布式计算来支撑海量数据的分析工作。
回过头来看,早先那种多线程,多任务分解的日志分析设计,其实是分布式计算的一个单机版缩略,如何将这种单机的工作进行分拆,变成协同工作的集群,其实就是分布式计算框架设计所涉及的。在去年参加 BEA 大会的时候,BEA 和 VMWare 合作采用虚拟机来构建集群,无非就是希望使得计算机硬件能够类似于应用程序中资源池的资源,使用者无需关心资源的分配情况,从而最大化了硬件资源的使用价值。分布式计算也是如此,具体的计算任务交由哪一台机器执行,执行后由谁来汇总,这都由分布式框架的 Master 来抉择,而使用者只需简单地将待分析内容提供给分布式计算系统作为输入,就可以得到分布式计算后的结果。
Hadoop 是 Apache 开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如亚马逊、Facebook 和 Yahoo 等等。对于我来说,最近的一个使用点就是服务集成平台的日志分析。服务集成平台的日志量将会很大,而这也正好符合了分布式计算的适用场景(日志分析和索引建立就是两大应用场景)。
当前没有正式确定使用,所以也是自己业余摸索,后续所写的相关内容,都是一个新手的学习过程,难免会有一些错误,只是希望记录下来可以分享给更多志同道合的朋友。
什么是 Hadoop?
搞什么东西之前,第一步是要知道 What(是什么),然后是 Why(为什么),最后才是 How(怎么做)。但很多开发的朋友在做了多年项目以后,都习惯是先 How,然后 What,最后才是 Why,这样只会让自己变得浮躁,同时往往会将技术误用于不适合的场景。
Hadoop 框架中最核心的设计就是:MapReduce 和 HDFS。MapReduce 的思想是由 Google 的一篇论文所提及而被广为流传的,简单的一句话解释 MapReduce 就是“任务的分解与结果的汇总”。HDFS 是 Hadoop 分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce 从它名字上来看就大致可以看出个缘由,两个动词 Map 和 Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实在前面提到的多线程,多任务的设计就可以找到这种思想的影子。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。回到大学时期,教授上课时让大家去分析关键路径,无非就是找最省时的任务分解执行方式。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。(其实我一直认为 Hadoop 的卡通图标不应该是一个小象,应该是蚂蚁,分布式计算就好比蚂蚁吃大象,廉价的机器群可以匹敌任何高性能的计算机,纵向扩展的曲线始终敌不过横向扩展的斜线)。任务分解处理以后,那就需要将处理以后的结果再汇总起来,这就是 Reduce 要做的工作。
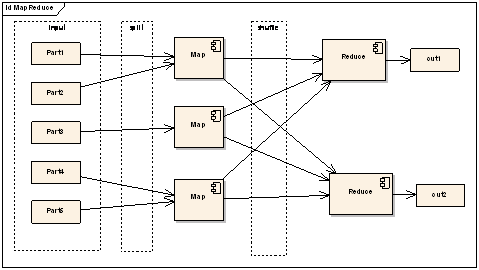
图 1:MapReduce 结构示意图上图就是 MapReduce 大致的结构图,在 Map 前还可能会对输入的数据有 Split(分割)的过程,保证任务并行效率,在 Map 之后还会有 Shuffle(混合)的过程,对于提高 Reduce 的效率以及减小数据传输的压力有很大的帮助。后面会具体提及这些部分的细节。
HDFS 是分布式计算的存储基石,Hadoop 的分布式文件系统和其他分布式文件系统有很多类似的特质。分布式文件系统基本的几个特点:
- 对于整个集群有单一的命名空间。
- 数据一致性。适合一次写入多次读取的模型,客户端在文件没有被成功创建之前无法看到文件存在。
- 文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且根据配置会由复制文件块来保证数据的安全性。
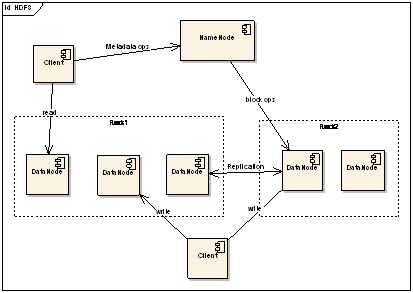
图 2:HDFS 结构示意图上图中展现了整个 HDFS 三个重要角色:NameNode、DataNode 和 Client。NameNode 可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode 会将文件系统的 Meta-data 存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在 DataNode 的信息等。DataNode 是文件存储的基本单元,它将 Block 存储在本地文件系统中,保存了 Block 的 Meta-data,同时周期性地将所有存在的 Block 信息发送给 NameNode。Client 就是需要获取分布式文件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。
文件写入:
- Client 向 NameNode 发起文件写入的请求。
- NameNode 根据文件大小和文件块配置情况,返回给 Client 它所管理部分 DataNode 的信息。
- Client 将文件划分为多个 Block,根据 DataNode 的地址信息,按顺序写入到每一个 DataNode 块中。
文件读取:
- Client 向 NameNode 发起文件读取的请求。
- NameNode 返回文件存储的 DataNode 的信息。
- Client 读取文件信息。
文件 Block 复制:
- NameNode 发现部分文件的 Block 不符合最小复制数或者部分 DataNode 失效。
- 通知 DataNode 相互复制 Block。
- DataNode 开始直接相互复制。
最后再说一下 HDFS 的几个设计特点(对于框架设计值得借鉴):
- Block 的放置:默认不配置。一个 Block 会有三份备份,一份放在 NameNode 指定的 DataNode,另一份放在与指定 DataNode 非同一 Rack 上的 DataNode,最后一份放在与指定 DataNode 同一 Rack 上的 DataNode 上。备份无非就是为了数据安全,考虑同一 Rack 的失败情况以及不同 Rack 之间数据拷贝性能问题就采用这种配置方式。
- 心跳检测 DataNode 的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
- 数据复制(场景为 DataNode 失败、需要平衡 DataNode 的存储利用率和需要平衡 DataNode 数据交互压力等情况):这里先说一下,使用 HDFS 的 balancer 命令,可以配置一个 Threshold 来平衡每一个 DataNode 磁盘利用率。例如设置了 Threshold 为 10%,那么执行 balancer 命令的时候,首先统计所有 DataNode 的磁盘利用率的均值,然后判断如果某一个 DataNode 的磁盘利用率超过这个均值 Threshold 以上,那么将会把这个 DataNode 的 block 转移到磁盘利用率低的 DataNode,这对于新节点的加入来说十分有用。
- 数据交验:采用 CRC32 作数据交验。在文件 Block 写入的时候除了写入数据还会写入交验信息,在读取的时候需要交验后再读入。
- NameNode 是单点:如果失败的话,任务处理信息将会纪录在本地文件系统和远端的文件系统中。
- 数据管道性的写入:当客户端要写入文件到 DataNode 上,首先客户端读取一个 Block 然后写到第一个 DataNode 上,然后由第一个 DataNode 传递到备份的 DataNode 上,一直到所有需要写入这个 Block 的 NataNode 都成功写入,客户端才会继续开始写下一个 Block。
- 安全模式:在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个 DataNode 上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
下面综合 MapReduce 和 HDFS 来看 Hadoop 的结构:
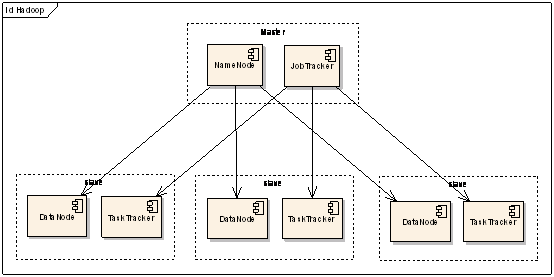
图 3:Hadoop 结构示意图
在 Hadoop 的系统中,会有一台 Master,主要负责 NameNode 的工作以及 JobTracker 的工作。JobTracker 的主要职责就是启动、跟踪和调度各个 Slave 的任务执行。还会有多台 Slave,每一台 Slave 通常具有 DataNode 的功能并负责 TaskTracker 的工作。TaskTracker 根据应用要求来结合本地数据执行 Map 任务以及 Reduce 任务。
说到这里,就要提到分布式计算最重要的一个设计点:Moving Computation is Cheaper than Moving Data。就是在分布式处理中,移动数据的代价总是高于转移计算的代价。简单来说就是分而治之的工作,需要将数据也分而存储,本地任务处理本地数据然后归总,这样才会保证分布式计算的高效性。
为什么要选择 Hadoop?
说完了 What,简单地说一下 Why。官方网站已经给了很多的说明,这里就大致说一下其优点及使用的场景(没有不好的工具,只用不适用的工具,因此选择好场景才能够真正发挥分布式计算的作用):
- 可扩展:不论是存储的可扩展还是计算的可扩展都是 Hadoop 的设计根本。
- 经济:框架可以运行在任何普通的 PC 上。
- 可靠:分布式文件系统的备份恢复机制以及 MapReduce 的任务监控保证了分布式处理的可靠性。
- 高效:分布式文件系统的高效数据交互实现以及 MapReduce 结合 Local Data 处理的模式,为高效处理海量的信息作了基础准备。
使用场景:个人觉得最适合的就是海量数据的分析,其实 Google 最早提出 MapReduce 也就是为了海量数据分析。同时 HDFS 最早是为了搜索引擎实现而开发的,后来才被用于分布式计算框架中。海量数据被分割于多个节点,然后由每一个节点并行计算,将得出的结果归并到输出。同时第一阶段的输出又可以作为下一阶段计算的输入,因此可以想象到一个树状结构的分布式计算图,在不同阶段都有不同产出,同时并行和串行结合的计算也可以很好地在分布式集群的资源下得以高效的处理。
相关阅读:
作者介绍:岑文初,就职于阿里软件公司研发中心平台一部,任架构师。当前主要工作涉及阿里软件开发平台服务框架(ASF)设计与实现,服务集成平台(SIP)设计与实现。没有什么擅长或者精通,工作到现在唯一提升的就是学习能力和速度。个人 Blog 为: http://blog.csdn.net/cenwenchu79 。
参与 InfoQ 中文站内容建设,请邮件至 editors@cn.infoq.com 。也欢迎大家到 InfoQ 中文站用户讨论组参与我们的线上讨论。




