

随着近几年好大夫在线全面转向微服务化,服务间调用复杂度急剧上升,故障难定位,技术债务难量化等相关问题随之而来,如服务稳定性没有统一衡量标准,服务容量配比是否合适等等。面对这些问题,好大夫在线基础架构部积极探索落地全链路监控系统,主要包括链路诊断、容量监控、应用运行时健康画像、实时告警及应用风险评估模型。本系列文章将从不同点切入,对好大夫在线落地全链路监控系统做一个介绍。
SRE(Site Reliability Engineering)在选择指标 SLI(Service Level Indicator)时,有四个黄金指标:延迟、流量、错误和饱和度(取自 Google SRE 的书籍)。
本期我们分析一下“延迟”指标如何作用于应用风险识别系统。
接口请求响应时间指示着应用单机峰值的 QPS/TPS(在机器硬件配置相同的情况下)。
响应越快能并发处理的用户请求也就越多,水平扩展时收益也越大,能减少获客成本和机器成本。
请求慢有很多因素,从用户角度来看,CDN 回源、css/js/html 渲染、网络抖动、微服务接口粒度过细、局域网内部请求过多、机器硬件、依赖中间件等等都会影响请求的耗时,接下来我们从微服务局域网请求角度来分析。
应用出现慢接口有哪些表现和危害
用户的耐心是有限的,过慢的请求,会流失用户,将用户导向响应更快的竞品;
php 应用会导致 php-fpm 进程数被耗尽,单机处理能力大幅度下降,请求会被积压,从而导致 QPS/TPS 下降,从而造成大量 5xx 错误;
线程、进程阻塞,应用 CPU 负载因为大量的 context 切换而飚高,导致应用响应越来越慢,甚至出现整个系统雪崩;
由于大量线程/进程变慢,资源没有及时释放,导致各种连接池、中间件等连接数被耗尽,触发过载保护,造成客户端连接断开,出现错误数据或者流程中断;
什么是慢接口(高延迟)?
慢接口:直观来看就是接口慢。那接口耗时多少算慢呢?统计接口平均耗时大于某个阈值?一次响应慢就算吗?
MessageQueue 消费事件算吗?定时任务里面的方法执行慢算吗?链路入口的慢接口又是如何判定的?基于这些疑问,我们根据经验总结出慢接口的具体说明。
慢接口:当服务发起方单次 RPC 请求响应耗时大于当前应用 95%请求耗时计数累加 1,一个分析周期后,当前应用累计数排名 TOPK 的接口标记为慢接口。
名词解释:
单次请求,指的是一个请求周期内的响应耗时,比如入口链路耗时时间就是处理完这次请求的总耗时,任何请求都是上游方法请求下游方法的聚合;
响应耗时 = 网络传输耗时 + 应用处理耗时;
每个应用职责不一样,所在链路位置也不一样,每个接口的耗时也不一样,如果取平均耗时,由于长尾效应,分析的数据会失真,根据公司现状分析,取 95%百分位的接口响应时间记为参考值;
为了避免网络抖动和消除突发异常,我们采用累计数,调用量大的系统,看累加总数,调用量小的看请求占比;
一个分析周期,也是为了消除抖动或者突发异常,目前我们采用一个小时为分析周期;
为什么不用平均耗时
因为通常对于延迟这个指标,我们不会直接做所有请求延迟的平均,因为整个延迟的分布也符合正态分布,所以通常会以类似 “90% 请求的延迟 <= 80ms,或者 95% 请求的延迟 <=120ms ”这样的方式来设定延迟 SLO(Service Level Objective) ,熟悉数理统计的同学应该知道,这个 90% 或 95% 我们称之为置信区间。
为什么每个应用的耗时指标设置不一样
由于每个系统目前的机器分布不均衡,调用量不相同,再加上历史遗留代码,改造成本也不一样。为了让优化收益最大化,我们目前的规则是:按应用内接口横向比较,取应用的 p95 耗时,再根据调用频率,优先改排名前 5 的接口。优化是一个持续的过程,如果所有的应用都卡一个指标去优化,对那些老系统来说,短期内很难达成目标。先优化收益高的任务,有效果了,再优化新生成的任务,形成积极的正反馈。
慢接口优化的 SLO
对延迟有一定了解之后,我们要怎么做呢,也就是说我们的目标是什么,延迟 SLO(Service Level Objective) 优化目标,根据前面的分析,我们选择为应用接口访问量大耗时大于当前应用 95%请求的接口。这样随着优化的进行,p95 在逐渐下降 等 p95 达标后,可以优化 p99,p99.9。
慢接口分析模型设计原理
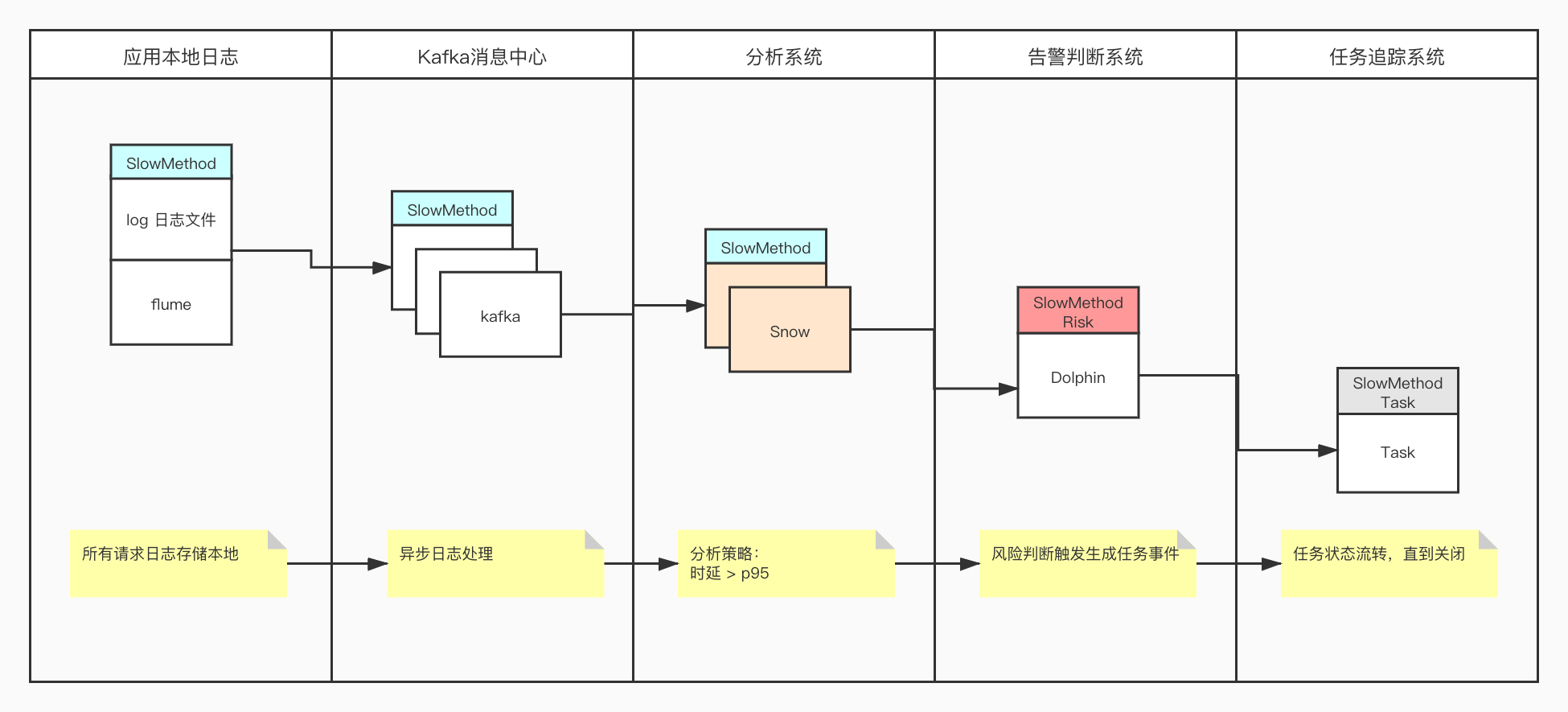
a. 日志存储本地磁盘,基于 Flume 异步收集,推送到 Kafka,日志分析系统 Snow(自研)订阅 Kafka 消息进行流式处理,准实时分析;
b. 每条日志携带的信息比较丰富,日志分析系统采用 Goroutine,按照目前定义的规则(如慢接口、异常事件、慢 SQL、循环远程调用等)进行并发分析;
c. 分析后,生成风险指标 Metrics,判断系统(Dolphin,见:好大夫在线监控系统答辩的 60 分钟)周期性拉取 Metrics 存入 Prometheus,通过预设的判定规则,触发生成风险事件;
d. Task 任务追踪系统(自研)订阅风险事件,生成可追踪的任务后,下发到各个事业部的开发人员名下(直接生成对应的 JIRA 任务);
e. 测试同学管理自己部门相关的改进任务 -> 开发同学进行优化后上线 -> 测试同学线上验证后关闭;
f. 整个流程从风险评估系统发起,到风险评估系统持续追踪验证,形成闭环;
宏观架构如下:
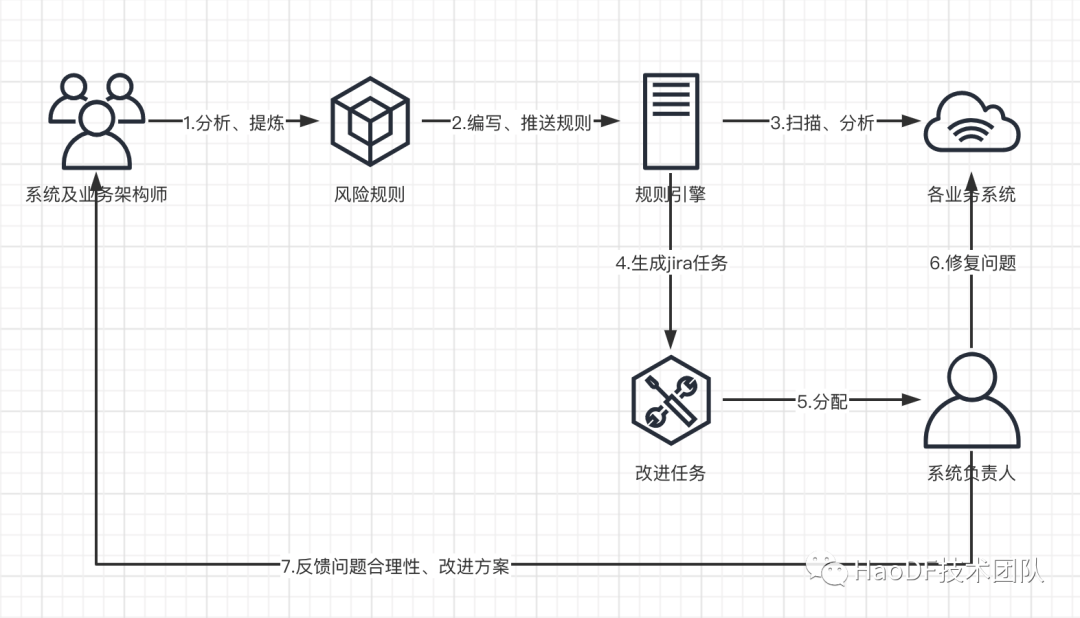
我们如何找到慢接口?
我们将所有 RPC 请求的耗时,记录到日志(从发出请求 到 接收到请求 一个来回),辅助诊断工具“APM 链路分析”,标注风险点。
任务是如何分配的
现在的风险评估模型,分析出来的任务都统一分配给了服务调用方,即分给了上游服务,我们认为,应用负责人应该感知自己调用下游的健康状态,对影响接口的因素要做到心中有数,如果链路跨度比较大, 比如 SystemA::methodA()调用 SystemB::methodB()而 SystemB::methodB()又调用了 SystemC::methodC(),如果 SystemC::methodC() 耗时超过 100ms。这时候 SystemA,SystemB,SystemC 都会生成任务,SystemA,SystemB 负载人 推动 SystemC 负责人 去优化 SystemC::methodC()。
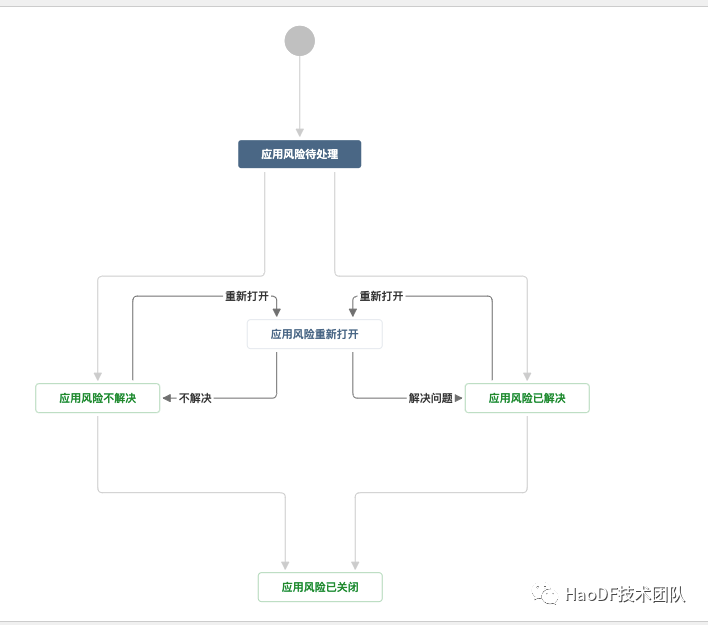
任务追踪系统状态流转
任务状态流转,从创建到关闭形成闭环:
任务优先级是如何划分的
每个应用面临的状态不一样,我们会优先选择收益高的慢接口生成任务,应用方再结合调用量,和修改难易程度和项目排期自己合理安排。
系统抖动产生的任务如何处理
由于网络抖动产生的临时事件,或者依赖的框架异常,中间件突发异常生成的任务,可以直接静默该任务,默认静默一个月。
如何处理(优化策略)
有些应用历史包袱比较重,调用跨度深,或者准备重构的均可以参考以下思路处理。
不管是重构还是要优化,先分析链路调用关系,画出时序图,看看依赖是否合理,应该能发现一些可优化项;
可以从产品层面思考一下,比如用户提交订单 在支付回调的过程中,给用户显示系统处理中页面,让同步请求转成异步请求,减少依赖;
分析慢接口的源头,基于时间线分布,查看是下游慢,还是自己当前应用处理逻辑慢;
判断是否依赖第三方接口,比如依赖微信,上传/下载附件等,考考是否转成异步处理;
是否存在循环调用,频繁的调用下游同一个方法除了徒劳浪费带宽外没啥意义;
是否存在多次依赖,这时候主要考虑是否存在接口粒度过细的情况,如果依赖下游方法过多可以考虑是否需要聚合,当然根据单一职责设计原则,不要盲目聚合;
调用跨度是否过大,RPC 请求如果链路超过 100 次,假设每次请求耗时 20ms,整条链路耗时也会超过 2000ms;
是否可以考虑并发请求,对于跨度大的,请求返回值不相互依赖的可以考虑并发请求;
片段缓存被穿透,导致出现慢 sql;
脚本或者 mq 消费者,大量并发操作中间件,导致中间件过载防护,或超载 阻塞连接或拒绝连接,考虑延迟消费,减少并发量,定时任务分片,分时段执行;
get 等幂等请求,是否考虑增加片段缓存;
对条件查询数据库的操作,是否可以转化为查询主键;
高频调用中间件,是否可以调整为批量操作,如批量发布消息,和 Redis 交互 增加 Pipline 减少网络 I/O;
查看应用依赖是否合理,基础应用不应该依赖高层应用,应用间的交互可以基于契约,高层应用也不直接依赖基础应用,大家通过异步回调实现;
代码组织形式是否合理,可以基于设计模式 重构代码,对接口做基准测试 对核心接口的 QPS/TPS 要做到心中有数;
优化的误区
为了减少并发,直接在程序中添加延迟因子,如 sleep(n)。
慢接口模型会分析出这类接口,在优化和平时写代码的时候一定要注意,如果要延迟处理部分逻辑。可以考虑提交事务后触发 mq 异步时间,如果是缓解并发问题可以利用加锁,而不是随机增加 sleep 时间。
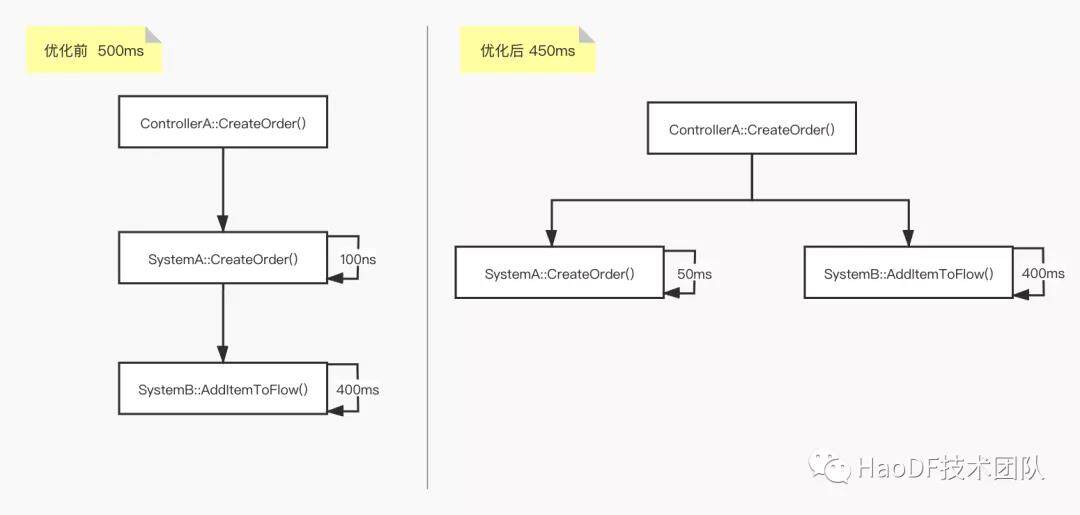
强制分离自己的业务领域职责,将自己的依赖的下游往上层抛,让前台代码变的臃肿无法维护,并且没有解决延迟慢的问题,只是将自己的问题抛给了上游调用方。
如 controller 层调用接单服务,优化后,本来 SystemB::AddItemToFlow() 属于 SystemA::CreateOrder()的领域逻辑,拆到 Controller 后,虽然 SystemA 健康了,但整个链路耗时依然很大,并且破坏了 SystemA 的领域逻辑。
盲目申请更大的缓存存储空间,由于数据冷热分布不均,缓存命中率低,扩大缓存后命中率没有显著提升,只会徒增机器成本。
比如按用户展示推荐文章列表,如果直接按入参设计片段缓存,由于 userid 不一样,会大量申请缓存,命中率没有提高,相当于每次还是直接查询数据库。
如何验证优化效果,应用变好或变坏的信号? 关注应用风险评估系统的每周周报,关注风险评级指标,关注优化后的 95 线趋势,以及优化后的任务是否被重新打开。
分析实战
为了方便大家持续跟进任务,我们开发任务跟进系统:“dany”,如下图:
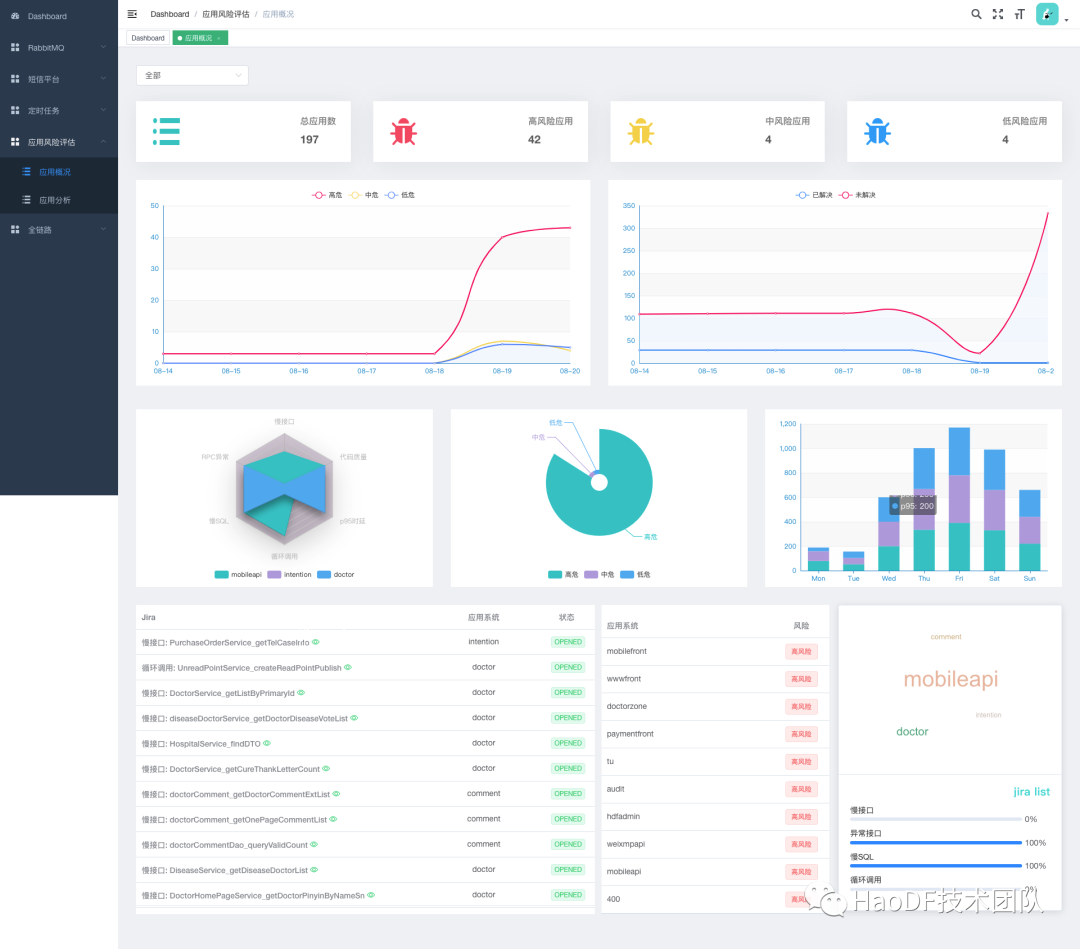
按事业部划分应用归属,既可以查看每个事业部的风险趋势,也可以选择自己应用的任务列表,选择慢接口类型,可以借助 APM 链路分析,更方便的定位问题,测试也可以根据任务状态推进开发优化。接下来我们具体来分析一个:
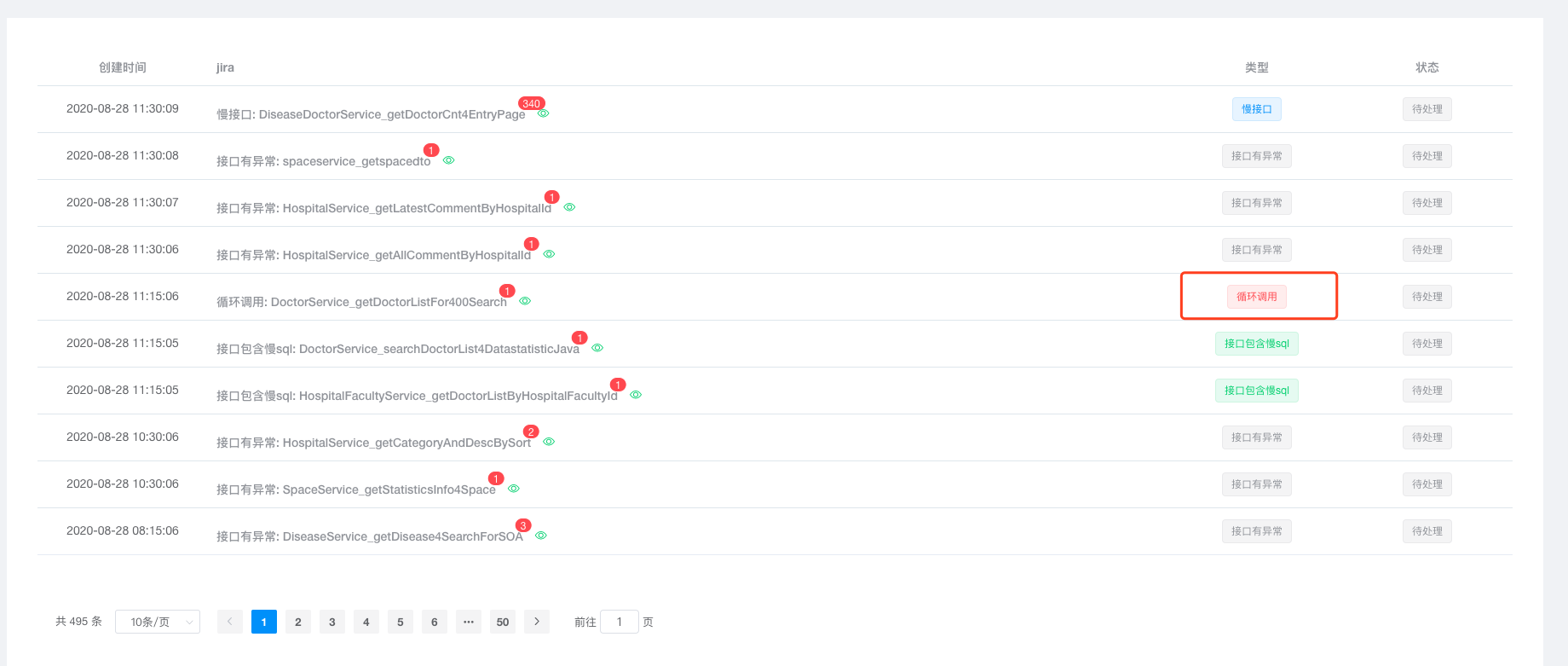
我们选一个循环调用的方法借助 APM 诊断工具,分析一下:
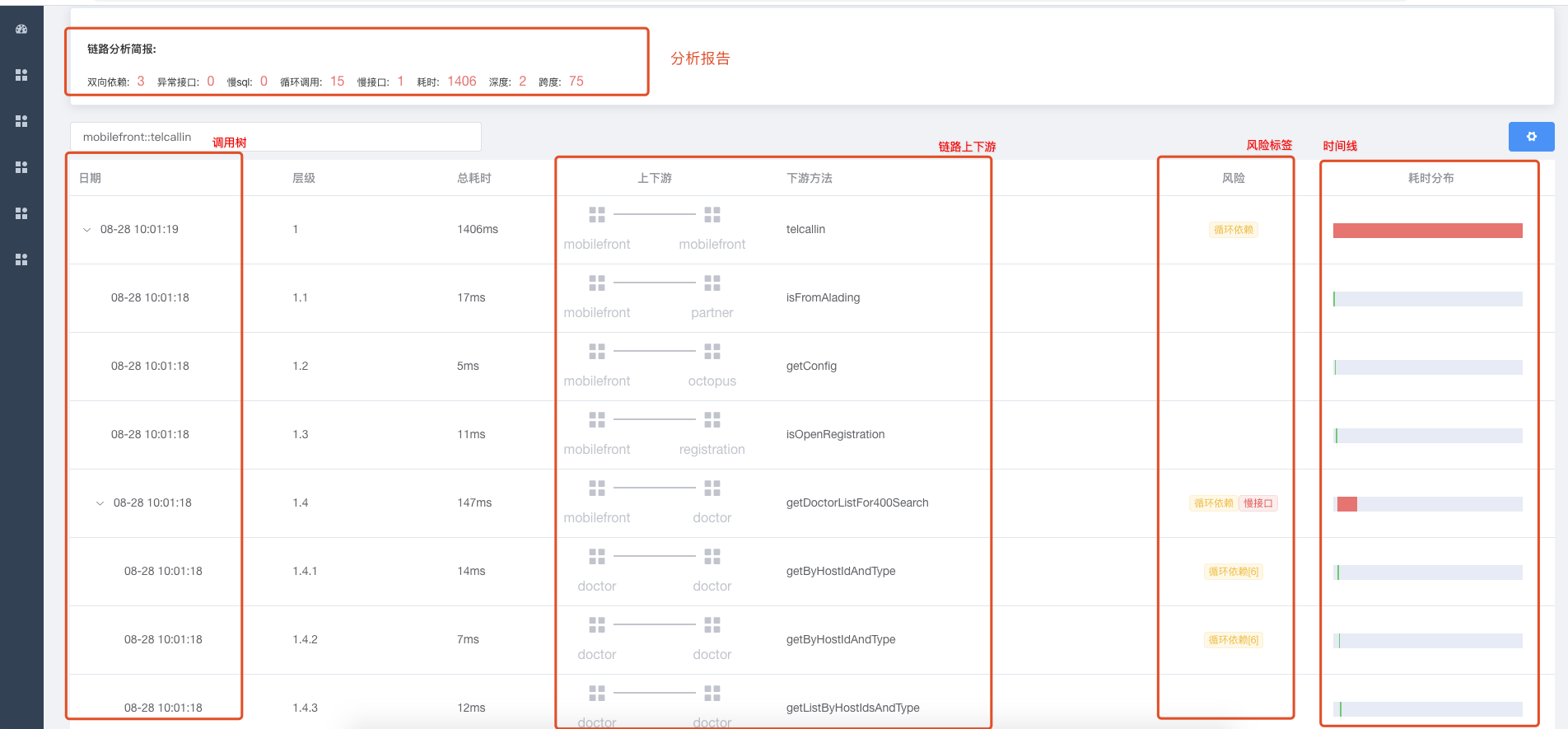
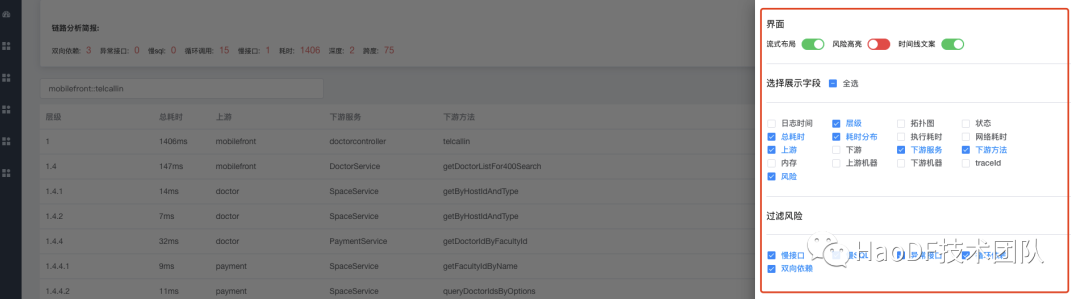
APM 诊断工具,会给出分析报告,绘出上下游拓扑图,绘出整个调用树,绘出每个方法的时间线,给不健康的方法加上标签 我们可以看出 这条链路中,存在 3 处双向依赖,循环调用 15 组,调用跨度 75,总耗时 1.4s 左右。为了更好的用户体验,我们对界面做了很多支持动态配置的功能,比如筛选指定的风险点。

具体到 1.4 这条链路中,我们可以看到总耗时 147ms。
两处循环调用 1.4.1 和 1.4.2 都是调用 getByHostIdAndType 总耗时 21ms,优化建议可以合并成一次请求。
双向依赖有三处 1.4.4 -> 1.4.4.1 -> 1.4.4.2,我们可以看出层级关系,上游发起请求后,下游又回调了上游应用,这种交叉依赖,很容易形成依赖环,从而导致交叉故障,更早的到达故障临界点。优化建议,聚合接口,上游一次性把参数传给下游,剪掉双向依赖。
从时间线外面可以判断出,下游调用时间 一共消耗 85ms, 去掉下游耗时,1.4 入口耗时 62ms,也就是说,入口方法本身还存在优化空间。
其他的风险点都可以采用类似的方法进行分析,从而制定自己的优化方案。
分析步骤总结
选择应用,查看任务,分析调用链;
分析链路每一个请求的时序图;
按风险进行过滤筛选;
分析耗时时间线;
找出主要可优化的点,然后去评估是否、如何去优化;
作者介绍:
方勇:好大夫在线系统开发工程师,专注于微服务、中间件的稳定性和可用性建设,整体负责好大夫风险评估系统的设计和搭建;
翟康奇:好大夫在线系统开发工程师,专注于分布式任务调度,RabbitMQ 高可用解决方案,负责全链路应用风险分析建模;
刘伟:好大夫在线系统开发工程师,主要负责统一推送平台,中间件运行时指标的监控挖掘及调优,主导 RabbitMQ 多集群管理平台建设。

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论 6 条评论