
自机器学习重新火起来,深度强化学习就一直是科研的一大热点,也是最有可能实现通用人工智能的一个分支。然而对于没有强化学习基础的同学们,如果直接去学习深度强化学习,想必会碰到很多问题。本文尝试普及一些最基础的强化学习算法,并以一个小例子来辅助大家理解。
问题定义
强化学习究竟研究的是一个什么样的问题,让其具有实现通用人工智能的潜力?
这个问题与我们认识世界的方式相关。我们都知道这个世界时刻在变化着,而每件事物的变化,势必是由其他一系列事物导致的。这就是我们所普遍认识的世界,一个由因果律定义的世界。由于因果律的存在,我们就有可能根据某个当前世界的状态,计算后一时刻世界的状态。
而我们人类,作为一个智能体,通过观察这个世界,并进行各种各样的自主行动,在这个世界中生存,并对其产生影响。通用人工智能的实现,就是期望能通过计算机模拟人类这样的智能体进行各种各样的行动决策。
为了简化问题,我们可以像下面这样建模这个世界和智能体。我们可以认为在某一个时刻整个世界处于状态 S1,当智能体进行了某一个行动之后,这个世界的状态变化为了 S2。智能体之所以能够做出这一行动,是因为其心中有一个目标,并且从这个世界中得到了一定的反馈。
举个例子。比如我们想要喝水(目标),身边有一个杯子和一个饮水机(状态 S1),我们会观察杯子和饮水机的位置,再伸手去拿取杯子(行动),然后将杯子靠近(反馈)饮水机,到达饮水机出水位置之后(状态 S2),饮水机开始出水,之后我们再将杯子举到嘴边就能喝到水了。这个简单的模型可以图示如下:
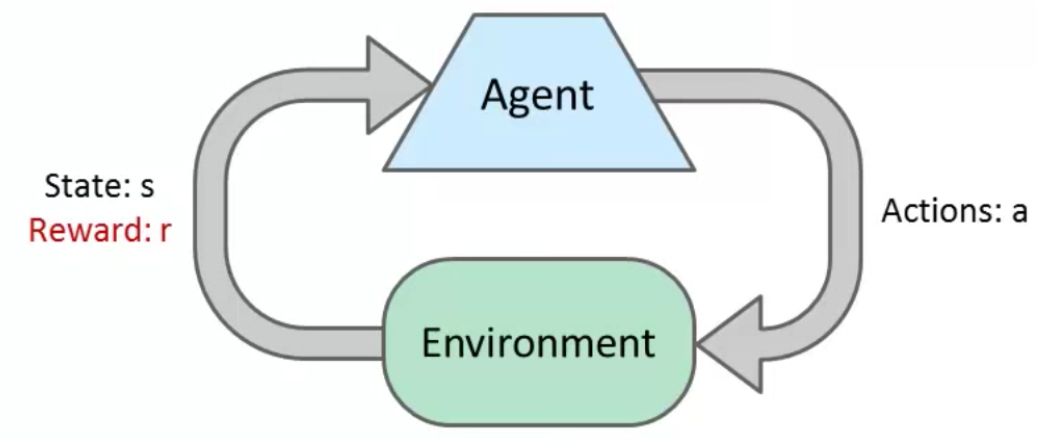
智能体(Agent)通过观察这个世界(Environment)的状态(State: s),经过智能决策,开展了一些行动(Actions: a),这些行动进而引起了这个世界的状态变化。智能体从这些变化的状态中获得关于之前行动的反馈(Reward: r),从而指导后续的行动决策。就这样,整个世界周而复始的一直循环下去。
从这个模型出发,由于因果律的存在,是不是知道了 S1 这个初始状态及智能体做出的行动 A 之后,我们就可以直接计算下一状态 S2 了呢?理论是可行的,但实际情况要更复杂一些,因为状态实在太多太多了,我们通常无法直接建模所有的状态。这时,我们可以用统计学的方式来解决这个问题。我们可以认为在我们做出某一行动之后,这个世界的状态只是有一定概率会转换为 S2,同时也有一定的概率会转换为 S2_1 等等。这样就算我们建模的状态不全,也可以相对较好的描述这个系统。
引入统计学的思维,也就引入了不确定性,虽然如此,但是却带来了更合理的描述系统的方式和系统层面的确定性。
以上描述的这一模型,在强化学习的世界里,我们称作 Markov 决策过程,简称 MDP(Markov Decision Process)。这里面的不确定性也就是 Markov 特性。
有了这个模型之后,我们就可以从数学上来研究这个问题了。强化学习研究的正是如何在这样的一个数学模型的基础上去实现一个有效的算法,进而实现智能决策。
一个小例子
我们可以设计一个简单的小游戏来辅助解决这个问题。
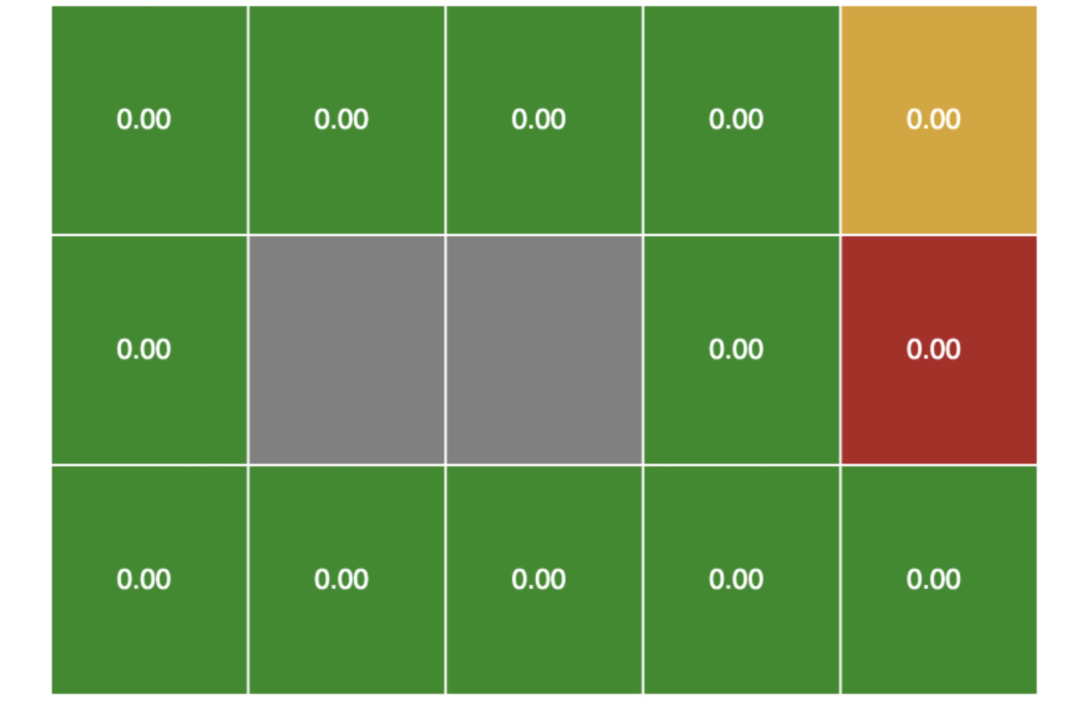
如上图,机器人(智能体)可以在这样的网格中移动:
绿色格子代表机器人可以移动到的位置
灰色格子表示有障碍物,机器人不能移动到那个位置
红色格子表示一个陷阱,如果机器人移动到此,游戏失败
黄色格子代表一个出口,如果机器人移动到此,游戏成功
这个游戏中的 MDP,可以描述为如下:
系统状态:格子位置,机器人位置
机器人可执行的动作:向上下左右四个方向移动
状态转换概率:如果机器人向某个方向移动,它移动到对应方向的格子的概率假设为 0.7(如果无法移动到对应方向的位置,则留在原格子的概率为 0.7),移动到其他位置的概率为 0.3/n,n 为其他可转换到的状态的数量。
状态转换概率举例如下(假设我们对格子进行编码,编码方式与 excel 表格的编码方式一致,从 A1 到 E3):
假设机器人在位置 A2,如果其向上移动,有 70%的概率会移动到 A1,分别有 15%的概率会移动到 A2(留在原位)和 A3
假设机器人在位置 A2,如果其向左或向右移动,有 70%的的概率会留在原位 A2,分别有 15%的概率会移动到 A1 和 A3
我们的算法要解决的问题是,在任意绿色格子里面放置一个机器人,算法可以指导机器人一步一步到达位置 E1(成功完成游戏)。
方案与算法
为了实现一个智能算法解决上述机器人走格子问题,我们可以考虑给每个格子定义一个价值。这个价值表示到达这个格子后有多大可能性能成功完成游戏。
观察这个游戏可以发现,D1 的价值应该高于 C1,C1 的价值应该高于 B1。
如果可以计算出每个格子的价值,我们是不是就解决了这个问题了呢?因为,无论机器人处于哪个位置,它只需要往价值比当前格子更高的格子方向走即可。
现在问题转化为如何定义和计算这个价值。
我们先将目标数值化。由于到达出口格子即成功,如果机器人能到达此处,我们就给智能体反馈奖励 1。同理,如果到达陷进格子,反馈奖励-1,到达绿色格子则奖励 0。
这个时候我们来看格子 D1。如果机器人在此处,它可以往四个方向移动。如果右移,有 70%的概率可以到达出口,获得奖励 1。如果往其他三个方向走,则分别有 10%的概率会到达出口,获得奖励 1。
经过以上的分析可以发现,我们其实可以将概率与奖励相乘来代表某个移动方向的价值。得到如下的价值数值:
向右移动:0.7 * 1 = 0.7
向上/下/左移动:0.1 * 1 = 0.1
这里的数值我们可以定义为动作价值。有了这个动作价值,要计算某个格子的价值,我们其实可以直接用最大的动作价值来表示,即:max([0.7, 0.1, 0.1, 0.1]) = 0.7。
如果要计算格子 C1 的价值呢?这时,虽然达到格子 D1 的奖励为 0,但是我们可以利用刚计算好的 D1 的价值。还是按照前面的方式进行计算:
向右移动:0.7 * (0 + 0.7) = 0.49
向上/下/左移动:0.1 * (0 + 0.7) = 0.07
格子价值:max([0.49, 0.07, 0.07, 0.07]) = 0.49
到这里,一个简单的算法呼之欲出。我们只需要找到所有有奖励的位置,然后从那里开始去计算其他所有位置的奖励,好像这个问题就解决了。
实际情况会稍微复杂一些。因为我们可能有很多个位置都存在奖励,而且这些奖励的多少可能由于任务定义而不一样。这里更实际一些的算法是利用多次迭代来实现。
为了不失一般性,我们可以定义公式:
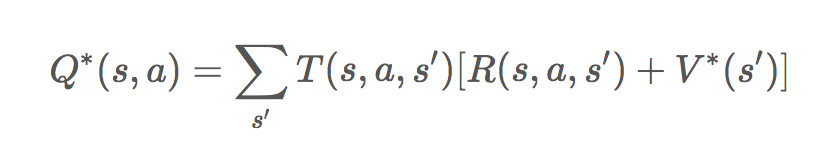
(表示每个动作的价值,其中:s 表示当前状态;a 表示动作;s'表示下一个状态;T(s, a, s')表示在状态 s,执行动作 a 转换到状态 s'的概率;R(s, a, s')表示表示在状态 s,执行动作 a 转换到状态 s'得到的奖励)
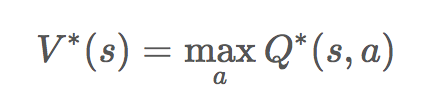
(表示每个格子的价值,其中:s 表示当前状态,a 表示动作)
一般而言,我们会引入一个额外的γ参数,对下一个状态的价值打一定的折扣,这是因为当前获得的奖励一般会优于下一个状态的价值的,毕竟下一个状态的价值只是一个估计值。这时,上述第一个公式变为:
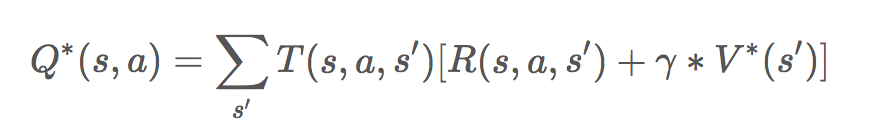
于是,我们的算法就可以描述为:* 对每一个状态,初始化 V := 0 * 循环,直到 V 收敛:* 对每一个状态,
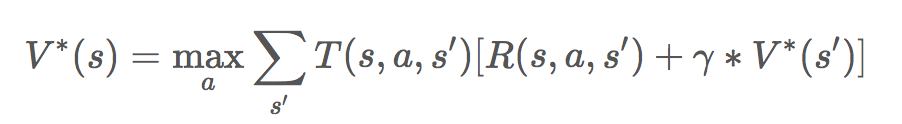
这里为判断 V 是否收敛,我们可以检查当前这次迭代是否会更新 V 的值。用 javascript 代码实现,主要代码如下:
MDPVISolver.solve = function () { var values = m.zeroArray([this.states.length]); var valuesNew = values; var iterations = 0; do { var qValuesAll = []; values = valuesNew; valuesNew = []; for (var i = 0; i < this.states.length; i++) { var state = this.states[i]; var qValues = this.qValues(values, state); qValuesAll.push(qValues); var value = this.value(qValues); valuesNew.push(value); } console.log('finished iteration ' + (++iterations)); // console.log('values: ', values); } while(!this.converged(values, valuesNew)); ...}这里我已经实现了上述的游戏的一个 Demo,见这里(http://brightliao.com/examples/mdp/grid-world.html),完整代码见这里(https://github.com/gmlove/gmlove.github.io/blob/source/source/examples/mdp/grid-world.js)865 行到 890 行。
上述算法就是强化学习里面的经典算法 价值迭代 算法了。而我们上面定义 V 的迭代形式的公式就是著名的 Bellman 公式了,其最初由 Richard Bellman 提出。
另一个思路
上述算法存在一个问题,我们最后得到的是一系列状态价值(每个格子的价值),为了得到我们想要的行动,我们还需要根据根据状态价值,计算行动价值,即上述 Q(s, a)。使用上有所不便。
那么有没有办法改进呢?再来思考一下这个问题的目标,实际上我们想要找到一种指导机器人行动的策略。这里的策略可以表示为:在任意一个位置,算法可以给出一个恰当的行动。
我们能不能直接去衡量某一个策略的价值呢?因为一旦有了这个策略的价值,我们就可以考虑直接去优化这个策略,而不是去对所有的状态计算价值。
对于某一策略,由于其可以基于当前状态指导我们作出行动,我们可以定义它为一个 输入为状态 输出为行动 的函数,即π: a = π(s)
既然这样,参考价值迭代算法中的状态价值(格子价值)定义,我们可以定义策略价值函数为:
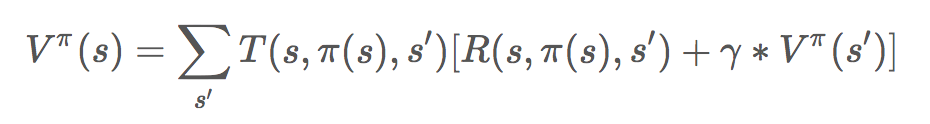
(策略π的价值,其中:s 表示当前状态;a = π(s)表示动作;s'表示下一个状态;T(s, π(s), s')表示在状态 s,执行动作 a=π(s)转换到状态 s'的概率;R(s, π(s), s')表示在状态 s,执行动作 a=π(s)转换到状态 s'得到的奖励)
上面的公式是一个迭代形式的定义,既然如此,我们可以参考之前的状态价值迭代算法,迭代计算这个策略的价值,最后这个价值可能会收敛到某个具体的值。
然而就算可以计算策略的价值,我们如何得到一个有效的策略呢?如果没有策略,其实也无从计算其价值。
能不能随机初始化一个策略?在这基础上计算其价值,进而得到更好的策略。
对于以上解决问题的思路,我第一次看到的时候,也不禁暗暗赞叹。事实上,这就是我这里想要给大家介绍的另一个强化学习经典算法:策略迭代 算法。
如何根据一个策略寻找更优策略?可以这样做:
计算在当前策略下,哪一个行动能得到最大价值
选择价值最大的行动作为新策略的行动
用公式表述如下:
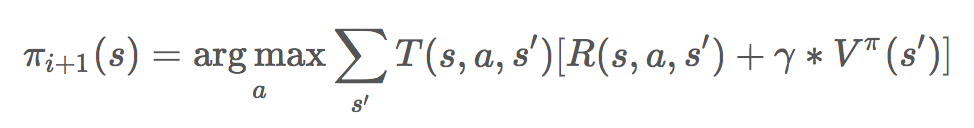
(下一个(第 i+1 个)更优策略π(i+1),其中:s 表示当前状态;a = π(s)表示动作;s'表示下一个状态;T(s, a, s')表示在状态 s,执行动作 a 转换到状态 s'的概率;R(s, a, s')表示在状态 s,执行动作 a 转换到状态 s'得到的奖励)
到这里,这个 策略迭代 算法就差不多完成了。用 JavaScript 代码实现,主要代码如下:
MDPPISolver.solve = function () { var policy = this.randomPolicy(); var policyNew = policy; do { policy = policyNew; values = this.solveForPolicy(policy); policyNew = this.improvePolicy(values, policy); } while (!this.converged(policy, policyNew)); ...}完整代码见这里(https://github.com/gmlove/gmlove.github.io/blob/source/source/examples/mdp/grid-world.js)932 行到 1024 行。
扩展
状态空间降维
虽然我们可以用上述两个经典算法解决这个问题,但是它们的效率是很低的,算法复杂度用大 O 计算法可以表示为 O(ass)。对于这个非常简单的问题,计算速度尚能接受,但是如果我们考虑一些更复杂的问题,就会发现这里的状态 s 的取值空间可能会非常大。
比如对于下面这个吃豆子的游戏,这里的状态数量为:
状态数量 = 格子数量 * N (N 为每个格子的可能状态:比如是否有吃豆人、是否有豆子、是否有敌人及敌人的类型等等)

过大的状态空间就导致上述经典算法实际无法执行,也就无法满足实际需求。
一个可能的优化手段是人为的设计一些特征来表示某个状态 s,这样就实现了对 s 进行降维的操作。比如对于上面吃豆子的游戏,我们可以建模这样几个特征:
离最近的豆子的方向和距离
离每个敌人的方向和距离
敌人的移动速度和方向
有了这样的很小的状态空间,上述算法就可以执行了。
深度强化学习 DQN
有了上述状态空间降维的办法,我们可以考虑是不是可以用一个深度神经网络来替代人工特征的过程呢?当然是可以的,这就是前几年 Deep Mind 轰动学界和产业界的关于 深度强化学习 的论文中的内容了。
DQN 的全称是 Deep Q-Network,它的核心是一个 Q 值迭代的算法。Q 值迭代公式就是我们 价值迭代 公式中的关于行动价值的公式的一个迭代形式。算法也是不断迭代直到收敛。
我在另一篇文章中有关于 DQN 的更多内容。详情见这里(http://brightliao.com/2016/12/05/let-machine-play-games/)。
更多的问题
考虑一个更实际的问题,上述经典算法假设我们知道了状态转移函数 T。但实际上当前世界可能对于我们是全新的,T 对于我们而言当然也是未知的。这个时候有什么办法呢?一个简单的思路是我们可以通过不断在这个世界中进行探索,去了解这个世界的运作方式,也就是不断的弄清了这个 T 函数。在强化学习的研究中,抽象一下这个过程,即通过不断采样来近似估计 T 函数。
另一个实际的问题是,有时候我们可能无法执行这么多次探索,或者每次探索的成本太高以至于负担不起。这时,一个有效的思路是,我们可以从别人的经验中学习,或者通过看电影读书进行学习。当前的强化学习方法也在这个方向上进行了很多探索。
对于如何高效的进行学习,还有一个思路,那就是我们能否模仿某个已有的不错的行动策略呢?比如,假设我们希望训练机器人做家务,那么是不是可以通过演示一遍给机器人看,然后机器人通过模仿进行学习呢?这就是模仿学习思路去解决这个问题。
关于这个领域,我们还可以想出更多的问题,比如,如何让机器人自己去探索解决问题的方法?如何处理连续的动作(文章开始时提到的喝水的例子,这里移动双手的过程其实就是连续动作决策的过程)?如何自动设置奖励甚至不设置奖励?很多越来越难问题被一个一个提出,同时又正在被不断提出的新思路一个一个攻克。
总结
总结起来,强化学习其实就是关于如何学习的研究。这个领域发展至今能解决的问题还比较有限,我们离最终的通用人工智能的路还很长。同时,很多新的有挑战性的问题不断被提出来,被大家研究,很多创新的解决问题的思路也不断被发掘出来。正是我们对这个领域充满热情,才推动了这个领域如此蓬勃的发展。相信终有一天这个问题能被我们人类攻克。
本文转载自:ThoughtWorks 洞见(ID:TW-Insights)
原文链接:强化学习入门——说到底研究的是如何学习




