

最近几年,云的出现以及企业纷纷向互联网转型导致了数据大爆炸。因此,数据科学家在市场上供不应求。据《哈佛商业评论》称,21 世纪数据科学家是最性感的职业。他们每天畅游在大数据的海洋里,与 AI 和深度学习为伴,探索并发现撬动世界变革的力量。 而在真正的数据科学家眼中,他们对自己的认知却与外界有所不同,本文就是一位数据科学家的自白。
过去 5 年,我一直从事“ 数据科学家 ”这个工作,人们都觉得这个工作“很性感”,但其实我始终弄不明白到底哪儿“性感”。可能除了我新烫的头发看起来有点像韩国欧巴外,其他的都和性感这个词不沾边儿。
那么,我就先来为大家揭秘数据科学家每天要做的工作有哪些?
通过分析 LinkedIn 上的职位发布,我得出了以下内容,我总结了一些最为日常的工作内容:
了解业务和客户,对假设问题进行验证;
建立预测模型和机器学习流水线,进行 A / B 测试;
历史数据的分析挖掘:包括跟各种产品线相关的业务分析,用户画像,用户行为分析,用户留存分析等;
开发算法为业务线赋能;
进行实验并研究新技术和方法,提高技术能力;
这些工作听起来是不是很性感?
而这些,仅仅是数据科学家工作的“冰山一角”。
在 CrowdFlower 的一份调查中揭露了数据科学家每天的日常工作:
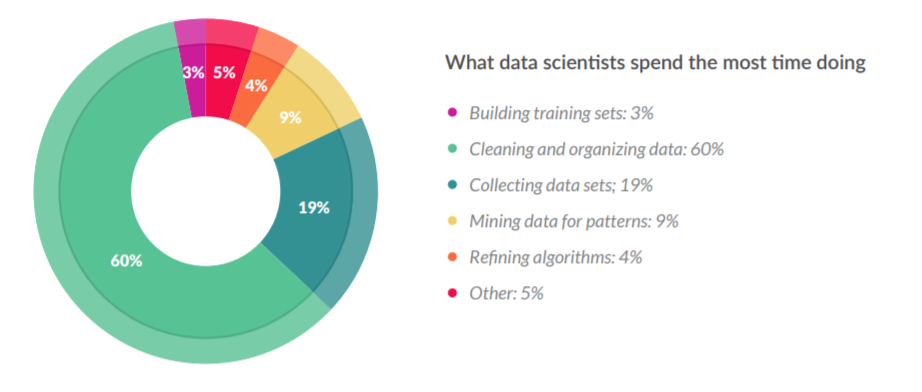
通常,我们认为数据科学家每天都在构建算法、研究数据并进行预测分析。从上表中可以看出,这并不是他们的主要工作内容,实际上,他们大部分时间都在收集数据集、清理和管理数据。
为什么需要高效的数据清理专家?
数据湖是存储公司所有数据的集中存储库。企业或组织可以使用数据湖中的数据来构建机器学习模型。但令人不解的是,有人把数据湖当成了数据存储中转站,或者是超大硬盘。
许多组织最初实施数据湖时,对如何处理收集中的数据一无所知。他们不明就里地去收集一切数据,根本不去考虑其实际用途。尽管数据湖的核心作用是将公司的所有数据集中在一个地方,但需要根据特定的项目需求对数据湖进行定制化设计。不进行合理规划就像创建一个新的“未命名文件夹 ”,然后在其中复制并粘贴公司所有数据,到头来只会变为一团乱麻。
及时清理数据是十分必要的。其实,数据科学家并不喜欢处理杂乱的数据,所以他们不得不花费很长的时间来进行数据清理、数据标记和数据精练。在调查数据科学家最不喜欢做的工作排名时,我们得到了这样的结论:他们最不喜欢的,也是花费时间最长的工作就是清理和管理数据。
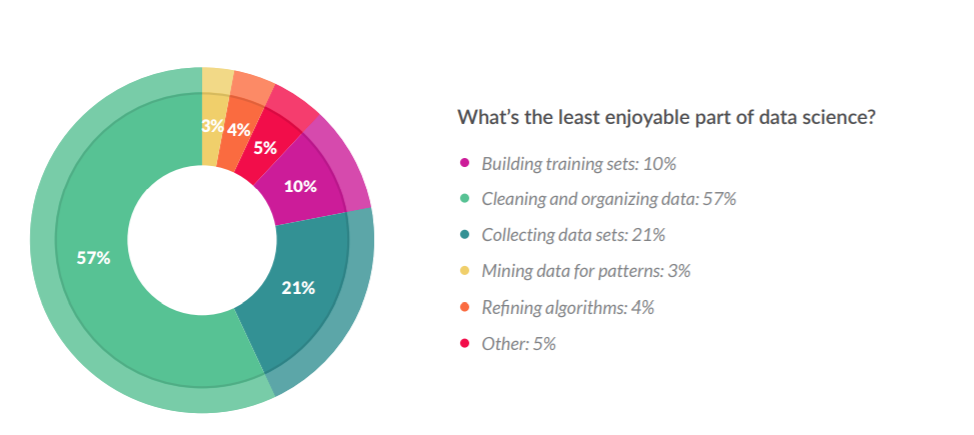
数据科学家最不喜欢的工作内容排名
“脏数据”无所不在
每个处理数据的人都应该听说过“ 脏数据”一词。因为原始数据存在各种各样的问题,如篡改数据、数据不完整、数据不一致、数据重复、数据存在错误、异常数据等,这些情况我们统称为存在“脏数据”。“脏数据”的存在不仅浪费时间,而且可能导致最终分析有误。
数据不完整是指某些基础特征缺失。例如,假设你的任务是预测房价,在这其中“房子的面积”对于预测房价来说至关重要,但是如果这部分信息缺失,这项任务很可能就无法完成,因此模型的效果也就会不佳。
数据不准确和不一致是指数值在技术上是正确的,但放在场景中就是错误的。例如,一名员工变更了他的地址,但是并未及时更新,或者某一组数据有多个副本,但是数据科学家使用的版本是过时的版本,这些都指的是数据的不准确和不一致。
重复数据是一个普遍的问题。我与大家分享下我在一家电商公司发生的一件事。根据设计,当访问者单击“领取优惠券”按钮时,网站会响应到服务器上,随后我们就能计算出有多少用户收集到了优惠券。
网站一直运行良好,但突然有一天网站发生了点状况,而我却对此一无所知。前端开发人员在有人成功领取优惠券时添加了另外一个响应,理由是某些优惠券可能缺货。他们新添加的另外一个响应是想跟踪单击该按钮的访问者以及已经领取完优惠券的访问者。
在添加完新的响应后,两个响应结果都发到了同一个日志表中。等我再查看我的报告工具时,发现领取的优惠券的数量似乎在一夜之间翻了一番!在前一天部署模型时,我还天真地以为我的新模型会很完美,但后来我才意识到我只是做了重复计算。
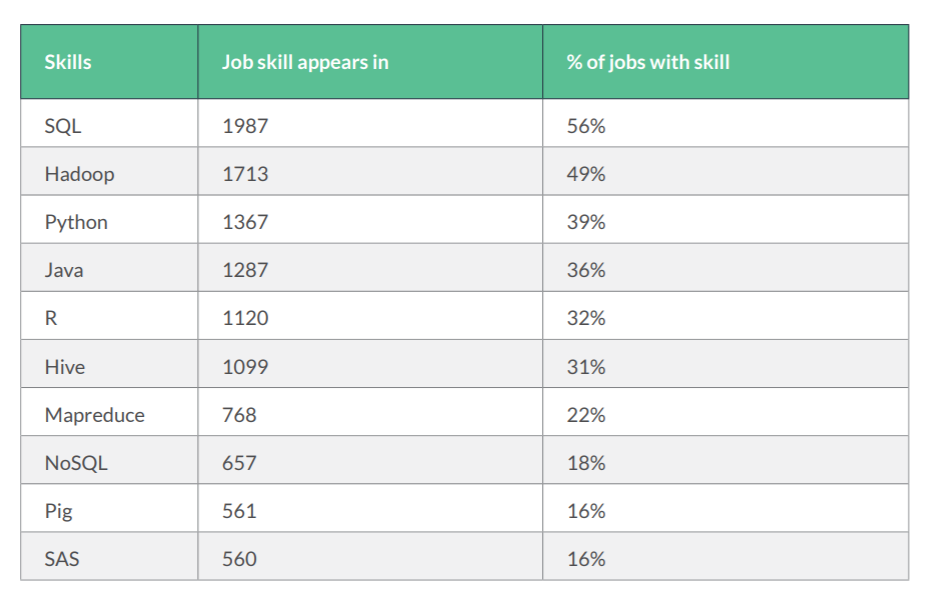
数据科学家最应该掌握的十大技能
除了数据清理和管理,数据科学家还要做什么?
这个世界每天都充斥着海量的数据,有的来自人工输入,有的来自机器日志,但无论是那种数据,数据整理都是现实世界中数据科学家工作的重要部分。为了使监督学习更加有效,我们需要可靠的、带有标签的数据,标记错误的数据无法建立预训练模型,但问题在于,没有人喜欢这项繁杂的、枯燥的数据标记工作。
许多人将数据科学家的工作描述为 80/20 原则。也就是说他们会用 20%的时间来构建模型,而其他 80%的时间用于收集、分析、清理和重组数据。处理脏数据是数据科学家工作中最耗时的部分。
尽管这项工作做起来很让人厌烦,但数据清理在任何一个项目中都是十分重要的,凌乱的数据不会产生好的结果,就像很多人都听过一句话“输入的是垃圾,得到的也会是垃圾”。
如果要来对我的工作进行个总结,我会认为我是 40%的数据清洁工、40%的数据管理员,最后 20%的…算命先生,因为我还要在出现问题时进行诊断和分析,找出症结所在。
原文链接:
https://towardsdatascience.com/data-scientist-the-dirtiest-job-of-the-21st-century-7f0c8215e845

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论