

一、前言
跨 DC(数据中心)的数据同步是企业提升容灾实力的必备手段。随着携程业务向海外发展的速度越来越快,应用架构能够快速全球部署的能力也愈发重要。对于服务而言,我们可以尽量做到无状态的部署架构,来达到灵活拓展,快速部署的目的,比如 server-less。
然而,对于业务应用来讲,大量的业务逻辑是有状态的,仅仅做到服务的灵活拓展还不够,需要数据也拥有多站点共享的能力。
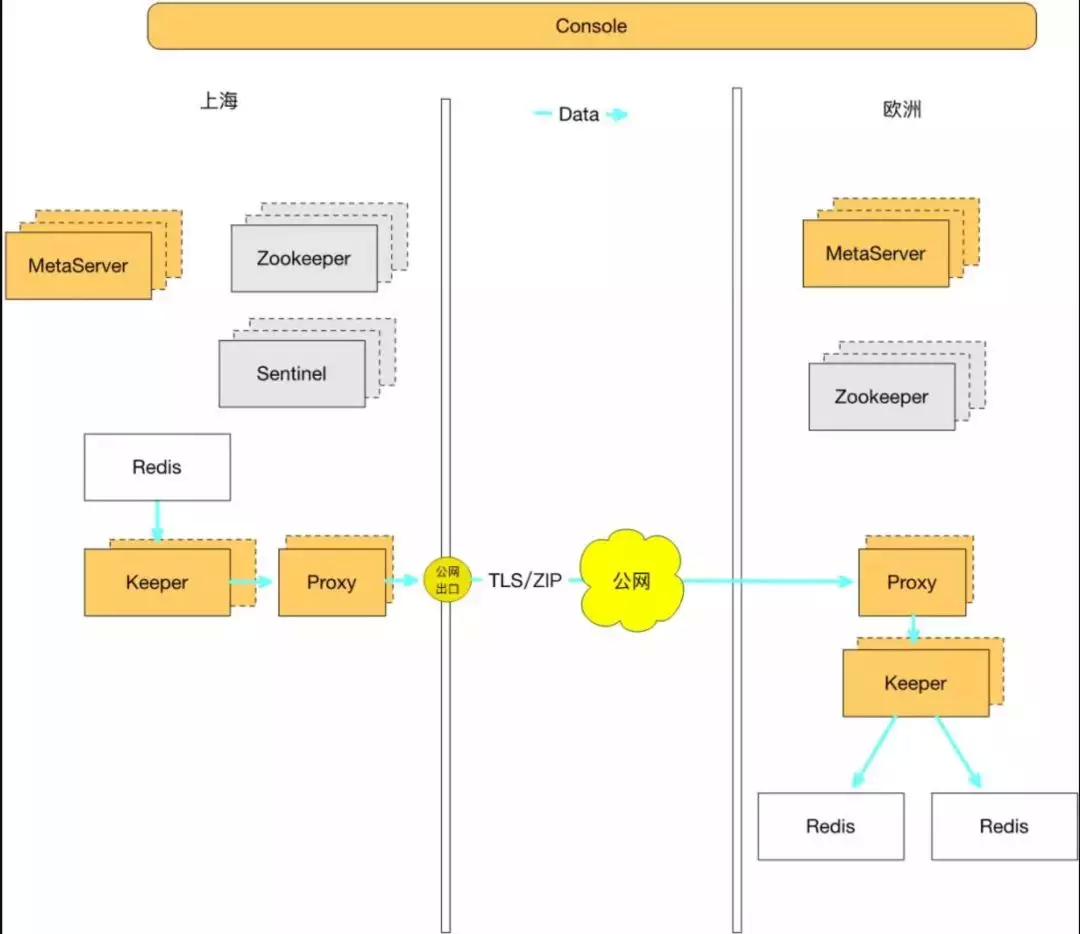
携程在一年前已经可以实现 Redis 单向跨区域同步,从上海将数据复制到美国加州,德国法兰克福,以及新加坡等众多海外站点,延迟稳定在 180ms 左右,支持单个 Redis 5MB/s 的传输带宽。
关于跨公网传输以及跨区域单向复制,详情参考这篇文章:携程Redis海外机房数据同步实践。
但是,技术人的目标就是不断突破自己。在 Redis 出海同步一年之后,业务上有了新的需求:能否在每个站点都可以独立地写入和读取,所有数据中心之间互相同步,而跨区域复制的一致性等问题,也可以由底层存储来解决?
单向同步的 Redis 固然可以解决问题,然而,大量的海外数据需要先回流上海,再从上海同步至各个数据中心,这一来一去, 不仅给业务开发带来了额外的复杂性和代码的冗余性,也给数据本身的时效性以及跨区域传输的费用带来了问题(携程的数据回源需要走专线,而 Redis 同步通过公网传输,由携程的框架中间件 - XPipe 来解决跨公网传输的安全和不稳定性因素)。[1]
二、技术选型
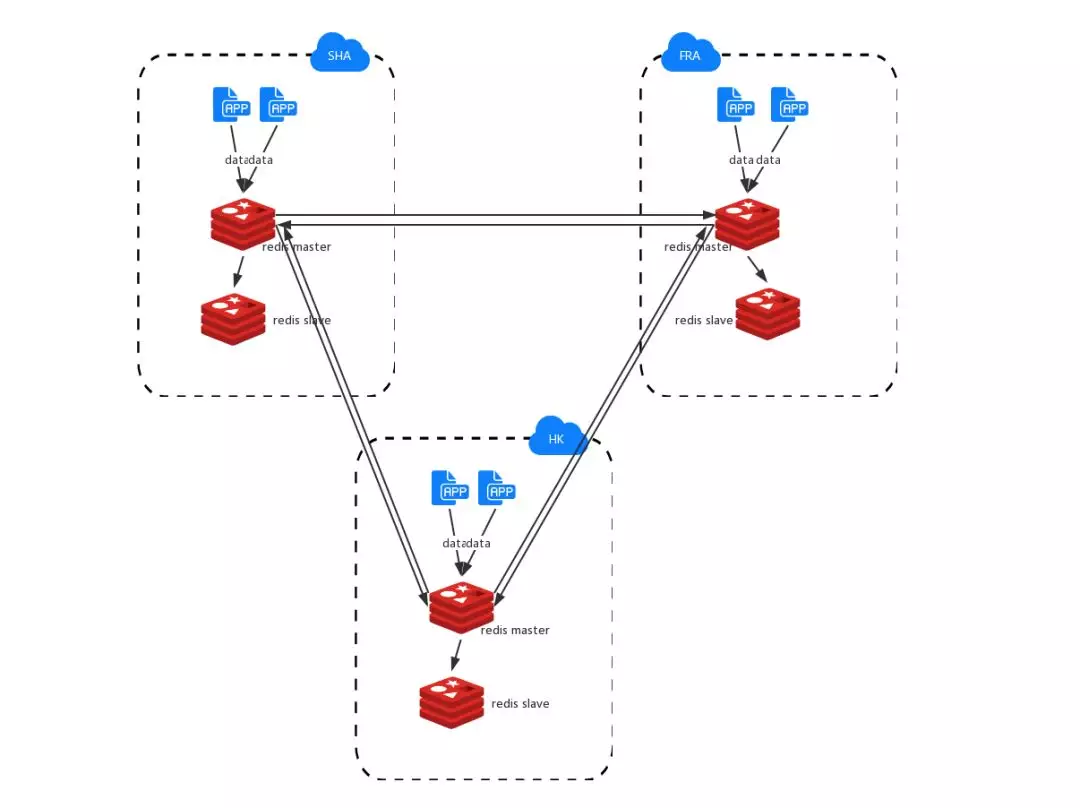
所以,我们需要的是一个分布式的 Redis 存储,能够实现跨区域多向同步。面对大型分布式系统,不免要讨论 CAP 理论,在跨区域多活的场景下如何取舍?
显然 P(网络分区)是首要考虑因素。其次,跨区域部署就是为了提高可用性,而且对于常见的一致性协议,不管是 2PC、Paxos 还是 raft,在此场景下都要做跨区域同步更新,不仅会降低用户体验,在网络分区的时候还会影响可用性。
对于 Redis 这种毫秒级相应的数据库,应用希望能够在每个站点都可以“如丝般顺滑”地使用,因此 C 必定被排在最后。
那是不是 C 无法被满足了呢?事实并非如此,退而求其次,最终一致也是一种选择。经过调研,我们决定选用“强最终一致性”的理论模型来满足一致性的需求。[2]
关于“最终一致性”(Eventually Consistency) 和“强最终一致性”(Strong Eventually Consistency),大家可以参考 wiki 百科给出的释义:
(Strong Eventually Consistency) Whereas eventual consistency is only a liveness guarantee (updates will be observed eventually), strong eventual consistency (SEC) adds the safety guarantee that any two nodes that have received the same (unordered) set of updates will be in the same state. If, furthermore, the system is monotonic, the application will never suffer rollbacks.
三、问题
有了目标,自然是开始计划和设计,那么在开始之前有什么问题呢?
3.1 跨数据中心双向同步共同的问题
各种数据库在设计双向数据同步时,均会遇到的问题:
1)复制回源:A -> B -> A
数据从 A 复制到 B,B 收到数据后,再回源复制给 A 的问题。
2)环形复制:A -> B -> C -> A
我们可以通过标记来解决上一问题,然而系统引入更多节点之后,A 发送到 B 的数据,可能通过 C 再次回到 A。
3)数据一致性
网络传输具有延迟性和不稳定性,多节点的并发写入会造成数据不一致的问题。
4)同步时延(鉴于是跨国的数据同步,这一项我们先忽略)
3.2 Redis 的问题
1)Redis 原生的复制模型,是不能够支持 Multi-Master 的理论架构的。
开源版的 Redis 只能支持 Master-Slave 的架构,并不能支持 Redis 之间互相同步数据。
2)Redis 特殊的同步方式(全量同步+增量同步),给数据一致性带来了更多挑战。
Redis 全量同步和增量同步都基于 replicationId + offset 的方式来做,在引入多个节点互相同步之后,如何对齐互相之间全量同步和增量同步的 offset 是一个巨大的问题。
3)同时支持原生的 Master-Slave 系统
在新版系统上,同时兼容现存的 Master-Slave 架构,两种同步方式和策略的异同,也带来了新的挑战。
四、解决方案
由于篇幅的限制,这里只对数据一致性的解决方案做下介绍,对于分布式系统或者是双向同步感兴趣的同学,可以关注我们后续的技术文章和技术大会。
4.1 一致性的解决方案
CRDT(Conflict-Free Replicated Data Type)[3] 是各种基础数据结构最终一致算法的理论总结,能根据一定的规则自动合并,解决冲突,达到强最终一致的效果。
2012 年 CAP 理论提出者 Eric Brewer 撰文回顾 CAP[4]时也提到,C 和 A 并不是完全互斥,建议大家使用 CRDT 来保障一致性。自从被大神打了广告,各种分布式系统和应用均开始尝试 CRDT,redislabs[5]和 riak[6]已经实现多种数据结构,微软的 CosmosDB[7]也在 azure 上使用 CRDT 作为多活一致性的解决方案。
携程的框架部门最终也选择站在巨人的肩膀上,通过 CRDT 这种数据结构,来实现自己的 Redis 跨区域多向同步。
4.2 CRDT
CRDT 同步方式有两种:
1)state-based replication
发送端将自身的“全量状态”发送给接收端,接收端执行“merge”操作,来达到和发送端状态一致的结果。state-base replication 适用于不稳定的网络系统,通常会有多次重传。要求数据结构能够支持 associative(结合律)/commutative(交换律)/idempotent(幂等性)。
2)operation-based replication
发送端将状态的改变转换为“操作”发送给接收端,接收端执行“update”操作,来达到和发送端状态一直的结果。op-based replication 只要求数据结构满足 commutative 的特性,不要求 idempotent(大家可以想一想为什么)。op-based replication 在接收到 client 端的请求时,通常分为两步进行操作:
a. prepare 阶段:将 client 端操作转译为 CRDT 的操作;
b. effect 阶段:将转译后的操作 broadcast 到其他 server;
两者之间在实现上,界限比较模糊。一方面,state-based replication 可以通过发送 delta 减少网络流量,从而做到和 op-based replication 比较接近的效果;另一方面,op-based replication 可以通过发送 compact op-logs 将操作全集发送过去,来解决初始化的时候同步问题,从而达到类似于 state-based replication 的效果。
我们的系统需要借助两种同步方式,以适用于不同的场景中:
state-based replication 通常是基于“全量状态”进行同步,这样的结果是造成的网络流量太大,且同步的效率低下。在同步机制已经建立的系统中,我们更倾向于使用 op-based replication,以达到节省流量和快速同步的目的。
op-based replication 是基于 unbounded resource 的假设上进行论证的学术理念,在实践过程中,不可能有无限大的存储资源,将某个站点的全部数据缓存下来。
这样就带来一个问题,如果新加节点或者网络断开过久时,我们的存储资源不足以缓存所有值钱的操作,从而使得复制操作无法进行。此时,我们需要借助 state-based replication 进行多个站点之间,状态的 merge 操作。
4.3 CRDT 的数据结构
Redis 的 String 类型对应的操作有 SET, DEL, APPEND, INCRBY 等等,这里我们只讲一下 SET 操作(INCRBY 会是不同的数据类型)。
Register
先来讲一下,CRDT 理论中如何处理 Redis String 类型的同步问题。
Redis 的 String 类型对应于 CRDT 里面的 Register 数据结构,对应的具体实现有两种比较符合我们的应用场景:
MV(Multi-Value) Register:数据保留多份副本,客户端执行 GET 操作时,根据一定的规则返回值,这种类型比较适合 INCRBY 的整型数操作。
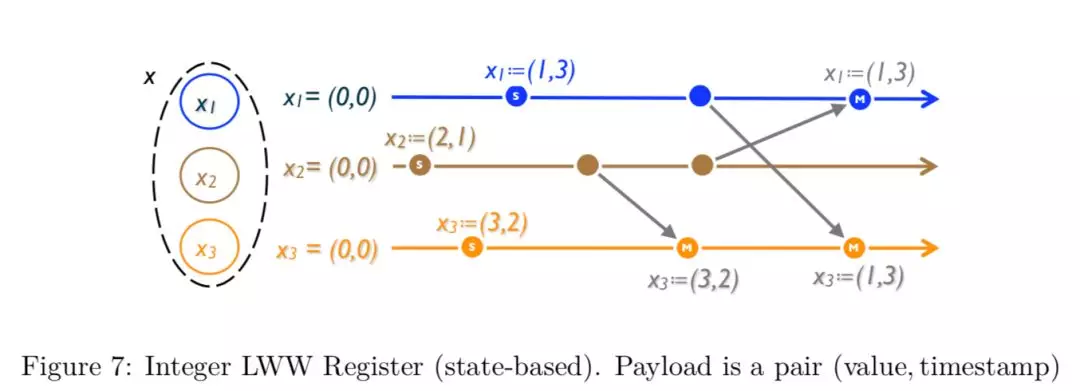
LWW(Last-Write-Wins) Register:数据只保留一份副本,以时间戳最大的那组数据为准,SET 操作中,我们使用这种类型。
还记得上文提到的两种不同的同步方式么,关于两种不同的同步方式,对于 LWW Register,实现方式会稍有不同。
Op-based LWW Register [8]

State-based LWW Register [8]

4.4 CRDT Register 在 Redis 中的落地
讲完了 CRDT 的传输类型和一个基本的数据结构,那么具体这样的理论是如何落地到 Redis 中间的呢?
在最终的实现中,我们采用了 OR-Set(Observed-Remove Set) + LWW(Last-Write-Wins) Register 来实现 Redis 中的 String 操作。
4.4.1 Redis K/V
以下是理论上的数据结构,并不是 redis 中真正的结构体,仅仅作为说明使用。
1)key 既是 SET 操作中的 key
2)val 用来存储相应的 value
3)delete-tag 是逻辑删除的标记位,具体的理论来源是 OR(Observed-Remove) Set
4)timestamp 用于 LWW(Last Write Wins)机制,来解决并发冲突
由于目前我们的多写 Redis 还没有开源,这里我们拿 Java 程序举个栗子[9] 详细可以访问 github。
LWW Register
processCommand 是这个 CRDT 框架的核心函数,基本定义了每一种类型,是如何进行 merge/update 等操作的。
在这里我们可以看到,每一个 command 过来时,会携带一个自身的时钟,由本地的程序进行判定,如果时钟符合偏序(partial ordered),就进行 merge 操作,并储存元素。
OR-SET
而 Observed-Remove SET 相较 LWW-Register 就复杂一些,主要涉及两个概念,一个是正常的原生储存的地方,在 Set<Element<E>> elements 中。而另一个重要的概念,是 tombstone(墓地),用来存放会删除的元素 Set<Element<E>> tombstone OR-SET 的 tombstone,就可以解决并发删除的问题,而 LWW-Register 则可以解决并发添加的问题。
4.4.2 用户视角
正常同步的场景
Data Type: Strings
Use Case: Common SETs Conflict Resolution: None

并发冲突的场景
Data Type: Strings
Use Case: Concurrent SETs
Conflict Resolution: Last Write Wins (LWW)

五、未完待续
由于篇幅限制,我们详细介绍了 CRDT 同步的理论基础以及一个 Redis 的 K/V 数据结构在 CRDT 中是如何展现出来的。对 CRDT 或分布式数据库感兴趣的同学,请关注携程的公众号,也可以支持一下我们目前已经开源的的 redis 同步产品 – XPipe (https://github.com/ctripcorp/x-pipe)。
附录
[3] CRDT: https://hal.inria.fr/inria-00609399/document
[4] Eric Brewer: https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
[5] redislabs, Developing Applications with Geo-replicated CRDBs on Redis Enterprise Software(RS): https://redislabs.com/redis-enterprise-documentation/developing/crdbs/
[6] riak: https://docs.basho.com/riak/kv/2.0.0/developing/data-types/
[7] cosmosDB: https://docs.microsoft.com/en-us/azure/cosmos-db/multi-region-writers
[8] A comprehensive study of Convergent and Commutative Replicated Data Types(https://links.jianshu.com/go?to=http%3A%2F%2Fhal.upmc.fr%2Ffile%2Findex%2Fdocid%2F555588%2Ffilename%2Ftechreport.pdf)
[9] CRDT Java: https://github.com/netopyr/wurmloch-crdt
作者介绍:
祝辰,携程框架架构研发部资深研发工程师,主要负责 Redis 跨站点容灾方面的工作, 目前致力于研究分布式系统中的一致性问题以及相关理论和解决方案。此前曾就职于 EMC 混合云部门。对底层技术比较感兴趣,乐于研究操作系统和各种数据库的实现思路。
本文转载自公众号携程技术中心(ID:ctriptech)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论