

多模态分层视频分类算法
▐ 视频分类的难点
多模态:淘宝短视频的信息是非常丰富的,有视频/封面图/文本/音频/商品等模态,分别刻画了短视频不同维度的信息,这些信息的展示形式都是非结构化的,如何将非结构化的信息转化成结构化的特征是一大难点。不同模态的信息在不同的视频中对类别的贡献度也是不一样的,小部分视频通过标题就可以简单地推测出类别,但大部分视频的标题有效信息过少,需要兼顾其他模态信息才能推测出类别,因此在算法的训练中如何协同不同模态的特征,达到不同模态特征互补的效果又是另一个难点。
层次化label:单独使用二级类目的label虽然也可以进行算法的训练,但是无法使算法达到最优的效果,因为不同一级类目下面的二级类目之间的差距是远大于同一个一级类目下面的二级类目之间的差距的,单独使用二级类目的label无法学习到这个信息。因此如何在算法的训练中充分利用一级类目+二级类目的层次化label同样是一个难点。
模态信息缺失:淘宝视频包含多种不同的模态信息,然而这些视频不一定包含全部的模态信息,有些视频没有外挂商品,有些视频没有对应的视频标题或者摘要,还有的视频没有封面图。如何让算法能够自适应模态缺失的情况也是一个难点。
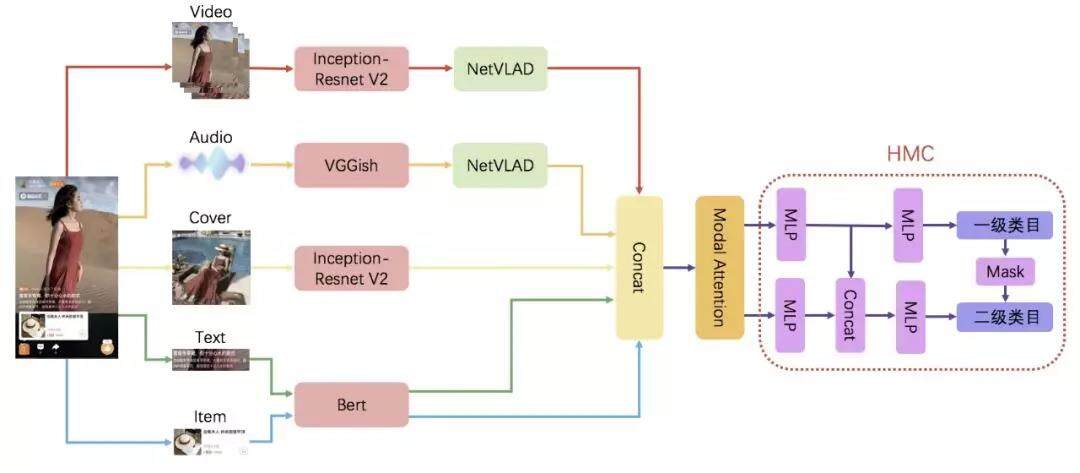
▐ 多模态分层视频分类算法框架图
针对建立高效准确的视频分类算法的迫切需求,解决视频分类中存在的诸多挑战,我们提出了基于模态注意力机制的多模态分层视频分类算法,算法总体框架如图 3 所示。算法的核心主要分为 3 个部分:
(1) 预训练模型的选择,
(2) 模态融合方法的设计,
(3) 多目标的分类器的设计。
图三
▐ 预训练模型的选择
随着硬件水平的提高以及大规模的预训练数据集的推出,迁移学习在深度学习任务中扮演的角色越来越重要。尤其是在缺乏训练数据的情况下,使用预训练模型进行迁移学习能够加速 loss 收敛并显著提升下游任务的准确率。
(1) 视觉模态:视频和封面图共同构成了视觉模态信息,视频是视频内容的主体,包含了主要的内容信息,封面图是视频内容的精华,两者可以互相补充。在 VGG16、Inception 系列模型、ResNet 等经典的图像分类模型中,我们选择了 Inception-Resnet v2[1]作为视觉特征提取的模型。这个模型是 2016 年 Google 推出的大规模图像分类模型,既具有 Inception 系列模型的优势,能够通过堆叠不同的 Inception Block 增加网络的宽度提高算法的准确率,还加入了 Resnet 的残差学习单元(如图 4 所示),残差学习单元的输出由多个卷积层级联的输出和输入元素间相加,能够缓解网络退化的问题,增加深度网络的层数,有效提高视觉特征的的泛化性。
视频特征序列相较于普通的图像特征包含了更加丰富的信息,不同特征之间具有时序相关性。我们采用 NetVLAD(如图 3 所示)作为视频特征的聚合网络。NetVLAD 常出现在近几年国内外视频分类大赛的 top 方案中,以 CNN 的网络结构实现 VLAD 算法,构成了新生成的 VLAD 层,VLAD 算法(如公式 1 所示)统计的是特征 x 和其相应的聚类中心 c 的残差和,a 决定 c 是否是特征 x 距离最近的聚类中心。相比于 Average Pooling,NetVLAD[2]可以通过聚类中心将视频序列特征转化为多个视频镜头特征,然后通过可以学习的权重对多个视频镜头加权求和获得全局特征向量。
公式 1
(2) 音频模态:淘宝视频中包含大量的教程类视频,这些视频内容的关键信息通过音频表现出来,因此在淘宝视频分类中音频模态至关重要。我们首先从淘宝视频中分离音频信号,通过计算 MFCC 特征将音频信号转换为图像输入,然后使用 VGGish[3]提取音频特征序列。音频特征序列与视频特征序列类似,使用 NetVLAD 提取不同镜头对应的音频特征,然后通过可学习的权重融合生成音频模态的全局特征向量。
(3)文本模态:视频内容中的文本包含了视频标题和视频摘要,是视频描述内容的大致概括,对视频分类起到指导性的作用。文本模态,我们使用 Bert 模型生成视频标题和视频摘要的全局特征向量。Bert 是 18 年 Google 推出的大规模文本预训练模型,可谓是 nlp 领域大力出奇迹的代表,Bert 用 12 层的 transformer encoder 将 nlp 任务的 benchmark 提高了一大截。相较于普通的 word2vec,经过海量文本预训练的 Bert 能够在视频分类算法中引入更多的迁移知识,提供更精准的文本特征。
(4) 商品模态:商品模态是淘宝视频区别于站外视频的标志,是体现我们的视频分类算法优势的关键所在。我们沿用文本模态的 Bert 模型生成商品模态的全局特征向量。商品模态在推荐领域常用 item_id lookup 到商品的 embedding 矩阵再接入下游网络,然而我们的视频分类算法是离线学习的,对于新发现的 item_id 不能很迅速地获得它的 embedding 特征,因此我们使用 Bert 模型提取商品的标题和类目名称的文本特征,作为商品模态的全局特征向量。
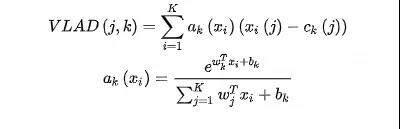
图四
本文转载自淘系技术公众号。
原文链接:https://mp.weixin.qq.com/s/kT01tMRPUCx307m0cF5x0w

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论