
实时数据分析一直是个热门话题,需要实时数据分析的场景也越来越多,如金融支付中的风控,基础运维中的监控告警,实时大盘之外,AI 模型也需要消费更为实时的聚合结果来达到很好的预测效果。
实时数据分析如果讲的更加具体些,基本上会牵涉到数据聚合分析。
数据聚合分析在实时场景下,面临的新问题是什么,要解决的很好,大致有哪些方面的思路和框架可供使用,本文尝试做一下分析和厘清。
在实时数据分析场景下,最大的制约因素是时间,时间一变动,所要处理的源头数据会发生改变,处理的结果自然也会因此而不同。在此背景下,引申出来的三大子问题就是:
通过何种机制观察到变化的数据
通过何种方式能最有效的处理变化数据,将结果并入到原先的聚合分析结果中
分析后的数据如何让使用方及时感知并获取
可以说,数据新鲜性和处理及时性是实时数据处理中的一对基本矛盾。
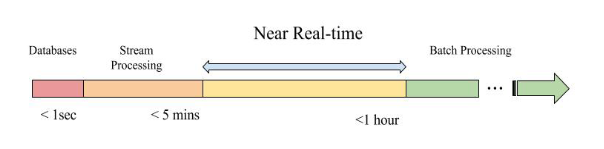
另外实时是一个相对的概念,在不同场景下对应的时延也差异很大,借用 Uber 给出的定义,大体来区分一下实时处理所能接受的时延范围。
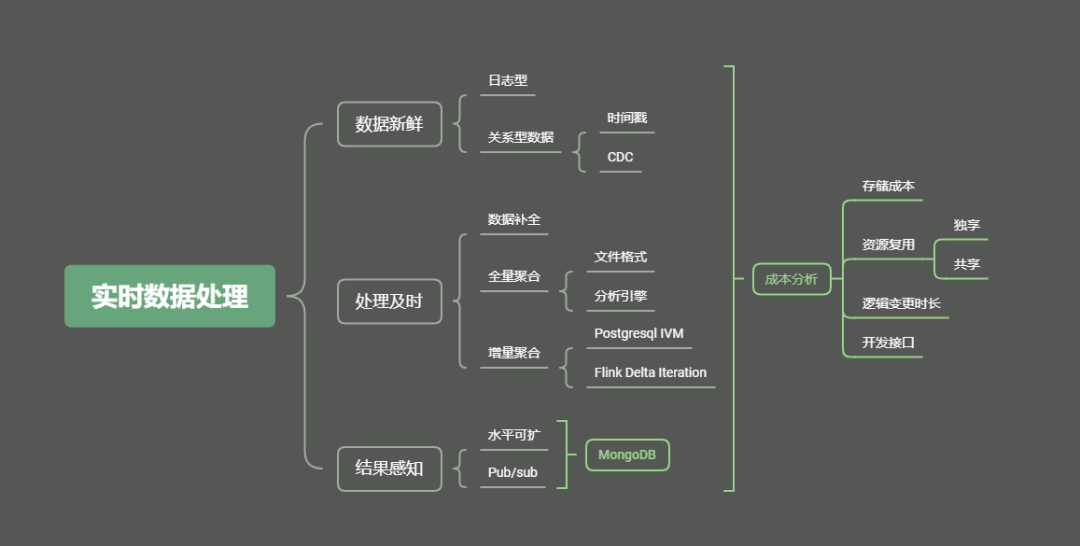
一、数据新鲜性
为简单起见,把数据分成两大类,一类是关键的交易性数据,以存储在关系型数据库为主,另一类是日志型数据,以存储在日志型消息队列(如 kafka)为主。
第二类数据,消费端到感知到最新的变化数据,采用内嵌的 pull 机制,比较容易实现,同时日志类数据,绝大部分是 append-only,不涉及到删改,无论是采用 ClickHouse 还是使用 TimeScaleDB 都可以达到很好的实时聚合效果,这里就不再赘述。
针对第一类存储在数据库中的数据,要想实时感知到变化的数据(这里的变化包含有增/删/改三种操作类型),有两种打法。
打法一:基于时间戳方式的数据同步,假设在表设计时,每张表中都有 datachange_lasttime 字段表示最近一次操作发生的时间,同步程序会定期扫描目标表,把 datachange_lasttime 不小于上次同步时间的数据拉出进行同步。
这种处理方式的主要缺点是无法感知到数据删除操作,为了规避这个不足,可以采用逻辑删除的表设计方式。数据删除并不是采取物理删除,只是修改表示数据已经删除的列中的值标记为删除或无效。使用这种方法虽然让同步程序可以感知到删除操作,但额外的成本是让应用程序在删除和查询时,操作语句和逻辑都变得复杂,降低了数据库的可维护性。
打法一的变种是基于触发器方式,把变化过的数据推送给同步程序。这种方式的成本,一方面是需要设计实现触发器,另一方面是了降低了 insert/update/delete 操作的性能, 提升了时延,降低了吞吐量。
打法二:基于 CDC(Change Data Capture)的方式进行增量数据同步,这种方式对数据库设计的侵入性最小,性能影响也最低,同时可以获得丰富的开源组件支持,如 Cannal 对 MySQL 有很好支持,Debezium 对 PostgreSQL 有支持。利用这些同步组件,把变化数据写入到 Kafka,然后供后续实时数据分析进一步处理。
二、数据关联
新鲜数据在获取到之后,第一步常见操作是进行数据补全(Data Enrichment), 数据补全自然涉及到多表之间的关联。这里有一个痛点,要关联的数据并不一定也会在增量数据中,如机票订单数据状态发生变化,要找到变化过订单涉及到的航段信息。由于订单信息和航段信息是两张不同的表维护,如果只是拿增量数据进行关联,那么有可能找不到航段信息。这是一个典型的实时数据和历史数据关联的例子。
解决实时数据和历史数据关联一种非常容易想到的思路就是当实时数据到达的时候,去和数据库中的历史数据进行关联,这种做法一是加大了数据库的访问,导致数据库负担增加,另一方面是关联的时延会大大加长。为了让历史数据迅速可达,自然想到添加缓存,缓存的引入固然可以减少关联处理时延,但容易引起缓存数据和数据库中的数据不一致问题,另外缓存容量不易估算,成本增加。
有没有别的套路可以尝试?这个必须要有。
可以在数据库侧先把数据进行补全,利用行转列的方式,形成一张宽表,实现数据自完备,宽表的变化内容,利用 CDC 机制,让外界实时感知。
三、计算及时性
在解决好数据变化实时感知和数据完备两个问题之后,进入最关键一环,数据聚合分析。为了达到结果准确和处理及时之间的平衡,有两大解决方法:一为全量,一为增量。
3.1 全量计算(1m<时延<5m)
全量计算以时间代价,对变化过的数据进行全量分析,分析结果有最高的准确性和可靠性。成本是花费较长的计算时间和消耗较多的计算资源。可以使用的分析引擎或计算框架有 Apache Spark 和 Apache Flink。
全量数据容量一般会比较大,为了节约存储,同时为了方便数据过滤和减少不必要的网络传输,大多会使用列式存储, 列式存储使用较多的当属 Parquet 和 ORC。
列式存储最大的不足是无法进行删/改操作,为了支持删改,一般会把列式存储和行式存储相结合。最近时间内变化的数据采用行式存储如 avro 格式,然后定期合并成列式存储。非常成功和红火的 Apache Hudi 和 Delta IO 就是基于这种思路。
3.2 增量计算
假设当前处理的时间窗口中有 10 万条记录,因为其中不到 100 条的记录发生变化,而对所有记录的聚合指标进行计算重演,显然不是非常合理,那么有没有可能只对增量数据导致的变化聚合指标进行重算。答案是肯定的,或者说在部分场景下,是可以实现的。
让我们把增量计算分成几种不同情况:
1)增量数据会添加新的聚合记录,对原有计算结果无影响
2)增量数据会添加新的聚合记录,并导致原有计算结果部分失效
3)增量数据不添加新的聚合记录,但导致原有计算结果全部失效
第 1、2 两种情况下,增量计算会带来实时性上的收益,第三种不会,因为所有指标均被破坏,都需要重演,已经褪化成全量计算。
增量处理模型除了 Apache Flink 之外,非常著名的还有 Microsoft 提出的 Naiad 模型,后者更为高效。由于后者只提供了非常底层的调用 API,在生态建设方面远不如 Apache Flink,但其思想深刻影响了 TensorFlow 等框架的设计和实现,等有时间再详细介绍一下 Naiad。
上面讨论的全量也好,增量也罢,都是把数据从数据库拉出来再进行计算,那么有没有可能在数据库内部实现增量计算的可能?
Oracle 在 12.x 版本中提供物理视图(materialized view)的自动刷新机制,这意味着用户可以把实时聚合逻辑定义在物理视图中,然后每当有数据更新,视图会被自动更新。既然 Oracle 有,那么在开源的世界里一定会有对应的东西出现,最起码会有相应的影子在浮现,这个影子就是 PostgreSQL IVM。
PostgreSQL IVM 使用到 Transition Table 这个概念,在触发器中,用户可以看到变化前和变化后的数据,从而计算出变更的内容,利用这些 Delta 数据,进行刷新预先定义好的物理视图。
四、计算触发机制
定时触发
trigger for every new element
计算成本比较

五、聚合结果实时可见
聚合结果的存储要支持 upsert 语义,聚合结果的消费者实时感知到,同时聚合结果的存储要有水平可扩性。结合这三个要求,比较推荐使用 NoSQL 来进行指标的存储,具体可以使用 MongoDB。
六、小结
本文尝试对实时数据聚合分析中涉及到的问题和常见思路进行梳理,文中定有不少疏漏,不足之处希望读者批评指正。
作者简介
数据猩猩,携程数据分析总监,关注分布式数据存储和实时数据分析。
本文转载自:携程技术中心(ID:ctriptech)
原文链接:干货 | 实时数据聚合怎么破




