

1 引言
在 2019 年 2 月 21 号发布的《DATABUS-数据孤岛解决方案》(点击跳转)文章中,就有提到 TiSpark。在 Databus 项目中,为了打通散落在公司内部的业务数据,解决数据孤岛,一个重要的功能是将指定数据库表快速准确导入目的地数据源中。目前 Databus 支持以 T+1 方式,天级别、小时级别配置全量,增量任务,从指定数据源导入目的地数据源中。其中在将业务数据导入到数据仓库的过程中,TiSpark 起到了重要的作用。
2 介绍
首先什么是 TiSpark?在介绍 Tispark 之前需要简单介绍下 TiDB 的整体架构,因为 TiSpark 是基于 TIDB 与 TIKV 的。TiDB 是一款定位于在线事务处理/在线分析处理(HTAP)的融合型数据库产品,具有易水平伸缩,强一致性的多副本数据安全,分布式事务,实时 OLAP 等重要特性。TIDB 的整体架构如下所示。
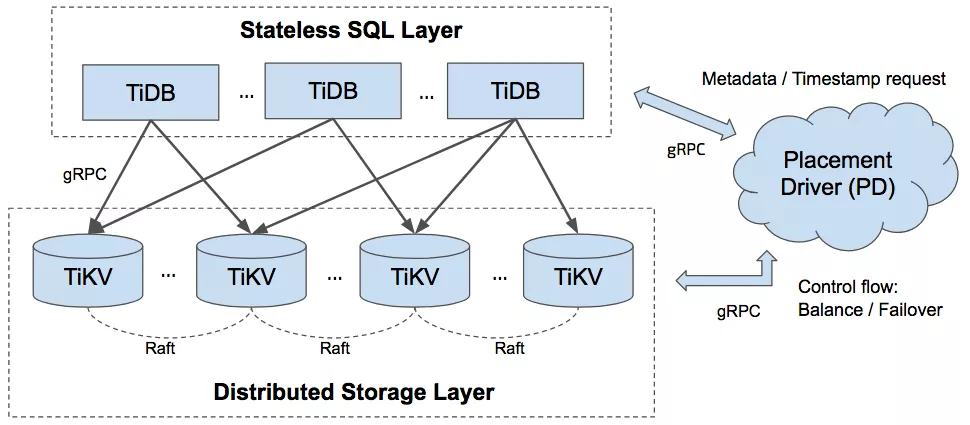
2.1 TiDB Server
Tispark 深度整合了 Spark Catalys 引擎。它可以对计算的精确控制,可以高效的从 TIKV 读取数据.它还支持索引查找,这样大大提高了查询的性能。它通过计算下推策略将一部分计算任务移交给 TIKV,减少 Spark SQL 需要处理的数据量,这样加快了查询的效率。它还使用 TiDB 内置的统计信息来优化查询计划。
2.2 Placement Driver
Placement Driver(简称 PD)是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
2.3 TiKV Serve
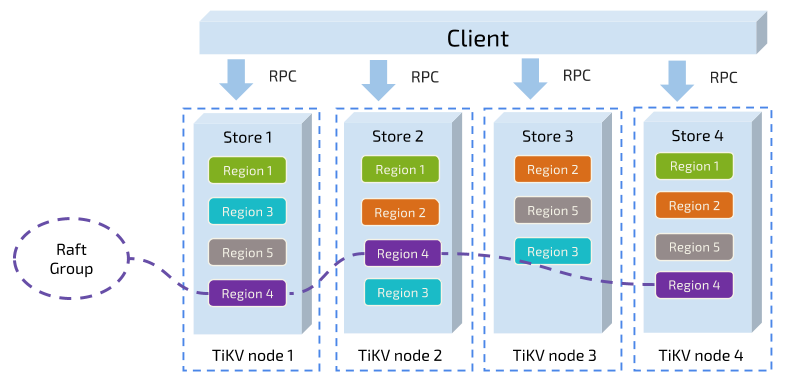
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2.4 TiSpark
TiSpark 是为了在 TiDB/TiKV 上运行 Spark 程序而产生的,可以用于一些复杂的 OLAP 查询。TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。它借助 Spark 平台,同时融合 TiKV 分布式集群的优势,和 TiDB 一起为用户一站式解决 HTAP(Hybrid Transactional/Analytical Processing)需求。
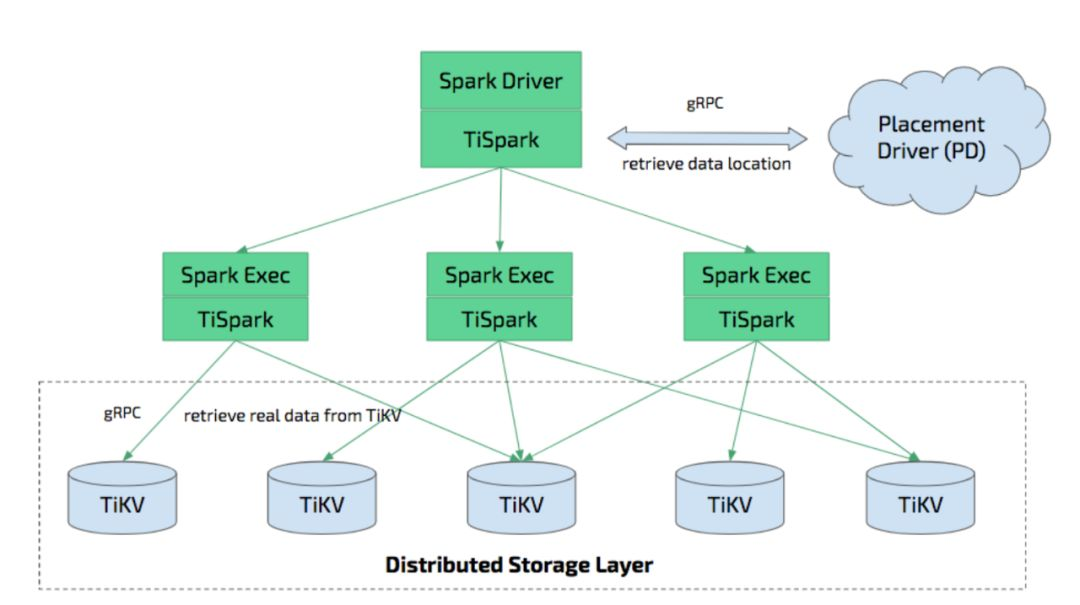
TiSpark 整体架构
TiSpark 深度整合了 Spark Catalys 引擎。它可以对计算的精确控制,可以高效的从 TIKV 读取数据。它还支持索引查找,这样大大提高了查询的性能。
它通过计算下推策略将一部分计算任务移交给 TIKV,减少 Spark SQL 需要处理的数据量,这样加快了查询的效率。它还使用 TiDB 内置的统计信息来优化查询计划。
从数据集成的角度来看,TiSpark+TiDB 提供了一站式的解决方案,可以在同一个平台上直接运行事务和分析,而无需构建和维护任何 ETL,这样简化了系统架构,降低了维护成本。
此外,还可以利用 Spark 生态系统中的工具来对 TiDB 进行进一步的数据处理和分析。例如,使用 TiSpark 进行数据分析和 ETL;从 TiKV 中检索数据作为机器学习数据源;从调度系统生成报告等等。
3 实践
Databus 对于 TIDB 的使用如下图所示。TiSpark 主要用来将业务数据以 T+1 的方式同步到 Hive 数据仓库。
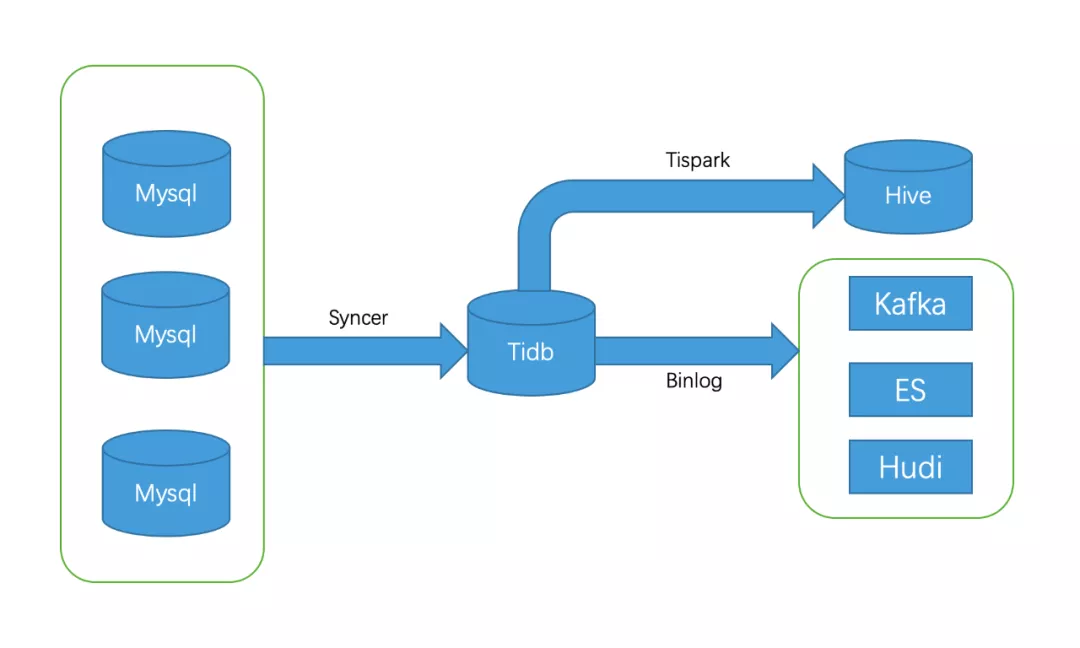
运行环境:Jdk1.8、Spark2.3.2、Spark 部署模式 Yarn
TiSaprk 部署采用外接 jar 包的方式,因此在已有的 Spark 集群部署 TiSpark 的方式很简单,只需将 Tispark 的 jar 包放到 spark 的 jars 路径,并修改 spark-defaults.conf 配置文件即可。
3.1 关键配置
spark.sql.extensions org.apache.spark.sql.TiExtensions 该配置必须存在表示 Spark 引入 Tispark 扩展。
spark.tispark.pd.addresses,该配置为 Placement Driver 集群的地址,Spark driver 会与 Placement Driver 进行通信,获得要查询的数据的在对应 TIKV 结点的具体地址。
spark.tispark.db_prefix,该配置可以在 TiDB 中所有数据库上加上额外数据库前缀,如 databus 数据库在利用 TiSpark 查询时应该查询的数据库名为 tidb_databus,这样可以简单区分源数据库来自 TIDB。
spark.tispark.request.command.priority Tispark 查询的优先级,可选为"Low", “Normal”, “High"通过设置优先级可以影响 Tispark 获取的 TIKV 资源,默认的优先级级别为"Low”,这样是为了避免 Tispark 影响 OLTP 的工作负担,在 Databus 项目中,目前 TIDB 的 OLTP 的查询量较少,而 TiSpark 在每天凌晨有大量的数据同步任务,因此将优先级设为"Normal"。
3.2 数据同步效率提升
在引入 Tispark 之后数据同步的效率大大提升,将 TiSpark 分别与 Spark sql、Sqoop 进行对比,选取多个数据量不同的表来进行测试,分别用 Tispark、Spark sql、Sqoop 将数据同步到 hive 中,实验效果如下图所示。
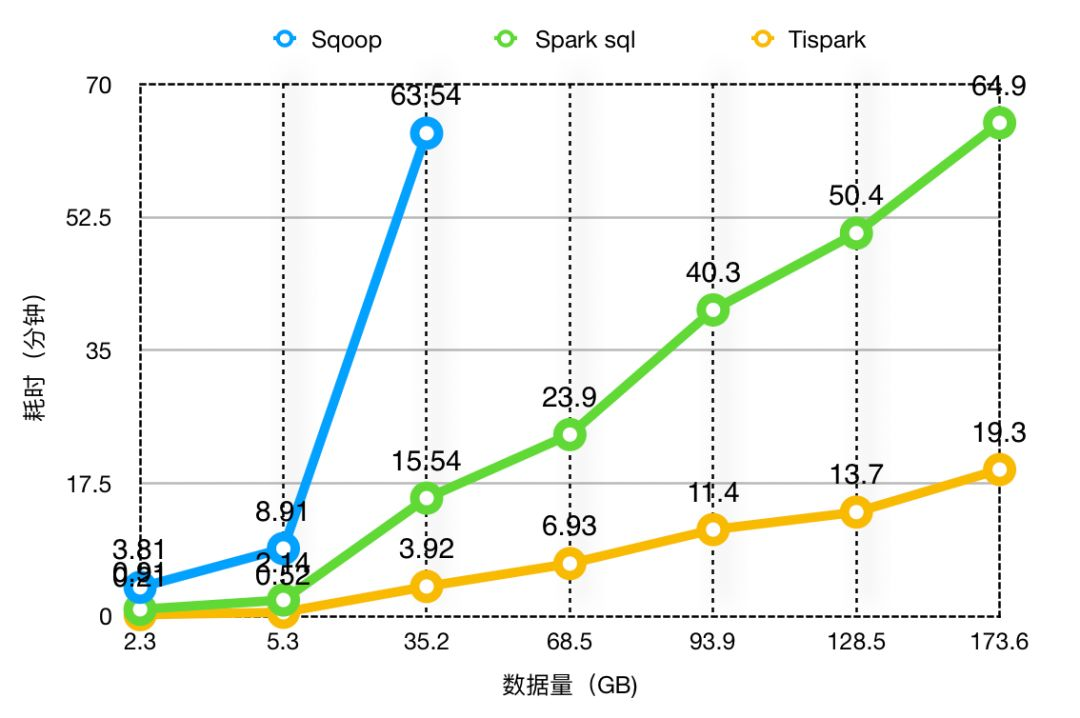
由实验可得 TiSaprk 数据同步效率有显著的优势,平均单位数据量 Tispark 同步速率是 Spark Sql 的四分倍左右,为 Sqoop15 倍左右。
3.3 优化数据同步流程
在 Spark sql 同步数据时存在着一些问题,例如对于个别数据量比较大的业务数据表,有着主键非递增不连续、分布不均匀的情况。为了提高 spark sql 的数据同步性能,执行任务之前会指定 partitionColumn(通常为业务表的主键或者其他数值类型的字段)、lowerBound、upperBound。那么分布不均匀的主键会导致 spark 不同 partition 的数据量差距很大,对于数据量大的 partition 则可能会出现 OOM 的情况。
除此之外,spark sql 在执行任务之前需要指定 spark.executor.memory 的大小,目前只能根据业务数据库元数据存储的数据量大小,并考虑到将数据读到 Java 内存中会有一定的增大来进行预估,来调整 spark 任务需要的资源,这样存在着资源浪费的情况。
而引入 Tispark 之后可以很好的解决这些之前存在的问题。当数据量较大时,存储在 TIKV 的数据会被分成多个 Region,切分的方式是按照 key range 进行排序并划分,每一个 key range 对应一个 Region。相邻的两个 Regiona 不会出现空洞,前面一个 Region 的 start key 是下一个 Region 的 end key。Region 会有一定的大小限制,当超过阀值后,一个大的 Region 会分裂成小的 Region,相反,数据量很小的两个相邻 Region 也会合并生成一个大的 Region。
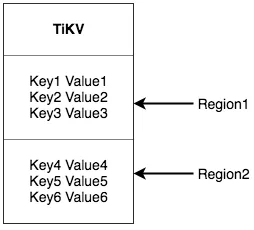
TIKV 查询数据时,首先会跟 PD 进行通信,从 PD 的 Region 路由表获 Region 的具体信息,比如 Region 有多少副本,leader 副本存储在哪个 TIKV 结点上。Tispark 可以根据不同的 TIKV 结点切分多个 Spark partition 并行读取,Spark 分区数据量比较均匀。
3.4 提高数据同步稳定性
利用 TIDB 的周边工具 Syncer 利用主从同步可以将 mysql 数据实时、增量同步到 TIDB 中,TiSpark 则可以直接从 TIKV 读取数据。
众所周知,无论是 Spark sql 还是 Sqoop 来同步数据都需要通过大量的 JDBC 连接 mysql 从库,对业务数据库会造成一定的压力,若从库不可用则同步数据任务将会失败。
在 TIDB 架构中数据在 TIKV 中以 Region 为单位,被分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多,并且以 Region 为单位做 Raft 的复制和成员管理,这样一方面实现了存储容量的水平扩展(增加新的节点后,会自动将其他节点上的 Region 调度过来),另一方面也实现了负载均衡(不会出现某个节点有很多数据,其他节点上没什么数据的情况)。
除此之外的好处是具有一定的容灾能力,一个节点挂掉之后,数据在其他节点依旧存在,可以继续提供服务。
4 总结与展望
在 Databus 项目中,TiDB 与 TiSpark 起到了至关重要的作用,目前 Tispark 主要用来定时的同步数据,在 Databus 的未来规划中,会利用 Tispark 提供一定的数据分析功能,这样的一个好处是不需要再把数据同步到数据分析平台,不需要 ETL 过程,上游业务 OLTP 的数据通过 TiDB 实时写入,并且可以利用 TiSpark 的 OLAP 能力实时分析,可以实时的查询最新的业务数据,满足一部分用户查询需求。
作者介绍:
沸羊羊(企业代号名),目前负责实时数据流平台以及大数据工具链组件研发相关工作。
本文转载自公众号贝壳产品技术(ID:gh_9afeb423f390)。
原文链接:
https://mp.weixin.qq.com/s/RYZEMH3SKCyP_CqgbSVq9w

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论