
在当今数字化时代,数据已经成为企业和组织中不可或缺的重要资产,包括个人信息、商业机密、财务数据等等。然而,随着数据泄露和安全问题的不断增加,数据脱敏已经成为了一项非常重要的工作。随着以 Flink 为代表的实时数仓的兴起,企业对实时数据安全的需求越来越迫切。但由于 Flink 实时数仓领域发展相对较短,Apache Ranger 尚不支持 FlinkSQL,且依赖 Ranger 会导致系统的部署和运维愈加复杂。
因此,自研出 FlinkSQL 的数据脱敏方案,支持面向用户级别的数据脱敏访问控制,即特定用户只能访问到脱敏后的数据。在技术实现上做到对 Flink 和 Calcite 源码的零侵入,可以快速集成到已有实时平台产品中。
一、基础知识
1.1 数据脱敏
数据脱敏(Data Masking)是一种数据安全技术,用于保护敏感数据,以防止未经授权的访问。该技术通过将敏感数据替换为虚假数据或不可识别的数据来实现。例如可以使用数据脱敏技术将信用卡号码、社会安全号码等敏感信息替换为随机生成的数字或字母,以保护这些信息的隐私和安全。
1.2 业务流程
下面用订单表orders的两行数据来举例,示例数据如下:

1.2.1 设置脱敏策略
管理员配置用户、表、字段、脱敏条件,例如下面的配置。

1.2.2 用户访问数据
当用户在 Flink 上查询orders表的数据时,会在底层结合该用户的脱敏条件重新生成 SQL,即让数据脱敏生效。当用户 A 和用户 B 在执行下面相同的 SQL 时,会看到不同的结果数据。
SELECT * FROM orders用户 A 查看到的结果数据如下,customer_name字段的数据被全部掩盖掉。

用户 B 查看到的结果数据如下,customer_name字段的数据只显示前 4 位,剩下的用 x 代替。

二、Hive 数据脱敏解决方案
在离线数仓工具 Hive 领域,由于发展多年已有 Ranger Column Masking 方案来支持字段数据的脱敏控制,详见参考文献[1]。下图是在 Ranger 里配置 Hive 表数据脱敏条件的页面,供参考。
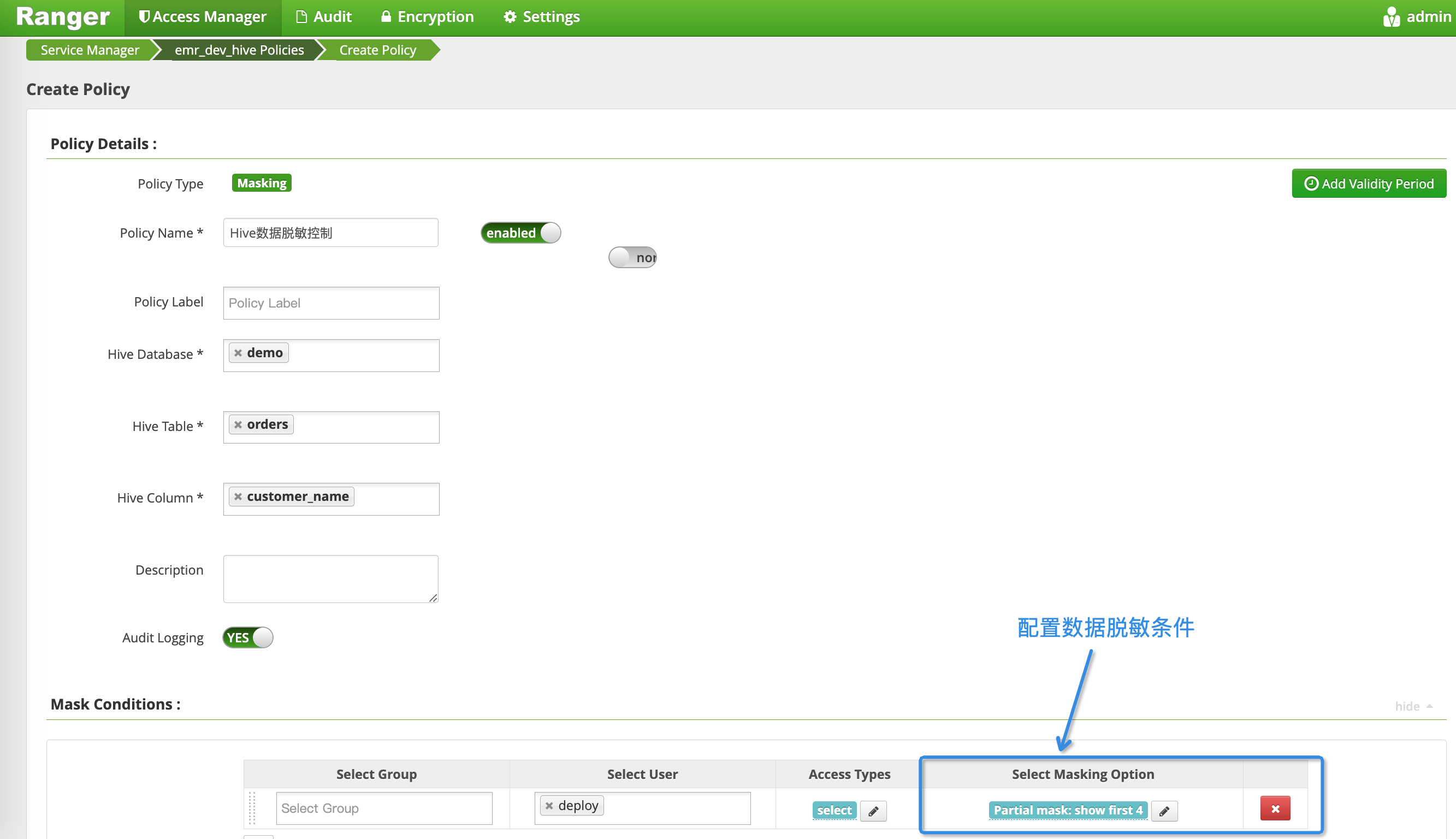
但由于 Flink 实时数仓领域发展相对较短,Ranger 还不支持 FlinkSQL,以及依赖 Ranger 的话会导致系统部署和运维过重,因此开始自研实时数仓的数据脱敏解决工具。当然本文中的核心思想也适用于 Ranger 中,可以基于此较快开发出 ranger-flink 插件。
三、FlinkSQL 数据脱敏解决方案
3.1 解决方案
3.1.1 FlinkSQL 执行流程
可以参考作者文章[FlinkSQL字段血缘解决方案及源码],本文根据 Flink1.16 修正和简化后的执行流程如下图所示。
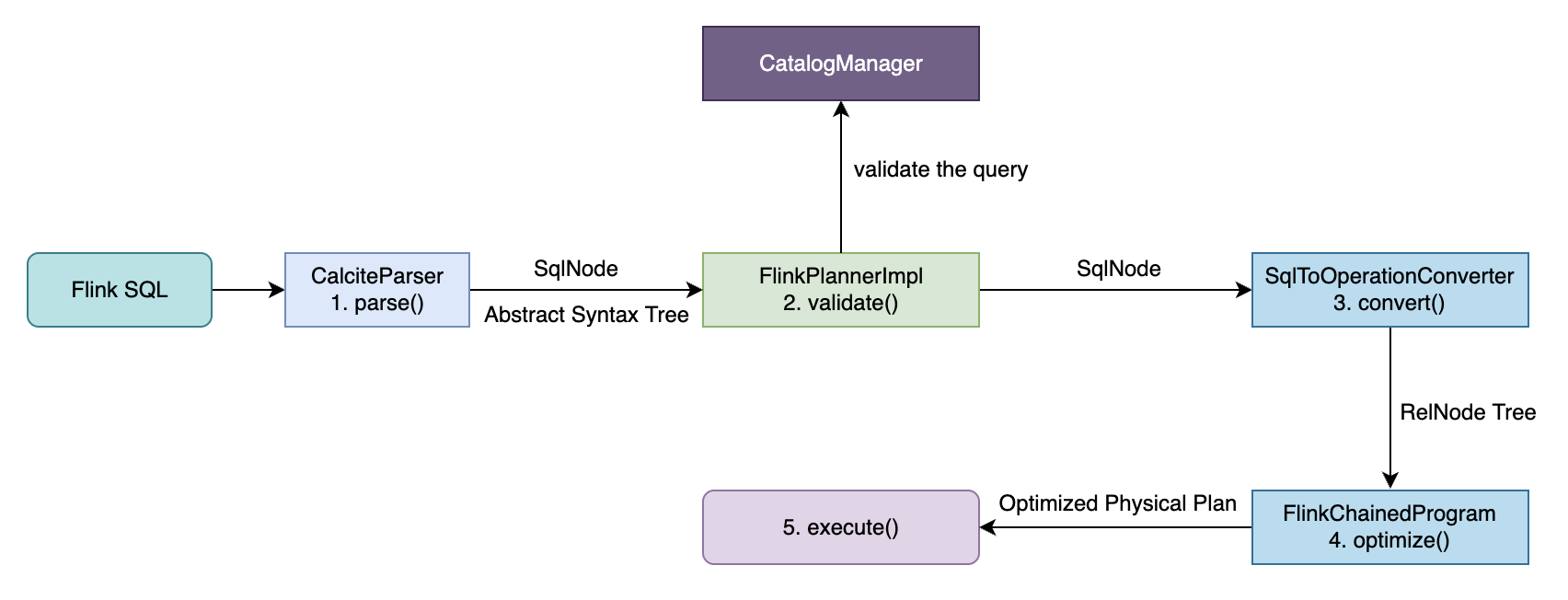
在CalciteParser进行parse()和validate()处理后会得到一个 SqlNode 类型的抽象语法树(Abstract Syntax Tree,简称 AST),本文会针对此抽象语法树来组装行级过滤条件后生成新的 AST,以实现数据脱敏控制。
3.1.2 Calcite 对象继承关系
下面章节要用到 Calcite 中的 SqlNode、SqlCall、SqlIdentifier、SqlJoin、SqlBasicCall 和 SqlSelect 等类,此处进行简单介绍以及展示它们间继承关系,以便读者阅读本文源码。
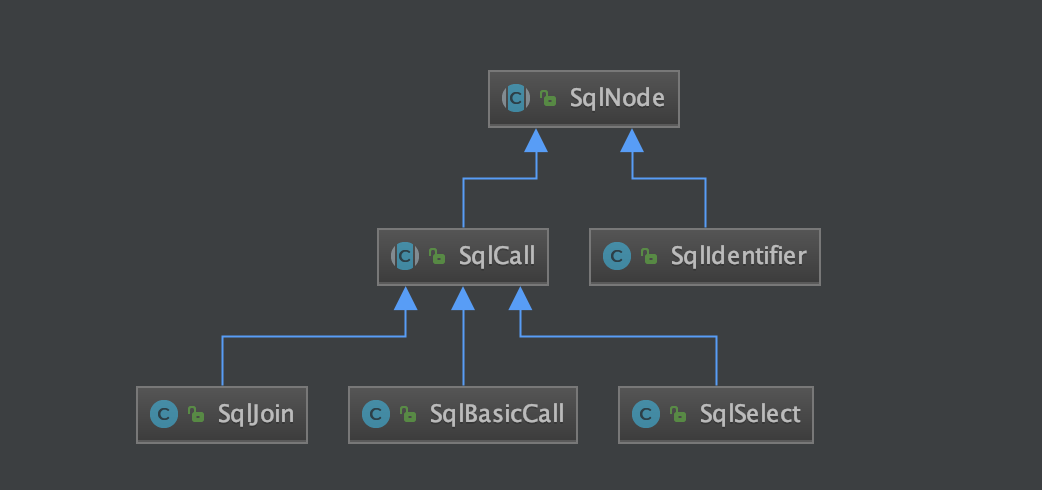
3.1.3 解决思路
针对输入的 Flink SQL,在CalciteParser进行语法解析(parse)和语法校验(validate)后生成抽象语法树(Abstract Syntax Tree,简称 AST)后,采用自定义Calcite SqlBasicVisitor的方法遍历 AST 中的所有SqlSelect,获取到里面的每个输入表。如果输入表中字段有配置脱敏条件,则针对输入表生成子查询语句,并把脱敏字段改写成CAST(脱敏函数(字段名) AS 字段类型) AS 字段名,再通过CalciteParser.parseExpression()把子查询转换成 SqlSelect,并用此 SqlSelect 替换原 AST 中的输入表来生成新的 AST,最后得到新的 SQL 来继续执行。
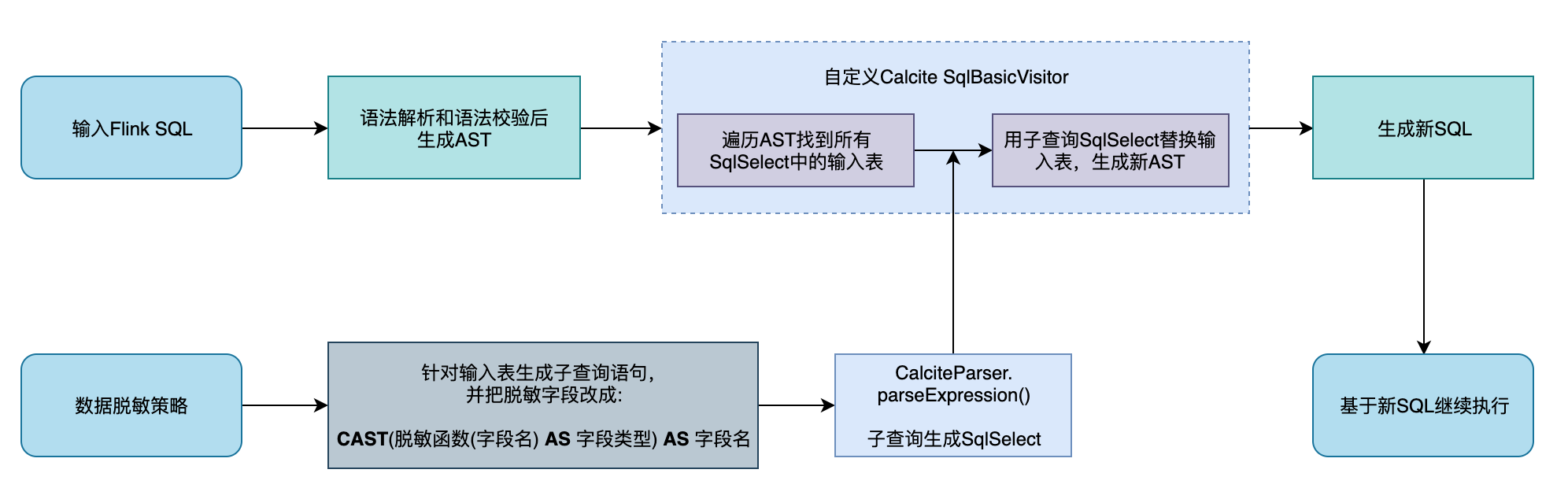
3.2 详细方案
3.2.1 解析输入表
通过对 Flink SQL 语法的分析和研究,最终出现输入表的只包含以下两种情况:
SELECT 语句的 FROM 子句,如果是子查询,则递归继续遍历。
SELECT ... JOIN 语句的 Left 和 Right 子句,如果是多表 JOIN,则递归查询遍历。
因此,下面的主要步骤会根据 FROM 子句的类型来寻找输入表。
3.2.2 主要步骤
主要通过 Calcite 提供的访问者模式自定义 DataMaskVisitor 来实现,遍历 AST 中所有的 SqlSelect 对象用子查询替换里面的输入表。下面详细描述替换输入表的步骤,整体流程如下图所示。
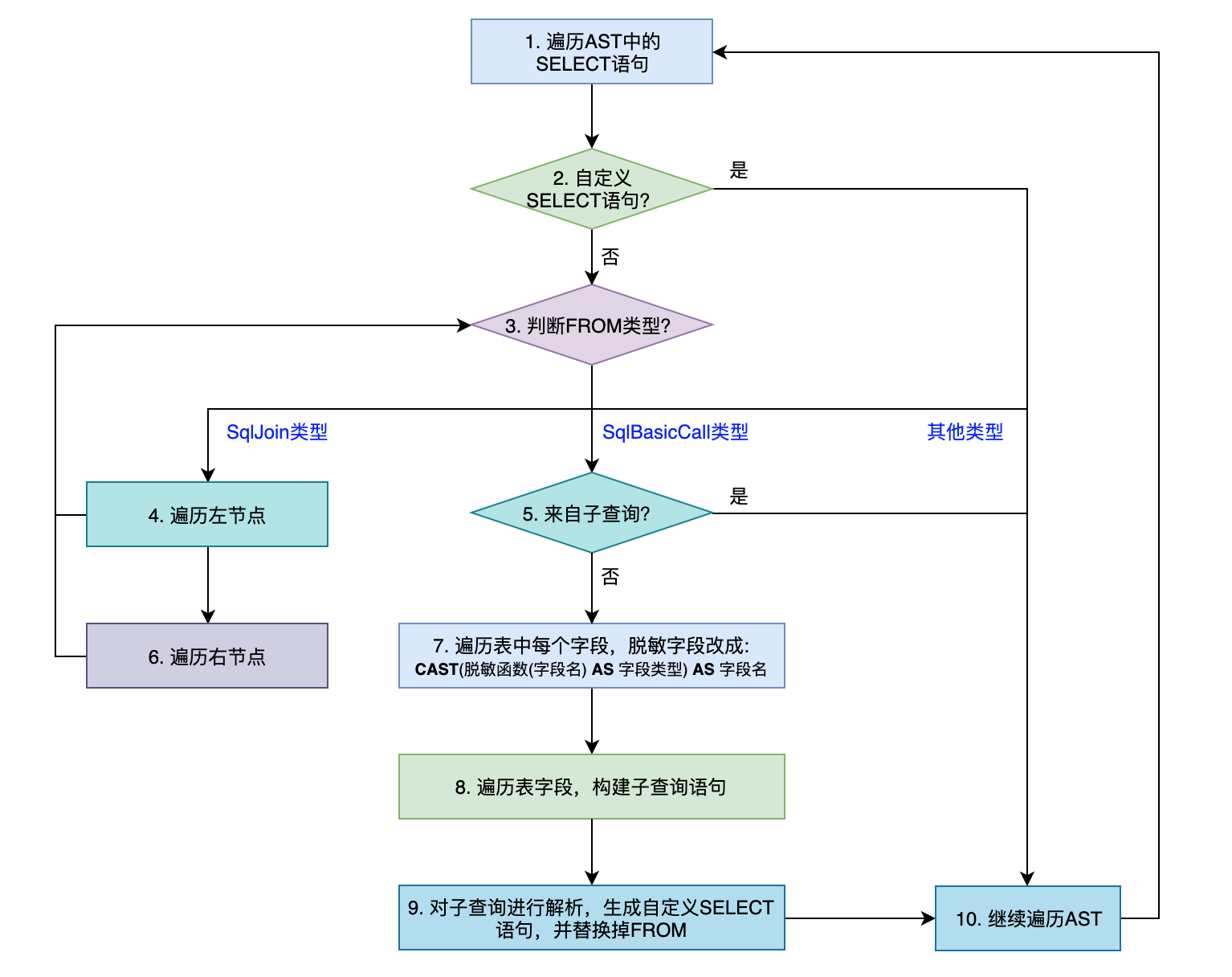
遍历 AST 中的 SELECT 语句。
判断是否自定义的 SELECT 语句(由下面步骤 9 生成),是则跳转到步骤 10,否则继续步骤 3。
判断 SELECT 语句中的 FROM 类型,按照不同类型对应执行下面的步骤 4、5 和 10。
如果 FROM 是 SqlJoin 类型,则分别遍历其左 Left 和 Right 右节点,即执行当前步骤 4 和步骤 6。由于可能是三张表及以上的 Join,因此进行递归处理,即针对其左节点跳回到步骤 3。
如果 FROM 是 SqlBasicCall 类型,还需要判断是否来自子查询,是则跳转到步骤 10 继续遍历 AST,后续步骤 1 会对子查询中的 SELECT 语句进行处理。否则跳转到步骤 7。
递归处理 Join 的右节点,即跳回到步骤 3。
遍历表中的每个字段,如果某个字段有定义脱敏条件,则把改字段改写成格式
CAST(脱敏函数(字段名) AS 字段类型) AS 字段名,否则用原字段名。针对步骤 7 处理后的字段,构建子查询语句,形如
(SELECT 字段名1, 字段名2, CAST(脱敏函数(字段名3) AS 字段类型) AS 字段名3、字段名4 FROM 表名) AS 表别名。对步骤 8 的子查询调用
CalciteParser.parseExpression()进行解析,生成自定义的 SELECT 语句,并替换掉原 FROM。继续遍历 AST,找到里面的 SELECT 语句进行处理,跳回到步骤 1。
3.2.3 Hive 及 Ranger 兼容性
在 Ranger 中,默认的脱敏策略的如下所示。通过调研发现 Ranger 的大部分脱敏策略是通过调用 Hive 自带或自定义的系统函数实现的。
由于 Flink 支持 Hive Catalog,在 Flink 能调用 Hive 系统函数。 因此,本方案也支持在 Flink SQL 配置 Ranger 的脱敏策略。
四、用例测试
源码地址:https://github.com/HamaWhiteGG/flink-sql-security
注: 如果用 IntelliJ IDEA 打开源码,请提前安装 Manifold 插件。
用例测试数据来自于 CDC Connectors for Apache Flink 官网,本文给orders表增加一个 region 字段,再增加'connector'='print'类型的 print_sink 表,其字段和orders表的一样,数据库建表及初始化 SQL 位于 data/database 目录下。
下载本文源码后,可通过 Maven 运行单元测试,测试用例中的 catalog 名称是hive,database 名称是default。
$ cd flink-sql-security$ mvn test详细测试用例可查看源码中的单测RewriteDataMaskTest和ExecuteDataMaskTest,下面只描述两个案例。
4.1 测试 SELECT
4.1.1 输入 SQL
用户 A 执行下述 SQL:
SELECT order_id, customer_name, product_id, region FROM orders4.1.2 根据脱敏条件重新生成 SQL
输入 SQL 是一个简单 SELECT 语句,经过语法分析和语法校验后 FROM 类型是
SqlBasicCall,SQL 中的表名orders会被替换为完整的hive.default.orders,别名是orders。由于用户 A 针对字段
customer_name定义脱敏条件 MASK(对应函数是脱敏函数是mask),该字段在流程图中的步骤 8 中被改写为CAST(mask(customer_name) AS STRING) AS customer_name,其余字段未定义脱敏条件则保持不变。然后在步骤 8 的操作中,表名
hive.default.orders被改写成如下子查询,子查询两侧用括号()进行包裹,并且用AS 别名来增加表别名。
(SELECT order_id, order_date, CAST(mask(customer_name) AS STRING) AS customer_name, product_id, price, order_status, regionFROM hive.default.orders ) AS orders4.1.3 输出 SQL 和运行结果
最终执行的改写后 SQL 如下所示,这样用户 A 查询到的顾客姓名customer_name字段都是掩盖后的数据。
SELECT orders.order_id, orders.customer_name, orders.product_id, orders.regionFROM ( SELECT order_id, order_date, CAST(mask(customer_name) AS STRING) AS customer_name, product_id, price, order_status, region FROM hive.default.orders ) AS orders4.2 测试 INSERT-SELECT
4.2.1 输入 SQL
用户 A 执行下述 SQL:
INSERT INTO print_sink SELECT * FROM orders4.2.2 根据脱敏条件重新生成 SQL
通过自定义 Calcite DataMaskVisitor 访问生成的 AST,能找到对应的 SELECT 语句SELECT * FROM orders,注意在语法校验阶段 * 会被改写成表中所有字段。针对此 SELECT 语句的改写逻辑同上,不再阐述。
4.2.3 输出 SQL 和运行结果
最终执行的改写后 SQL 如下所示,注意插入到print_sink表的customer_name字段是掩盖后的数据。
INSERT INTO print_sink ( SELECT orders.order_id, orders.order_date, orders.customer_name, orders.product_id, orders.price, orders.order_status, orders.region FROM ( SELECT order_id, order_date, CAST(mask(customer_name) AS STRING) AS customer_name, product_id, price, order_status, region FROM hive.default.orders ) AS orders)



