

一、正确的直播姿势
文明直播受到一些平台规范、行业规范和国家法律法规的约束。
首先是每个直播平台都有响应的规范规范,比如禁止低俗、性暗示的行为。禁止男性赤裸上身,同时展示和露出纹身也不允许,所以今天大家只能看到把双手裸露出来,看不到我胸前的 HelloKitty 哈。
除了平台本身的规范,行业为了规范发展,也有一些规范约束主播的行为。包括主播不能过于暴露,不能穿情趣内衣,同时国家法律法规也有相当多的规定做这方面的约束。所以今天的我们是一个文明的直播,拒绝翻车。

二、近期业务增长带来的风险
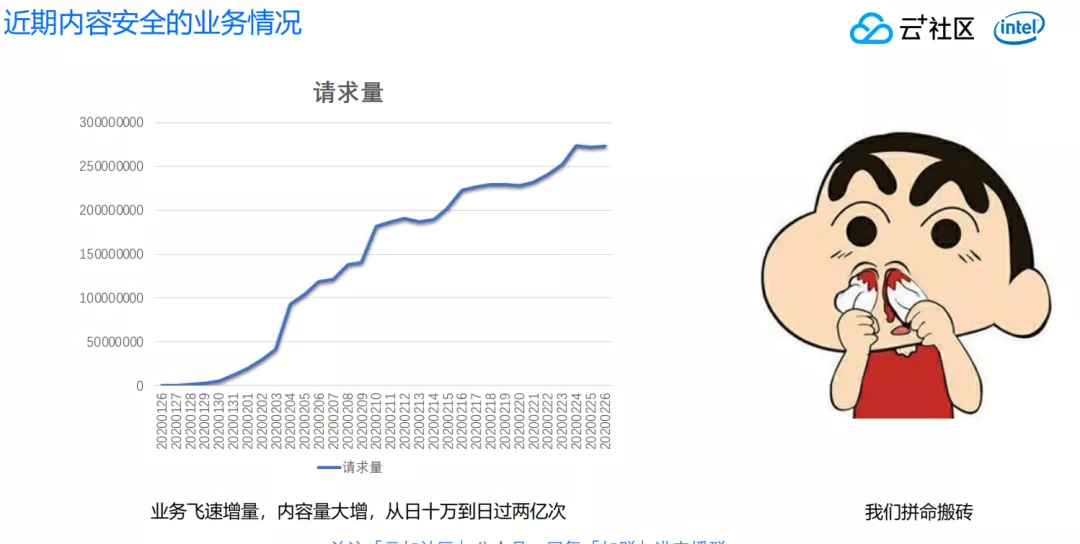
随着疫情的爆发,很多业务得到了始料不及的爆发。比如下图所示的业务,在 1 月 27、28 日的时候,每天大概是 10 万张图片的量级,但是到 2 月 26 日数据就已经突破了 2.5 亿张,整体的增长速度非常快。业务量大幅度增长之后,给我们带来非常多的工作,在搬砖过程中我们发现了大量平台当中违规的内容。
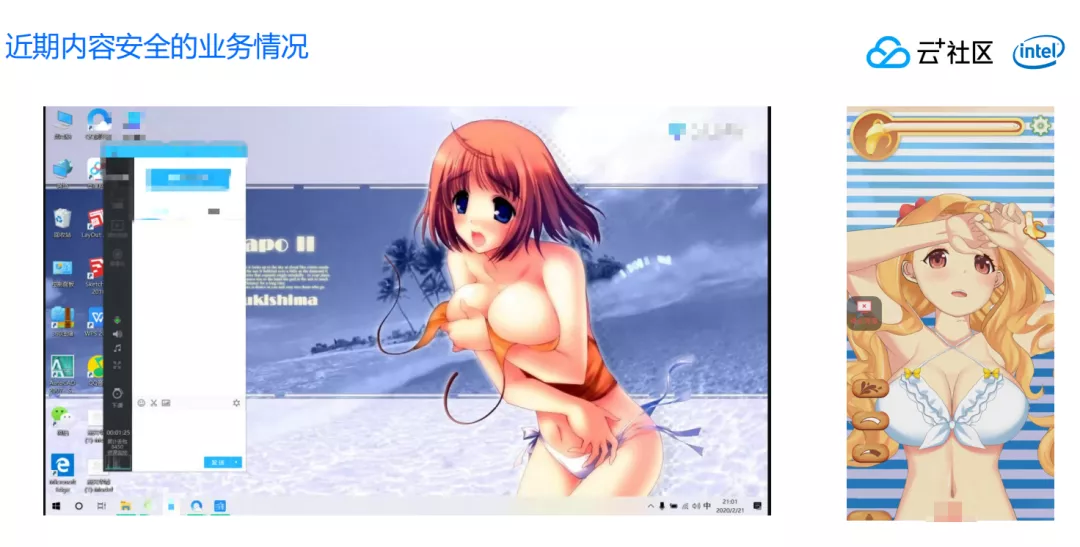
如下图所示的两个案例,这两张图片分别是性感图片和色情图片。左边被判定为性感图片,而右边的图片则会被判定为色情图片,这是为什么呢?我们会在下文详细解释。
三、多标签学习在图片安全中的应用
直播间可能会有很多内容涉及低俗问题,尤其是视觉方面。针对图片和视频的识别,随着互联网发展,技术也在不断演进,下面将介绍下在图片安全当中的技术演进。
1. 相同图片识别
互联网刚发展的时期,图片识别技术主要就是做相同图片的识别。什么意思呢?就是如果有一张图片已经被人工识别为是违规,比如色情的图片,会把该计算该图片的 MD5 然后保存起来,后面进来的照片会对比 MD5,看图片是不是一致。此类方式是通过比对二进制的内容看看是不是违规,但是却忽略了图片的表征特性,图片变大变小问题没有办法解决。

2. 相似图片识别
为了解决 MD5 库的短板,开发了基于传统的图像特征相似度想法,同样建立不良图片的库,能够识别经过旋转、拉伸和裁剪的变种的相似图片,通过这种方式能进一步识别变种的问题。图像相似度比对的方法考虑到了图像的底层特征,对同一幅图的几何变换(一般是仿射变换)具有一定的检出鲁棒性,但是它有两个主要的问题:
第一,针对恶意图片的打击,与相同图片识别一样,也总是具有滞后性。
第二,随着种子库规模增长,越来越多的图片加进去以后,检索效率也会成为很大的瓶颈。

3. 同类图片识别
随着 AI 技术的发展,利用深度学习的泛化领域,我们提出一种新的方式,同类图片的识别。
什么是同类图片识别呢?就是把图片安全当作大类的问题,把里面很多不同识别类型当作一个类,每一个识别类型用模型解决。把一个复杂领域分解成 N 个子领域,对于每个子领域单独列一个模型解决。

这个方式在刚开始的时候能够很有效解决互联网中传播的内容识别,尤其是经历了移动互联网之后,网民普遍拥有便携式的手机,能够随时随地拍摄照片,修改照片后进行传播,从而带来非常大的压力。随着 AI 技术应用,针对同类图片识别也得到了解决。
但是同类图片识别也会有问题存在,早期只依靠某几种模型就能够把大多数问题解决。但是随着安全对抗的深入,很多图片当中有一些敏感的内容或者元素,是属于很小的一个部位,或者在很小的一个区域,导致识别的难度非常大。如果针对每一个问题训练一个模型,就会带来非常大的算法、人员投入,同时针对这种小的问题,也需要搜集非常多的样本解决。
4. 图片语义识别
我们现在正在探讨一个新的方式来解决,那就是图片语义的识别。为什么需要图片语义的识别?就是为了解决灵活多变的需求,尝试以灵活多变的方式寻找不变的东西。基于图像识别客观存在的信息,通过语义信息构建这张图片表达的内容,通过 N 个模型解决 N+类的问题。

如上图所示的两张图片,有同样的特征,都含有刀,右上角的刀是在厨房里的菜刀,背景包括一些水果:胡萝卜、包菜,还有一个砧板。如果通过正常人判断可以识别出来这是一个正常的画面。但是如果我们仅仅根据里面有把刀就判定为违规图片,这显然是有问题的。下面图片中同样也有一把刀,这个刀不是长度有问题,而是出现的环境不一样。同样一把刀出现在不同环境下,我们需要通过语义识别,来弄清这张图片到底表达什么意思。
(1)多标签学习
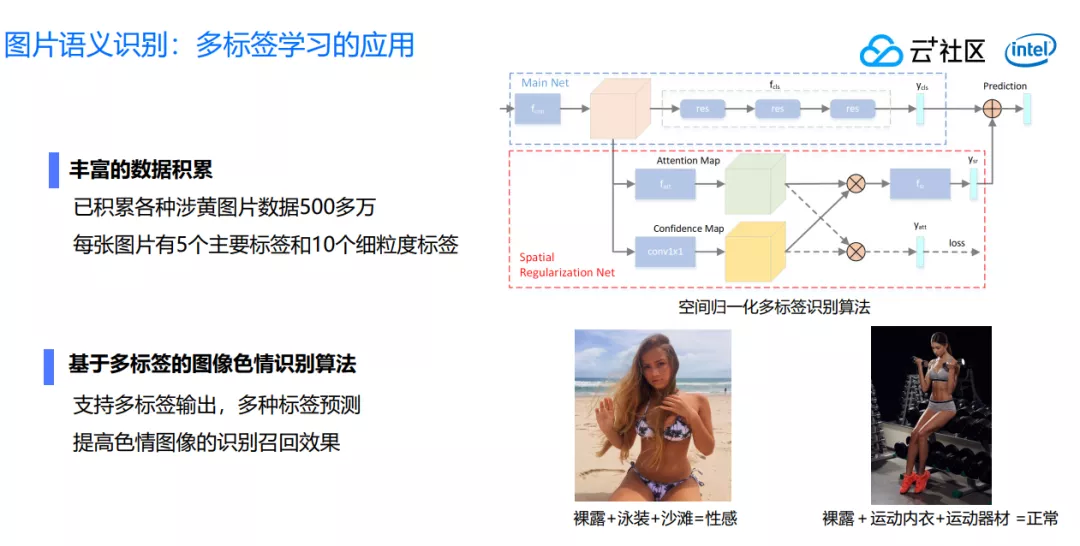
针对图片语义识别有很多相关联的技术,比如多标签学习。为什么需要多标签学习呢?因为通过得到一张图片上的不同标签,才能进一步了解图片想要表达的信息,通过足够多的图片构建图片语义信息理解图片最终表达的信息。目前我们已累积涉黄图片 500 多万张,每张图片有 5 个主标签,10 个细粒度标签,可以预测不同图片属于哪一种违规类型。
如下图所示的两张照片,第一张图人物身着比较裸露,但是背景是沙滩,如果是个人判断,我们完全可以认为是性感图片,我们希望机器也获得认知这个图片的过程。另外一张图片也是裸露的,在室内穿着内衣,而且伴有健身器材,我们也认为是正常图片,希望我们的模型、机器、算法像人一样识别出这是一张正常的图片。
(2)细粒度识别
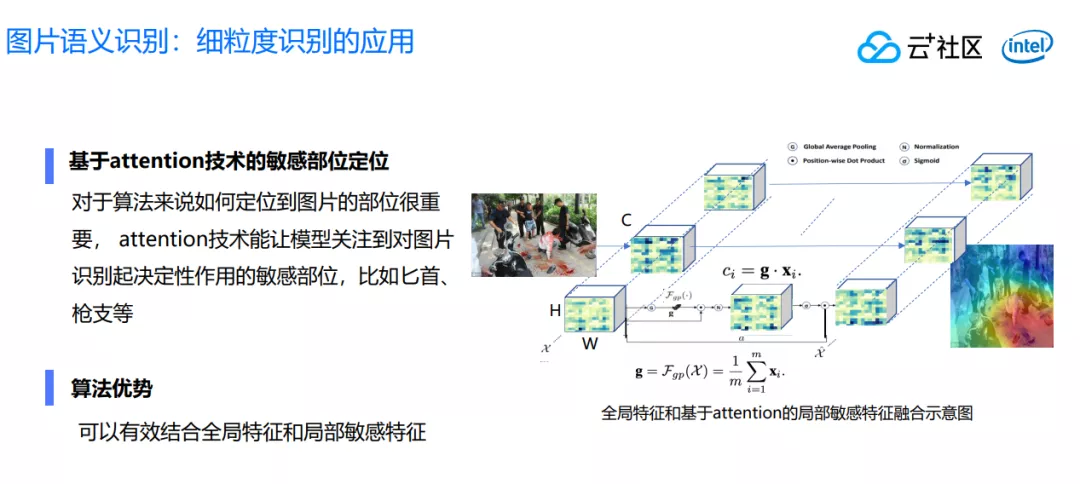
除了多标签学习外,涉及到另外一个技术——细粒度的识别。因为图片当中可能存在的一些微小区域,容易被我们忽略掉,但是使用这个技术之后,我们可以通过热力图标识出哪一个区域是比较热门的,那里就是需要我们算法和模型重点关注的区域。优势就是可以结合全区的特征和局部的敏感特征,这样就能避免有的模型算法会忽略掉局部的特征。
所以当我们面临的图片越来越复杂的时候,不仅需要我们有足够多的标签语义支撑,同时也要通过细粒度对足够细微的敏感特征做识别,所以我们这边创造性地把这两种技术结合起来用。
每一种图片处理方式都涉及特定领域和特定细分类的问题,每一种技术也都有优缺点。我们认为随着技术不断的迭代,老的技术也有一定的价值,可以在系统当中发挥相应作用。
四、色情音频与谩骂音频识别
下面主要介绍我们在色情音频和谩骂音频上的识别。
最近这段时间网上课程增长非常多,很多违规内容也随之产生。在一些案例中,虽然视频内容是正常的,但是里面发出的声音其实存在低俗信息。
下图所示的是我们在外网捕捉到的一个色情音频,从这里可以得到非常多的信息。如何判断一段音频表达内容到底是正常的呼吸和说话声,还是低俗的声音呢?下文会详细介绍对低俗语音声音涉黄的识别。
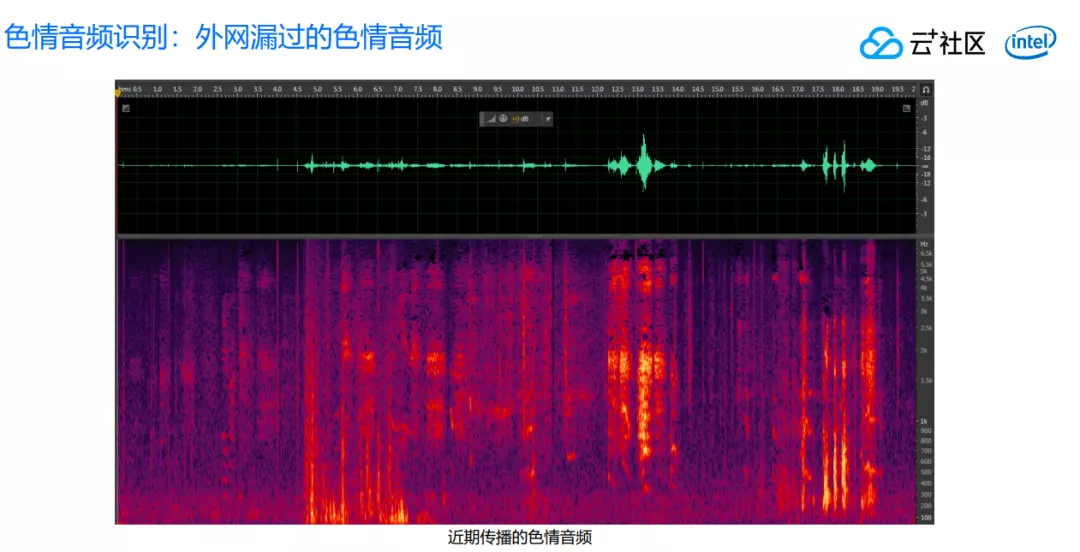
虽然声音涉黄是很复杂的问题,但是实际上可以通过很简单的技术来鉴别。就像把大象装到冰箱里一样,只需要分三步骤就可以解决。第一步打开冰箱,然后把大象装进去,最后把冰箱门关上。
1. 色情音频识别流程
音频分割模块采用自研的音频检测技术(VAD)对每帧语音给出语音/非语音标签,经过后处理后在较长静音处将音频切割为多个片段,作为后续的识别单元。
系统采用当前说话人识别领域主流的 x-vector embedding 模型做为主系统,对每个音频片段进行特征提取,通过 TDNN 网络和 Statistics Pooling 层,得到表征音频内容信息的 embedding。
在类别分类和结果整合阶段,表征每个音频片段的 embedding 通过后端分类器得到在不同类别上的得分,最后系统根据得分和片段时长,根据业务需要,汇总得到整条音频内容的识别识别结果和置信度。

过程是很简单的三步,但是里面涉及到的技术难点还是非常多的。其中非常重要一个点就是训练样本的采集。
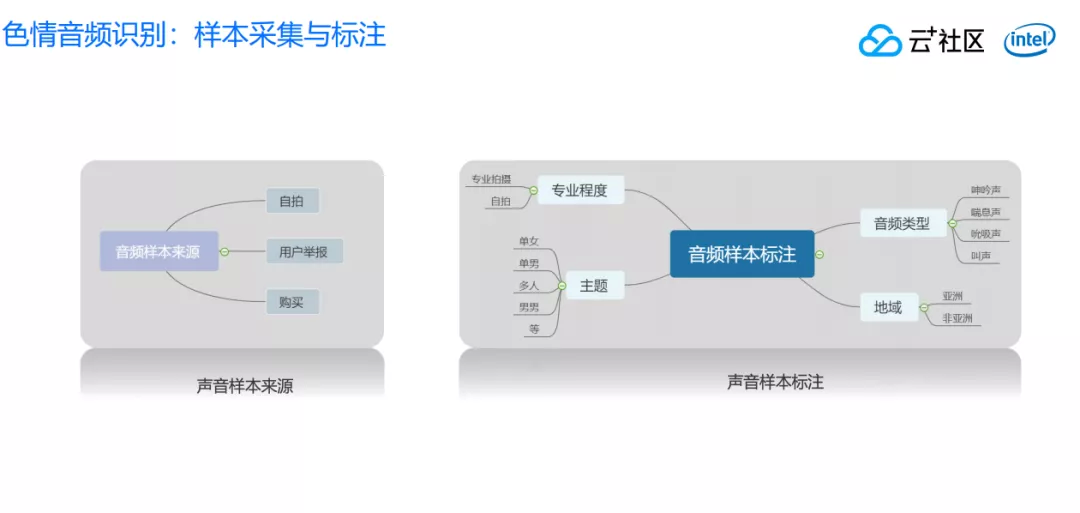
2. 样本采集与标注
音频这一块的处理相对图片来说隐蔽性更高,对于我们人工的标注、采集这一块工作量要求非常大。我们做了非常多的工作,确保能够获取足够多音频的样本,以及把这个样品做得足够细致的分类,提升最后的效果。
有了这个样本之后,经过对模型不断调整和训练才能持续提升识别效果。除了涉黄的音频,还有谩骂音频也需要识别。这就是我们的高性能可自定义多语种语音关键词系统,这个关键词系统也是分三步骤:第一是做特征提取,第二是声学建模,第三做解码器。

以上部分就是我们在色情音频与谩骂音频当中识别的一些介绍了。当然我们也会运用到一些其他的手段,比如把一段音频的内容全部转化成文本,再通过文本来识别,等等。
五、垃圾文本治理的思路和实践
另外其实在直播当中,很多评论区的弹幕和文本也需要做过滤,弹幕也有很多垃圾内容,这一块我们怎么做对抗呢?
首先我们来看一下对垃圾文本的治理,首先这里会存在一些特殊服务诱导信息的干扰,最常见的就是“加群”变成“+群”,群用拼音,数字用圆圈数字,内容有很多变体字的干扰,比如使用微信上的各种变体字,虽然第一眼看不出来,但是细细揣摩就知道里面意思。
其次就是很多同义词的干扰,除了微信的变体字,还有同音字,拆字的干扰。这些信息还有非常明显的聚集性,大批量的用户不断地再发送同样的垃圾内容。
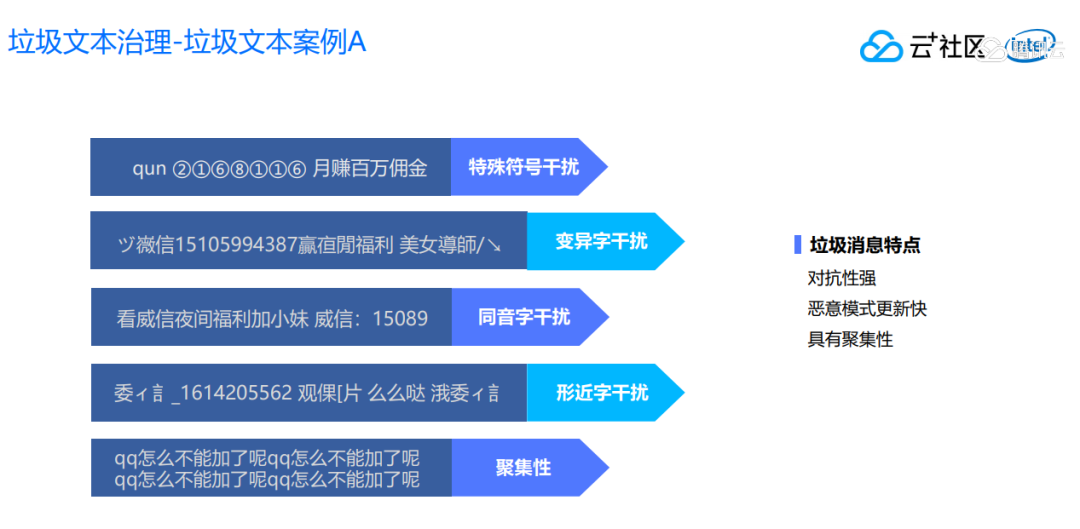
这种垃圾文本的特点就是它的对抗性强,恶意模式更新快,同时具有聚集性。我们怎么对这种垃圾文本做持续有效的对抗呢?我们的做法分两部分:
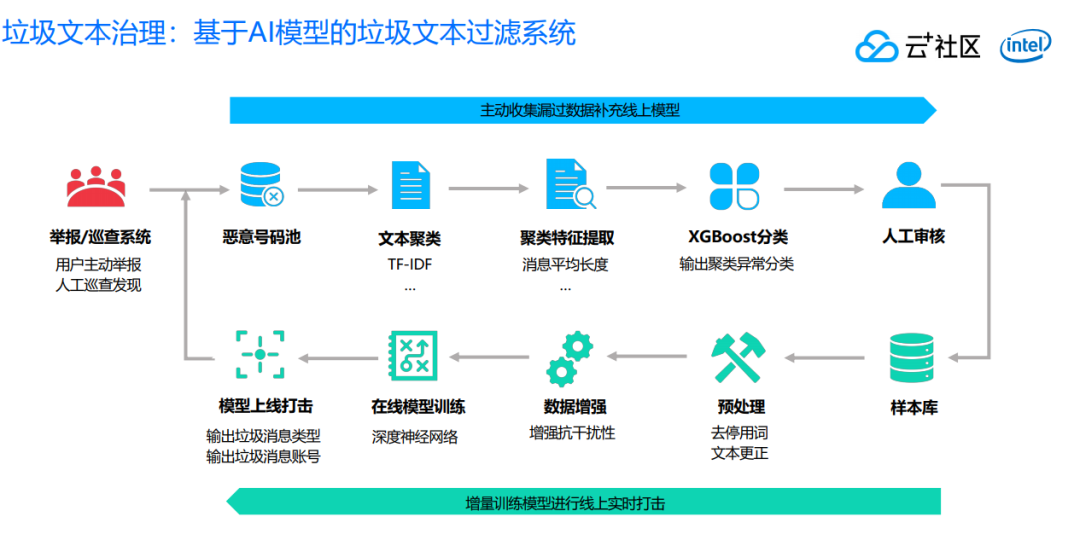
第一,我们对垃圾文本的治理分为线上部分和离线部分,线上主要是做增量的训练模型,进行线上实时打击。
对于线上打击,我们通过人工和预设置的方式进行样本收集,人工对样本进行标注,最后做预处理,做一些文本更正,拿到文本之后做数据增强。
为什么要做数据增强呢?因为垃圾文本其实具有非常多的变种,我们可以在做数据训练之前主动在训练样本当中加入一些变体,同音字,以及偏旁增加数据,这样通过模型训练能够有效做对抗。
对于模型训练,业界比较通用的,像 texcnn、fastcnn 都是针对不同场景解决这些问题的。有了模型之后就可以做线上打击,我们不仅仅会输出这一条文本的类型,到底是色情的,还是一个广告,还是属于谩骂信息。同时还会标识发送的 ID 是什么,为什么需要发送 ID,就是因为需要主动搜集漏过的数据来补充的线上模型。
我们可以这样假定,一个人他发了一次恶意内容,或者垃圾文本之后,他有很大概率不仅仅是只发了一次,如果我们把这个垃圾文本对应帐号的所有内容全部捞出来,就有可能找出我们漏过的东西做提升。
另外,我们有一套举报巡查的系统,可以提供一个入口给用户做主动举报。我们也会用人工巡查的方式做一些筛查,看是不是能够找出恶意的内容和帐号。在我们得到这批恶意帐号之后,把帐号所有的文本提取出来,做一些文本的聚类,进一步针对这些聚类的特征做一些提取。
比如说消息的长度,信息熵之类的,最后做一个分类,进行聚类异常分类,把文本最终给人工审核,标志 Logo 的样本,最后这些样本进入我们库。这就是我们线上做闭环的操作,好处就是线上和线下都是通过 AI 模型算法方式做主动打击,主动搜索漏过,降低人工投入,持续和黑产和恶意的用户做对抗。
虽然我们有了一整套线上加线下,以主动搜集、主动对抗的方式解决垃圾文本的系统,但是所有垃圾文本过滤还是少不了关键词系统,如何有效把关键词的价值发挥到最大,其实是有讲究的。
最简单是可以上一些分词的策略来降低误杀。另外很多关键词其实有一些组合的策略,关键词本身可能会有一些中性、负面的属性,对关键词进行分级分类可以降低误杀。
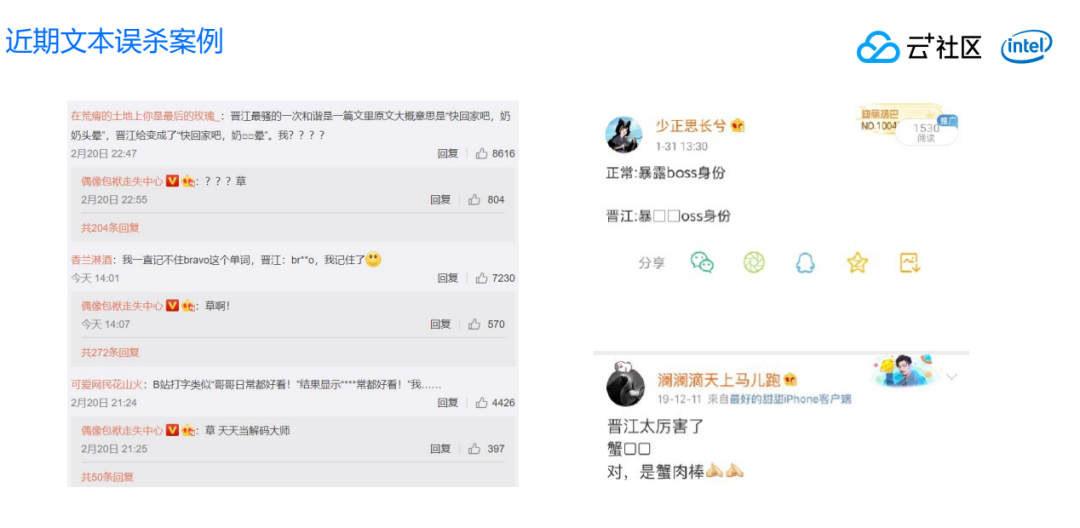
对于违规视频内容的处理,主要会从两个方面进行处理:
第一是做细粒度的截帧,识别图片是不是有涉黄广告违规内容,检测里面的台标和人物,判断这张图片是正常还是恶意的。
另外,我们会提取这段音频的内容,做色情音频或者谩骂音频的识别,或者是把音频全部转换成文本之后再做文本识别,基本上目前行业处理方式还是复用图片、音频、文本的方式做打击和对抗。
五、云上内容安全方案
虽然现在有很多的开源技术能够使用,我们也能够在互联网搜索很多样本,训练我们的模型,取得一定的效果。
但是内容安全在互联网发展开始之后,其实一直都是存在的,这是一个持续对抗的过程,我们想通过一朝一夕把这个问题完全解决掉是不可能的,必须构建一个复杂并且持续可运营的系统,才能够长期有效解决我们线上所面临到的各种文本、音频、图片、视频当中的问题。
我们的这一套系统,其实就是腾讯本身在内容安全领域长期积累下的经验,以及不断对一些 AI 新的技术做探索所沉淀出来的一整套内容风控的方案。
这个方案除了上文介绍的机器审核、模型识别、关键词识别、策略识别之外,还有辅助的一套人工识别机制,因为机器没有办法达到百分之百的准确,机器可能对某张图片有 95%、甚至 99%识别准确率,但是仍然会造成 1%的误杀,怎么解决这个误杀问题呢?可以通过少量的人工做辅助判断,减少对用户的干扰。这就是天御内容风控系统,我们同样支持做人工的辅助审核。
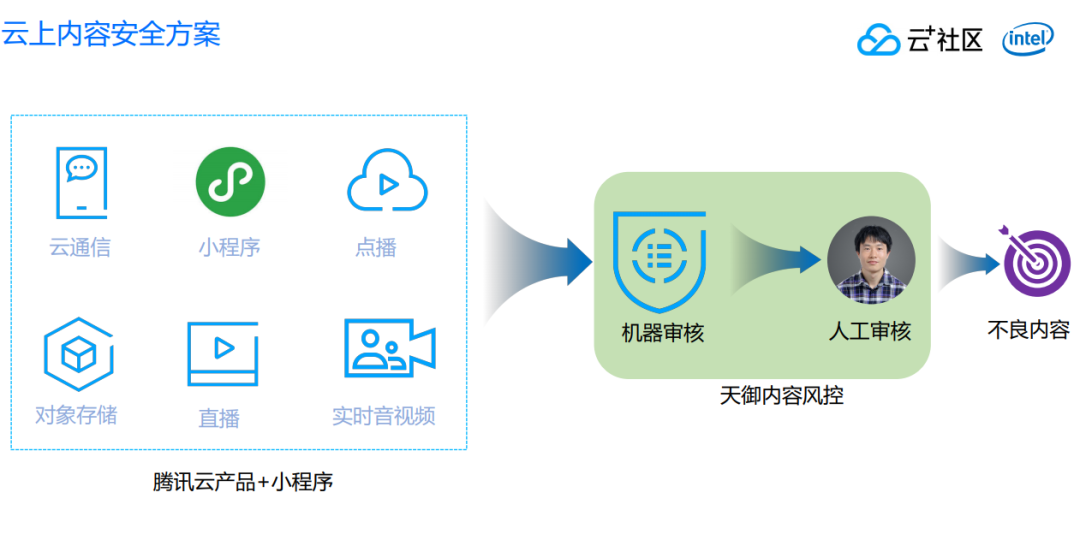
除此以外,我们还跟腾讯云产品和小程序做了绑定,不管使用哪一种腾讯云通信类产品,都可以无缝对接到我们的产品。只需要一键开启,在平台当中产生内容都可以通过风控系统做机器识别和人工的二次确认,最终告诉你哪一些内容是不良的,只要根据这些不良的内容,再制定相应的策略直接进行打击,开发者或者客户只需要专注于自己本身内容的良性运营就可以了。
除了与腾讯产品做了深度绑定以外,还跟微信小程序做了比较深度的结合。我们内容安全服务已经上线微信小程序服务市场,大家可以通过服务市场使用我们的服务。
最后给大家一个小小的建议,对于如何规范直播内容,我认为需要做好以下这三点防止意外翻车:
第一,清理桌面,比如在直播过程当中,尤其是讲课或者其他场景漏出自己的桌面,让大家看到里面非常杂乱,或者桌面背景有一些性感甚至其他类型的图片是不太好的。
第二,如果离开了直播间,需要及时关掉麦克风,避免有一些其他声音被采集到。
第三,也是非常重要一点,记得及时关掉摄像头,这样就能避免一些内容的意外流出,我们会发现有很多的违规内容并不是主播主动或者用户主动发出去的,而是不经意之间流露出来,所以做好这三点可以有效解决大多数问题。

六、Q&A
Q:声音鉴黄使用哪一些技术?
A:涉及自研的 VAD 音频检测技术、x-vector embedding 模型、TDNN 网络、SVM 分类器等。
Q:运行这些算法运用了多大的算力?
A:目前通用的 GPU 服务器,可以满足需求,当然随着你业务规模的增长,其实也会用到大量的服务器,当然这里对我们来说都不是问题,因为腾讯云有非常庞大的池子足以支持我们的各种算力使用。
Q:现在有没有人工审核平台?
A:我们现在除了提供机器审核之外,还会提供人工审核服务。为什么需要提供人工审核服务呢?第一,目前机器识别准确率没有办法做到 100%,还是有小部分识别出来的内容依赖于人工做审核。我们需要把人工审核纳入整体服务当中。第二,我们通过机器审核跟人工审核的方式其实可以做到更加好的闭环,人工审核的结果快速进入到机器当中做二次训练,这样能够自助提升识别的效果。同时,我们认为对于开发者、企业主来说,他们核心关注的问题应该是聚焦在业务本身的运营,所以可以把这块内容安全交给腾讯云来解决。
Q:开发好的小程序有上传视频内容,如何更好做好过滤?
A:其实我们已经把这一套系统通过小程序上面的服务市场给到广大小程序开发者使用,其次如果在微信小程序当中有短视频需求,腾讯云也有相应的点播产品,包括存储、加速以及转码、审核整套的流程,可以从内容创作到分发的全流程上帮助到大家,也是一个便捷的平台。
Q:语音涉及到检测吗?
A:涉及到低俗语言识别、通过关键词唤醒来识别谩骂,或者全量 ASR 来做音频的内容识别。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/6Pzq3ugrFbmlAI03mG8Zfw

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论