分布式存储系统通常采用多副本的方式来保证系统的可靠性,而多副本之间如何保证数据的一致性就是系统的核心。Ceph 号称统一存储,其核心 RADOS 既支持多副本,也支持纠删码。本文主要分析 Ceph 的多副本一致性协议。
1.pglog 及读写流程
Ceph 使用 pglog 来保证多副本之间的一致性,pglog 的示意图如下:pglog 主要是用来记录做了什么操作,比如修改,删除等,而每一条记录里包含了对象信息,还有版本。
Ceph 使用版本控制的方式来标记一个 PG 内的每一次更新,每个版本包括一个 (epoch,version) 来组成:其中 epoch 是 osdmap 的版本,每当有 OSD 状态变化如增加删除等时,epoch 就递增;version 是 PG 内每次更新操作的版本号,递增的,由 PG 内的 Primary OSD 进行分配的。
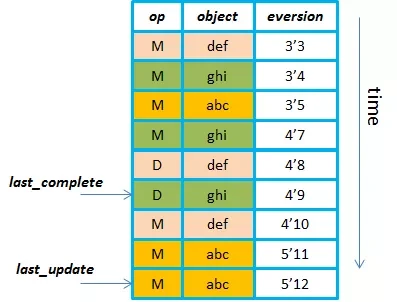
每个副本上都维护了 pglog,pglog 里最重要的两个指针就是 last_complete 和 last_update,正常情况下,每个副本上这两个指针都指向同一个位置,当出现机器重启、网络中断等故障时,故障副本的这两个指针就会有所区别,以便于来记录副本间的差异。
为了便于说明 Ceph 的一致性协议,先简要描述一下 Ceph 的读写处理流程。
写处理流程:
- client 把写请求发到 Primary OSD 上,Primary OSD 上将写请求序列化到一个事务中(在内存里),然后构造一条 pglog 记录,也序列化到这个事务中,然后将这个事务以 directIO 的方式异步写入 journal,同时 Primary OSD 把写请求和 pglog(pglog_entry 是由 primary 生成的)发送到 Replicas 上;
- 在 Primary OSD 将事务写到 journal 上后,会通过一系列的线程和回调处理,然后将这个事务里的数据写入 filesystem(只是写到文件系统的缓存里,会有线程定期刷数据),这个事务里的 pglog 记录(也包括 pginfo 的 last_complete 和 last_update)会写到 leveldb,还有一些扩展属性相关的也在这个事务里,在遍历这个事务时也会写到 leveldb;
- 在 Replicas 上,也是进行类似于 Primary 的动作,先写 journal,写成功会给 Primary 发送一个 committed ack,然后将这个事务里的数据写到 filesystem,pglog 与 pginfo 写到 leveldb 里,写完后会给 Primary 发送另外一个 applied ack;
- Primary 在自己完成 journal 的写入时,以及在收到 Replica 的 committed ack 时都会检查是否多个副本都写入 journal 成功了,如果是则向 client 端发送 ack 通知写完成;Primary 在自己完成事务写到文件系统和 leveldb 后,以及在收到 replica 的 applied ack 时都会检查是否多个副本都写文件系统成功,如果是则向 client 端发送 ack 通知数据可读;
对读流程来说,就比较简单,都是由 Primary 来处理,这里就不多说了。
2. 故障恢复
Ceph 在进行故障恢复的时候会经过 peering 的过程。简要来说,peering 就是对比各个副本上的 pglog,然后根据副本上 pglog 的差异来构造 missing 列表,然后在恢复阶段就可以根据 missing 列表来进行恢复了。peering 是按照 pg 为单位进行的,在进行 peering 的过程中,I/O 请求是会挂起的;当进行完 peering 阶段进入 recovery 阶段时,I/O 可以继续进行。不过当 I/O 请求命中了 missing 列表的时候,对应的这个待恢复的对象会优先进行恢复,当这个对象恢复完成后,再进行 I/O 的处理。
因为 pglog 记录数有限制,当对比各个副本上的 pglog 时,发现故障的副本已经落后太多了,这样就无法根据 pglog 来恢复了,所以这种情况下就只能全量恢复,称为 backfill。坏盘坏机器或者集群扩容时也会触发 backfill,这里不做介绍,后续单独一篇文章来进行分析。
基于 pglog 的一致性协议包含两种恢复过程,一个是 Primary 挂掉后又起来的恢复,一种是 Replica 挂掉后又起来的恢复。
2.1 Primary 故障恢复
(点击放大图像)

简单起见,图中的数字就表示 pglog 里不同对象的版本。
- 正常情况下,都是由 Primary 处理 client 端的 I/O 请求,这时,Primary 和 Replicas 上的 last_update 和 last_complete 都会指向 pglog 最新记录;
- 当 Primary 挂掉后,会选出一个 Replica 作为“临时主”,这个“临时主”负责处理新的读写请求,并且这个时候“临时主”和剩下的 Replicas 上的 last_complete 和 last_update 都更新到该副本上的 pglog 的最新记录;
- 当原来的 Primary 又重启时,会从本地读出 pginfo 和 pglog,当发现 last_complete 因此将该对象加到 missing 列表里;
- Primary 发起 peering 过程,即“抢回原来的主”,选出权威日志,一般就是“临时主”的 pglog,将该权威日志获取过来,与自己的 pglog 进行 merge_log 的步骤,构建出 missing 列表,并且更新自己的 last_update 为最新的 pglog 记录(与各个副本一致),这个时候 last_complete 与 last_update 之间的就会加到 missing 列表,并且 peering 完成后会持久化 last_complete 和 last_update;
- 当有新的写入时,仍然是由 Primary 负责处理,会更新 last_update,副本上会同时更新 last_complete,与此同时,Primary 会进行恢复,就是从其他副本上拉取对象数据到自己这里进行恢复,每当恢复完一个时,就会更新自己的 last_complete(会持久化的),当所有对象都恢复完成后,last_complete 就会追上 last_update 了。
- 当恢复过程中,Primary 又挂了再起来恢复时,先读出本地 pglog 时就会根据自己的 last_complete 和 last_update 构建出 missing 列表,而在 peering 的时候对比权威日志和本地的 pglog 发现权威与自己的 last_update 都一样,peering 的过程中就没有新的对象加到 missing 列表里,总的来说,missing 列表就是由两个地方进行构建的:一个是 osd 启动的时候 read_log 里构建的,另一个是 peering 的时候对比权威日志构建的。
2.2 Replica 故障恢复
(点击放大图像)

与Primary 的恢复类似,peering 都是由Primary 发起的,Replica 起来后也会根据pglog 的last_complete 和last_update 构建出replica 自己的missing,然后Primary 进行peering 的时候对比权威日志(即自身)与故障replica 的日志,结合replica 的missing,构建出peer_missing,然后就遍历peer_missing 来恢复对象。然后新的写入时会在各个副本上更新last_complete 和last_update,其中故障replica 上只更新last_update。恢复过程中,每恢复完一个对象,故障replica 会更新last_complete,这样所有对象都恢复完成后,replica 的last_complete 就会追上last_update。
如果恢复过程中,故障replica 又挂掉,然后重启后进行恢复的时候,也是先读出本地log,对比last_complete 与last_update 之间的pglog 记录里的对象版本与本地读出来的该对象版本,如果本地不是最新的,就会加到missing 列表里,然后Primary 发起peering 的时候发现replica 的last_update 是最新的,peering 过程就没有新的对象加到peer_missing 列表里,peer_missing 里就是replica 自己的missing 里的对象。
感谢魏星对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




