

编者按:本文节选自华章科技大数据技术丛书 《Apache Kylin 权威指南(第 2 版)》一书中的部分章节。
剪枝优化工具
使用衍生维度
首先观察下面这个维度表,如图 1 所示。
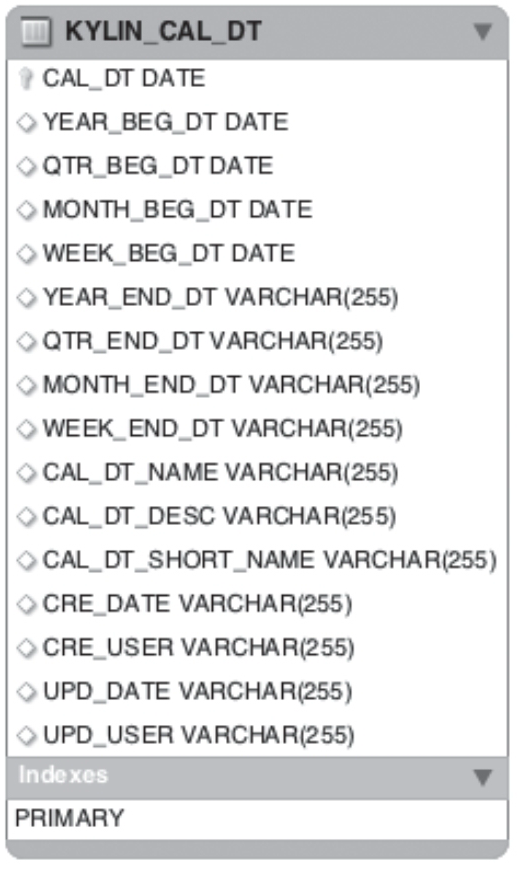
图 1 一个维度表
这是一个常见的时间维度表,里面充斥着各种用途的时间维度,如每个日期对应的星期,每个日期对应的月份等。这些维度可以被分析师用来灵活地进行各个时间粒度上的聚合分析,而不需要进行额外的上卷操作。但是如果为了这个目的一下子引入这么多维度,会导致 Cube 中 Cuboid 的总数量呈现爆炸式的增长,往往得不偿失。
在实际使用中,可以在维度中只放入这个维度表的主键(在底层实现中,我们更偏向使用事实表上的外键,因为在 Inner Join 的情况下,事实表外键和维度表主键是一致的,而在 Left Join 的情况下事实表外键是维度表主键的超集),也就是只物化按日期(CAL_DT)聚合的 Cuboid。当用户需要在更高的粒度如按周、按月来进行聚合时,在查询时会获取按日期聚合的 Cuboid 数据,并在查询引擎中实时地进行上卷操作,那么就达到了牺牲一部分运行时性能来节省 Cube 空间占用的目的。
Kylin 将这样的理念包装成一个简单的优化工具—衍生维度。将一个维度表上的维度设置为衍生维度,则这个维度不会参与预计算,而是使用维度表的主键(其实是事实表上相应的外键)来替代它。Kylin 会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。虽然听起来有些复杂,但是使用起来其实非常简单,在创建 Cube 的 Cube designer 第二步添加维度的时候,选择“Derived”而非“Normal”,如图 2 所示。
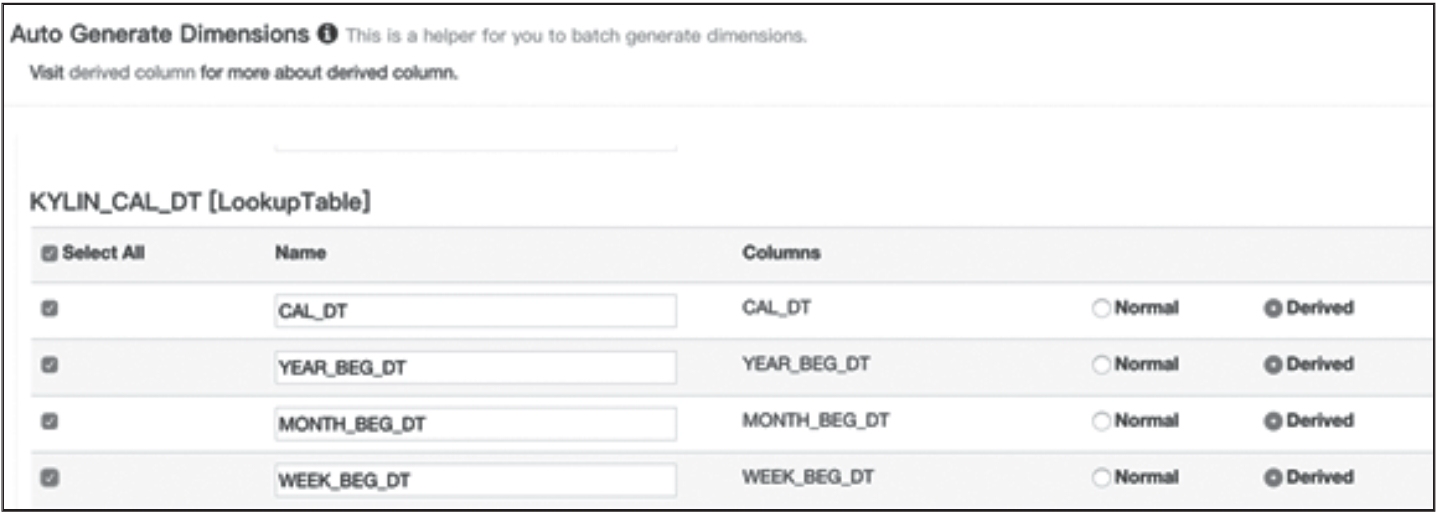
图 2 添加衍生维度
衍生维度在 Cube 中不参加预计算,事实上如果前往 Cube Designer 的 Advanced Setting,在 Aggregation Groups 和 Rowkeys 部分也完全看不到这些衍生维度,甚至在这些地方也找不到维度表 KYLIN_CAL_DT 的主键,因为如前所述,Kylin 实际上是用事实表上的外键作为这些衍生维度背后真正的有效维度的,在前面的例子中,事实表与 KYLIN_CAL_DT 通过以下方式连接:
因此,在 Advanced Setting 的 Rowkeys 部分就会看到 PART_DT 而看不到 CAL_DT,更看不到那些 KYLIN_\CAL_DT 表上的衍生维度,如图 3 所示。
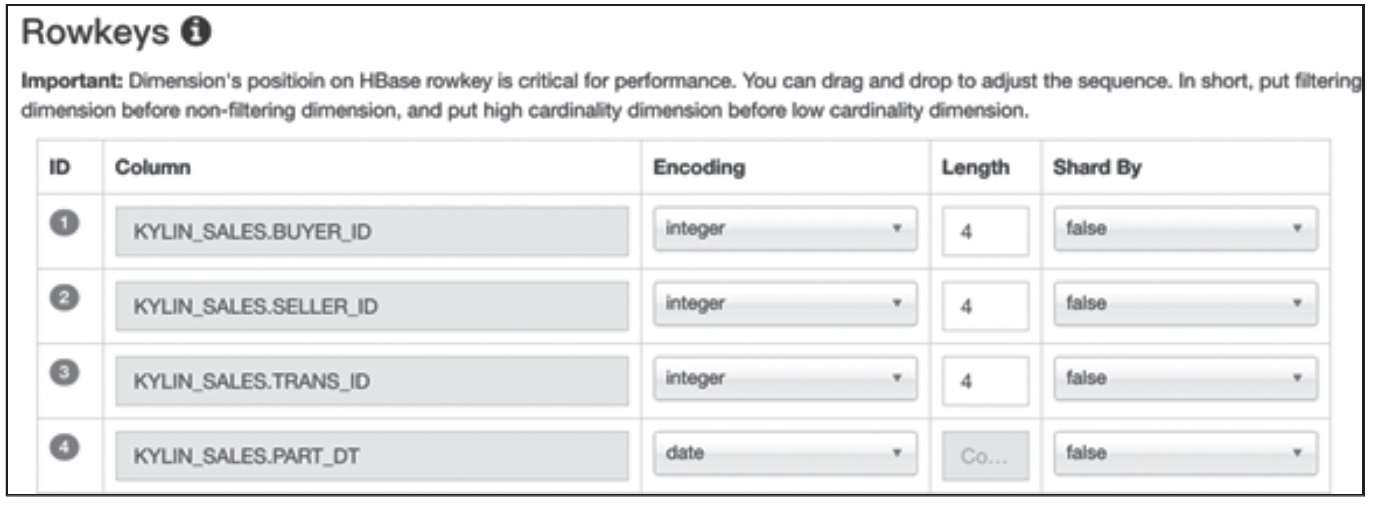
图 3 PART\_DT 外键在 Rowkeys 中
虽然衍生维度具有非常大的吸引力,但也并不是说所有的维度表上的维度都得变成衍生维度,如果从维度表主键到某个维度表维度所需的聚合工作量非常大,如从 CAT_DT 到 YEAR_BEG_DT 基本上需要 365 : 1 的聚合量,那么将 YERR_BEG_DT 作为一个普通的维度,而不是衍生维度可能是一种更好的选择。这种情况下,YERR_BEG_DT 会参与预计算,也会有一些包含 YERR_BEG_DT 的 Cuboid 被生成。
聚合组
聚合组(Aggregation Group)是一个强大的剪枝工具,可以在 Cube Designer 的 Advanced Settings 里设置不同的聚合组。聚合组将一个 Cube 的所有维度根据业务需求划分成若干组(当然也可以只有一个组),同一个组内的维度更可能同时被同一个查询用到,因此表现出更加紧密的内在关联。不同组之间的维度在绝大多数业务场景里不会用在同一个查询里,因此只有在很少的 Cuboid 里它们才有联系。所以如果一个查询需要同时使用两个聚合组里的维度,一般从一个较大的 Cuboid 在线聚合得到结果,这通常也意味着整个查询会耗时较长。
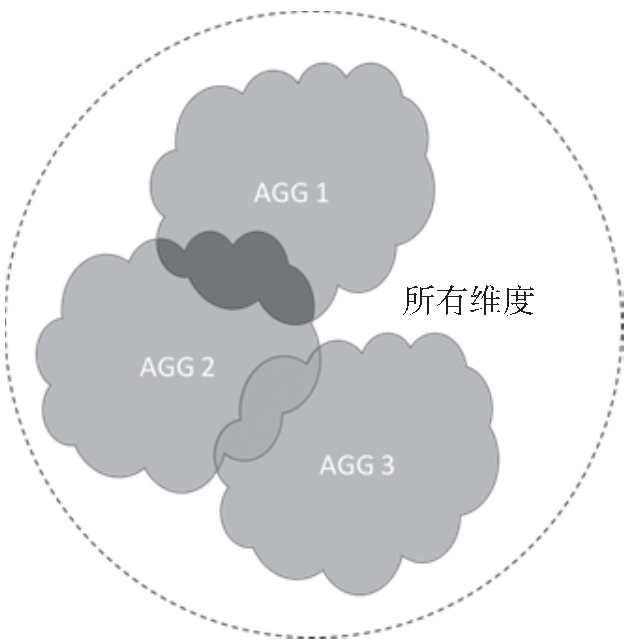
图 4 聚合组重叠示意
每个分组的维度集合是 Cube 的所有维度的一个子集,分组之间可能有相同的维度,也可能完全没有相同的维度。每个分组各自独立地根据自身的规则产生一批需要被物化的 Cuboid,所有分组产生的 Cuboid 的并集就形成了 Cube 中全部需要物化的 Cuboid。不同的分组有可能会贡献出相同的 Cuboid,构建引擎会察觉到这点,并且保证每一个 Cuboid 无论在多少个分组中出现,都只会被物化一次,如图 4 所示。
举例来说,假设有四个维度 A、B、C、D,如果知道业务用户只会进行维度 AB 的组合查询或维度 CD 的组合查询,那么该 Cube 可以被设计成两个聚合组,分别是聚合组 AB 和聚合组 CD。如图 5 所示,生成的 Cuboid 的数量从 个缩减成 8 个。
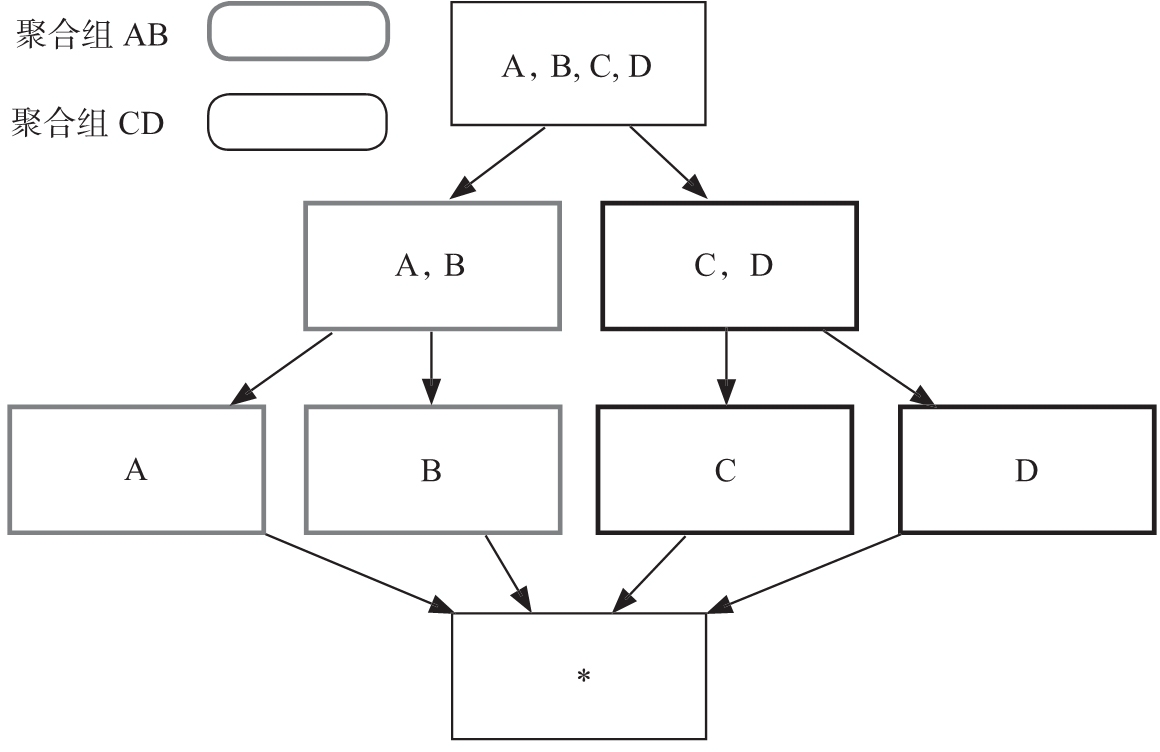
图 5 两个聚合组示意
假设创建了一个分析交易数据的 Cube,它包含以下维度:顾客 ID(buyer_id)、交易日期(cal_dt)、付款的方式(pay_type)和买家所在的城市(city)。有时分析师需要通过分组聚合 city 、cal_dt 和 pay_type 来获知不同消费方式在不同城市的情况;有时分析师需要通过聚合 city、cal_dt 和 buyer_id,来查看不同城市的顾客的消费行为。在上述实例中,推荐建立两个聚合组,包含的维度和方式如图 6 所示。
聚合组 1:包含维度 [cal_dt, city, pay_type]
聚合组 2:包含维度 [cal_dt, city, buyer_id]
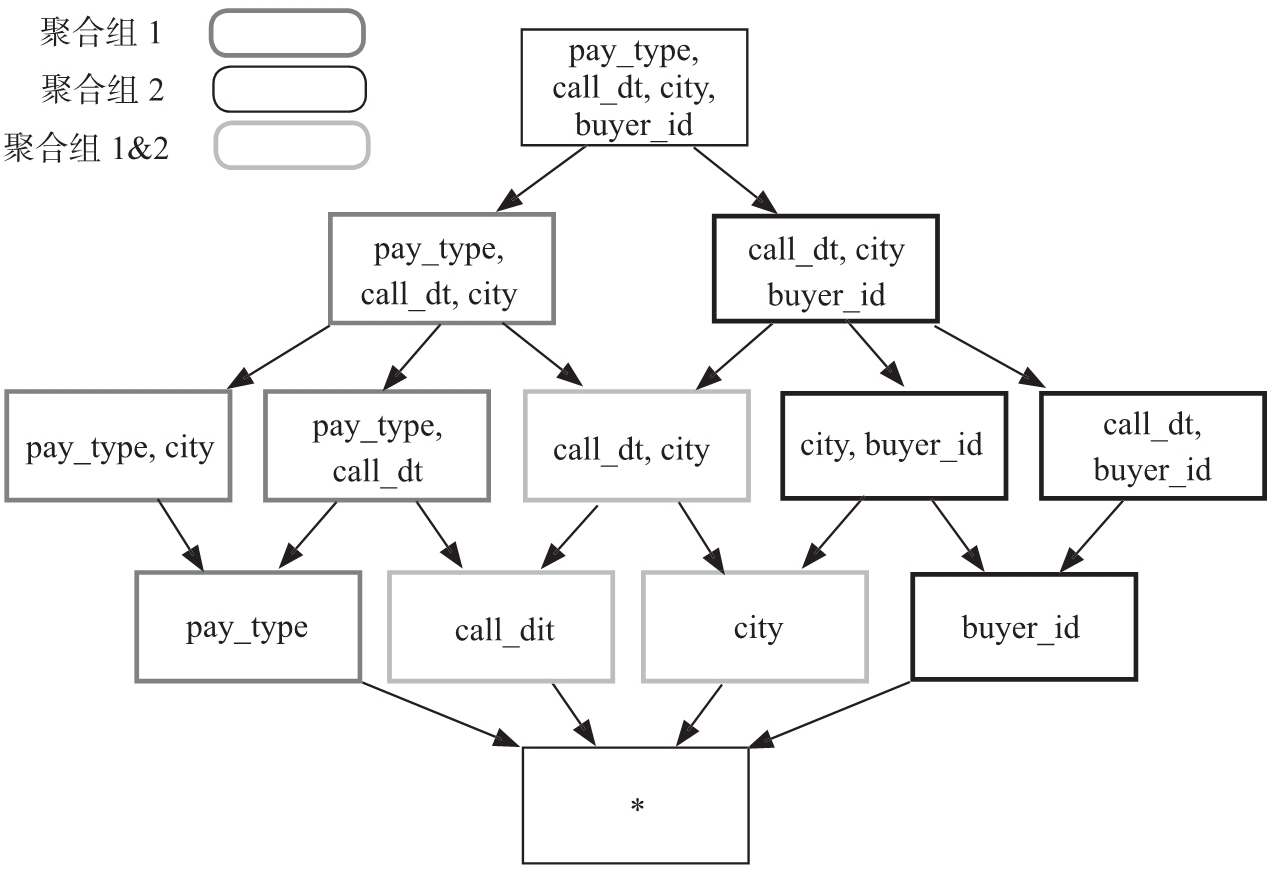
图 6 某交易场景的聚合组实例
可以看到,这样设置聚合组后,组之间会有重合的 Cuboid(上图浅灰色部分),对于这些 Cuboid 只会构建一次。在不考虑其他干扰因素的情况下,这样的聚合组设置将节省不必要的 3 个 Cuboid: [pay_type, buyer_id]、[city, pay_type, buyer_id]和[cal_dt, pay_type, buyer_id],这样就节省了存储资源和构建的执行时间。
在执行查询时,分几种情况进行讨论:
情况 1(分组维度在同一聚合组中):
将从 Cuboid [cal_dt, city, pay_type]中获取数据。
情况 2(分组维度在两个聚合组交集中):
将从 Cuboid [cal_dt, city]中获取数据,可以看到这个 Cuboid 同时属于两个聚合组,这对查询引擎是透明的。
情况 3 如果有一条不常用的查询(分组维度跨越了两个聚合组):
没有现成的完全匹配的 Cuboid,此时,Kylin 会先找到包含这两个维度的最小的 Cuboid,这里是 Base Cuboid [pay_type,cal_dt,city,buyer_id],通过在线聚合的方式,从 Case Cuboid 中计算出最终结果,但会花费较长的时间,甚至有可能造成查询超时。
必需维度
如果某个维度在所有查询中都会作为 group by 或者 where 中的条件,那么可以把它设置为必需维度(Mandatory),这样在生成 Cube 时会使所有 Cuboid 都必须包含这个维度,Cuboid 的数量将减少一半。
通常而言,日期维度在大多数场景下可以作为必需维度,因为一般进行多维分析时都需要设置日期范围。
再次,如果某个查询不包含必需维度,那么它将基于某个更大的 Cuboid 进行在线计算以得到结果。
层级维度
如果维度之间有层级关系,如国家–省–市这样的层级,我们可以在 Cube Designer 的 Advanced Settings 里设置层级维度。注意,需要按从大到小的顺序选择维度。
查询时通常不会抛开上级节点单独查询下级节点,如国家–省–市的维度组合,查询的组合一般是「国家」「国家,省」「国家,省,市」。因为城市会有重名,所以不会出现「国家,市」或者[市]这样的组合。因此将国家(Country)、省(Province)、市(City)这三个维度设为层级维度后,就只会保留 Cuboid[Country, Province,City],[Country, Province],[Country]这三个组合,这样能将三个维度的 Cuboid 组合数从 8 个减至 3 个。
层级维度的适用场景主要是一对多的层级关系,如地域层级、机构层级、渠道层级、产品层级。
如果一个查询没有按照设计来进行,如 select Country,City,count(*) from table group by Country,City,那么这里不能回答这个查询的 Cuboid 会从最接近的 Cuboid[Country, Province, City]进行在线计算。显而易见,由于[Country, Province, City]和[Country, City]之间相差的记录数不多,这里在线计算的代价会比较小。
联合维度
联合维度(Joint Dimension)一般用在同时查询几个维度的场景,它是一个比较强力的维度剪枝工具,往往能把 Cuboid 的总数降低几个数量级。
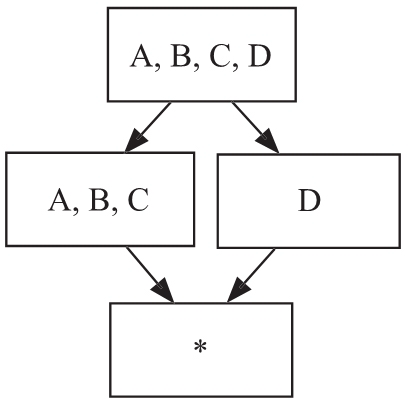
图 7 联合维度示例
举例来说,如果用户的业务场景中总是同时进行 A、B、C 三个维度的查询分析,而不会出现聚合 A、B 或者聚合 C 这些更上卷的维度组合,那么这类场景就是联合维度所适合的。可以将维度 A、B 和 C 定义为联合维度,Kylin 就仅仅会构建 Cuboid [A,B,C],而 Cuboid [A,B][B,C] [A]等都不会被生成。最终的 Cube 结果如 7 所示,Cuboid 的数量从 16 个减至 4 个。
假设创建一个交易数据的 Cube,它具有很多普通的维度,像是交易日期 cal_dt、交易的城市 city、顾客性别 sex_id 和支付类型 pay_type 等。分析师常用的分析总是同时聚合交易日期 cal_dt、交易的城市 city 和顾客性别 sex_id,有时可能希望根据支付类型进行过滤,有时又希望看到所有支付类型下的结果。那么,在上述实例中,推荐设立一组聚合组,并建立一组联合维度,所包含的维度和组合方式下:
聚合组(Aggregation Group):[cal_dt, city, sex_id,pay_type]
联合维度(Joint Dimension): [cal_dt, city, sex_id]
情况 1(查询包含所有的联合维度):
它将从 Cuboid [cal_dt, city, sex_id]中直接获取数据。
情况 2(如果有一条不常用的查询,只聚合了部分联合维度):
没有现成的完全匹配的 Cuboid,Kylin 会通过在线计算的方式,从现有的 Cuboid [cal_dt, city, sex_id 中计算出最终结果。
联合维度的适用场景:
维度经常同时在查询 where 或 group by 条件中同时出现,甚至本来就是一一对应的,如 customer_id 和 customer_name,将它们组成一个联合维度。
将若干个低基数(建议每个维度基数不超过 10,总的基数叉乘结果小于 10000)的维度合并组成一个了联合维度,可以大大减少 Cuboid 的数量,利用在线计算能力,虽然会在查询时多耗费有限的时间,但相比能减少的存储空间和构建时间而言是值得的。
必要时可以将两个有强关系的高基维度组成一个联合维度,如合同日期和入账日期。
可以将查询时很少使用的若干维度组成一个联合维度,在少数查询场景中承受在线计算的额外时间消耗,但能大大减少存储空间和构建时间。
以上这些维度剪枝操作都可以在 Cube Designer 的 Advanced Setting 中的 Aggregation Groups 区域完成,如图 8 所示。
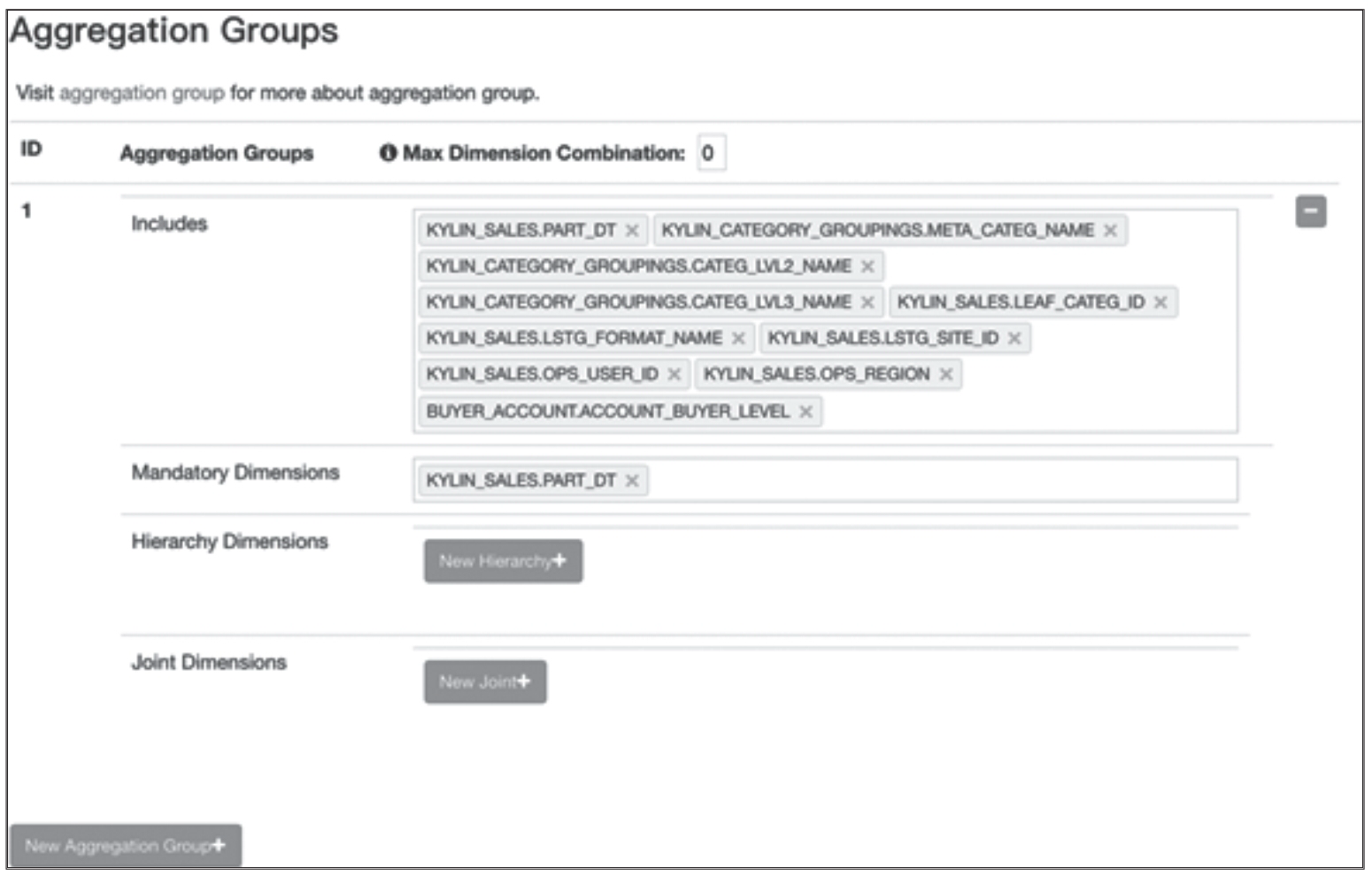
图 8 Advanced Settings 中的 Aggregation Groups
从图 8 中可以看到,目前 Cube 中只有一个分组,点击左下角的 “New Aggregation Group”按钮可以添加一个新的分组。在某一分组内,首先需要指定这个分组包含(Include)哪些维度,然后才可以进行必需维度、层级维度和联合维度的创建。除了“Include”选项,其他三项都是可选的。此外,还可以设置“Max Dimension Combination”(默认为 0,即不加限制),该设置表示对聚合组的查询最多包含几个维度,注意一组层级维度或联合维度计为一个维度。在生成聚合组时会不生成超过“Max Dimension Combination”中设置的数量的 Cuboid,因此可以有效减少 Cuboid 的总数。
聚合组的设计非常灵活,甚至可以用来描述一些极端的设计。假设我们的业务需求非常单一,只需要某几个特定的 Cuboid,那么可以创建多个聚合组,每个聚合组代表一个 Cuboid。具体的方法是在聚合组中先包含某个 Cuboid 所需的所有维度,然后把这些维度都设置为强制维度。这样当前的聚合组就只包含我们想要的那一个 Cuboid 了。
再如,有时我们的 Cube 中有一些基数非常大的维度,如果不做特殊处理,它会和其他维度进行各种组合,从而产生大量包含它的 Cuboid。所有包含高基数维度的 Cuboid 在行数和体积上都会非常庞大,这会导致整个 Cube 的膨胀率过大。如果根据业务需求知道这个高基数的维度只会与若干个维度(而不是所有维度)同时被查询,那么就可以通过聚合组对这个高基数维度做一定的“隔离”。
我们把这个高基数的维度放入一个单独的聚合组,再把所有可能会与这个高基数维度一起被查询到的其他维度也放进来。这样,这个高基数的维度就被“隔离”在一个聚合组中了,所有不会与它一起被查询到的维度都不会和它一起出现在任何一个分组中,也就不会有多余的 Cuboid 产生。这大大减少了包含该高基数维度的 Cuboid 的数量,可以有效地控制 Cube 的膨胀率。
图书简介:https://item.jd.com/12566389.html

相关阅读:
Apache Kylin权威指南(五):Getting Started
Apache Kylin权威指南(六):Cuboid剪枝优化

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论