

导读:今天分享篇 Youtube 推荐排序模块的论文 from RECSYS 2019:
Recommending What Video to Watch Next: A Multitask Ranking System
https://dl.acm.org/citation.cfm?id=3346997
之前内部查找论文时就注意到了这篇文章,从摘要中就可以看出这应该是在 youtube 上实践的一篇文章,并且内容应该比较实在。不过那时候文章还没有发布出来,中秋最后一天发现有 pdf 发出来了,便果断看了下。
看完后发现不出所料,确实是一篇实用的文章,本身虽然没有提出特别新颖的结构,不过内容很实在,也 work,算是推荐系统中排序模块很通俗易懂的文章了,主要聚焦于大规模视频推荐中的排序阶段,介绍一些比较实在的经验和教训,解决 Multitask Learning, Selection Bias 这两个排序系统的关键点。
一般推荐系统排序模块的进化路径是:ctr 任务 -> ctr+ 时长 -> mulittask & selection bias。
所以格外推荐还在推荐系统起步阶段的同学读一读这篇 paper,下边简单抽文章的重点介绍下。
真实场景中有很多挑战:
有很多不同甚至是冲突的优化目标,比如我们不仅希望用户观看,还希望用户能给出高评价并分享。
系统中经常有一些隐性偏见,比如用户是因为视频排得靠前而点击 & 观看,而非用户确实很喜欢。因此用之前模型产生的数据会引发 bias,从而形成一个反馈循环,越来越偏。如何高效有力地去解决还是个尚未解决的问题。
本文还是一个 NN 的架构去作为排序模块,如图 1 基于 Wide&Deep 的架构 + Multi-gate Mixture-of-Experts ( MMOE )。MMOE 也是谷歌的一篇做 multitask 的论文,对于不是那么一致的多目标上效果比 shared bottom 的结构好些,不过实际效果还是比较分业务场景,有兴趣的同学可以读读论文、实践下。另外,还引入了个 shallow tower 去建模并移除 selection bias。作者介绍将其应用于线上大规模视频平台上是有显著提升的。
先说下多目标,分为两类:
engagement objectives:点击以及于视频观看等参与度目标。
satisfaction objectives:给 Youtube 上喜欢的某个视频打分。
对于存在潜在冲突的目标,通过 MMOE 的结构来解决,通过门结构来选择性的从输入获取信息。
为了减少 selection bias ( 比如 position bias ),用图 1 左边的浅层塔,接收 selection bias 作为输入,比如排序位置,输出标量作为主模型最终预测的偏差项。 模型将目标分解为两部分,一个是无偏的用户偏好,另一个是倾向分。模型结构可以看做是 Wide&Deep 的扩展,浅层塔代替 Wide 部分。因为直接学习 shallow tower,所以不用随机实验去获得倾向分。
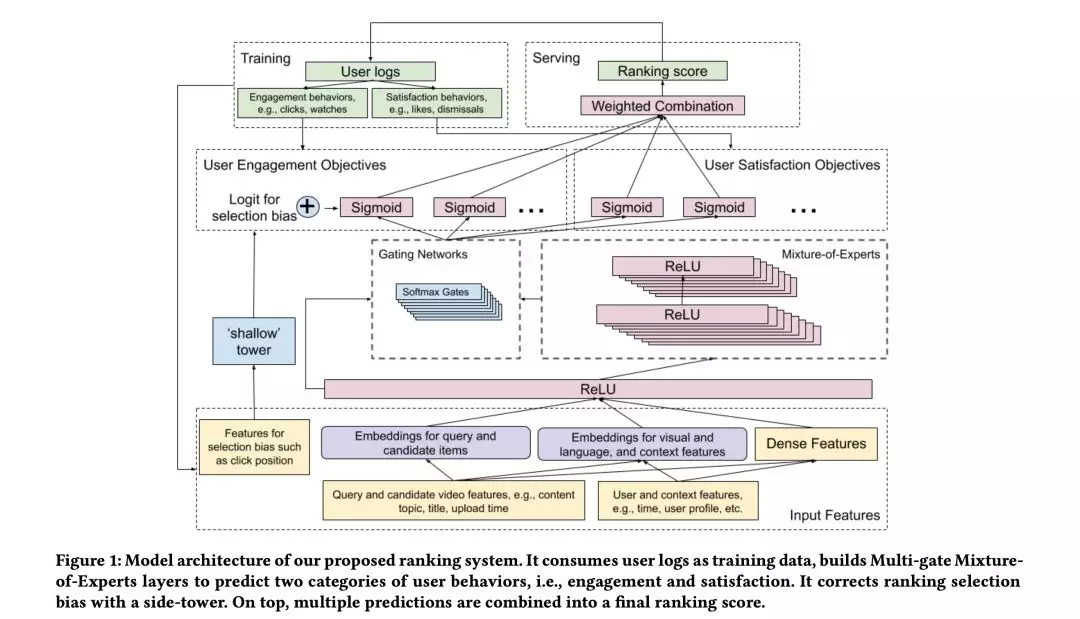
在 Youtube 上进行两段实验验证效果:
multitask learning
removing a common type of selection bias
贡献:
an end-to-end ranking system
multi-objective learning ( MMOE )
mitigate position bias
signifcant improvements on a real-world large-scale video recommendation system
相关工作
模型结构就不多介绍了,基本上就是各种 pointwise,pairwise 目标,还有各种 NN 模型结构,rnn,attention,NN+GBDT 等等。
多目标的话最基础的就是 shared-bottom 这种共享底层的结构,进阶版就是 MMOE 这种了,以及因为不同目标的 loss 贡献不一样所以会搞一些比如 gradnorm 这种的优化算法。
Bias 之前的分享的推荐系统文章基本都提过这块。常见的是把 position 之类的作为输入,预估时用 position 为 1 的输出值。其他的方案有从随机数据中学一个 bias iterm,也有不需要随机数据的,用 counter-factual model 学 inverse propensity score ( IPS )。像 Twitter、Youtube 这种用户兴趣变化比较快的,不太适合 IPS,需要更高效的方案来适应这种数据分布变化。
模型结构
1. System Overview
排序系统学习两种目标:
参与度:点击、观看
2)满意度:喜欢、不喜欢
所以排序目标是分类问题和回归问题的组合。
此方法是 pointwise,像 pairwise 和 listwise 的方案虽然可以提升推荐的多样性。但是基于 serving 时的考虑还是选择用 pointwise,简单高效,尤其是候选集比较多的时候。
2. Ranking Objectives
目标基本上就是刚才说的两类,一类是点击、时长, 一类是点赞、打分。分类问题就用 cross entropy loss 学习,回归问题可就是 square loss。最后用融合公式来平衡用户交互和满意度指标,取得最佳效果。
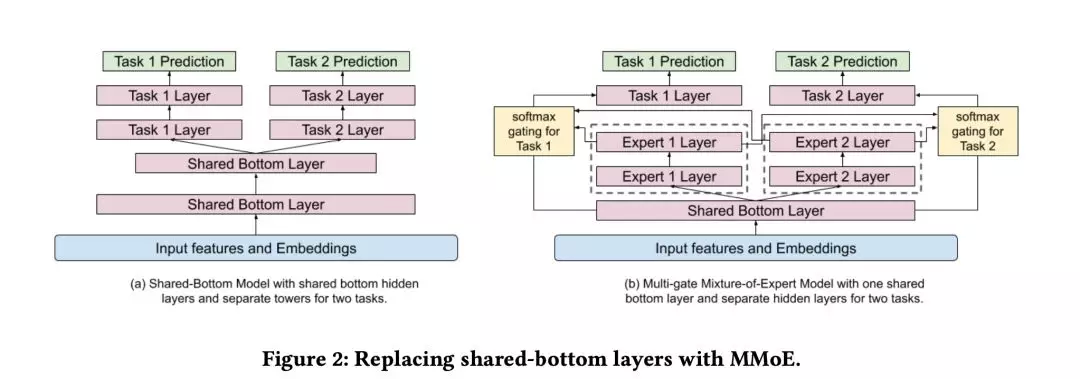
3. Modeling Task Relations and Conficts with Multi-gate Mixture-of-Experts
常见的多目标的排序系统用的是 shared-bottom 结构,但是这种 hard-parameter 强行共享底层的方案对于目标之间相关性小的任务,是有损效果的。因此采用并扩展 MMOE 结构来解决多目标冲突问题。
本文的排序系统上是在共享隐层上边加 experts,如图 2-b。Mixture-of-Experts 层可以帮助从输入中学习模块化信息,更好的建模多模态特征空间。但直接上 MoE 层会显著增大训练和预测的消耗,因为输入层维度一般比隐层维度大。
具体公式如下:
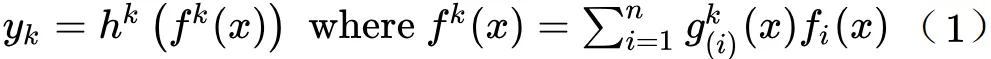
x 就是低层的共享 embedding,fi(x) 就是第 i 个 expert,g(x) 就是图中的 gate layer。
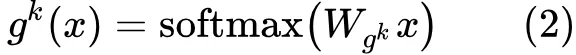
4. Modeling and Removing Position and Selection Biases
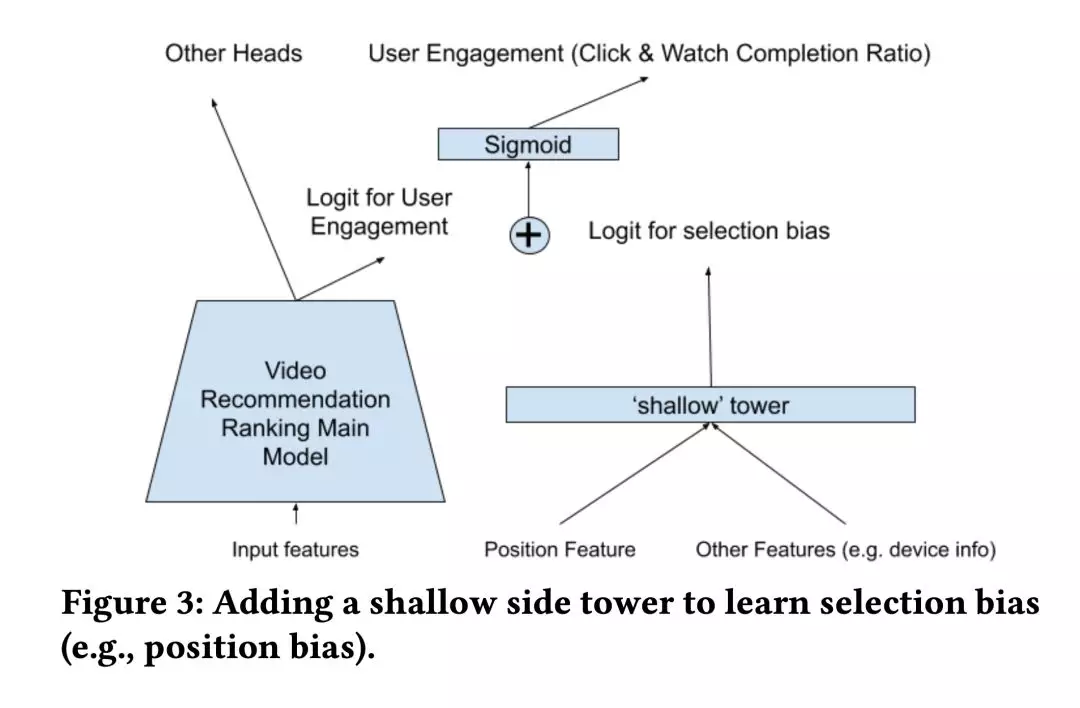
排序系统中有很多 bias,最明显的就是 position bias,排的靠前的天然就比排的靠后的容易被点击,所以我们需要去移除这种 bias,打破这种越来越偏的循环。
所以模型结构上除了一个 main tower,还有一个 shallow tower 去建模 bias,将输出的偏置项加到 main tower 最终输出的 logit 上,如图 3 训练的时候浏览时的位置作为输入,设置 drop-out rate 为 10%,避免过度依赖位置特征。serving 时,位置特征设为 missing。设备信息会被加入到 shallow tower 的输入中,因为不同设备上不同位置的 bias 是不同的。
EXPERIMENT RESULTS
实验就开在 Youtube 上,比较可靠。有不少推荐系统方向论文的改进是在很小数据集上测试的,在大规模场景下经常就不好使了,所以我比较少去看学术界的推荐系统论文。
离线使用指标用 AUC,线上开 AB 实验,评估参与度指标和满意度指标,除此外还要关注下服务的预测开销。
1. Multitask Ranking With MMoE
① Baseline Methods
基线方法就是图 2a 的 shared-bottom,模型复杂度是差不多的,确保线上 serving 开销相同。
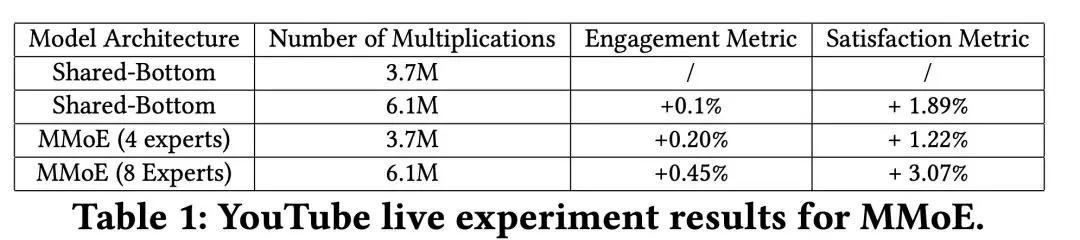
② Live Experiment Results
结果如表 1,MMOE 在保持模型复杂度不变的情况下,比较了下 4 个 experts 和 8 个 experts。可以看出参与度、满意度指标都有所提升。
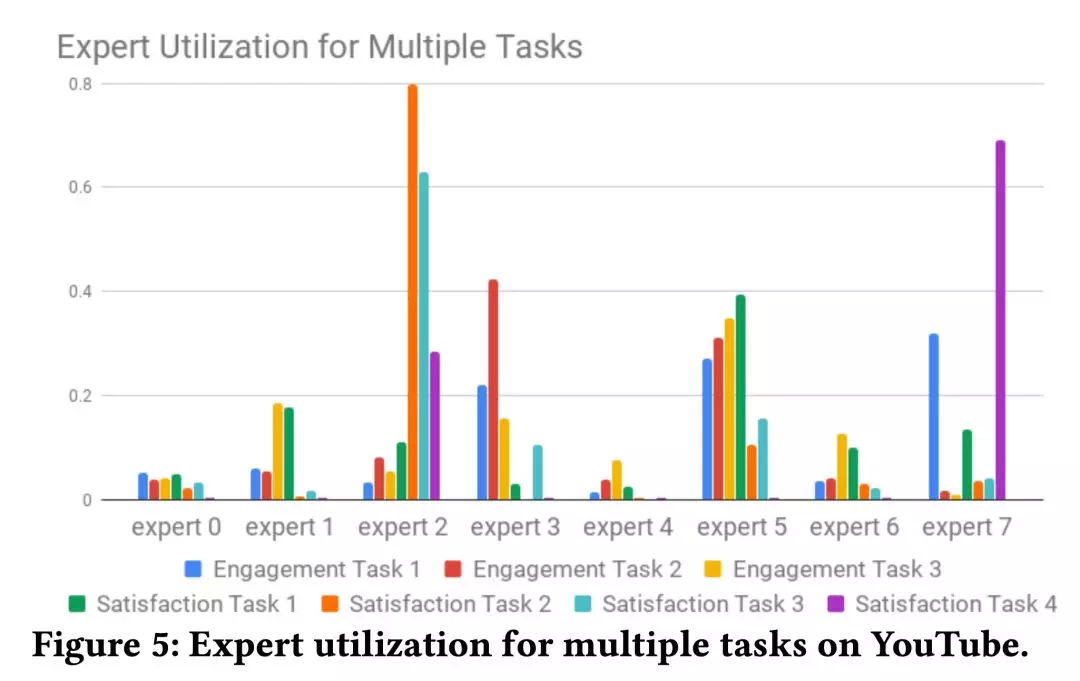
③ Gating Network Distribution
图 5 画了网络中每个 expert 对每个任务的累计概率,方便理解 MMoE 如何帮助优化多目标。可以看到有的 expert 偏重参与度任务,有的偏重满意度任务。
另外让 gating networks 直接和 input layer 相连,没有明显提升,所以没必要增大开销进行直连。
④ Gating Network Stability
多机分布式训练可能会导致 model diverged,比如 Relu death。在分布式训练中,可以观察到此模型中 gating network 有 20%会极化,这降低了模型性能。因此训练中要使用 drop-out,10%的概率将 expert 的利用程度设为 0 并重新归一化 softmax 输出的概率。
2. Modeling and Reducing Position Bias
① Analysis of User Implicit Feedback
图 6 展示了位置 1-9 的 CTR,这里边有 item 相关性的原因也有 position bias 的因素。因此用个 shollow tower 去学下 position bias。
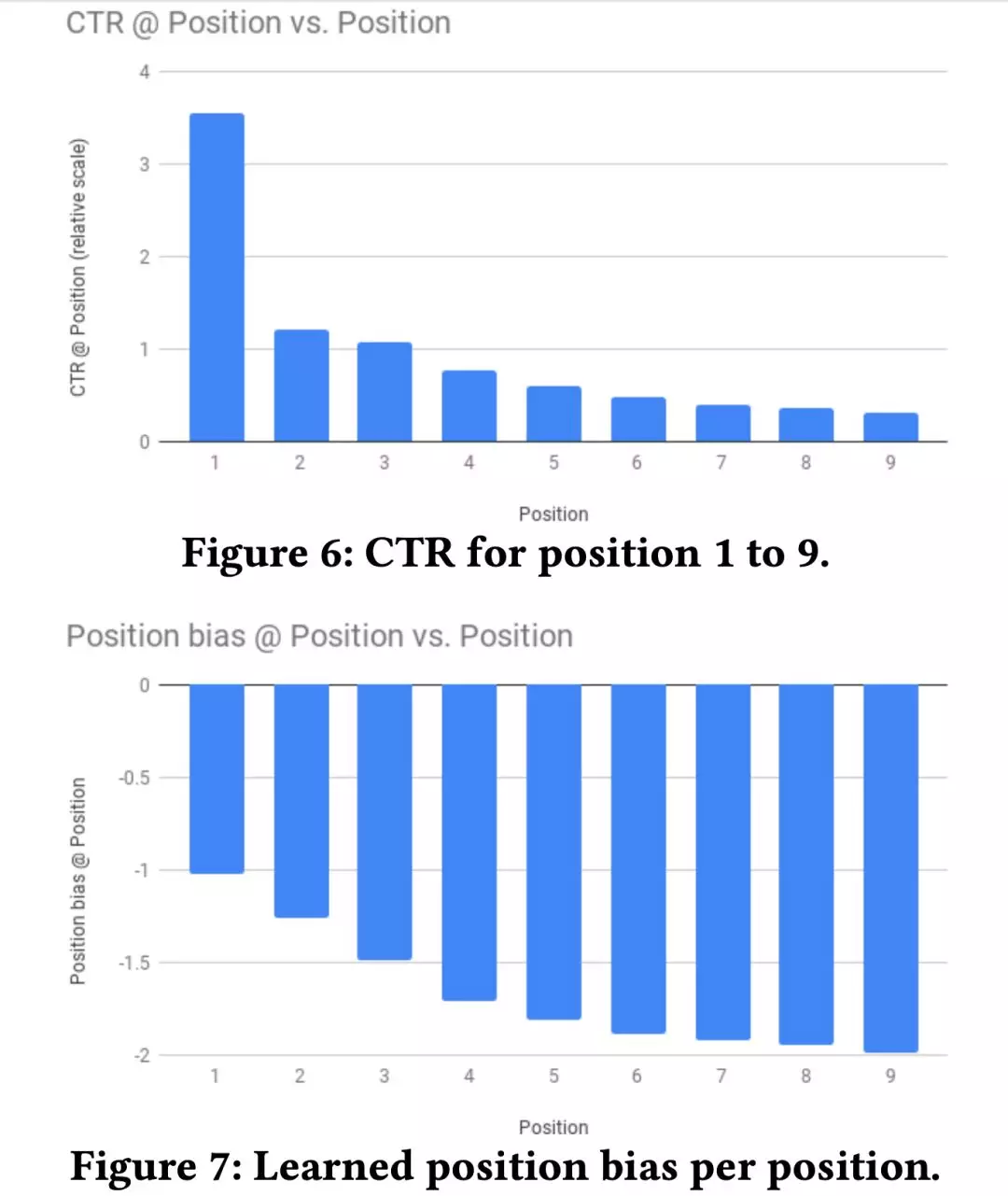
② Baseline Methods
直接用位置特征作为输入
Adversarial learning: 用辅助任务去预测展现的位置,在反向传播阶段把梯度取负(这里之前理解错了,写成了把梯度抹除掉),这样主模型不会依赖位置特征

下边是原文,这里说的不太详细,我又专门去看了下文章引用的第五篇:
https://arxiv.org/pdf/1707.00075.pdf
这个基线方案就是这个论文里讲得:

逻辑上是一个 head 正常预测比如点击,另一个预测位置,然后预测位置的这个 loss 反传是用负梯度,让 share 的底层不去学习位置逻辑,这样主模型就不依赖位置特征了。
③ Live Experiment Results
表 2 是结果,文中提的方法更好
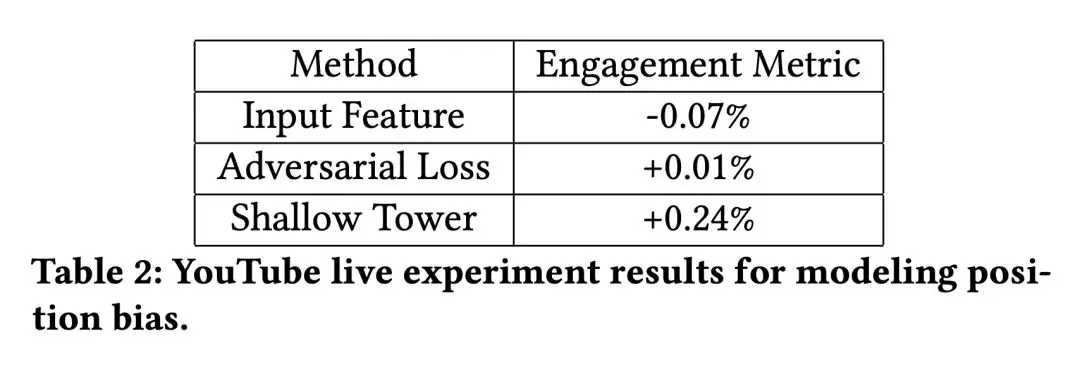
④ Learned Position Biases
图 7 是学到的 position bias,可以看到位置越靠后,bias 越小。
Discussion
① Neural Network Model Architecture for Recommendation and Ranking
许多推荐系统 paper 里提出的结构源于一些传统机器学习领域,比如 NLP 的 multi-headed attention,CV 里的 CNN。但这些其实都不直接适合我们的需求。主要原因:
Multimodal feature spaces.
Scalability and multiple ranking objectives.
Noisy and locally sparse training data.
Distributed training with mini-batch stochastic gradient descent.
② Tradeof between Efectiveness and Eficiency.
③ Biases in Training Data.
④ Evaluation Challenge.
⑤ Future Directions.
Exploring new model architecture for multi-objective ranking which balances stability, trainability and expressiveness.
Understanding and learning to factorize.
Model compression.
本文来自 DataFun 社区
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论