

编者按
深度学习模型应用广泛,但其自身有一定的“脆弱性”,即模型输入的微小改动,在不影响人判断的情况下,可能使模型的输出出错,这个过程被称为对模型的对抗攻击。针对对抗攻击的研究,早期集中在图像领域,近几年,文本领域也逐渐增多。2019 年,百分点从业务实际出发,与北京市科学技术委员会联合主办了数据智能创新应用(DIAC)大赛,聚焦于智能问答中的语义等价问题的对抗攻击。经过一个多月的研究实践,参赛队伍对该任务做了富有成效的探索,在优胜队伍的方案中,数据增强、对抗样本纠错、使用 Focal Loss 损失函数和基于 FGM 的对抗训练成为行之有效的策略。
一、对抗攻击概述
随着近些年深度学习的快速发展,深度神经网络逐渐成为机器学习领域的主流模型,被广泛应用于计算机视觉、自然语言处理等领域,但在研究与应用的同时,人们渐渐发现,深度神经网络具有一定的“脆弱性”。比如,在图像识别中,对模型的输入也就是图像像素值做轻微扰动,这种扰动不会改变图像的实际分类,人也难以觉察,却可能导致模型对图像的分类出错;或者在一段文本的情感分析中,文本中有一个字写错,这个错误不影响人的理解,也不会改变人对这段文本的情感判断,模型却可能判断出错。这类错误一方面会降低人们对系统使用体验的好感度,另一方面可能会造成严重的后果,从而也限制了深度神经网络在一些安全要求很高的场景下的应用。
近几年,人们开始对这一问题展开研究。如前文例子那样,人们精心设计一些样本,模型却判断出错,这个过程就是对抗攻击,这些样本就是对抗样本。通过研究对抗攻击以及相应的防御策略,有助于提高神经网络的鲁棒性和可解释性。
二、文本对抗攻击的主要方法
深度神经网络对抗攻击的研究最早在图像领域展开,现在在文本领域也有了一些相关研究。针对文本的对抗攻击,从不同的角度有不同的分类,常见的有:根据构造对抗样本时基于的信息分为白盒攻击和黑盒攻击;根据错误的输出是否是某个特定的结果,分为定向攻击和非定向攻击;根据改动文本的类型,分为基于字、词和句子的对抗攻击。这里我们主要介绍一下第一种分类。
2.1 白盒攻击
白盒攻击,是指在构造对抗样本的时候,有所要攻击的模型的知识,如模型的结构、参数、权重等。属于白盒攻击的攻击方式有很多种,这里举例介绍其中一种:基于 FGSM 的方法。例如,对于一个输入样本,一种方法是计算模型的损失对输入向量(对于文本来说,输入向量一般是文本的字向量或词向量)的梯度,然后将梯度量纲最大的维度所属的字定义为“热字”,包含足够多热字并且出现频繁的短语被定义为热短语。然后基于热短语,进行增删改,生成对抗样本。
2.2 黑盒攻击
黑盒攻击与白盒攻击相反,在构造对抗样本的时候,没有所要攻击的模型的知识。如果这个模型能被攻击者使用,则攻击者可以通过不断尝试,修改模型输入,观察模型输出来构造对抗样本。
如果不具备上述条件,但是能够对模型结果定义一个置信度打分函数,则可使用基于重要性的攻击方法。以文本分类为例,对文本中的每个词语,计算将该词语删除或替换为空格前后,文本分到正确类别上置信度分数(比如分到该类别的概率值)的变化量,将这个变化量作为这个词语重要性的分数,变化量越大越重要。然后,对重要性高的词语进行改动。
如果上述条件均不具备,则攻击者通常训练一个替代模型,然后针对替代模型,构造对抗样本,由于对抗样本具有一定可迁移性,可以用这些样本对目标模型进行攻击。在使用替代模型的情况下,构造对抗样本就可以运用白盒攻击中的一些方法。
三、语义等价问题的对抗攻击
2019 年,百分点与北京市科委一起主办了数据智能创新应用大赛,大赛聚焦于智能问答中的语义等价问题的对抗攻击,要求参赛者通过研究智能对话的鲁棒性问题进行算法创新,来提高对话系统的“思考能力”和“解决问题”的能力,让机器实现从“听见”到“听懂”,最终提升用户体验感。
在这个过程中,判断两个问题是否语义等价,是基于 FAQ 的问答系统的核心环节。例如:“市政府管辖哪些部门?”和“哪些部门受到市政府的管辖?”是语义等价的两个问题,后者的答案可以回答前者;而“市政府管辖哪些部门?”和“市长管辖哪些部门?”则为不等价的问题。在问答系统实际使用中,用户问的一个问题可能和知识库中问题语义等价,但用户的问题表述方式和用词多样,有的会出现不影响理解的多字、少字、错字、语气词、停顿等;有的问题则和知识库里的问题字面上很相近,但由于关键信息的不同,二者语义并不完全等价。如果针对第一种情况,系统仍然能判断为等价,第二种情况能判断为不等价,则能较好地保证用户的使用体验。
如本文第一节所述,对抗攻击是指对模型的输入样本作微小改动,这个改动不影响样本的真实输出(如真实类别),但对应的模型输出改变的过程。在这里,我们对这个概念稍作扩展,将对输入作微小改动,使得输出由正确变为错误的,都认为是对抗攻击。
两个问题原本是不等价的,大多数情况,这两个问题字面上就相差比较大,经过微小改动,往往仍然是不等价的,而且模型预测结果也不容易出错,所以对抗样本的构造没有涉及这种情况,而是针对两个问题原本等价的情况进行,这种情况又分改动以后仍然等价和不等价两种情况。
由于对抗样本的构造过程中,没有待攻击的模型的信息,因此这里对抗样本的构造是个黑盒攻击的过程。我们利用比赛训练集,训练了一个基于 BERT 的语义等价模型,来辅助对抗样本的构造。对两个等价问题经过改造后不等价的情况,我们采取人工给问题中的某个词加影响语义的修饰限定成分或将关键词换成非同义词的方式改造,然后看模型是否仍然判断为等价,如果是,则改造成功。对两个等价问题,经过改造后仍然等价的情况,我们主要通过人工给原问题换同音字、形近字、同义词、增加无意义词或不影响语义的修饰限定成分的方式改造,同时保证所做的改造是合理且不改变语义的,改造后,看模型是否判断为不等价,如果是,则改造成功。
第二种情况,改动往往不容易成功,为了提高针对性,我们对一组两个问题中的每个词语,将其删除后,计算模型预测两个问题为等价的概率值,根据每个词语对应的概率值从低到高的顺序,对词语排序,排在前面的词语,认为是对模型预测这两个问题等价比较重要的词语,在问题改造时,重点围绕这些词语进行。构造的对抗样本举例如下图:

四、文本对抗攻击的防御策略
针对文本对抗攻击的防御策略主要包括两个方面,一方面是去发现对抗样本,比如有一些对抗攻击,是将文本中的字改成音近字、形近字或错字,可以检测包含这类异常字的文本,然后对其做额外的处理;另一方面是对模型进行对抗性训练,包括在训练样本中加入对抗样本,对损失函数和模型结构进行改动等,本次大赛方案中有一些应对对抗攻击的策略,具体在下面章节介绍。
五、DIAC 大赛方案分享
DIAC 大赛优胜队伍普遍选择 RoBERTa_wwm 作为语义等价任务的基础模型,即将两个问题拼起来,进入模型,然后选择[cls]位置对应的向量,经过一个全连接层和 softmax 操作,输出在 2 个类别上的概率。在模型训练之前,进行了对抗样本的数据增强;在模型训练阶段,采用 FocalLoss 作为损失函数,利用 Fast Gradient Method(FGM)在 embedding 层上添加扰动;在测试集上作预测时,对疑似对抗样本进行纠错。
5.1 数据增强
根据对抗样本举例,通过以下方式进行了数据增强:
方法一: 音近字替换、形近字替换、同义词替换、词序调整。用开源的音近字、形近字、同义词词典,以一定比例对问题中的字或词进行替换,同时限制一组问题中替换的总字数小于 3,或以一定比例对问题中的词语词序随机调整,限制最远的词序调整,两个词汇间隔不超过 2 个词。
方法二: 反义词替换、增加或删除否定词。以一定比例进行将问题中的某个词替换为反义词、增加或删除问题中的否定词,如:“未”、“没有”、“无”、“非”,并修改样本标签。
方法三: 用开源的错别字校正工具,对问题进行校正,矫正结果矫正错误率接近 100%,但错误矫正只影响 1-2 个字,不影响对问题的理解,故可以用这种方式生成对抗样本。
通过上面的一种或几种方式,进行数据增强,训练的模型与不进行数据增强相比,在最终测试集上的宏 F1 值有约 1.5~2 个百分点的提升。
5.2 智能纠错
针对对抗样本特点,有下面几种纠错方式:
方法一: 召回与待纠错问题相似的问题,对比相似片段,进行纠错。具体做法是:以两个问题分词集合的差集中包含的词语数目作为二者相关性的一个度量。对一个问题,从整个数据集合中,召回一些和它相关性较高的问题。相关问题召回后,接着对原问题与相关问题进行共现的相似文本片段查找,文本片段相似采用汉明距离作为度量,由于一般对抗样本中错别字都只有一个,若是有两个错别字一般都是连在一起的,因此将汉明距离小于 2 且满足不同字必须连续做为判断相似文本片段的依据。
相似片段找到后,对相似片段的每个位置进行一一对比,如果不同,考虑这两个字是否是同音字,如果不是同音的字再考虑是否是形近字,若都不是就不进行纠错。判断是否同音采用一个汉字转拼音的模块,同形的判断采用笔顺的编辑距离作为相似度的判断,同音或同形的错别字在相似文本片段中的位置确定后,接下来就是确定两个文本片段哪个有错别字。通过对相似片段分词,然后计算所有词的在训练集中出现次数的总和,判定总和小的片段包含错别字,然后用总和大的对总和小的进行修正。
方法二: 统计问题中词语上下文的 ngram,根据 ngram 为对抗样本中的错误词语寻找纠错建议。具体做法为:对问题进行分词及词性标注,对具有词性为 m、nr、ns、nt、nz、r、x、w 的词替换为对应的词性标记。对每个词语,分别统计上文的一、二、三元 ngram 和下文一、二、三元 ngram 共 6 个词条,添加到 ngram 词表里。在纠错阶段,对问题中的词 W,利用其上下文的 6 个 ngram 词条和前一步统计的 ngram 词表,获得纠错的候选词及候选词的词频,基于拼音编辑距离,计算候选词与词 W 的拼音相似度。按照如下公式,进行候选词得分计算:
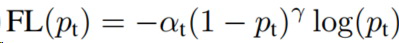
其中 x 为候选词,c 为原错词,d 为词表,为候选词的词频,为候选词与原错词的拼音相似度数,为对应的词表字典的权重。对所有候选词按照分值从大到小进行排序。取前 N(这里取 N 为 10)个,如果存在候选词与错词的编辑距离小于等于 1,则优先返回这个候选词,否则返回所有候选词分值最高的词。
方法三: 将测试样本中两个句子中的同音字或形近字相互替换。当句 A 中连续两个字的读音与句 B 中连续两个字的读音相同时,可以用 B 中的同音字替代 A 中同音字,构造句 A’,那么 A’与 B 即可组成样本[A’,B]。同理可以构造[A,B’],它们与[A,B]共同组成一组测试样本,用训练好的模型预测这组测试样本,预测结果只要存在一个正样本,即认为原测试样本为正样本。
通过上面的方式,对测试集进行纠错,预测结果的宏 F1 值有约 2~3 个百分点的提升。
5.3 Focal Loss
在给出的训练集中,正负样本比例较不平衡,适合采用 Focal Loss 作为损失函数。Focal Loss 公式如下:
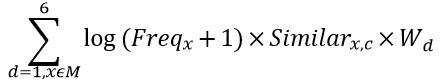
通过设定α的值来控制正负样本对总的 loss 的共享权重,α取比较小的值来降低多的那类样本的权重,通过设置γ来减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。
实验表明,使用 Focal Loss 相比于不使用 FocalLoss 作为损失函数,验证集预测结果的宏 F1 值有约 0.5 个百分点的提升。
5.4 Fast Gradient Method
对抗训练采用的是 Fast Gradient Method(FGM),其目的是提高模型对小的扰动的鲁棒性,扰动添加在 bert 模型的字向量上。对于分类问题,具体做法就是添加一个对抗损失:
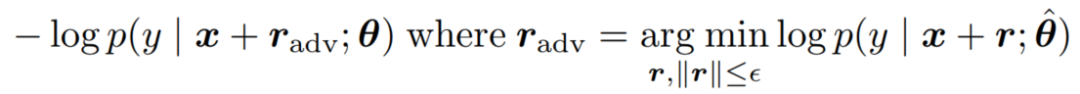
上式表达的意思即,对样本 x 加入的扰动 radv是可以使得预测为分类 y 的损失最大,radv的定义如下:
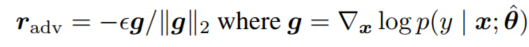
在具体训练时采取的损失,是原始损失与对抗损失的组合。实验表明,使用 FGM 训练的模型和没有使用的模型相比,验证集的宏 F1 值能有约 0.5~1 个百分点的提升。
5.5 各种方法的效果
总结上面提到的几种方法,在该任务上的效果如下表:
大赛优胜队伍以上面几种方案为主。第一名采取了除上面智能纠错以外的方案,同时,针对只是在局部进行个别词的增删改替换的对抗样本,设计了 Absolute Position-Aware 的模型输入方式进行捕捉,另外,在固定的网络结构中进行对抗训练。第二名和第三名的队伍,没有做太多数据增强,在使用 Focal Loss 和 Fast Gradient Method 的同时,将重点放在了智能纠错上,他们分别设计了巧妙的智能纠错方案,利用对抗样本和其他样本之间的相似特性,进行纠错,取得了不错的效果。
综合看前三名的队伍,除了数据增强和对抗训练等其他任务中也可能有效的方法,他们针对本次比赛的赛题特点,从数据出发,进行对抗样本的发现与纠错,方法巧妙,最终脱颖而出。
六、总结
通过这次比赛,大家对防御智能问答中语义等价问题的对抗攻击、增强模型鲁棒性的方法进行了许多探索与实践,发现在数据处理阶段的数据增强、对抗样本纠错和模型训练阶段使用 Focal Loss 和采用 FGM 的方法进行训练是行之有效的策略。这些实践与结论,将实现机器与人之间更加智能的对话,为实际的生产生活带来切实帮助。当然,随着研究的深入与应用的普及,还会出现新的对抗攻击的方法,我们也期待新的防御策略被发明,共同促进模型鲁棒性的提升,使系统更好地落地应用。
参考资料
[1] Wang, W., Wang,L., Wang, R., Ye, A., & Tang, B. (2019). A Survey: Towards a Robust DeepNeural Network in Text Domain. arXiv preprint arXiv:1902.07285.
[2] Wei Emma Zhang,Quan Z. Sheng, Ahoud Alhazmi, and Chenliang Li. 2019. Adversarial Attacks onDeep Learning Models in Natural Language Processing: A Survey. 1, 1 (April2019), 40 pages.
https://doi.org/10.1145/nnnnnnn.nnnnnnn
[3] DIAC 大赛优胜队伍(比较牛的丹棱街 5 号、观、沐鑫、XiaoduoAI-NLP、zhys513、苏州课得乐-强行跳大)解决方案
本文转载自公众号百分点(ID:baifendian_com)。
原文链接:
https://mp.weixin.qq.com/s/nk_7mnG_HEU-43YeS0DB7Q

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论