

0. 目录
背景
解决思路
现场分析
网络分析
负载分析
redis sdk 问题排查
runtime 问题排查及优化
抓 trace ,查看调用栈
原理分析
总结
1. 背景
最近,策略组同学反馈有个服务上线后 redis 超时非常严重,严重到什么地步呢,内网读写 redis 毛刺超过 100ms! 而且不是随机出现,非常多,而且均匀,导致整个接口超时严重。因为用的 redis 库是由我们稳定性与业务中间件组维护,所以任务落我们组小伙伴头上了。
这个项目有非常复杂的业务逻辑,然后要求接口在 100 ms 左右能返回。这个服务有密集型 io(调度问题)+定时任务(cpu 问题)+常驻内存 cache(gc 问题)。频繁访问 redis,在定时逻辑中,业务逻辑一个 request 可能达到上千次 redis Hmget/Get (先不讨论合理性)。 复杂业务给问题排查带来比较多干扰因素,这些因素都可能导致抖动。
go version : 1.8,机器是 8 核+16G 容器,没有开 runtime 监控,redis 的同事初步反馈没有 slowlog。因为 rd 也追了很久,到我们这边来的时候,redis 的超时指标监控已经给我们加了,每个 key 的查询都会打印日志方便 debug。
redis get 接口的耗时监控显示如下,因为高频请求,大部分耗时是小于 10ms 的,但是这毛刺看着非常严重,是不可忍受了。
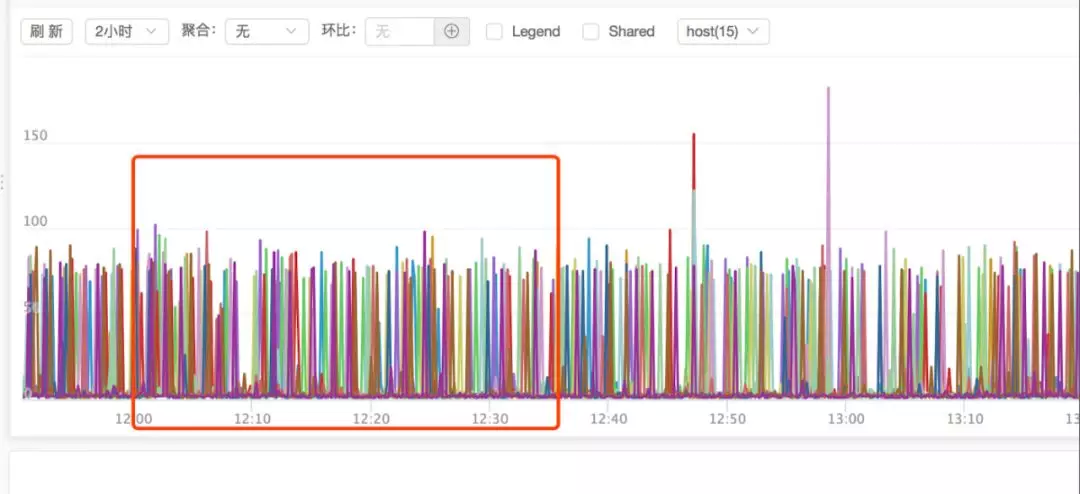
系统 cpu 问题比较严重,抖动非常大,内存并没有太大问题,但是占用有点大。因为用了 local-cache,也可能引起 gc 问题。
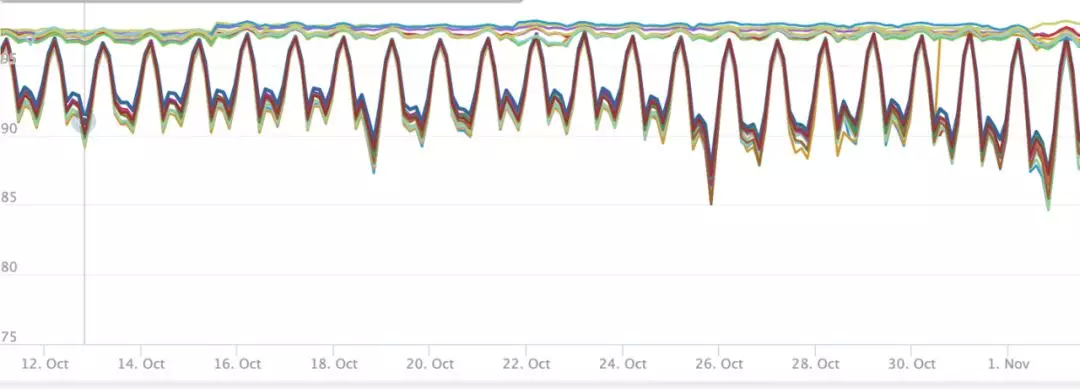
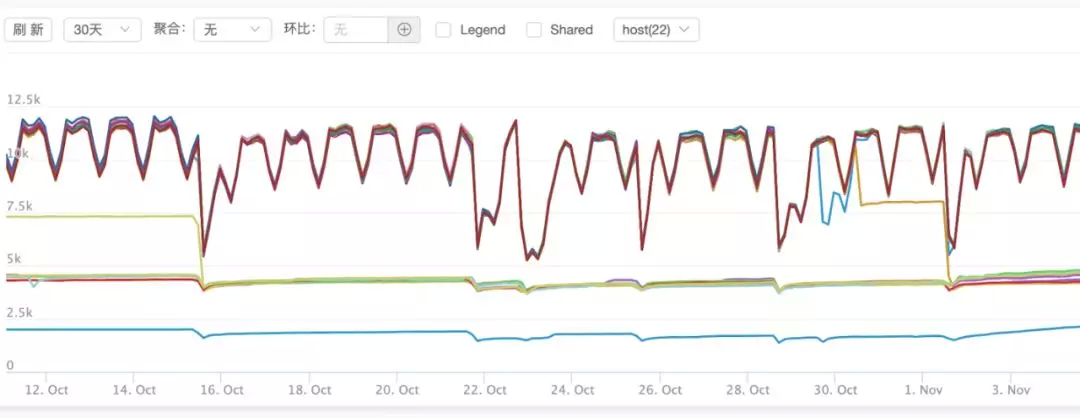
因为没有加 runtime 监控,其他信息暂不可知。
2. 解决思路
因为追查接口毛刺比较复杂,我们的原则是不影响业务的情况下,尽量少上线的将业务问题解决。
第一、首先排查是不是网络问题,查一段时间的 redis slowlog(slowlog 最直接简单);
第二、 本地抓包,看日志中 redis 的 get key 网络耗时跟日志的时间是否对的上;
第三、查机器负载,是否对的上毛刺时间(弹性云机器,宿主机情况比较复杂);
第四、查 redis sdk,这库我们维护的,看源码,看实时栈,看是否有阻塞(sdk 用了 pool,pool 逻辑是否可能造成阻塞);
第五、查看 runtime 监控,看是否有协程暴增,看 gc stw 时间是否影响 redis(go 版本有点低,同时内存占用大);
第六、抓 trace ,看调度时间和调度时机是否有问题(并发协程数,GOMAXPROCS cpu 负载都会影响调度);
整个分析下来,只能用排除法了。
3. 现场分析
网络分析
因为服务的并发量比较大,其实查起来非常耗时。
redis slowlog 经查是正常的,显示没有超过 10ms 的 get 请求。
我们该抓包了,将日志里的 key 跟 tcpdump 的 key 对起来。因为并发量非常大,tcpdump 出来的数据简直没法看,这里我们线上 dump,线下分析。 tcpdump 抓了几分钟时间。grep 日志里超时的 case, 例如 key 是 rec_useraction_bg_2_user_319607672835 这个 key 显示 126ms, 但是 wireshark 显示仅仅不到 2ms。
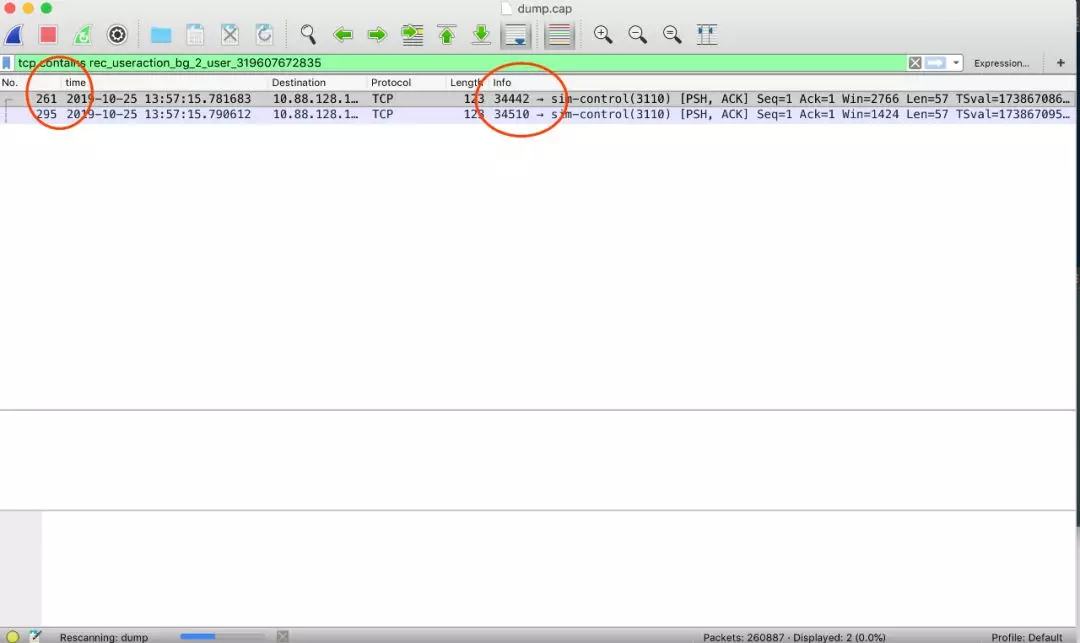
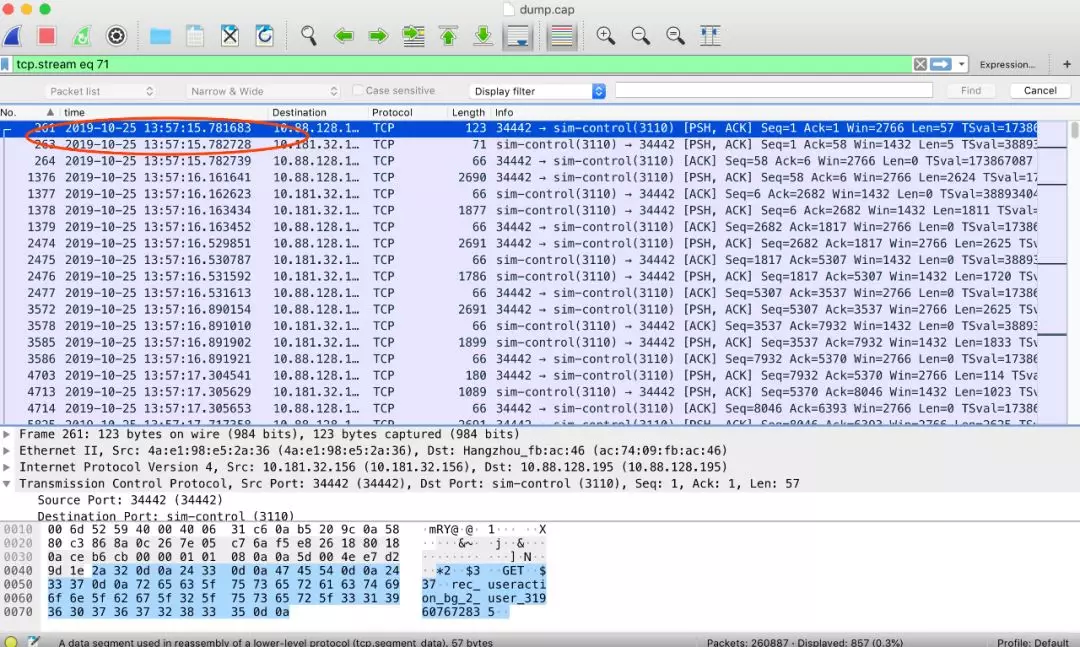
分析了其他的 key,得到的结论都类似,redis 返回非常快,根本没什么问题。
负载分析
我们是有 cpu 监控的,可惜的是,是宿主机的 cpu 监控。这里 cpu 占用看,因为资源隔离,宿主机没问题,但是这个进程的 cpu 抖动比较厉害,这里常用 40%,但是定时任务起起来的时候,接近全部打满!抖动是否跟定时任务有关?但看监控,其实相关性没有那么明显,redis 超时更频繁。

redis sdk 问题排查
sdk 是存在阻塞的可能的,怎么判断 sdk 是否阻塞了?两个方式,一种是源码级别追查,第二种是查看实时栈,看是否有 lock,wait 之类的逻辑。初步看并没有阻塞逻辑。dump 了下线上的栈,看起来,也没有什么问题。但日志确实显示,到底怎么回事?

这里有个认知问题,有 runtime 的语言,sdk 都是受 runtime 影响的,sdk 写的再好,并不能保证延时,比如你跑下下面这个 demo,50 个并发,你访问 redis 都各种超时。程序的 runtime 我们也需要查下。
runtime 排查及优化
抓了下线上 heap 图,查看历史的 gc stw 信息:curl http://localhost:8003/debug/pprof/heap?debug=1
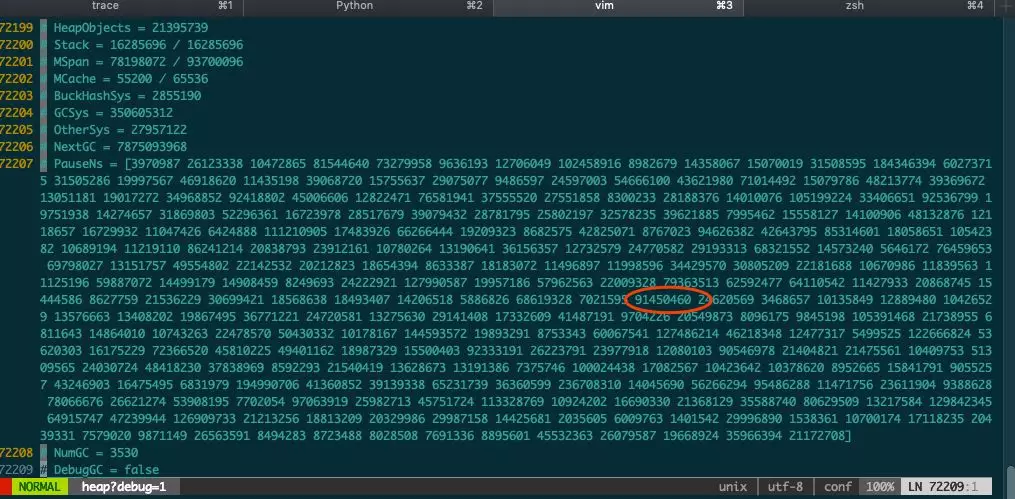
上面的数据,是历史 stw 时间,没 runtime 历史监控只能看这了,数据简直没法看,上面是个 256 的数组,单位是 ns,循环写入。gc 的策略一般主动触发是 2min 一次,或者内存增长到阈值,先初步认为 2min 一个点吧。gc 得必须得优化,但是跟日志毛刺的密度比,还对不上。
查看具体的问题在哪,graph 如下:
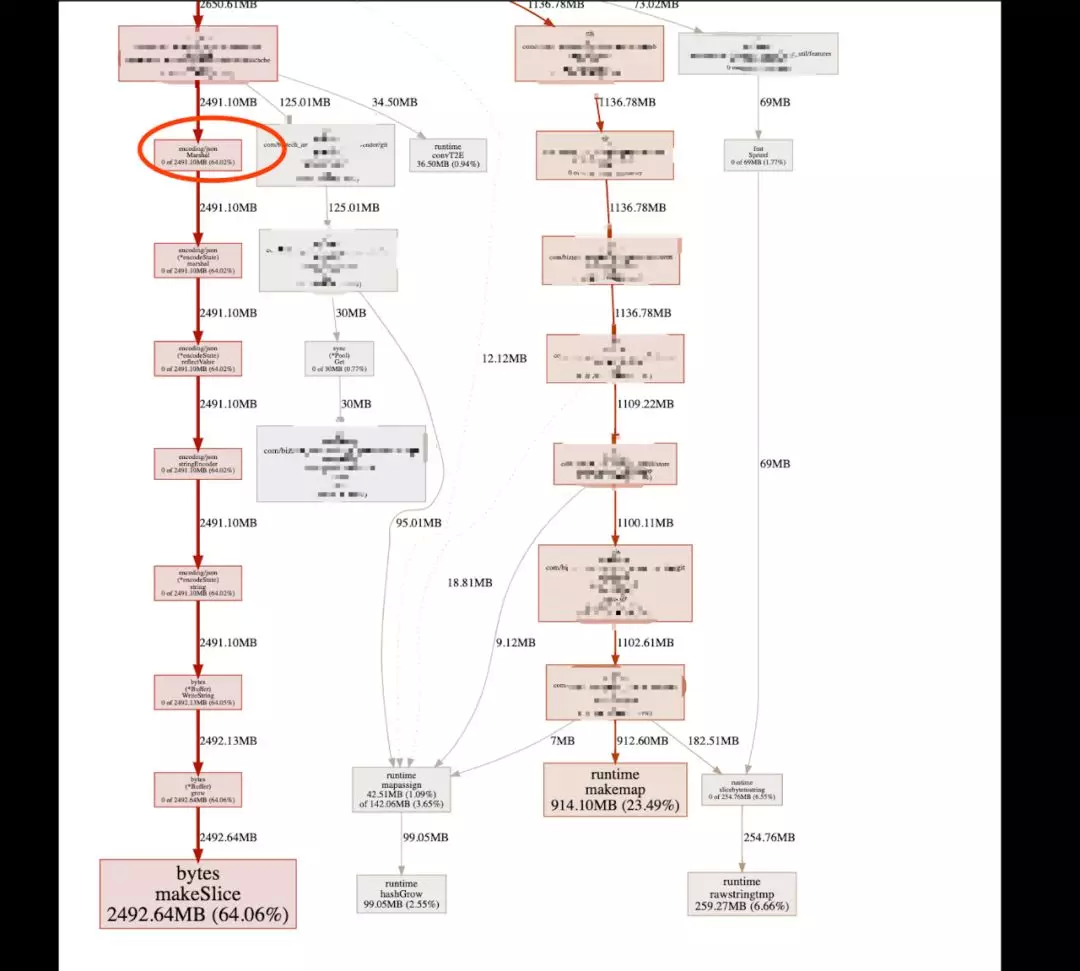
大头在两个地方,一个是 hmget, 一个是 json。优化 gc 的思路有很多,也不复杂,有实例,参考我个人博客。最简单有效的,你先把版本升下吧,高频服务,1.8 一个定时器问题你 qps 就上不去了,示例参考。
这里是业务同学升版本后的 graph:
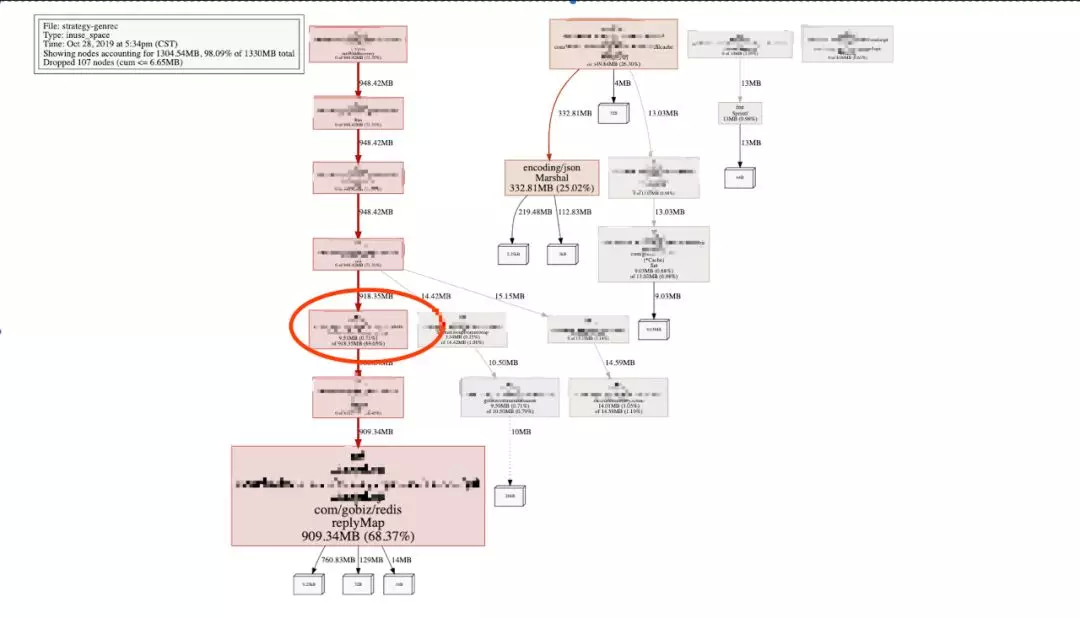
看下 hmget 和 json encode 的区别,现在大头全在 hmget 上了,效果立杆见影。这里为啥 hmget 这么多?问了下,这是业务逻辑实现,这样做是有问题的。不能影响业务,所有暂时作罢。只升级大版本,stw 好了很多,虽然偶尔也有几十毫秒的毛刺,对比图如下(单位 ms):
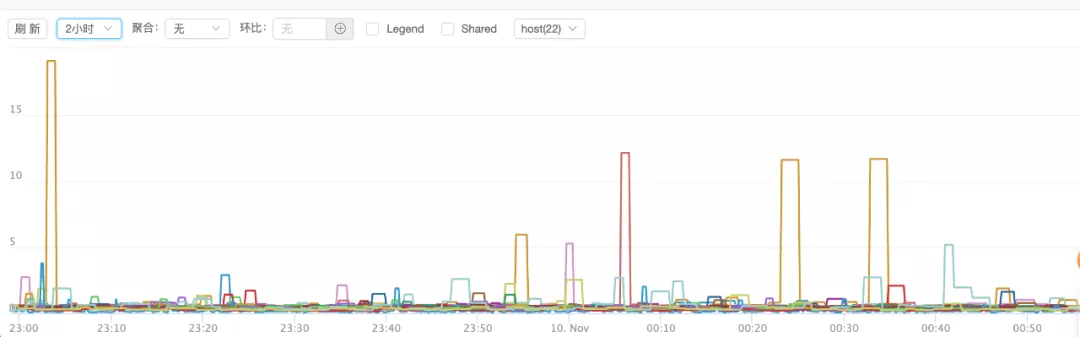
可惜,问题并没有解决,redis 的抖动没有明显变化:
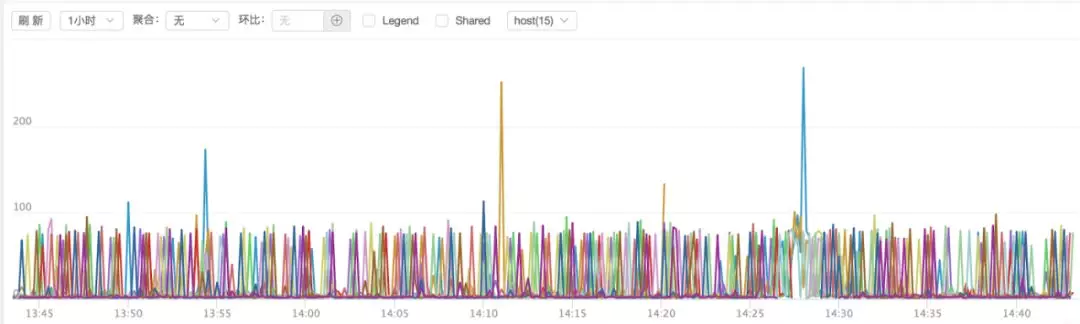
为什么一直追这 redis 查 ,不追着其他接口查,因为 redis 要求比较高,是 ms 级别,其他的 api 是百 ms 级别,毛刺就不明显了。
目前看 gc 问题其实还有优化空间,但是成本就高了,得源码优化,改动会比较大,业务方不能接受。而且,当前的 gc 大幅改善对接口耗时并没起到立竿见影效果,这里需从其他方面寻找问题。
抓 trace ,查看调用栈
线上 trace,记录了采样阶段 go 都在干嘛,不过因为混合业务代码,你想直接看图,基本是不可能了,打开都得等几分钟(没办法,有业务逻辑)…
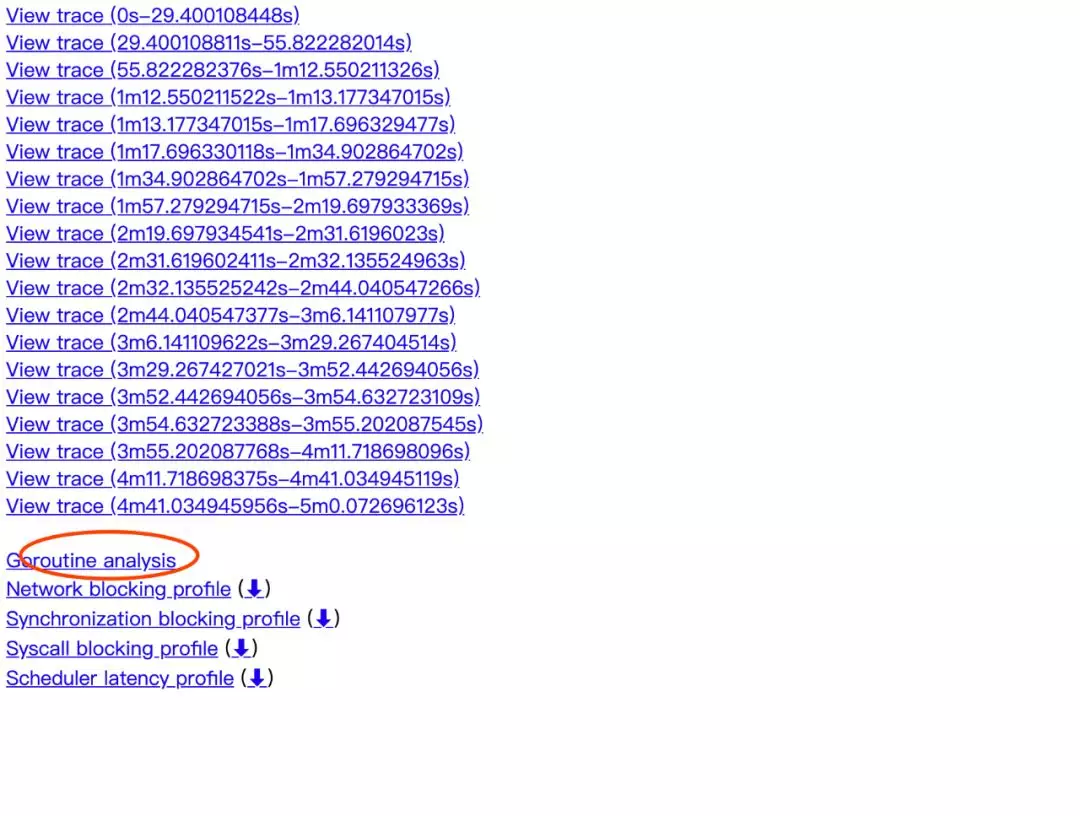
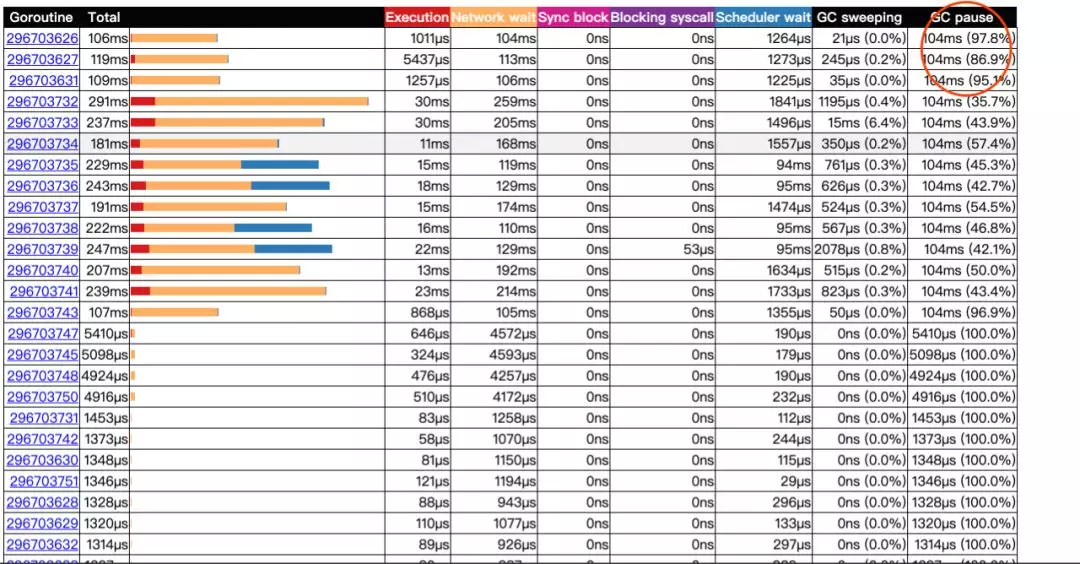
单独看 gc,和 heap 之中数据基本一致。这里问题比较严重的是调度,按 scheduler wait 排序后数据如下:
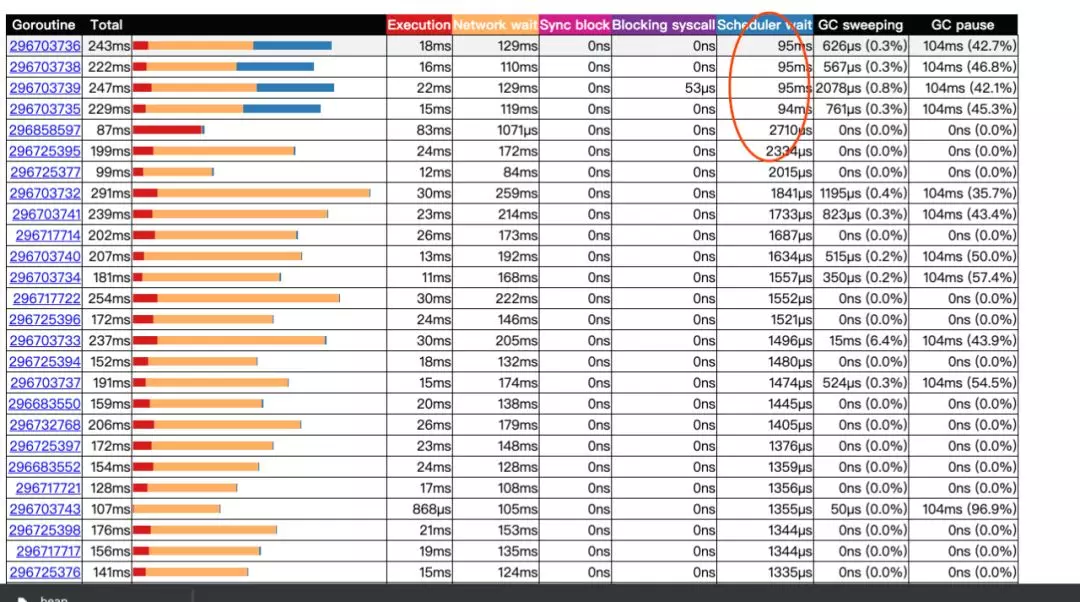
影响调度的,主要是协程数量和线程数量。
加了监控后,看到其实并发的协程数量并不太多,也没出现协程暴增的情况,照理调度并不会这么严重。
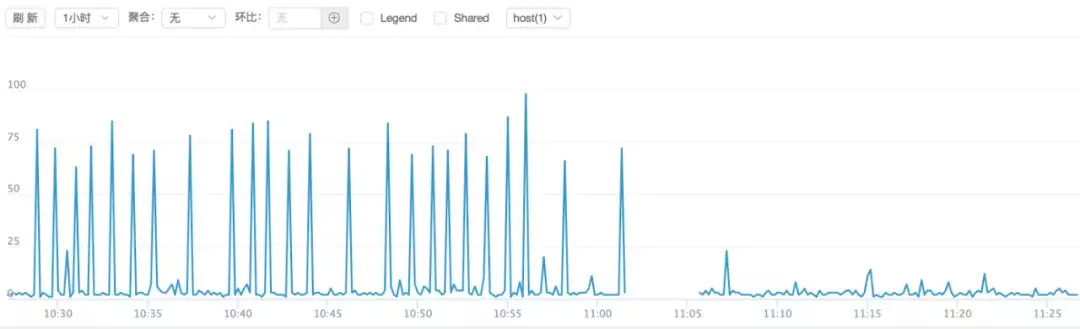
线程数查看 ps -T -p pid,线程数是 200+,这个数量很奇怪,有点超出预期,8 核的容器,默认 p 是 8,线程数超过 p 数量 20 多倍。而从 trace 图上看 p 是 48,看着是 go 获取了物理机的核心数。线程数会影响调度,这个影响不好评估,但是要优化。我们建议将 GOMAXPROC 设置成 8,然后重新上线。然后抖动立刻降下来了,效果如下:
同时,pprof 显示,目前的线程数,降到了以前的 1/3。通过 perf 看线程的上下文切换也少了,同时调度本身也少了。

到此,问题基本查到根因,并解决了。
4. 原理分析
为什么获取到错误的 cpu 数,会导致业务耗时增长这么严重?主要还是对延迟要求太敏感了,然后又是高频服务,runtime 的影响被放大了。
关于怎么解决获取正确核数的问题,目前 golang 服务的解决方式主要是两个,第一是设置环境变量 GOMAXPROCS 启动,第二是显式调用 uber/automaxprocs。
golang 是如何设置 cpu 核数,并取成宿主的核数的呢,追 runtime.NumCPU() 发现,其实现细追,发现是 getproccount, 查 linux 下源码发现,其实调用的是 sched_getaffinity,直接通过系统调用获取的宿主机核数。
uber/aotomaxprocs 是如何算正确的 cpu 核数?读取 cgroup 接口 /sys/fs/cgroup/cpu/cpu.cfs_quota_us ,然后除以 /sys/fs/cgroup/cpu/cpu.cfs_period_us 并向上取整:
像 java ,jdk8u191 以后,都已经能自适应容器和实体服务器了,go 也应该考虑考虑自适应容器核数,毕竟是容器时代。
##5. 总结
这个问题排查优化结束了,但怎么让公司其他项目受益?
我们怎么解决其他项目线上线下容器获取错 cpu 数的问题?现在很多项目没开 runtime 监控,线上异常,怎么方便定位问题?这个项目本身还有哪些可以优化的?等等。
第一个问题,我们在镜像里注入环境变量 GOMAXPROCS,并算出 cgroup 限制的核数。如果大家有需求自定义 p 的数量,可以自己显式调用 https://github.com/uber-go/automaxprocs 。镜像注入环境变量,相当于无感帮大家解决了获取错 cpu 的问题。
第二个问题,给我们部门 go 项目加上 runtime 监控,定时上报 runtime 信息同时提供采集 pprof 能力。
第三个问题,优化 redis sdk hmget 函数,减少对象分配,业务流程也使用 pipeline 模式,合并 io。
作者介绍:
万鼎铭
滴滴 | 高级软件开发工程师
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论