

0x04 背景
截止到目前,国内的大部分 Android 应用仍然是 32 位架构,特征是仅提供了 armeabi/armeabi-v7a 架构的动态库。Android 系统在启动此类应用的时候,会使用 32 位的 Zygote 进程孵化应用,让整个应用运行在 32 位兼容模式。虽然 Android 早在 5.0 版本就已经支持 64 位 CPU,但多年以来,大部分国内应用仍然运行在 32 位兼容模式。早在 2019 年 1 月,Google Play 就开始强制要求开发者上传包含 64 位架构支持的应用,保证应用运行在 64 位模式。国内各大应用市场也出台要求,希望国内应用在 2021 年年底之前上架双架构版本。
大型 32 位 Android 应用存在一个众所周知的问题,就是虚拟内存的寻址上限只有 2^32=4GB,而国内的各个厂商的头部应用普遍功能繁多,内含各种容器、框架、SDK 以及多媒体能力等等,导致应用启动后内存水位居高不下,在用户的高强度使用下,会出现因为虚拟内存不足而触发的 Crash(libc:abort)。根据观察到的线上 Crash 情况,可以发现 Native Crash 的 Top 10 中有大量的 libc abort,也就是信号 6,典型的特征就是在 Crash 堆栈中可以发现地址空间的总和接近 4GB、Console log 中有大量的 (Out of memory)、malloc (xxxx) failed、returning null pointer 等等。随着业务的发展和时间的推移,该问题逐渐突出,已经成为稳定性保障中的拦路虎。
想要解决这个问题,关键是解决虚拟内存不足的问题,而 64 位应用的虚拟内存地址空间上限是 2^39=512GB ,所以目前该问题的唯一解法就是升级到 64 位,因为 64 位带来的巨大地址空间除非出现 bug,一般不会触顶。
通常升级 64 位有两种办法:合包和拆包。其中合包会带来巨大的包大小压力,据 Google Play 调研:包大小每增加 6MB 会减少 1% 的下载。而拆包则需要一定的改造成本和维护成本。诚然终态一定是 64 位单架构,但无论是出于技术探索还是用户体验的考虑,都有必要研究一下这个问题,让 64 位升级可以在不牺牲包大小的前提下平稳过渡。本文将重点分享阿里开源用于缓解虚拟内存地址空间不足的“黑科技”—— Patrons,以及整个解决问题的探索过程,供大家参考。
0x08 探索过程
虚拟内存地址空间不足的课题在去年双十一前后被大家重视起来,大家纷纷下场投入了研究,也有很多阶段性结论,其中比较典型的观点有两种:
Android 10 的内存分配器存在 bug 导致内存泄漏;
Jemalloc5.1(Android10 的内存分配器) 的脏页释放条件相比前代版本进行了修改,导致内存延迟释放,最终使得虚拟内存的水位居高不下。
这里简单科普一下内存分配器:大多数情况下,我们写 Native 代码的时候,并不会直接调用内核的 API 去申请物理内存,而是使用 malloc 族函数进行内存申请。这时候返回的指针会指向虚拟内存中的地址空间,之后在这部分地址空间真的被使用的时候,才会发生缺页中断触发真实的物理内存分配,所以通常是两层分配结构。用户态代码申请的内存来自于内存分配器的二次分配,常见的内存分配器有 JeMalloc、TcMalloc、PtMalloc 等等。当然,我们在写业务的时候并不需要关心内存是哪个内存分配器分配的,Android 9、10 使用的内存分配器均为 JeMalloc,静态链接在 libc 中。Android 11 使用的是更加高性能、更加安全的 Scudo 分配器。
针对以上观点,我查阅了一些资料,针对 Jemalloc5.1 延迟释放的解决方案包括:
编译的时候修改编译参数(不可行,无法决定用户手机中的 Android 系统的编译参数);
将 dirty_decay_ms 设置为 0,可以修改 Jemalloc 的脏页释放方式。但是经过查阅 Android 10 源码,发现 Google 在 Android 10 中,已经将 dirty_decay_ms 设置为 0 了,可知并不存在脏页释放延迟的问题。
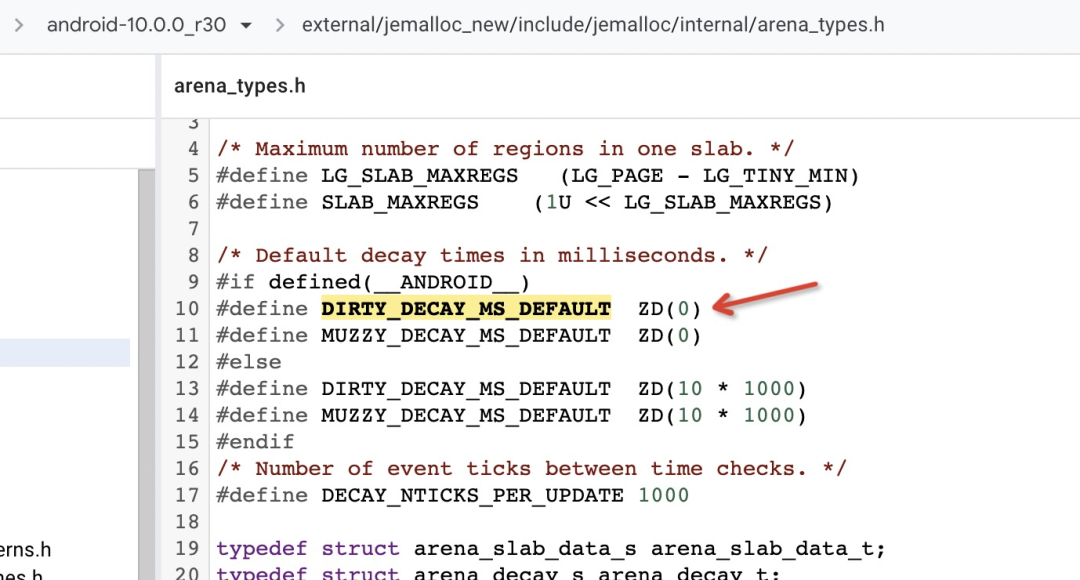
结合目前的资料来看,JeMalloc 可能并没有什么问题,但是在崩溃数据上展现出了一个奇怪的特征,就是 Top 1 的 crash 中,Android 10 和 11 的比例达到了 4:1 左右。难免会让人觉得这个问题是 Android 10 才突然出现的问题,Android 11 换成 Scudo 就好了。这个结论是否正确暂且按下不表,这里我做了第一次尝试:在 Android 10 中使用 Android 11 标配的 Scudo 分配器,而不使用 JeMalloc ,是不是就能解决这个问题了?
0x0c 尝试:移植 Scudo 到 Android 10
这个过程比较艰辛,主要是两部分工作:
把 Android 11 中的 Scudo 分配器源码拉出来,单独编译成一个动态库依赖到我们的应用;
通过一系列 Hook 手段,将应用的 Native 代码中涉及内存分配的函数,替换成 Scudo 分配器中的分配函数。
在实现这个方案的时候发现存在一些问题:
不只是 malloc 族函数会申请内存,strdup 和 strndup 这两个函数会在内部自己 malloc ,也要注意 Hook 掉;
安卓应用的 Native 内存申请不只是我们自己的 Native 代码,还有相当一部分是安卓自己的系统库,虽然 Hook 系统库不是不行,但是会存在下面的一个致命问题,在我们自行提供内存分配器的时候,会出现两种 case:
a. 使用系统 JeMalloc 申请的内存会尝试在我们自定义的分配器中释放:可以判断一下如果不是我们申请的内存,可以调用 libc 的 free 进行释放。如何来判断内存是不是我们的分配器申请的,大家可以学习一下 Scudo 的源码,写得非常精致;
b. 如果使用我们提供的分配器分配内存,再尝试使用系统的 JeMalloc 释放:无解,JeMalloc 不会考虑这种情况,你会得到一个信号 11,当然可以自己去处理 段错误,但这么费劲有点没必要了。
由于可能出现 2.b 这种情况,所以这种方案充满了不确定性,因为不能预料用户是怎么申请内存的,就无法从理论上证明可以 100% 覆盖所有内存操作,达不到上线标准。因此替换掉 JeMalloc 这条路行不通。
0x10 最终解决方案 Patrons
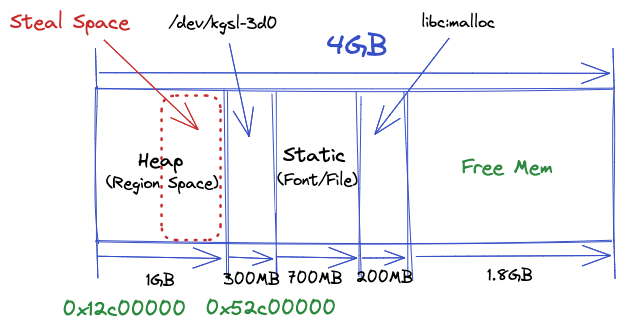
既然不能把 native 的内存分配到 art 虚拟机中去,那么干脆把这部分地址空间让出来好了。堵不如疏,不需要对 native 的内存分配进行任何修改和 hook,即可让 libcmalloc 使用这部分地址空间,可以极大缓解虚拟内存不足的问题。我们简单的回顾一下应用刚启动的时候,大致的内存布局:
提升 Android 稳定性的方案 Patrons,目前已经开源到 GitHub 上 :
https://github.com/alibaba/Patrons
这个方案的重点在于如何让 ART 把 Heap 预分配的地址空间释放出一部分。
首先说一下为什么要压缩这部分地址空间。通常情况下,我们的应用都会开启 largeHeap 来获得更大的内存上限,因为默认配置下只有 192M。这是由参数 dalvik.vm.heapgrowthlimit 决定的,对于大部分阿里系应用来说显然是不够的。但是开启 largeHeap 之后,应用启动的时候就会申请 1GB 的地址空间。同样对于大部分应用来说,直到 abort 或者应用被杀死,都不会使用如此多的地址空间。
实际上我们需要的是可以动态调整堆的地址空间。要想操作这部分地址空间,自然要研究一下 Android 是怎么管理这部分地址空间的。上文中提到 Android 实际上存在多种地址空间管理办法,目前的 Android 8(90%+ 以上用户) 以上版本都是通过 Region Space, 具体细节大家可以自行查阅 Android 源码。
那么问题就明确成了:如何动态调整 Region Space 的大小?这里需要了解一些前提,Region Space 之所以一经启动就会占用地址空间,显然是通过 mmap 拿到的,那分配结果自然会保存在某个成员变量上,具体怎么找到它?依然是阅读源码找到答案:region_space_ 保存在 Heap 实例中,而 Heap 实例则保存在 Runtime 中的 heap_,而这些字段都最终编译在 libart.so 中,所以要想操作这些,前提是至少可以手动加载 libart.so。最终需要构成下面的一条依赖关系:
libart ------> runtime_ ------> heap_ ------> region_space_
这里会遇到第一个问题,namespace 隔离机制,用以保证无法跨命名空间加载其他 so,可以通过阅读源码了解 Android 中 so 是怎么加载的。最终会使用到 libdl 的 __loader_dlopen,这个 dlopen 和我们常见的 dlopen 似乎有点区别,它多了一个参数,也就是 caller_addr,这是一个函数指针。再往下看就会发现它是通过拿到调用者之后去查表,找到 namespace,并和要加载的目标 so 的 namespace 进行对比,看看是否是互相可见的 namespace,来确定是否允许加载的。
这样一来想要破解这个隔离机制就易如反掌了,需要两样东西:
拿到包含 3 个参数的方法:__loader_dlopen 的指针;
拿到一个和目标 so 相同 namespace 的函数指针。
怎么拿到这个函数以及虚假的 caller_addr 不在这篇文章的讨论范围内,大家可以自行研究,核心思路是解析 ELF 即可(这里用到了 iqiyi 的开源项目 xhook:生产级的 PLT Hook 方案)。通过同样的套路,就可以破解 dlsym 了,也就能够完成 libart.so 的加载。
第二个问题就是如何通过找到各个属性相对于实例的偏移呢?我们以查找 region_space_ 相对于 heap_ 的偏移举例:首先需要找到一个 Heap 的实例方法,其中需要包含有对 region_space_ 的操作,比方说 art::gc::Heap::TrimSpaces() 这个函数,因为这是一个实例方法,所以 r0 就是实例本身 (heap_), 那么反编译 libart.so 之后,观察这个 TrimSpace 方法,可以发现在中间连续三个 if 的最后一个 if 的条件中用到了 region_space_,那么我们就拿到了 region_space_ 相对于 r0 也就是 heap_ 的偏移:
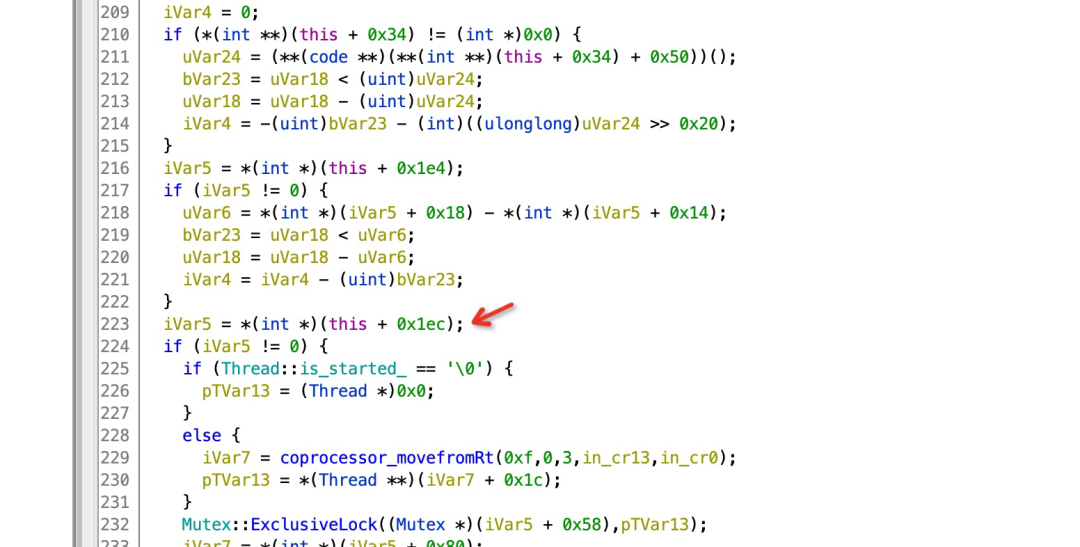
到此为止,调整 Region Space 所需要的前提都已经具备了,接下来就是通过找到 region_space_ 相对 heap_ 的偏移,一环套一环找到所有需要的条件。
可能有同学会问,为什么没有提到怎么调整 region_space_ 呢?其实也非常简单,可以通过 RegionSpace 的实例方法:RegionSpace::ClampGrowthLimit(size_t new_capacity) 来对 region_space_ 进行调整,大家可以自行查阅源码,逻辑比较简单,因为 Region Space 管理的内存是线性分配的,只要是还没用到 region 都是可以释放掉的。所以前面一系列的准备,就是为了能调用到这个方法。也就是说,在 >= 9 的 Android 版本中,找到 runtime_、heap_、region_space_ 之后,直接调用 ClampGrowthLimit 就可以调整 Region Space 大小了。在 <= 8 的版本中并没有这个方法,不过这也难不倒大家,自己参照 Android 9 中的源码实现一下就好了,没有太大的难度。
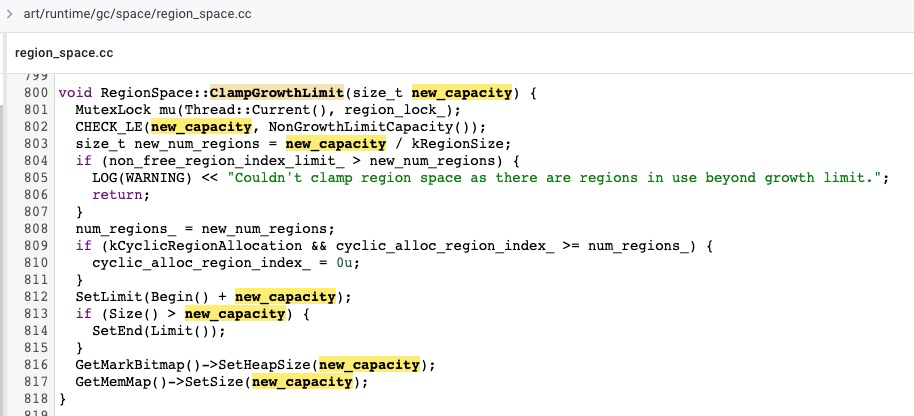
可能还有同学会问:如果依赖偏移查找会不会需要做大量适配工作?就实际情况来看,国内厂商对 ART 内存管理部分的修改是比较小的,参照 aosp 的版本就能做的差不多了。因为本来也不需要保证 100% 都能对的上,对不上就对不上好了,自己做好校验和保护,通过 longjump 等方式做一个 try catch 即可。
这里简单的提一下如何对前述通过偏移量拿到的各个实例进行校验:因为 Region Space 是按 Region 管理内存分配的,所以有以下公式:
num_regions_ * kRegionSize = *limit_ - *begin_;
剩下的就比较简单了,上层业务做一个定时轮询,设定一个阈值,每当虚拟内存达到 n% 的时候,就压缩一下 Region Space ,设置好步长,保证好下限即可。把以上逻辑封装起来,辅以相关的检查和调度,就是 Patrons 的全部内容了。
0x14 Patrons 实战效果
Patrons 方案在阿里集团内部推出之后,某航旅类应用首先完成了接入,新版本上线后,Native Crash 率下降了 80%。后续其他头部应用也陆续完成了接入,某电商类应用 Native Crash 下降了 78.6%。经过一段时间的统计,接入 Patrons 的集团头部应用,Native Crash 平均下降了接近 50%,大幅度提升了应用的稳定性,让客户用起来更加稳定放心。
0x18 附录 1:使用方法
工程中添加 gradle 依赖:
# build.gradle
implementation “com.alibaba:patrons:1.0.6.3”
# java
int code = Patrons.init(null); // 非 0 则初始化失败,可以埋点上报便于统计
默认情况下只需要在内存不足之前进行 Patrons 的初始化即可,兼容 Android 8、8.1、9、10、11,不兼容版本中不会生效,也没有副作用。
0x1c 附录 2:我的应用是否可以接入?
Patrons 方案已经开源到阿里集团的 GitHub Group 下,应用 MIT 授权协议,遵照该协议即可使用。
但是需要注意的是,该方案仅对大型 32 位 Android 应用有效,因为中小型应用因为业务规模有限,一般不会遇到虚拟内存不足的问题。当然这是建立在没有 or 较少内存泄漏的前提下,由于大量内存泄漏导致的虚拟内存不足不在本文讨论范围内。
作者介绍:
刘志龙,花名正纬,阿里巴巴高级无线开发专家,手机天猫端侧交易链路负责人。
2015 年毕业于哈尔滨理工大学,同年加入阿里云,负责手机阿里云从 0 到 1 建设,以及部分 Emas 移动服务相关业务。2019 年来到手机天猫,负责手猫端侧详情、交易链路,以及 Android 基础架构、端侧动态化搭建平台等相关技术创新、服务于千万天猫用户。打造并开源了 Android 组件化通信方案 ARouter、Android Native 稳定性保障方案 Patrons,在国内 Android 领域有着广泛的应用。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论