

在本文中,我们将演示如何使用 Amazon Elastic Container Service for Kubernetes (Amazon EKS) 在 AWS 上创建完全托管的 Kubernetes 集群,以及如何使用 Kubeflow 和 AWS FSx CSI 驱动程序运行分布式深度学习训练作业。然后,我们将讨论在 Amazon EKS 上优化机器学习训练性能的最佳实践,以提高吞吐量并最大限度地缩短训练时间。
我们将 ResNet-50 与 ImageNet 数据集和 Amazon EC2 P3 实例与 NVIDIA Tesla V100 GPU 结合使用,以设定训练吞吐量性能基准。
本文受前两篇博文启发:使用 AWS 云中的 GPU 进行可扩展多节点深度学习训练,以及使用 AWS Batch 和 Amazon FSx for Lustre 的多节点并行作业进行可扩展深度学习训练。
首先,让我们回顾一下解决方案的组成部分:
Kubernetes 是一种越来越受欢迎的深度神经网络训练选项,因为它提供了通过容器使用不同机器学习框架的灵活性,以及按需扩展的敏捷性。Amazon EKS 是 AWS 提供的托管 Kubernetes 服务,可以在 AWS EC2 P2 和 P3 实例上运行 Kubernetes 工作负载。
Kubeflow 是一个开源的 Kubernetes 原生平台,用于开发、编排、部署和运行可扩展的便携式机器学习工作负载。Kubeflow 可以在任何 Kubernetes 集群上运行,包括由 Amazon EKS 托管的集群。Kubeflow 支持两种不同的 Tensorflow 框架分布式训练方法。第一种是原生 Tensorflow 架构,它依赖于集中式参数服务器来实现工作线程之间的协调。第二种是分散式方法,工作线程通过 MPI AllReduce 原语直接相互通信,不使用参数服务器。NVIDIA 的 NCCL 库已经在 GPU 上有效地执行了大部分 MPI 原语,而 Uber 的 Horovod 让使用 TensorFlow 执行多 GPU 和多节点训练变得轻而易举。与参数服务器相比,第二种方法可以更好地优化带宽和更好地扩展。Kubeflow 提供 mpi-operator,可使 allreduce 样式的分布式训练像在单个节点上进行培训一样简单。
Amazon FSx for Lustre 是 AWS 的一项新服务,它与 S3 集成,并提供经过优化的高性能文件系统,可快速处理机器学习和高性能计算 (HPC) 等工作负载。借助 AWS FSx CSI 驱动程序,您可以使用持久卷和持久卷声明,以 Kubernetes 原生方式使用来自容器的 FSx for Lustre 文件系统。FSx CSI 驱动程序支持静态卷预置和动态卷预置,并且集群中多个节点的容器可连接到同一 Lustre 文件系统。您甚至可以将 S3 用作 Lustre 数据存储库,并将训练数据提供给容器,而无需手动传输数据来启动作业。
性能结果
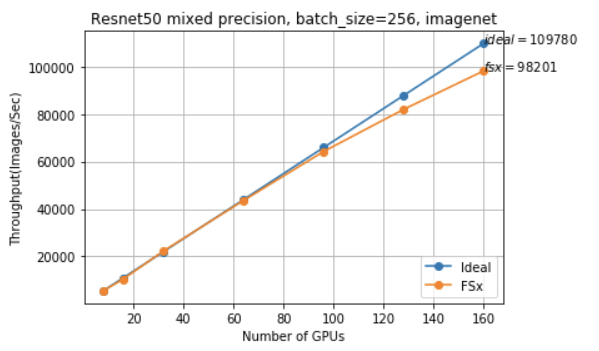
我们在 20 个 P3.16xlarge 实例使用混合精度(160 个 V100 GPU)上进行训练,每个 GPU 的批量大小为 256(总批量大小约为 41k)。为了实现更好的扩展效率,我们使用了 Horovod,这是一个与 TensorFlow 配合使用的分布式培训工具包,而非 Tensorflow 的原生参数服务器方法。
我们使用 TensorFlow 观察了近线性扩展,在 90-100% 之间扩展效率高达 160 GPU 和每秒 98k 图像。
配置
Amazon EKS (Kubernetes v1.11.8)
Kubeflow 0.4.1 的 MPI Operator Alpha
Amazon EKS 优化版 AMI(支持 GPU)
配置 NVIDIA Tesla 410.104 驱动程序的 CUDA 10
Docker 18.06.1-ce(包括 nvidia-docker2)
FSx for Lustre 文件系统源自提供 ImageNet TFRecords 的 S3 存储桶
FSx CSI Driver v0.1
自定义 Tensorflow 图像
TENSORFLOW_VERSION=v1.13.1
HOROVOD_VERSION=0.16.0
CUDNN_VERSION=7.4.2.24-1+cuda10.0
NCCL_VERSION=2.4.2-1+cuda10.0
OPENMPI 4.0.0
步骤
以下步骤将向您展示如何使用您自己的集群复制我们的工作。
先决条件
首先确保已安装以下工具:
awscli
eksctl
ksonnet
aws-iam-authenticator
准备 Imagenet 数据集
ImageNet 是最著名的图像分类数据集。自发布以来,大多数推动图像分类技术发展的研究均基于此数据集。
ImageNet 数据集由 image-net.org 提供。您需要先注册,然后才能下载原始数据集,其中包含 1,000 个类别中的原始 1.28M 图像。使用 utils 目录中提供的脚本或按照教程处理 ImageNet 图像以创建 Tensorflow 的 TF Record。创建一个用于存储 ImageNet 数据集的 S3 存储桶;有 1024 个训练文件和 128 个验证文件,总共约 57GB。以下是我们的数据:
使用 Amazon EKS 配置 Kubernetes 集群
使用 eksctl(Amazon EKS 的命令行工具)创建集群(根据需要更新参数):
创建集群后,可以通过部署 NVIDIA 设备插件在其中启用 GPU 支持:
安装 MPI Operator
MPI Operator 是 Kubeflow 的一个组件,可以轻松地在 Kubernetes 上运行 allreduce 样式的分布式训练。在操作系统上安装 ksonnet 后,可按照以下步骤安装 MPI Operator。将安装 MPIJob 和作业控制器,然后可以将 MPIJob 提交到 Kubernetes 集群。
添加注册表:
安装数据包:
生成 manifest:
部署:
将 FSx CSI 驱动程序安装到集群上
按照说明安装 FSx for Lustre CSI 驱动程序。
驱动程序启动后,可以准备持久卷声明和存储类。为了使用 FSx for Lustre,需要创建两个文件:storageclass.yaml 和 claim.yaml。
S3 可以用作 Lustre 数据存储库,并且无需将数据从 S3 显式复制到 Lustre。持久卷将动态预置,并可由 Kubernetes 安装到容器。
按照动态预置示例替换资源文件中的 subnetId、securityGroupIds 和 s3ImportPath
s3ImportPath 是前面步骤中使用数据集创建的存储桶。
可通过检查 AWS EC2 面板获取 subnetId 和 securityGroupId。请注意,ReadWriteMany 用于允许 Pod 共享卷。
使用安全组已打开 Lustre 使用的端口 988。
如果希望更深入地了解 CSI 驱动程序以及如何设置和使用 FSx CSI 驱动程序,还可以参考将 FSx for Lustre CSI 驱动程序与 Amazon EKS 结合使用。
构建容器镜像
AWS 深度学习容器(AWS DL 容器)是预先安装了深度学习框架的 Docker 镜像,可以轻松快速地部署自定义机器学习 (ML) 环境。深度学习容器让您可以跳过从头开始构建和优化环境的复杂过程;它们为 AWS 实例提供最新的 Tensorflow、Horovod 和拓扑优化。
构建 Docker 镜像需要几分钟时间。如果您想要节省一些时间并跳过构建自有镜像的过程,我们已使用 AWS DL 容器作为基础层为您构建了一个镜像,请查看预先构建镜像详细信息。
如果您想自己构建镜像,请将此 Dockerfile 下载到本地计算机并构建容器镜像,如下所示。
在拉取映像之前,登录以访问镜像存储库:
构建您的容器镜像:
推送至容器注册表:
提交培训作业
我们上面构建的 EKS 集群目前只有一个节点。为了运行多节点分布式训练,您需要添加更多节点。为此,您可以使用 eksctl 将自动扩展组更新为所需的节点数。
检查节点组名称:
扩展训练工作线程节点:
下载 MPI 模板作业 manifest,然后
将副本更新为 GPU 工作线程的数量。
在正在使用的实例类型上,将
nvidia.com/gpu: 8更新为 GPU 的数量将镜像更新为您自己构建的镜像
注意:在等待 FSx for Lustre 永久卷预置时,您的作业可能会挂起。
性能优化
以下是供您尝试实现最高性能的一些优化(有些未包含在上面)。您可以尝试其中任何一个或全部,然后重新运行实验以查看结果如何变化。
使用最新的深度学习工具套件。用于 EKS 的 GPU 优化型 AMI 附带最新的 NVIDIA Linux 驱动程序 410.104。得益于此,我们可以使用 CUDA 10.0、Tensorflow v1.13.1 以及兼容的 cuDNN 和 NCCL 构建自定义容器镜像。新版本提供了出色的性能改进和关键错误修复。有关详细信息,请参阅 Amazon 深度学习容器。
将 GPU 时钟速度设置为最大频率。 默认情况下,NVIDIA 驱动程序会改变 GPU 时钟速度。通过将 GPU 时钟速度设置为最大频率,您可以始终使用 GPU 实例实现最高性能。检查此 CloudFormation 模板中的 bootstrap 命令。有关更多详细信息,请参阅优化 GPU 设置。
启动置放群组中的实例,以利用低延迟而不降低速度。 您可以使用此 CloudFormation 模板添加具有无阻塞、无超订、完全双向连接性的新节点组。
使用最新的 AWS VPC CNI 插件获得巨帧支持。默认情况下,所有 NIC 在 EKS 集群上都会获得巨帧。
选择正确的存储后端。在我们的实验中,我们测试了 EBS、EFS 和 FSx for Lustre。I/O 性能是整体性能的关键因素。在训练期间,数据预处理 (CPU) 和训练步骤 的模型执行 (GPU) 并行运行。当加速器执行训练步骤 N 时,CPU 正在为步骤 N+1 准备数据(有关详细信息,请参见并行化数据转换)。如果您注意到 GPU 利用率并不总是 >95%,则 GPU 可能正在等待 CPU 完成工作。在这种情况下,还有改进空间。P3.16xlarge 实例具有 488GiB 内存,因此您的整个训练数据集可以适合内存。这意味着,在一个纪元后,您的存储后端对性能没有任何影响。您可以利用本地节点内存以提供吞吐量,并可以使用性能较低的后端。
使用静态 Kubernetes CPU 管理策略访问独占 CPU。默认情况下,在 Kubernetes 集群的计算节点上运行的所有 pod 和容器可以在系统中的任何可用核心上执行。启用 CPU 管理器静态策略后,可以为工作负载容器分配独占 CPU,但不能为其他容器分配独占 CPU。在训练案例中,CPU 工作可能对上下文切换敏感。如果多个训练作业共享同一节点,则使用静态策略会很有帮助。
通过进程绑定使用正确的 MPI 处理器关联。 Open MPI 通过进程绑定支持各种系统上的处理器关联,其中每个 MPI 进程及其线程均“绑定”到特定的处理资源子集(核心、套接字等)。节点的操作系统将限制进程仅在该子集上运行。通过减少资源争用(通过将进程彼此分散)或改进进程间通信(通过将进程彼此靠近),灵活使用绑定可提高性能。绑定还可以通过消除变量过程置放,提高再现性。根据我们的测试,使用 --bind-to socket -map-by slot 是 p3.16xlarge 实例的最优化选项。
通过使用英特尔®MKL DNN 构建 Tensorflow 来优化 CPU 性能。英特尔® 通过使用面向深度神经网络的英特尔® 数学核心函数库(英特尔® MKL-DNN)优化型原语,为英特尔® 至强® 和英特尔® 至强融核™ 的 TensorFlow 添加优化。优化还为英特尔的消费者处理器提供了速度提升,例如 i5 和 i7 英特尔处理器。如需在容器镜像中从源构建 Tensorflow,请查看 Dockerfile 以获取详细信息。
优化 Tensorflow 以并行化数据转换过程和并行线程。工作负载的最佳价值取决于使用的硬件和训练数据。一种简单的方法是使用可用 CPU 核心数。相应的参数是 num_parallel_calls。P3.16xlarge 有 64 个 vCPU,一个训练工作线程使用 8 个 GPU,因此我们使用 64 / 8 = 8。根据您使用的实例类型,通过将可用 CPU 核心数除以 GPU 数,提供设置此值的正确数字。
调整线程池和调整 CPU 性能。 相应的参数是 intra_op_parallelism_threads 和 inter_op_parallelism_threads。通常,建议将 intra_op_parallelism_threads 设置为物理核心数,并将 inter_op_parallelism_threads 设置为套接字数。P3.16xlarge 有两个套接字,每个套接字 16 个核心。由于使用了超线程,每个核心都有两个线程。这为我们提供了总共 64 个逻辑 CPU 和 32 个物理核心。根据我们在 GPU 训练中的测试,未发现调整这些参数时存在显著差异。如果您不想调整它们,只需分配 0 即可,系统将自动为您选择一个合适的数字。
小结和后续步骤
这项工作的结果表明,Amazon EKS 可以使用高性能、灵活且可扩展的架构,进行深度学习网络的快速训练。也就是说,我们认为,此博文中描述的实施仍有优化性能的空间。我们的目标是消除不同层次的性能障碍,并提高 EKS 分布式训练的整体扩展效率。
由于集群实施和训练工作量各不相同,我们构建了一个易于使用的深度学习基准测试实用程序,您可以使用该实用程序在 Amazon EKS 上自动运行深度学习基准测试作业。这有助于自动化本文中描述的过程。该项目尚处于初期阶段,我们欢迎所有人就 GitHub 上的 aws-eks-deep-learning-benchmark 提供建议和贡献。
作者介绍:
Jiaxin Shan
AWS 软件开发工程师
本文装载自 AWS 技术博客。
原文链接:


Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论