
美图影像研究院(MT Lab)与中国科学院信息工程研究所、北京航空航天大学、中山大学共同提出了 3D 场景编辑方法——CustomNeRF,同时支持文本描述和参考图像作为 3D 场景的编辑提示,该研究成果已被 CVPR 2024 接收。
背景
自 2020 年神经辐射场(Neural Radiance Field, NeRF)提出以来,将隐式表达推上了一个新的高度。作为当前最前沿的技术之一,NeRF 快速泛化应用在计算机视觉、计算机图形学、增强现实、虚拟现实等领域,并持续受到广泛关注。
有赖于易于优化和连续表示的特点,NeRF 在 3D 场景重建中有着大量应用,也带动了 3D 场景编辑领域的研究,如 3D 对象或场景的纹理重绘、风格化等。为了进一步提高 3D 场景编辑的灵活性,近期基于预训练扩散模型进行 3D 场景编辑的方法也正在被大量探索,但由于 NeRF 的隐式表征以及 3D 场景的几何特性,获得符合文本提示的编辑结果并非易事。
为了让文本驱动的 3D 场景编辑也能够实现精准控制,美图影像研究院(MT Lab)与中国科学院信息工程研究所、北京航空航天大学、中山大学,共同提出了一种将文本描述和参考图像统一为编辑提示的 CustomNeRF 框架,可以通过微调预训练的扩散模型将参考图像中包含的特定视觉主体 V∗嵌入到混合提示中,从而满足一般化和定制化的 3D 场景编辑要求。该研究成果目前已被 CVPR 2024 收录,代码已开源。

l 论文链接:https://arxiv.org/abs/2312.01663
l 代码链接:https://github.com/hrz2000/CustomNeRF
CustomNeRF 解决的两大挑战
目前,基于预训练扩散模型进行 3D 场景编辑的主流方法主要分为两类。
其一,是使用图像编辑模型迭代地更新数据集中的图像,但是受限于图像编辑模型的能力,会在部分编辑情形下失效。其二,则是利用分数蒸馏采样(SDS)损失对场景进行编辑,但由于文本和场景之间的对齐问题,这类方法在真实场景中无法直接适配,会对非编辑区域造成不必要的修改,往往需要 mesh 或 voxel 等显式中间表达。
此外,当前的这两类方法主要集中在由文本驱动的 3D 场景编辑任务中,文本描述往往难以准确表达用户的编辑需求,无法将图像中的具体概念定制化到 3D 场景中,只能对原始 3D 场景进行一般化编辑,因此难以获得用户预期中的编辑结果。
事实上,获得预期编辑结果的关键在于精确识别图像前景区域,这样能够在保持图像背景的同时促进几何一致的图像前景编辑。
因此,为了实现仅对图像前景区域进行准确编辑,该论文提出了一种局部-全局迭代编辑(LGIE)的训练方案,在图像前景区域编辑和全图像编辑之间交替进行。该方案能够准确定位图像前景区域,并在保留图像背景的同时仅对图像前景进行操作。
此外,在由图像驱动的 3D 场景编辑中,存在因微调的扩散模型过拟合到参考图像视角,所造成的编辑结果几何不一致问题。对此,该论文设计了一种类引导的正则化,在局部编辑阶段仅使用类词来表示参考图像的主体,并利用预训练扩散模型中的一般类先验来促进几何一致的编辑。
CustomNeRF 的整体流程
如图 2 所示,CustomNeRF 通过 3 个步骤,来实现在文本提示或参考图像的指导下精确编辑重建 3D 场景这一目标。
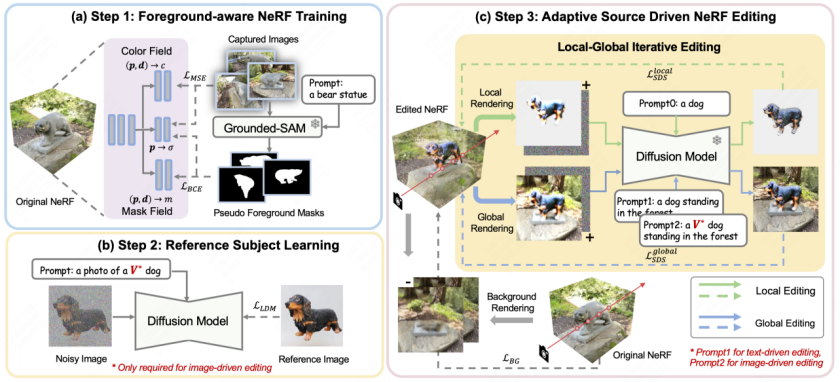
首先,在重建原始的 3D 场景时,CustomNeRF 引入了额外的 mask field 来估计除常规颜色和密度之外的编辑概率。如图 2(a) 所示,对于一组需要重建 3D 场景的图像,该论文先使用 Grouded SAM 从自然语言描述中提取图像编辑区域的掩码,结合原始图像集训练 foreground-aware NeRF。在 NeRF 重建后,编辑概率用于区分要编辑的图像区域(即图像前景区域)和不相关的图像区域(即图像背景区域),以便于在图像编辑训练过程中进行解耦合的渲染。
其次,为了统一图像驱动和文本驱动的 3D 场景编辑任务,如图 2(b)所示,该论文采用了 Custom Diffusion 的方法在图像驱动条件下针对参考图进行微调,以学习特定主体的关键特征。经过训练后,特殊词 V∗可以作为常规的单词标记用于表达参考图像中的主体概念,从而形成一个混合提示,例如“a photo of a V∗ dog”。通过这种方式,CustomNeRF 能够对自适应类型的数据(包括图像或文本)进行一致且有效的编辑。
在最终的编辑阶段,由于 NeRF 的隐式表达,如果使用 SDS 损失对整个 3D 区域进行优化会导致背景区域发生显著变化,而这些区域在编辑后理应与原始场景保持一致。如图 2(c)所示,该论文提出了局部-全局迭代编辑(LGIE)方案进行解耦合的 SDS 训练,使其能够在编辑布局区域的同时保留背景内容。
具体而言,该论文将 NeRF 的编辑训练过程进行了更精细的划分。借助 foreground-aware NeRF,CustomNeRF 可以在训练中灵活地控制 NeRF 的渲染过程,即在固定相机视角下,可以选择渲染前景、背景、以及包含前景和背景的常规图像。在训练过程中,通过迭代渲染前景和背景,并结合相应的前景或背景提示,可以利用 SDS 损失在不同层面编辑当前的 NeRF 场景。其中,局部的前景训练使得在编辑过程中能够只关注需编辑的区域,简化复杂场景中编辑任务的难度;而全局的训练将整个场景考虑在内,能够保持前景和背景的协调性。为了进一步保持非编辑区域不发生改变,该论文还利用编辑训练前的背景监督训练过程中所新渲染的背景,来保持背景像素的一致性。
此外,图像驱动 3D 场景编辑中存在着加剧的几何不一致问题。因为经过参考图像微调过的扩散模型,在推理过程中倾向于产生和参考图像视角相近的图像,造成编辑后 3D 场景的多个视角均是前视图的几何问题。为此,该论文设计了一种类引导的正则化策略,在全局提示中使用特殊描述符 V*,在局部提示中仅使用类词,以利用预训练扩散模型中包含的类先验,使用更几何一致的方式将新概念注入场景中。
实验结果
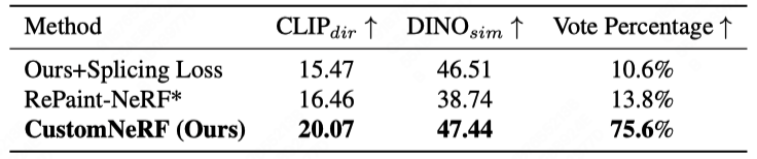
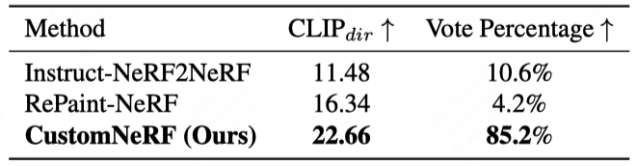
如图 3 和图 4 展示了 CustomNeRF 与基线方法的 3D 场景重建结果对比,在参考图像和文本驱动的 3D 场景编辑任务中,CustomNeRF 均取得了不错的编辑结果,不仅与编辑提示达成了良好的对齐,且背景区域和原场景保持一致。此外,表 1、表 2 展示了 CustomNeRF 在图像、文本驱动下与基线方法的量化比较,结果显示在文本对齐指标、图像对齐指标和人类评估中,CustomNeRF 均超越了基线方法。


总结
本论文创新性地提出了 CustomNeRF 模型,同时支持文本描述或参考图像的编辑提示,并解决了两个关键性挑战——精确的仅前景编辑以及在使用单视图参考图像时多个视图的一致性。该方案包括局部-全局迭代编辑(LGIE)训练方案,使得编辑操作能够在专注于前景的同时保持背景不变;以及类引导正则化,减轻图像驱动编辑中的视图不一致,通过大量实验,也验证了 CustomNeRF 在各种真实场景中,能够准确编辑由文本描述和参考图像提示的 3D 场景。
研究团队
该研究成果由美图影像研究院(MT Lab)和中国科学院信息工程研究所、北京航空航天大学、中山大学的研究者们共同提出。
美图影像研究院(MT Lab)是美图公司致力于计算机视觉、机器学习、增强现实、云计算等领域的算法研究、工程开发和产品化落地的团队,为美图秀秀、美颜相机、Wink、美图设计室、美图云修、WHEE 等美图旗下全系软硬件产品提供技术支持,同时面向影像行业内多个垂直赛道提供针对性 SaaS 服务,通过前沿技术推动美图产品发展,曾先后荣获国家科学技术进步奖、教育部技术发明奖,同时在 CVPR、ICCV、ECCV 等国际计算机视觉顶级赛事中斩获十余项冠亚军奖项,并在人工智能领域顶级会议与顶级期刊上累计发表 49 篇学术论文。
2023 年,美图公司持续持续深入 AI 领域,研发投入 6.4 亿元,占总收入的 23.6%,同年 6 月,正式推出美图奇想大模型(MiracleVision),依托强大技术能力,在不到半年时间已经迭代至 4.0 版本。未来,美图影像研究院(MT Lab)将加强 AI 能力储备,在技术端持续强化模型能力,助力构建 AI 原生工作流。




