

微信读书是市场上很欢迎的电子书籍阅读 APP, 每天唤醒的用户接近 500 万,并且还在快速增长,增长速度取决于投放的力度,APP 的阅读体验和推荐的质量。用户可以通过搜索购买自己喜欢的书籍和关系链用户的阅读行为进行筛选阅读。我们有无限卡和其他活动的形式吸引和鼓励用户阅读。
除了前述几种方式以外,用户很难再有其他方式发现更多有趣的书籍和文章,因此,猜你喜欢和故事流应运而生,我们利用用户在 APP 内的阅读、关注、分享、关系链等信息,结合机器学习和深度学习算法,为用户推荐最符合兴趣书籍,公众号。除了文章和书籍以外,也接入了腾讯视频,大大丰富了推荐的内容多样性,当然我们也还在不断地优化我们的展示形式和推荐算法以及推荐架构。
前言
微信读书猜你喜欢包括书城猜你喜欢和卡片栏目的为你推荐。故事流则是融合书籍,公众号以及视频的 feed 推荐。推荐系统的质量直接影响着用户的留存和用户在 APP 停留时长,如何利用用户已有的行为信息打造一个合适的推荐系统显得至关重要。接下来将详细地讲解 APP 的书籍推荐算法以及后台推荐的架构是如何设计。
书城猜你喜欢的推荐逻辑
对于如何构建书籍和公众号的 item similarity,这里不再赘述构建算法。我们的后台服务架构也是相对简单,大致如下:
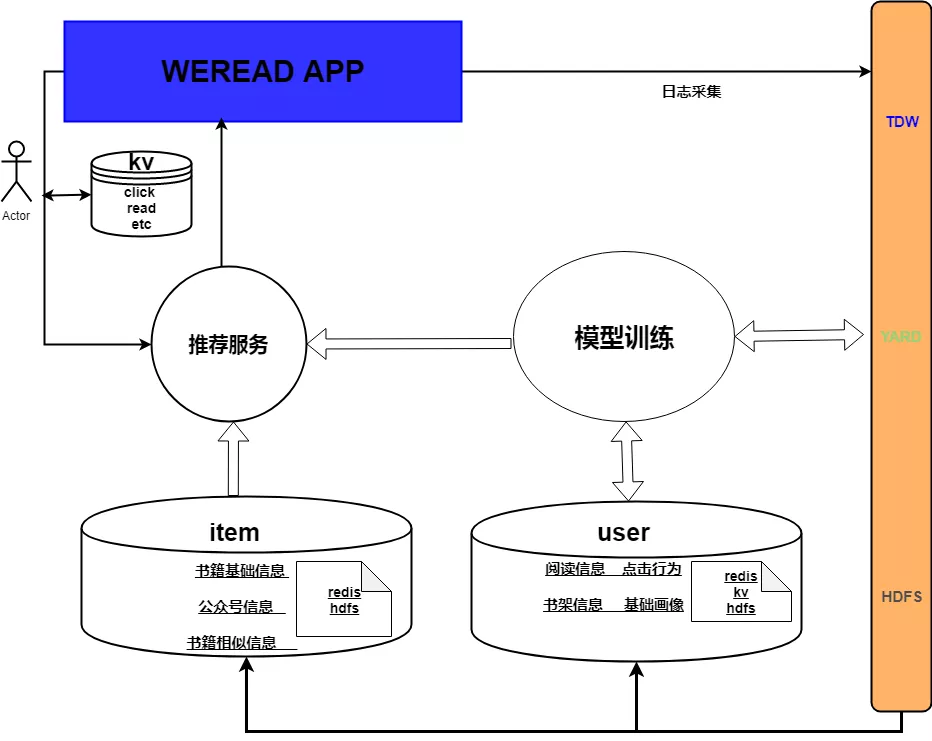
初期,我们并没有引入用户的实时行为,这里的时候行为包括:用户点击某本书,某个公众号或者阅读书籍的相关信息。一开始依赖的是 T+1 时刻用户的阅读统计。显而易见,收的成效是大打折扣的,后面随着 kv 的支持升级,我们把用户的实时的行为引入到我们的推荐逻辑,点击率也得到了比较大地的提升。这里并没有引入复杂的 MQ 的机制,在模型不需要实时更新的情况下,我们采取了一种折中的方案:我们把用户实时行为直接的存储在 paxos kv。结合用户的阅读历史以及一些运营的规则进行了推荐。对于新书的推荐,由于推荐栏的条数限制,一开始利用书籍本身的 tag 和分类做了一些 average embeding,考虑栏目条数限制和点击率,后面边去掉了新书推荐的逻辑。在书城的其他栏目我们给以了新书一些曝光机会。
卡片为你推荐
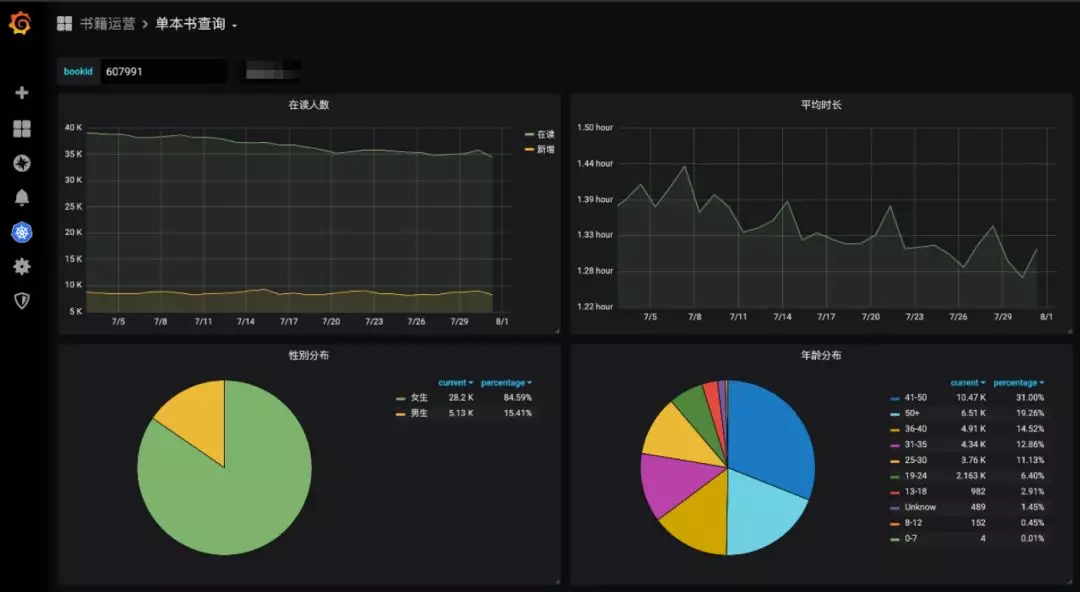
卡片为你推荐,一开始我们也只利用了用户的最近阅读和点击行为来进行相似推荐,后面观察到不同年龄性别的用户对书籍的阅读欲望是不同的:
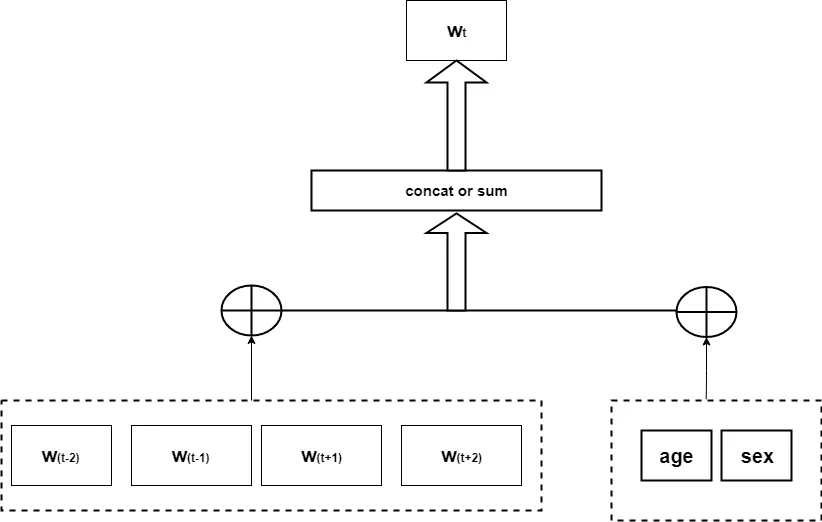
我们将用户的 basic profile 嵌入到我们的模型中,具体的嵌入模型如下:
模型训练完之后,我们 print 出用户的画像详细信息,格式(profile_sex_age),可以发现模型 is working
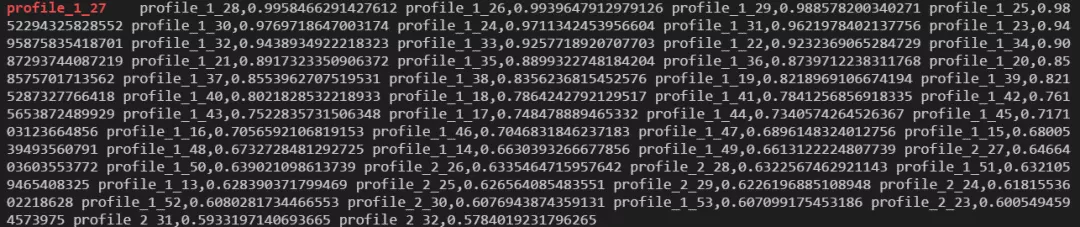
我们尝试了 concat 和直接 avg sum 的方式,发现 sum 的方式表现优于 concat。对比点击率效果(号段 8)对于如下:
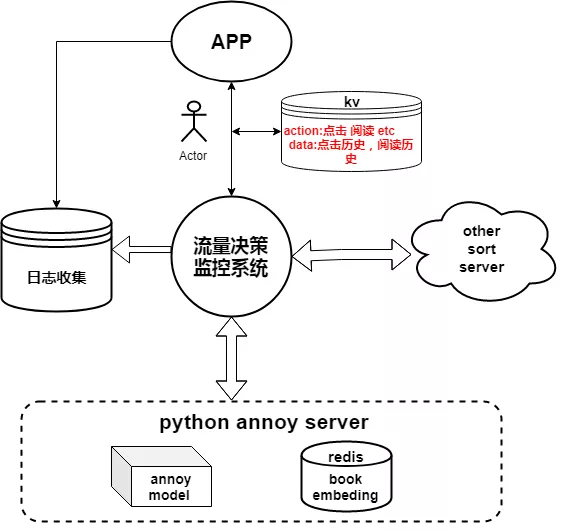
我们对于用户的最近阅读和点击行为做了热度和时间的加权惩罚得到一个 user recent interest embeding,然后通过 LSH server 进行了相关推荐,整体的架构如下:
故事流推荐架构和推荐算法
故事流模块是 APP 近期上线的一个 feed 模块。主要涉及书籍,公众号文章和企鹅号视频的混合推荐。涉及的模块比较多,首先来看下初期整体的推荐架构设计:
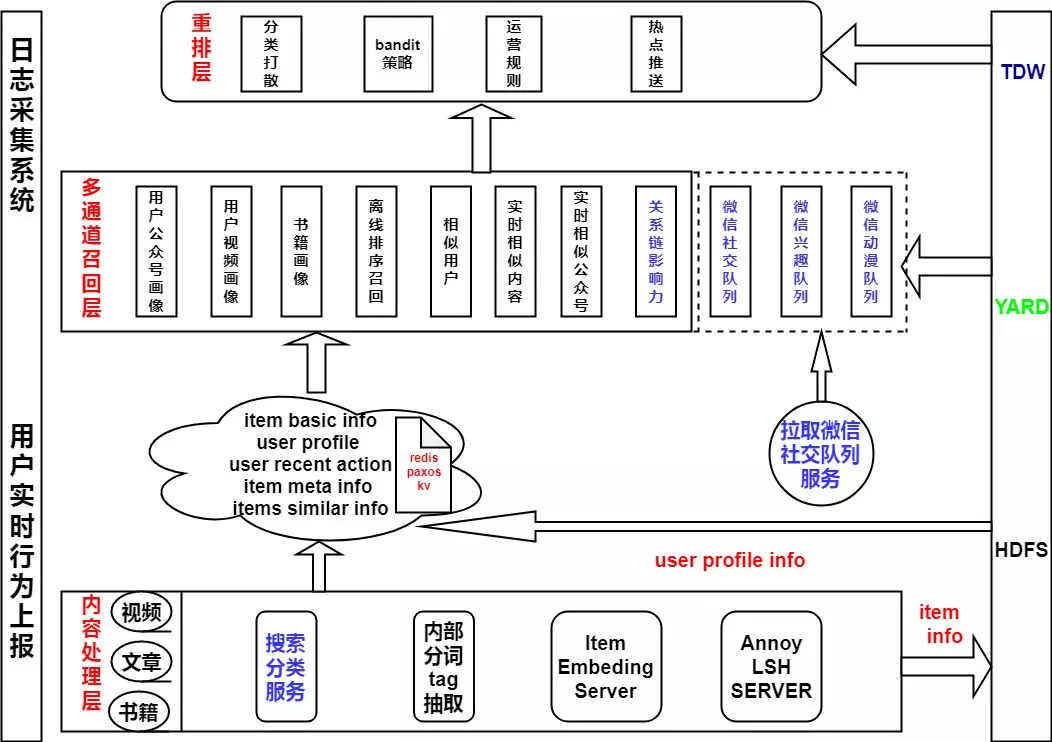
我们最底层采用了经典的召回、粗排、精排(暂时处于离线)三层结构。值得一提的是在架构中大量的引入了用户实时行为召回模块,包括跨类型的相互召回,主要考虑是用户短期对同一话题感兴趣程度更大。For example,用户在看完 NBA 相关的书籍,可能在 feed 上希望看到关于 NBA topic 的视频和公众号。目前我们不同类型的混排是简单的基于用户最近在不同内容类型的表现来采样条数,可以简单的理解为 bandit 算法,这里后面还有优化空间,目前考虑时间和后端存储迭代等因素,并没有引入太复杂的混排算法。
item 数据和 user 数据是推荐系统的天花板所在。推荐系统无非就是根据用户的兴趣从大量 item 中挑选最可能的 topN 条结果。对数据刻画得越准确,越细致,数据的表达能力越强,推荐也越精准。从整体上看,数据可以分为用户数据和内容数据。
1. item 基础数据处理(内容数据)
对于内容侧,我们引入了一系列的入库流程处理,包括分词,抽取 tag,计算 item embeding, 计算基于 content based item’s similar items。这里的 similar items 包括跨类型的相似信息。旨在捕获用户的实时行为,提供准确的 item 召回。整一个内容入库处理流程大致如下:
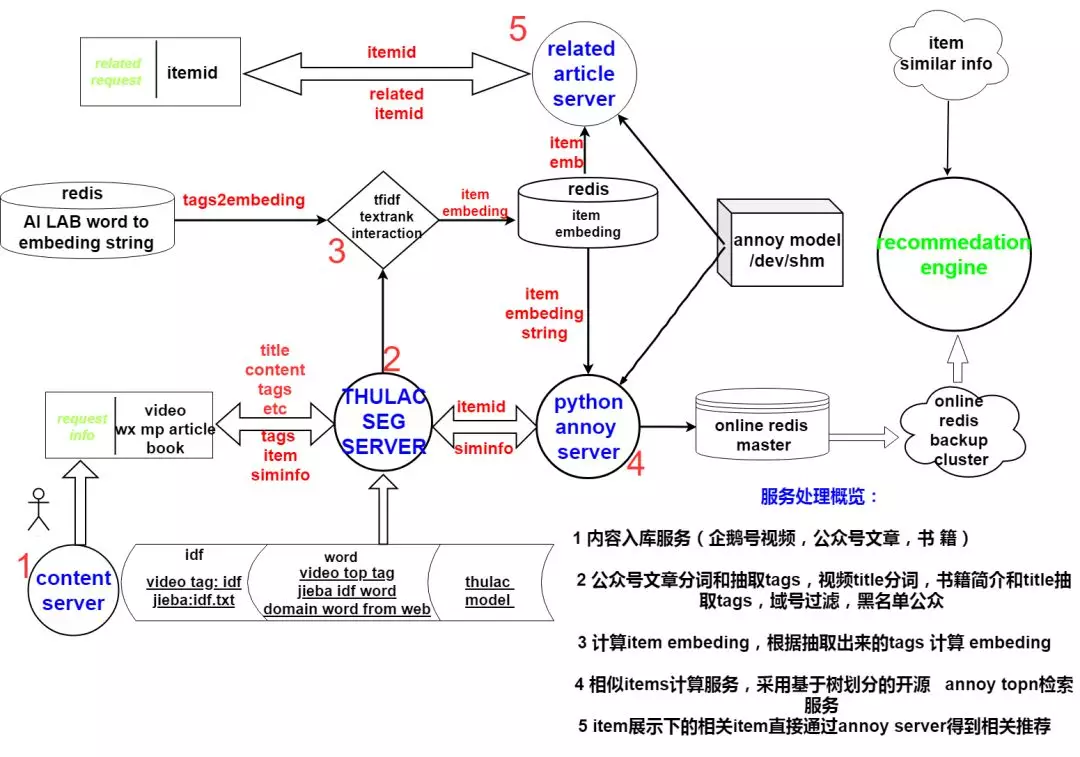
对于分词,我们对比了 jieba segment, 公司的 qq_segment tool 和 清华大学开源的 thulac 分词算法。考虑到入库的量和处理时间,我们最后选择了 thulac 算法,在对文章分完词后,我们引入了 tdidf 和 textrank 算法了综合计算文章的 key words。值得一提的是,我们在分词字典和 idf.txt 中引入了大量的视频 tags,书籍名,jieba 的 idf 字典和网上的开源词库,取得了不错分词成效,整个处理流程可以对新入库的 item 实时计算相似的 item。对于 word to embeding,我们则使用的是 ai lab 开源的 800 万的 embeding 加上一些后期处理。item 的相似信息,则是通过 python annoy server 实时计算,计算得到的相似信息存在到 paxos kv 和 hdfs,供实时召回和离线分析。
从整体的点击率来看,实时的相似 item 召回取得的效果是最佳的,在公众号,视频,书籍都取得了相同类型召回前几的成效。
2. user 画像的构建
用户画像的构建包括用户的视频二级分类画像,用户的兴趣公众号,用户的兴趣文章二级分类,用户的书籍阅读和书籍点击画像构建,用户的相似用户和用户影响力关系链构建。
用户的公众号画像构建:在 APP 内,我们有用户书架公众号,阅读过的文章,点赞过的文章,收藏过的文章,分享过的文章,我们可以刻画出用户的公众号感兴趣程度,此外我们还根据相似公众号扩展用户的公众号画像。对于用户的公众号二级分类画像,我们则根据用户对公众号的历史行为进行离线计算好后写入 kv。
用户的书籍画像:APP 内积累最多的就是用户的书籍阅读和点击行为,根据阅读时间的加权和相似书籍的扩展,我们便拥有的了用户的书籍兴趣画像。
用户的视频冷启动画像:一开始根据用户在 APP 积累的公众号行为,通过训练视频的二级分类的 bert 模型分类用户的公众号文章历史行为得到用户的视频冷启动画像。对比一开始的随机的推荐,也有不少的点击率提升。这里需要指出的是视频和公众号的分类体系并不一致,企鹅号视频自带了一套二级分类体系,文章的分类体系则使用了搜索的文章分类模型。
用户的关系链影响因子链:对于用户的实时行为,将用户在流的点赞评转行为扩散到关系链用户,作为备选召回集之一。
相似用户计算:我们并没有采取典型的 user cf 方法来计算,考虑到用户的量和相似矩阵的 weight 难以刻画。这里采取较为取巧的一种方式,利用用户在 APP 积累的阅读书籍时间和最近一次阅读时间,以及书籍的流行度来综合计算一个用户的 embeding,最后通过 LSH 的算法计算相似用户,取得了很不错的线上效果。过程中,我们尝试构建过用户和书籍的二部图的方式,以用户的阅读时间来作为二部图的权重,通过 node2vec graph embeding 算法来计算 user 和 item 的 embeding,最后取得的效果无论是在 item 的相似还是 user 相似都不尽人意。
3. offline 排序模块
典型的推荐系统,排序是一个直至关重要的模块,在架构发展的初期,我们没有针对每一个请求都进行一次排序,其中的原因多种多样(没有积累足够的用户行为,目前的推荐架构暂且不支持加入复杂排序模块),这里我们采取了一种折中的方案,我们针对用户的行为,进行了 T+1 的召回排序然后写入线上的 kv 队列进行推荐。目前,我们在公众号和视频进行了尝试,取得了不错的成效,我们根据用户最近的点击和阅读时间等行为进行了离线召回,包括二级分类的召回和内容的 avg embeding 召回,之后加入了 deepfm 模型作为排序模块。
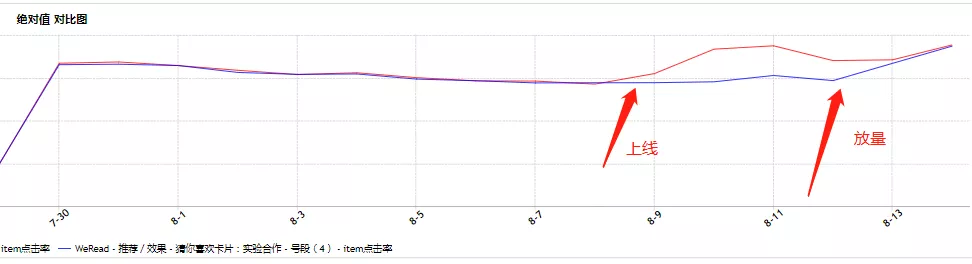
我们利用过去一个月的用户视频点击日志构建训练样本,以 AUC 作为评价指标构建二分类模型;再用召回视频队列构建测试集,输入到训练好的模型中进行排序,输出最终结果。
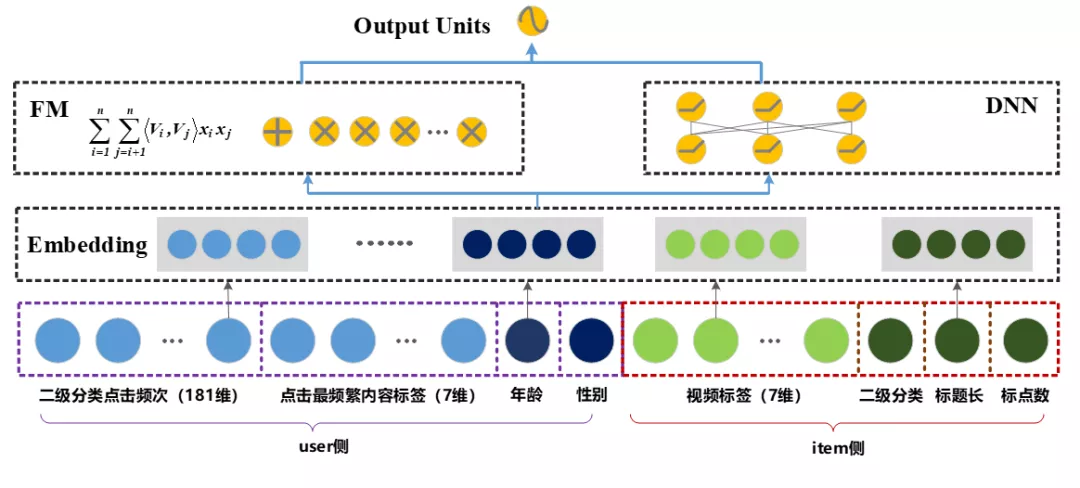
deepfm 输入特征:我们结合了 user 和 item 两个方面考虑进行模型训练。
user 特征:用户二级分类的累计点击频次、用户点击最频繁的标签、年龄、性别
item 特征:训练样本对应 item 的二级分类、tag、新闻标题长度、关键标点数
模型中的特征构建,主要出于以下两点思考:
不含 id 类特征,只基于静态特征和标签类特征,这样的模型只需定期更新,扩充样本量即可(召回策略仍需每天更新)
公众号文章和书籍也包括二级分类和标签特征,是的视频推荐模型容易迁移至公众号和书籍队列的推荐任务中
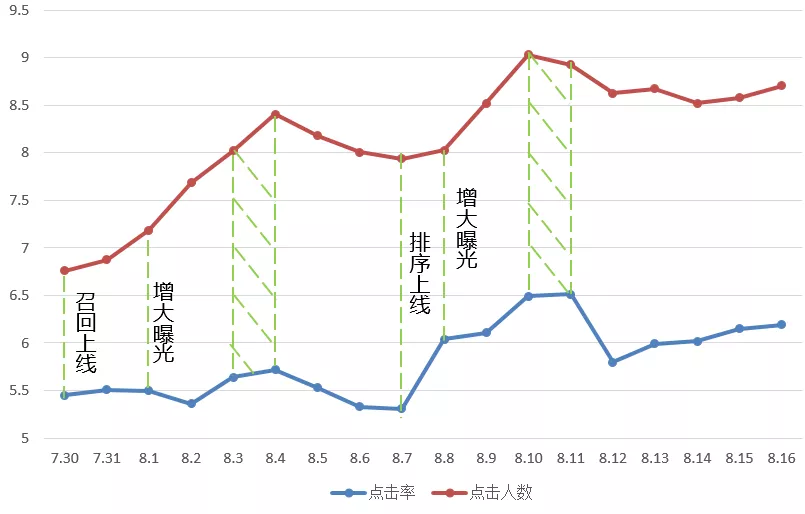
整个流程上线后,点击率和点击人数的变化如图所示,后续将继续进行优化。
总结和展望
推荐系统是一个不断演变的系统,需要尽可能地 balance 用户的已有兴趣和潜在兴趣的探索。这是一个 Exploration and Exploitation 之间的如何达到 balance 难题。如何在保证用户感兴趣的条件下,尽可能探索用户潜在的兴趣是一个难以权衡的问题。一味的追求的点击率到后期导致标题党的诞生,模型朝着一开始教的方向越走越偏,同样的一味追求探索,可能会导致夭折在初期。最后感谢云加社区、技术架构部,搜索,企鹅号的大力支持。
参考文献:
Covington, Paul, Jay Adams, and Emre Sargin. “Deep neural networks for youtube recommendations.” Proceedings of the 10th ACM conference on recommender systems. ACM, 2016.
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/Pt2L3_cwp3z0NBWnZLNaHQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论